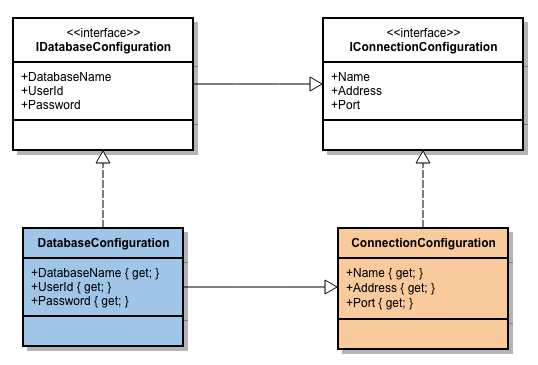
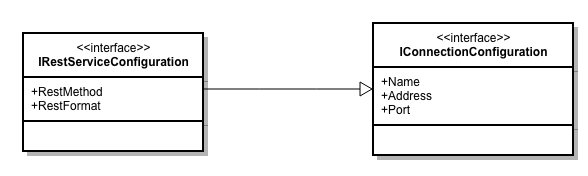
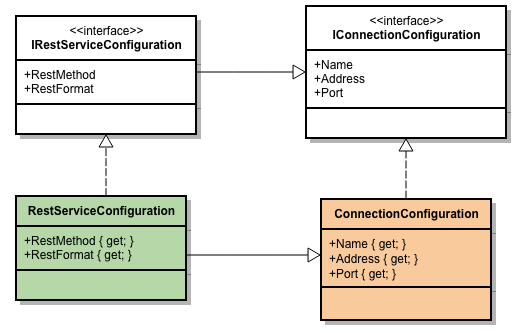
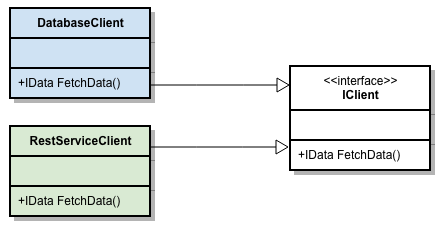
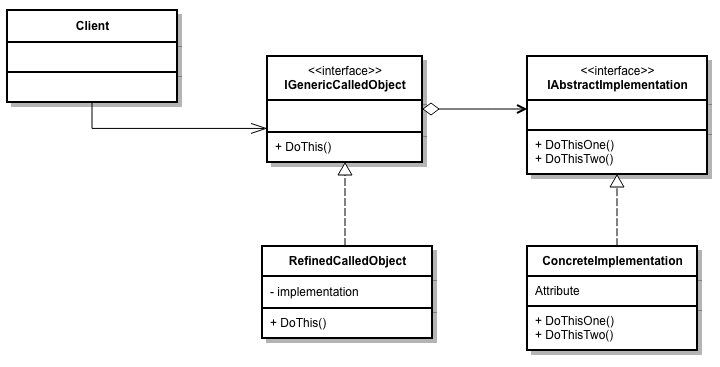
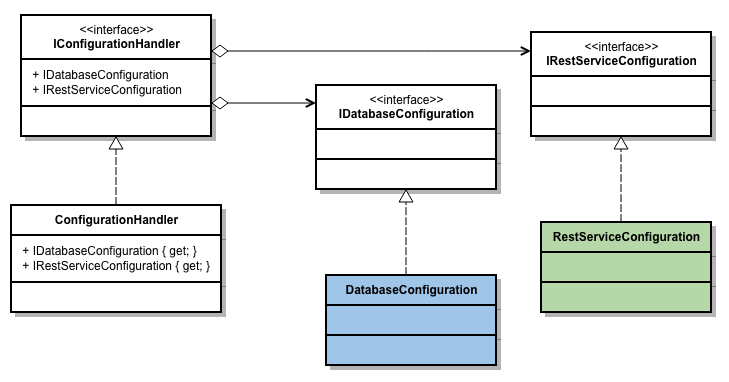
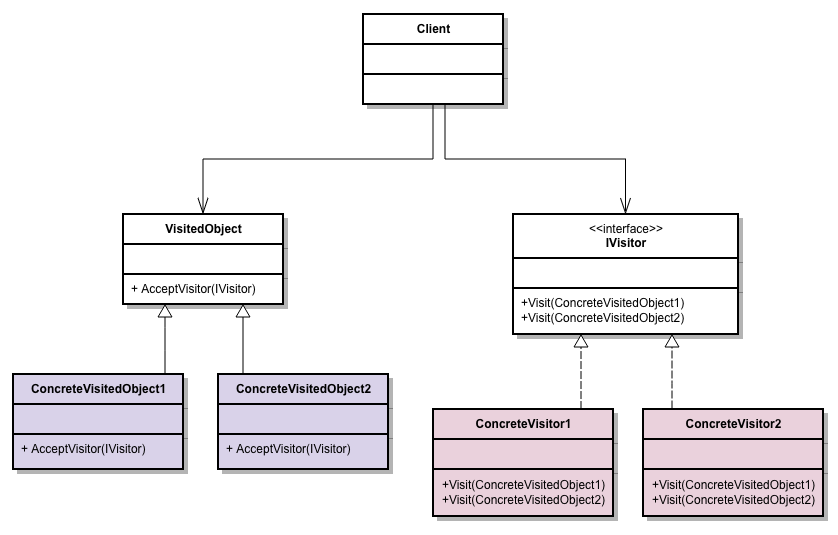
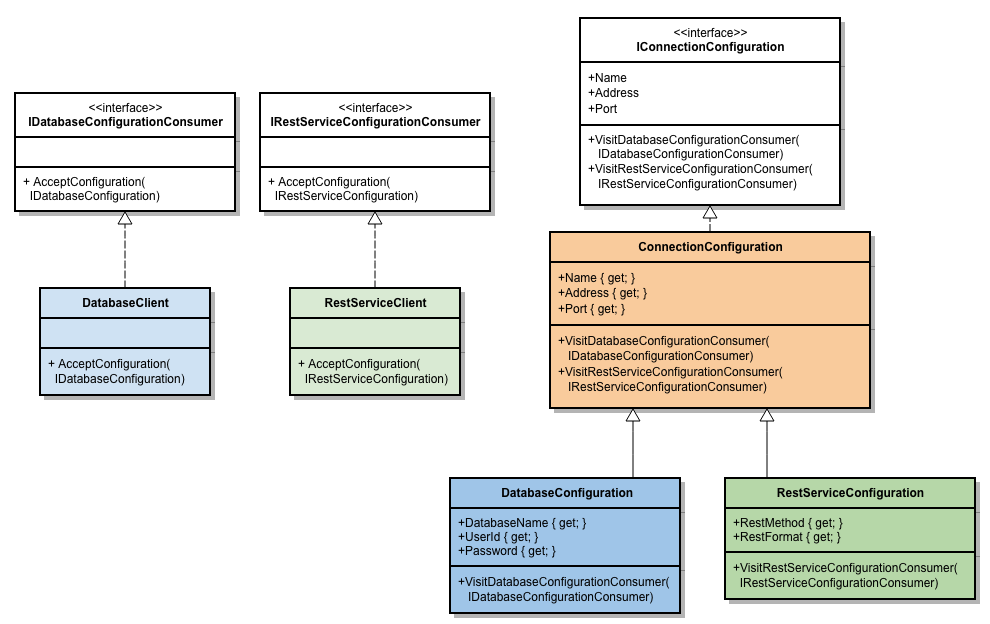
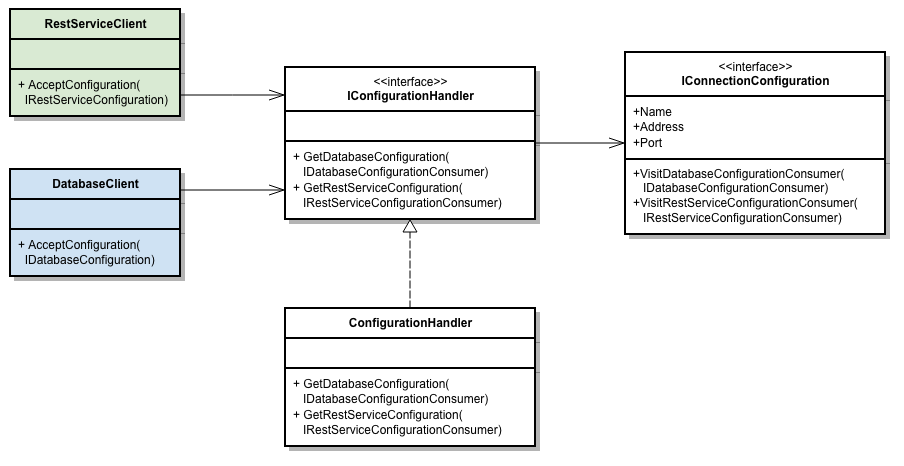
Avant de commencer, quelques brèves remarques au sujet de .NET Core:
.NET Core est une implémentation de Microsoft qui a pour but de rendre la technologie .NET disponible sur plusieurs plateformes.
.NET Core est open-source et les sources sont disponibles sur GitHub.
Un gros inconvénient du développement d’applications pour le framework .NET est qu’il nécessite l’installation du SDK du framework .NET et surtout l’installation de Visual Studio. Pour éviter l’installation de ces composants dans le cadre de .NET Core, Microsoft a mis à disposition une CLI .NET Core (i.e. Command Line Interface).
La CLI .NET Core permet d’effectuer la plupart des opérations effectuées par Visual Studio:
Créer un projet,
Ajouter une dépendance à un projet,
Builder une solution,
Générer un package NuGet,
etc…
Le gros avantage de la CLI .NET est d’être facile à installer et d’être disponible sur toutes les plateformes (Linux, macOS et Windows).
Avec .NET Core, il est possible de compiler des sources pour que les assemblies soient exécutées sur une machine où le SDK .NET Core est déjà installé. Les assemblies déployées ne contiendront que le code implémenté et non les assemblies du framework .NET Core (ce type de déploiement se rapproche du déploiement d’assemblies du framework .NET sur des machines Windows).
On peut aussi compiler le code .NET Core pour que les assemblies soient autonomes et qu’elles ne nécessitent aucune installation préalable du SDK .NET Core. Avec ce type de déploiement, les assemblies livrées contiennent le code compilé et les assemblies du framework .NET Core.
Il ne faut pas confondre .NET Core et .NET Standard. .NET Standard est une abstraction introduite par Microsoft pour permettre de livrer des assemblies en étant basé sur un standard plutôt que directement sur un framework. Etre basé sur un standard permet d’éviter d’avoir des dépendances vers une plateforme spécifique comme l’imposent les frameworks.
Il existe des compatibilités entre les versions de .NET Standard et les versions des frameworks, ce qui permet de savoir comment consommer les assemblies .NET Standard à partir d’assemblies basées sur des frameworks.
Une autre spécificité de .NET Standard est qu’il n’est possible de créer des livrables .NET Standard que pour des assemblies de type bibliothèque de classes (i.e. Class Library) car il ne doit pas y avoir de dépendances vers une plateforme particulière. Pour créer des assemblies sous forme d’exécutables, il faut utiliser des frameworks comme .NET ou .NET Core (pour davantage de détails sur .NET Standard: Comprendre .NET Standard en 5 min).
Les commandes siuvantes sont présentées pour Linux toutefois la syntaxe est la même pour les autres plateformes.
Pour afficher l’aide général de la commande dotnet:
user@debian:~% dotnet –h
Créer un nouveau projet (dotnet new)
Afficher la liste des modèles de projets disponibles:
user@debian:~% dotnet new -l
Créer un projet de type spécifique
Avec cette syntaxe, on peut créer un projet de type console. Le projet sera créé dans le répertoire courant avec le nom du répertoire courant:
user@debian:~% dotnet new console
Pour créer un projet avec un nom particulier (le projet sera créé dans un répertoire avec le nom du projet):
user@debian:~% dotnet new console –n <nom du projet>
Pour créer un projet avec un nom particulier en précisant le répertoire de sortie:
user@debian:~% dotnet new console –n <nom du projet> -o <chemin du répertoire de sortie>
Quelques autres types de projet:
Projet de test MS Test
mstest
Projet de test xUnit
xunit
Projet ASP.NET Core vide
web
Web application ASP.NET Core MVC
mvc
Web application ASP.NET Core avec Angular
angular
Projet Web API
webapi
Créer un fichier Solution
sln
Créer un projet pour une architecture déterminée
Par défaut, un projet est créé pour .NET Core 2.0. Pour indiquer une architecture spécifique, il faut utiliser l’option suivante:
user@debian:~% dotnet new <type du projet> –n <nom du projet> -f <nom du framework>
Les frameworks courants sont:
.NET Core
netcoreapp2.0
.NET Framework
net20
net45, net452
net46, net462
net47, net471
.NET Standard
netstandard2.0
Gérer une dépendance d’un projet vers un autre projet (dotnet add/remove)
Pour ajouter une dépendance dans le fichier .csproj d’un projet:
user@debian:~% dotnet add <chemin .csproj où ajouter la dépendance> reference
<chemin .csproj à rajouter>
Pour supprimer une dépendance dans le fichier .csproj d’un projet
user@debian:~% dotnet remove <chemin .csproj où supprimer la dépendance> reference
<chemin .csproj à supprimer>
Lister les dépendances:
user@debian:~% dotnet list <chemin .csproj> reference
Gérer le contenu d’un fichier .sln (solution)
Ajouter un projet à une solution:
user@debian:~% dotnet sln <fichier .sln à modifier> add <chemin .csproj à ajouter>
Pour supprimer un projet d’une solution
user@debian:~% dotnet sln <fichier .sln à modifier> remove <chemin .csproj à supprimer>
Effectuer une “build” (dotnet build)
Pour builder un projet ou une solution:
user@debian:~% dotnet build
Par défaut, la build est effectuée pour le framework .Net Core 2.0 et pour la configuration “Debug”.
Pour préciser le framework:
user@debian:~% dotnet build -f <nom du framework>
Pour indiquer la configuration “Debug” ou “Release”:
user@debian:~% dotnet build -c <nom de la configuration>
Pour spécifier un runtime:
user@debian:~% dotnet build -r <identificateur RID du runtime>
Quand on précise le runtime, le résultat de la build sera indépendant de la console .NET Core c’est-à-dire qu’il pourra être exécuté de façon autonome sur la plateforme cible sans que .NET Core ne soit installé.
Quelques exemples de RID (i.e. Runtime IDentifier):
Windows
any
win
win-x86
win-x64
MacOS
osx-x64
Linux
linux-x64
rhel-x64 (Red Hat)
debian-x64
ubuntu-x64
On peut utiliser l’option –o pour préciser un répertoire de sortie.
Supprimer le résultat d’une “build” (dotnet clean)
On peut exécuter la commande:
user@debian:~% dotnet clean
Les répertoires bin et obj sont présents toutefois leur contenu est supprimé.
Exécuter du code (dotnet run)
On peut exécuter du code .NET Core sans forcément avoir compilé avant. Cette commande est utile si on dispose de la console .NET Core et que les éléments de sortie n’ont pas été buildés pour un runtime particulier.
La commande est:
user@debian:~% dotnet run –p <chemin du répertoire du projet à exécuter>
On peut utiliser les options suivantes:
-c pour préciser la configuration (Debug ou Release)
-f pour préciser le framework
Publier les résultats de compilation (dotnet publish)
Permet de générer un répertoire contenant les assemblies destinées à être publiées sur d’autres plateformes.
Pour publier, il faut exécuter la commande:
user@debian:~% dotnet publish
De façon facultative, on peut ajouter le fichier .csproj du projet à publier:
user@debian:~% dotnet publish <chemin .csproj du projet à publier>
On peut utiliser les options suivantes:
-c pour préciser la configuration (Debug ou Release)
-f pour préciser le framework
-r pour préciser le runtime.
Par défaut le répertoire de sortie est:
<Répertoire du projet>/bin/Debug/<framework>/publish
Si on précise des éléments comme la configuration, le framework ou le RID (i.e. Runtime IDentifier), le répertoire de sortie sera:
<Répertoire du projet>/bin/<Configuration>/<framework>/<runtime identifier>/publish
Les assemblies générées seront autonomes et pourront être exécutées sans que le SDK .NET Core ne soit installé.
Exécuter les tests (dotnet test)
Pour exécuter les tests unitaires se trouvant dans un projet de test:
user@debian:~% dotnet test <chemin .csproj contenant les tests unitaires>
On peut utiliser les options suivantes:
-c pour préciser la configuration (par exemple Debug ou Release)
-f pour préciser le framework
Gérer les dépendances NuGet
Les sources des packages NuGet peuvent être paramétrées dans le fichier:
<répertoire de l'utilisateur>/.nuget/NuGet/NuGet.config
Par exemple, si l’utilisation est “debianuser” le répertoire sera sous Linux:
/home/debianuser/.nuget/NuGet/NuGet.config
Le contenu de ce fichier contient, par défaut, nuget.org:
La plupart du temps, il n’est pas nécessaire d’exécuter cette commande car elle est implicitement exécutée pour la plupart des commandes dotnet new, dotnet build, dotnet run etc…
Ajouter un package NuGet à un projet
Il faut exécuter la commande suivante:
user@debian:~% dotnet add <chemin .csproj> package <nom du package NuGet>
Si on se place dans le répertoire du projet, il n’est pas nécessaire de préciser le fichier .csproj:
user@debian:~/ProjectFolder% dotnet add package <nom du package NuGet>
On peut aussi ajouter des options liées au package NuGet comme la version:
user@debian:~% dotnet add package <nom du package NuGet> -version <version du package 1.2.3>
Supprimer la référence d’un package NuGet dans un projet
Pour supprimer une référence NuGet d’un projet, on peut exécuter:
user@debian:~% dotnet remove <chemin .csproj> package <nom du package NuGet>
Si on se place dans le répertoire du projet, il n’est pas nécessaire de préciser le fichier .csproj:
user@debian:~/ProjectFolder% dotnet remove package <nom du package NuGet>
Générer un package NuGet avec ses résultats de compilation (dotnet pack)
On peut générer un package NuGet avec la commande:
user@debian:~% dotnet pack <chemin .csproj>
Si on se trouve dans le répertoire d’un projet, il suffit d’exécuter:
user@debian:~% dotnet pack
On peut utiliser les options suivantes:
-c pour préciser la configuration (Debug ou Release)
-r pour préciser le runtime
-o pour indiquer un répertoire de sortie
--include-symbols pour générer un package contenant les fichiers PDB
Par défaut, le package est généré avec la configuration “Debug”.
Pour préciser la version du package, on peut utiliser l’option suivante:
Pour faire suite à l’installation, le présent article a pour but de présenter les fonctionnalités principales de Teamcity pour être capable de configurer une chaine de build. La documentation de Teamcity est bien faite et est très complète. Comme pour l’article précédent, le but n’est pas de paraphraser la documentation de Jetbrains mais de comprendre rapidement les fonctionnalités pour les utiliser efficacement. Cet outil est ergonomique toutefois il possède énormément de fonctionnalités qui ne sont pas faciles à appréhender aux premiers abords.
On va donc expliquer quelques fonctionnalités en illustrant en configurant une build d’une application .NET Core.
Avant de rentrer dans les détails de Teamcity, il reste quelques installations à effectuer pour être capable de builder une application .NET Core:
Installer le SDK .NET Core
Installer le plugin Teamcity pour .NET Core
Installer le SDK .NET Core sur l’agent
Il faut, dans un premier temps, installer le SDK .NET Core sur l’agent qui exécutera la build. Il n’est pas nécessaire d’installer .NET Core sur la machine qui héberge le serveur Teamcity (dans notre cas, il s’agit d’un container Docker).
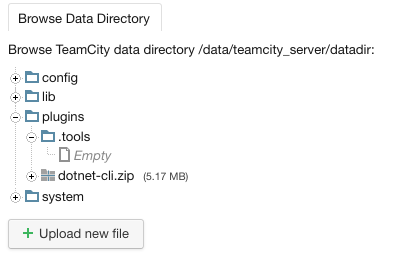
Chercher et télécharger le plugin “.NET CLI Support”. Le plugin est sous la forme d’un fichier .ZIP.
Il faut retourner sur la page des plugins de Teamcity et cliquer sur “Upload plugin zip”
Indiquer le fichier .ZIP du plugin et cliquer sur “Save”.
Le plugin doit apparaître dans la liste des fichiers:
Plugin “.NET CLI Support”
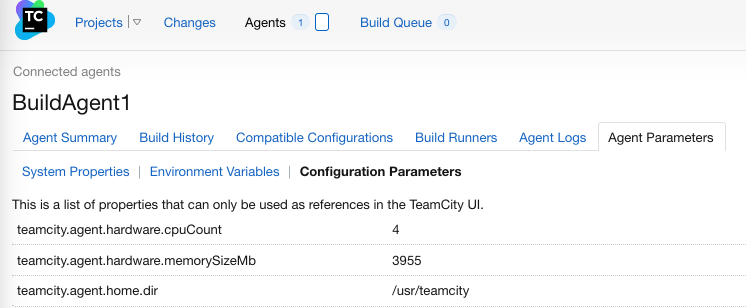
A ce moment, le plugin n’est pas exécuté. On peut s’en rendre compte en allant dans les paramètres de l’agent:
Cliquer sur “Agents” en haut de l’interface
Cliquer sur l’agent
Cliquer sur l’onglet “Agent Parameters”
Cliquer sur “Configuration Parameters”
On peut voir que la liste de paramètres ne contient pas de paramètres liés à .NET Core:
Paramètres liés à .NET Core sont absents
Pour que le plugin soit exécuté, il faut redémarrer le serveur Teamcity en exécutant les commandes suivantes:
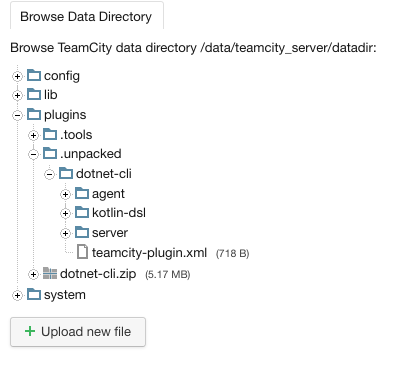
A la fin du redémarrage du serveur, si on clique sur “Administration” ⇒ “Diagnostics” ⇒ Onglet “Browse Data Directory” et si on déplie le contenu du répertoire plugins, on s’aperçoit qu’il contient un répertoire .unpacked contenant le plugin .NET Core dézippé:
Plugin dézippé
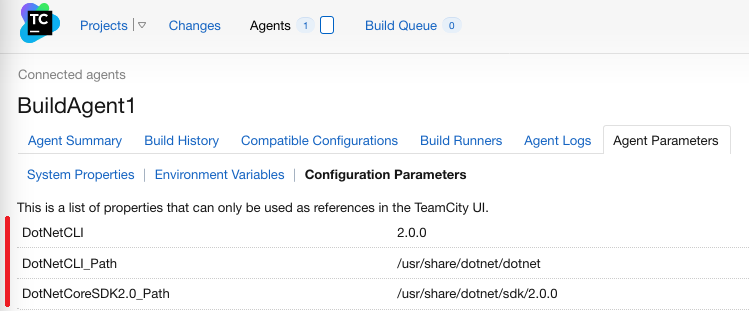
Enfin si on consulte de nouveau les paramètres de l’agent dans “Agents” ⇒ <nom de l’agent> ⇒ Onglet “Agent parameters” ⇒ Onglet “Configuration Parameters”, on doit voir des paramètres relatifs à .NET Core:
Les paramètres liés à .NET Core sont présents
Familles d’interfaces
Dans Teamcity, il existe 3 familles d’interfaces qui sont accéssibles suivant les autorisations des utilisateurs:
La partie Administration accessible quand on clique en haut à droite sur “Administration”
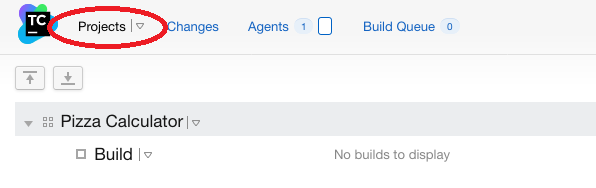
La partie affichant les builds des projets configurés accessible en cliquant sur “Projects” en haut à gauche: Cliquer sur “Projects”
La partie permettant de configurer un projet. Cette partie est accessible en cliquant sur “Projects” puis en cliquant sur le nom du projet lui-même et enfin en cliquant sur “Edit Project Settings”: Cliquer sur “Edit Project Settings”
On entrera, par la suite, plus en détail pour expliquer toutes ces parties.
Configuration des utilisateurs
La configuration des utilisateurs est accessibles en cliquant sur “Administration” dans la partie “User Management”.
La configuration des utilisateurs est classique et s’articule autour de 3 notions:
Les rôles qui indiquent les droits dont un utilisateur dispose pour effectuer une action
Des groupes d’utilisateurs: on peut affecter des rôles à un groupe de façon à ce que tous les utilisateurs de ce groupe disposent des mêmes droits.
Les utilisateurs ont des rôles et peuvent appartenir à groupe. Si un utilisateur appartient à une groupe, il hérite des rôles de ce groupe.
Il existe 2 modes pour paramétrer les utilisateurs: un mode simple et un mode par projet.
Mode simple
Quand ce mode est actif, la partie “User Management” ne comporte que 2 parties “Users” et “Groups”.
Ce mode ne comprends que quelques rôles:
Administrateur qui accède à tous les écrans sans restrictions. Pour créer ce type d’utilisateur, il faut cocher “Give the user administrative privileges” sur l’écran de création d’un utilisateur.
Utilisateur authentifié (i.e. logged-in user) qui accède à la configuration de tous les projets mais pas à la partie Administration. Pour pouvoir créer ce type d’utilisateurs, il faut que les utilisateurs du groupe “All Users” ne soient pas des administrateurs. On peut le vérifier en cliquant sur “Groups” ⇒ “All Users” ⇒ Décocher “Group with administrative privileges…”.
Enfin, au moment de créer un utilisateur, il faut que “Give the user administrative privileges” soit décoché.
Utilisateur invité (i.e. guest user) qui accède seulement à la partie affichant les builds des projets. Pour que les utilisateurs invités puissent se connecter, il faut l’autoriser en cliquant sur “Administration” ⇒ “Authentication” ⇒ Cocher “Allow login as guest user”.
Mode par projet
Pour activer ce mode, il faut aller dans “Administration” ⇒ “Authentication” ⇒ Cocher “Enable per-project permissions”.
Quand ce mode est actif, la partie “User Management” comporte 3 parties: “Users”, “Groups” et “Roles”. Il permet une gestion plus fine des rôles en permettant de configurer des accès pour chaque rôle. Par défaut, les rôles sont (visibles dans la partie “Roles” de “User management”):
“System administrator” qui accède à tous les écrans sans restriction.
“Project administrator” qui permet à un utilisateur de configurer tout ce qui est lié à un projet et aux projets enfant (gérer les utilisateurs du projet, paramétrer des configurations de build et configurer des agents).
“Project developer” qui permet à un utilisateur de voir des configurations de build et de lancer des builds.
“Project viewer” qui ne peut que voir les projets et les builds correspondantes.
“Agent manager” qui permet de gérer les paramètres liés à un agent.
Ces rôles peuvent être affectés à un groupe ou à un utilisateur par projet. D’autres parts, ils sont entièrement paramétrables dans l’écran “Roles” de la partie “User management”.
Par la suite, lorsqu’on parlera de la configuration d’une build, on utilisera le terme “build configuration” qui correspondant davantage au terme utilisé dans la documentation de Teamcity.
Avant de rentrer dans les détails de la configuration d’une build, il convient d’avoir quelques éléments en tête:
Héritage des paramètres: Teamcity possède un système d’héritage des paramètres d’un projet à ses enfants. De ce fait, si des éléments de configuration sont définis pour un projet parent, les projets enfant hériteront de ces éléments. Les projets peuvent, toutefois, surcharger les valeurs de ces éléments. Ce principe est valable pour une grande partie des paramètres.
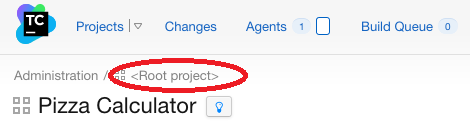
Le projet racine <Root project>: on peut avoir du mal à atteindre la configuration de ce projet car il n’est pas toujours affiché sur l’interface. Il faut évidemment que l’utilisateur ait le droit d’y accéder (en fonction des droits dont il dispose), ensuite pour y accéder il faut:
Cliquer sur “Projects” en haut à gauche
Cliquer sur un projet (peu importe le projet)
Cliquer sur “Edit Project Settings”
Cliquer sur “<Root project>”: Cliquer sur “<Root project>”
A ce moment, on accède aux paramétrages du projet racine. Le fait de ne pas voir apparaître ce niveau de la hiérarchie sur tous les écrans peut prêter à confusion car on peut hériter de paramètres sans comprendre d’où ils proviennent.
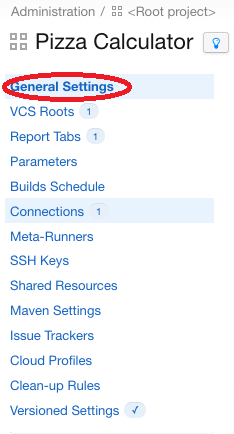
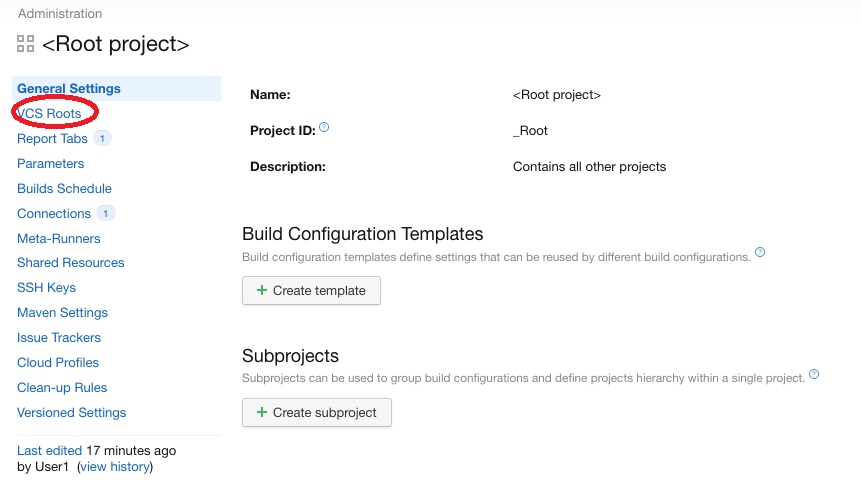
Le seul endroit où on peut voir clairement l’héritage des projets est dans la partie “General Settings” d’un projet: Cliquer sur “General Settings” pour voir la hiérarchie des projets
Si on clique sur “VCS Roots”, par exemple, on ne voit plus cet héritage, ce qui peut prêter à confusion.
On se propose, dans la suite, de configurer entièrement la build d’un projet de façon à voir toutes les étapes de la configuration.
Configurer un projet
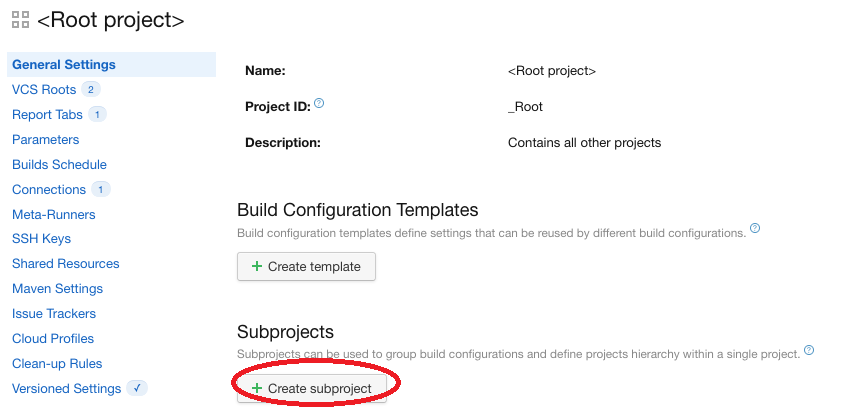
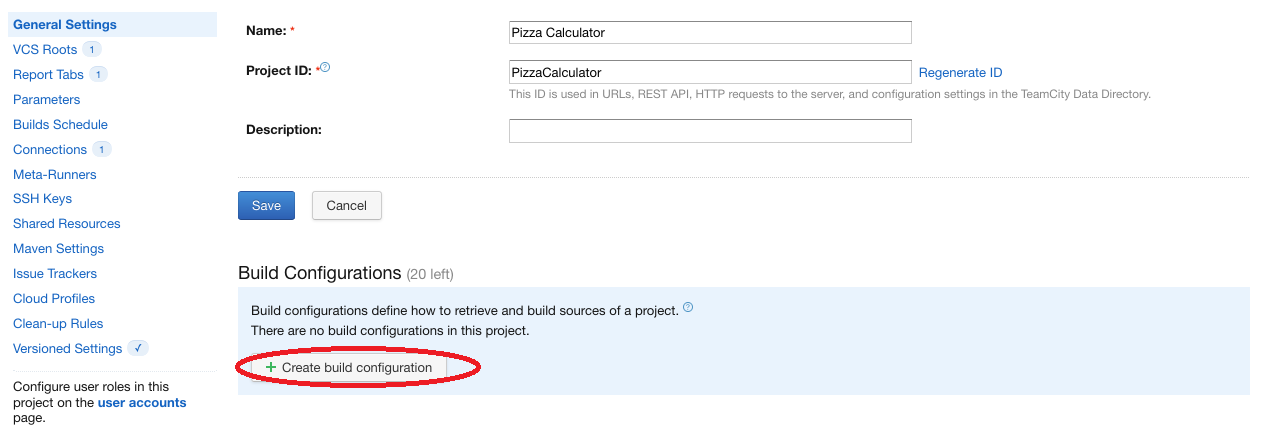
Pour créer un projet il suffit d’aller dans le projet racine <Root project> puis dans la partie “General Settings” (comme explicité plus haut). On clique ensuite sur “Create subproject”:
Cliquer sur “Create subproject”
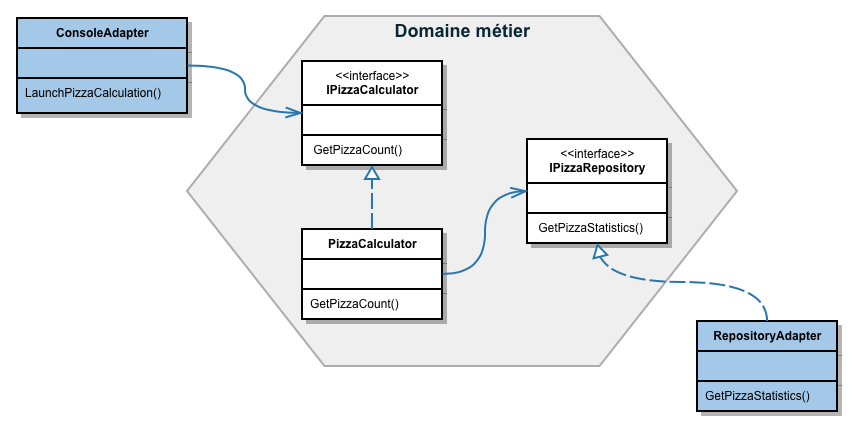
Dans notre exemple, on crée un projet s’appelant “Pizza Calculator”. Ce projet est disponible sur GitHub.
On clique ensuite sur le projet pour accéder à la configuration du projet.
VCS Root
Pour importer le projet à partir de GitHub, il faut configurer un VCS Root (VCS pour Version Control System). Pour ce faire, on clique sur “VCS Roots” dans les paramètres du projet:
Cliquer sur “Create VCS root”
On clique ensuite sur “Create VCS root” pour créer un VCS Root. On renseigne les paramètres liés au projet:
Type of VCS: Git
VCS root name: Pizza-calculator
VCS root ID: peu importe, il faut que l’ID soit unique
On indique ensuite le username et le mot de passe.
On peut tester en cliquant sur “Test connection”.
Configurer une “build configuration”
Cette partie permettra de configurer une build pour qu’elle apparaisse dans la partie affichant toutes les builds par projet (en cliquant sur “Projects” en haut à gauche).
On peut définir plusieurs build configurations par projet si on souhaite, par exemple, effectuer des builds pour des architectures différentes.
Pour créer une build configuration:
On clique sur “Create build configuration”: Cliquer sur “Create build configuration”
Cliquer sur “Manually” et indiquer les paramètres suivants:
Dans l’écran suivant, pour le paramètre “Attach existing VCS root”, il faut sélectionner Pizza-calculator et cliquer sur “Attach”.
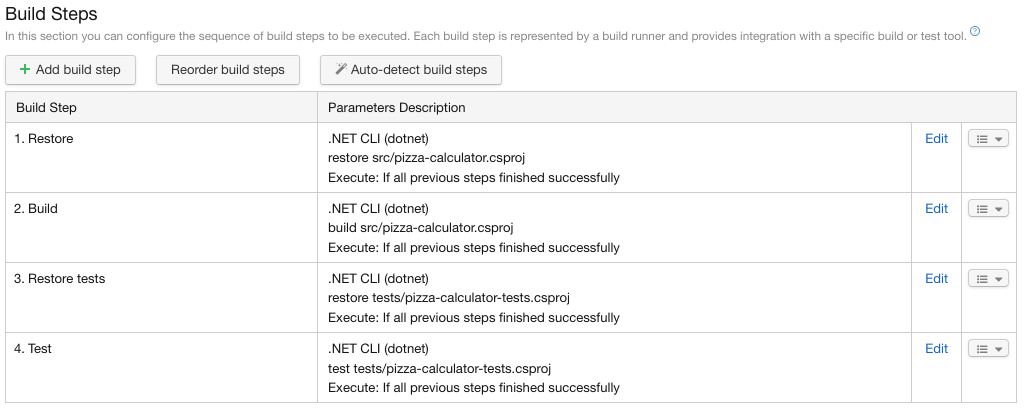
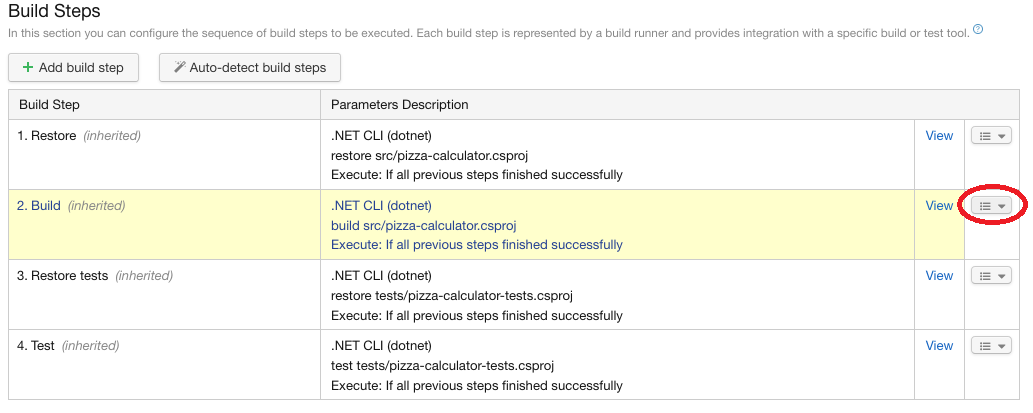
A ce moment Teamcity va détecter 4 étapes pour builder. Le terme utilisé pour désigner ces étapes est build step. Ces étapes sont exécutées successivement lors de l’exécution de la build:
Restore: permet de restaurer les packages NuGet dans le projet src/pizza-calculator.csproj
Build: permet de construire les assemblies dans le projet src/pizza-calculator.csproj
Restore Test: permet de restaurer les packages NuGet dans le projet de test tests/pizza-calculator.csproj
Test: exécute les tests dans le projet tests/pizza-calculator.csproj
Il faut sélectionner toutes les build steps puis cliquer sur “Use selected” pour qu’elles soient créées. On obtient alors une liste des build steps ordonnées.
On peut voir le paramétrage de chaque build step en cliquant sur “Edit”. On en profite pour renseigner un nom pour chaque build step en précisant le paramètre “Step name” de façon à avoir la configuration suivante:
Liste des build steps ordonnées
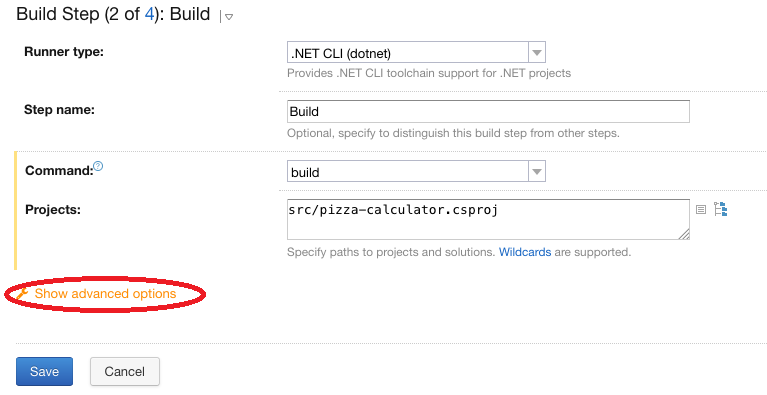
On peut compléter la configuration de la build step “Build” en ajoutant un paramètre après avoir cliqué sur “Show advanced options”:
Cliquer sur “Show advanced options”
Il faut compléter le paramètre “Configuration” avec la valeur “Release”.
Exécuter la “build configuration”
On peut à ce moment, exécuter la build en cliquant sur “Projects” en haut à gauche et en dépliant la nœud du projet “Pizza Calculator”. On clique ensuite sur le bouton “Run” correspondant à la build configuration “Build AnyCpu”:
Cliquer sur “Run”
Pour accéder aux détails de l’exécution de la build, il faut cliquer sur la build configuration “Build AnyCpu”, ensuite sur l’onglet “History” et enfin sur la build qui a été exécutée. On obtient un écran contenant tous les détails de l’exécution. Les onglets les plus intéressants sont:
Tests: qui permet d’indiquer les tests qui ont été exécutés. On peut voir notamment les tests qui ont éventuellement échoué.
Build log: cet écran est le plus intéressant car il permet de voir tous les détails de la build. Il est particulièrement utile quand on souhaite savoir pourquoi une build a échoué. Il faut cliquer sur la fléche du bas pour déplier tous les nœuds: Déplier tous les nœuds pour voir les détails d’une build
Parameters: cet écran présente tous les paramètres utilisés pendant la build. Ces données peuvent aussi être utiles en cas d’erreurs de façon à trouver le problème.
Répertoire où est effectué la build
Quand une build configuration est exécutée, le répertoire sur l’agent où le traitement est effectué se trouve dans le répertoire indiqué dans le fichier de configuration <répertoire d'installation de l'agent>/conf/buildAgent.properties avec le paramètre workDir.
Dans notre cas, le répertoire d’installation de l’agent est /usr/Teamcity et le répertoire de travail est /usr/Teamcity/work.
Pour une build configuration, le chemin du répertoire de travail sera complété par un nom aléatoire et différent pour chaque build configuration. Toutefois, il faut avoir en tête que le répertoire sera le même entre 2 exécutions de la même build configuration. Utilisé le même répertoire sans en vider le contenu peut parfois mener à des comportements étranges.
Détails de configuration d’une “build configuration”
Ils existent de nombreux autres paramètres dans une build configuration qui sont utiles pour des configurations plus complexes.
Artifacts
Ces éléments ne sont pas, à proprement parlé, des éléments de configuration. Ce sont des éléments qui sont générés par la build configuration. Ils se renseignent dans la partie “General Settings” d’une build configuration, et avec le paramètre “Artifact paths”:
Renseigner le paramètre “Artifact paths” d’une build configuration
Les artifacts sont importants quand on souhaite chainer plusieurs build configurations. Il faut avoir en tête un certain nombre de choses pour ne pas être surpris par certains comportements de Teamcity:
Quand une build configuration est exécutée, un certain nombre de traitements sont effectués. Par exemple, des assemblies sont buildées. Ces assemblies correspondent à des fichiers générés qui n’étaient pas présents au début de l’exécution de la build configuration.
Si une 2ebuild configuration dépend d’éléments générés par une autre build configuration, pour que ces éléments soient réellement accessibles par la 2ebuild configuration, il faut les indiquer dans les artifacts.
On indiquera dans la 1èrebuild configuration avec le paramètre “Artifact Paths” quelles sont les éléments qui ont été générés et qui doivent être transmis à la build configuration suivante.
On indiquera, ensuite, dans la 2ebuild configuration quelles sont les dépendances d’artifacts nécessaires à son exécution.
Ainsi, si on souhaite qu’une build configuration fournisse des éléments à une autre build configuration, il faut indiquer le répertoire ou le fichier à fournir en utilisant le paramètre “Artifact paths” avec une syntaxe du type:
+:bin/Debug=>assemblies: permet d’indiquer que le contenu du répertoire bin/Debug sera copié dans un répertoire assemblies pour les build configurations suivantes.
+:bin/Debug: indique que le contenu du répertoire bin/Debug sera copié dans un répertoire bin/Debug pour les build configurations suivantes.
-:bin/Debug/netcoreapp2.0=>bin/Debug: indique que le répertoire bin/Debug/netcoreapp2.0 ne sera pas copié dans bin/Debug pour les build configurations suivantes.
Triggers
Dans les paramètres d’une build configuration, la partie “Triggers” permet de configurer des conditions pour déclencher l’exécution d’une build:
VCS Trigger: déclenche une build quand un commit a été détecté dans le gestionnaire de versions (i.e. VCS).
Schedule Trigger: permet de déclencher le démarrage d’une build à un certaine heure.
Finish Build Trigger: déclenche la build quand une autre build s’est terminée.
Failure conditions
Il peut s’avérer nécessaire d’affiner certains critères pour considérer que l’exécution d’une build a echoué. Par exemple, si le temps d’exécution d’une build dépasse une certaine durée ou si un message particulier apparaît dans les logs.
Build features
Ce paramétrage permet d’effectuer des traitements très divers concernant des éléments assez différents. Par exemple, les build features les plus utiles peuvent être:
File Content Replacer: permet de remplacer un fragment de texte dans un fichier par un autre. Cette fonction est particulièrement utile quand on veut affecter une version particulière dans un fichier Version.cs ou quand on veut appliquer un paramétrage particulier dans un fichier App.config ou Web.config. La détection du fragment se fait par regex.
VCS labeling: permet de poser un tag dans le gestionnaire de version lorsqu’une build s’est exécuté et a réussi.
Automatic merge: merge des branches dans le gestionnaire de versions si la build a réussi.
Performance Monitor: permet de collecter quelques métriques (utilisation du CPU, de la mémoire du disque ou de la machine).
Ce paramétrage permet d’indiquer quelles sont les build configurations nécessaires à l’exécution de la build configuration courante. Ces dépendances peuvent être de 2 natures:
Snapshot dependencies: permet d’indiquer une condition qui doit être satisfaite quant à l’exécution d’une autre build configuration pour que la build configuration courante soit exécutée.
Par exemple, on pourra:
Déterminer la build configuration qui doit être exécutée avant la build configuration courante
Indiquer le critère de réussite de l’exécution d’une autre build configuration
Préciser qu’on souhaite exécuter la build configuration courante sur le même agent qu’une autre build configuration.
Ajouter des critères d’échec de la build configuration courante en fonction du résultat de build configurations précédentes.
Artifact dependencies: ce paramètre permet d’indiquer quels sont les éléments générés par une autre build configuration qui sont nécessaires à l’exécution de la build configuration courante.
Par exemple, une assembly compilée dans une autre build configuration peut être nécessaire à la compilation effectuée par la build configuration courante.
La syntaxe utilisée pour indiquer le chemin des artifacts est similaire à celle utilisée pour le paramètre “Artifact Paths”:
+:<chemin dans la build config précédente> => <chemin dans la build config courante>
+:<chemin dans la build config précédente>: si on ne précise pas de répertoire d’arrivée alors c’est le même répertoire que celui d’origine.
-: <chemin dans la build config précédente> => <chemin dans la build config courante>: indique qu’on souhaite exclure un fichier ou un répertoire dans les artifacts utilisés pour la build configuration courante.
L’élément de configuration “Clean destination paths before downloading artifacts” est assez important car il permet de supprimer le contenu du répertoire d’arrivée avant d’importer les artifacts d’une build précédente. Dans certains cas, si on exécute à plusieurs reprises une build configuration, on peut avoir des comportements étranges si le répertoire d’arrivée n’est pas vide.
Les paramètres sont particulièrement utiles car ils permettent de personnaliser certains éléments de configuration et de les rendre accessibles dans toute l’arborescence des projets. Comme pour la plupart des éléments de configuration, les paramètres sont héritables dans l’arborescence des projets. Cela signifie que:
Si on crée un paramètre au niveau d’un projet, ce paramètre sera accessible dans les projets sous-jacents (ou enfants), dans les build configurations de ce projet et dans les build templates de ce projet.
Si on crée un paramètre au niveau d’une build configuration, il sera accessible à tous les niveaux de cette build configuration.
Si on crée un paramètre dans un build template, il sera accessible automatiquement dans les build configurations qui implémentent le build template.
Les paramètres peuvent être utilisés dans n’importe quel écran de configuration d’un projet ou d’une build configuration si l’arborescence le permet avec la syntaxe:
%<nom du paramètre>%
Par exemple, si le paramètre s’appelle build.counter, on pourra l’utiliser avec la syntaxe:
%build.counter%
Il existe 3 types de paramètres:
Configuration parameter: ces paramètres peuvent être utilisés dans les éléments de configuration des projets et des build configurations. Ils sont spécifiques à Teamcity et ne seront pas accessibles à d’autres éléments que les commandes directement lancées par Teamcity. La documentation indique que ces variables ne sont pas injectées dans les builds.
Par exemple, si un paramètre s’appelle %DotNetBuildConfiguration%, on peut l’utiliser pour lancer une commande à partir de Teamcity comme, par exemple, la commande suivante:
En revanche, en dehors de Teamcity, la variable ne sera pas accessible comme pouvait l’être une variable d’environnement.
System Properties: ces variables sont injectées dans les builds et sont donc accessibles lorsque les commandes ne sont pas directement lancées par Teamcity. Ces variables peuvent être utilisées quand on ne veut pas utiliser de variables d’environnement (qui pourraient avoir une empreinte trop forte car elles modifient des éléments de configuration du serveur). En effet, les paramètres “system properties” sont spécifiques à une build ce qui permet de ne pas affecter d’autres builds exécutées en parallèle.
Environment variable: comme son nom l’indique, ce type de paramètre permet de définir des variables d’environnement. Ces variables sont accessibles dans la build mais aussi sur le serveur sur lequel la build est exécutée. Il faut donc, garder en tête que si 2 builds sont exécutées en même temps sur le même serveur et si elles utilisent des valeurs différentes d’une même variable, l’utilisation de ce type de paramètre peut occasionner des comportements inattendus.
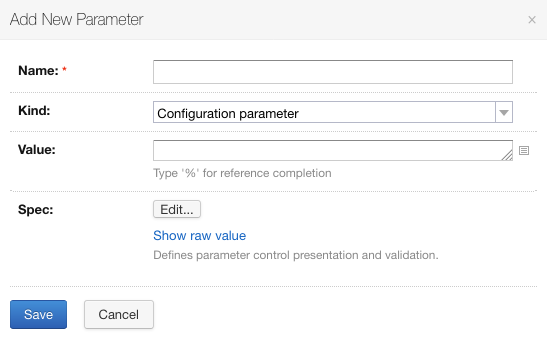
Pour créer un paramètre, il suffit de cliquer sur “Add new parameter”:
Cliquer sur “Add new parameter”
Il faut préciser ensuite quelques éléments de configuration comme le nom, le type de paramètre et la valeur:
Configurer un paramètre
D’autres éléments de configuration sont disponibles en cliquant sur “Edit”:
Label: permet d’indiquer un identifiant qui sera présenté sur les écrans d’exécution des build configurations. Le but est d’afficher un identifiant différent du nom du paramètre et plus explicite.
Display: ce paramétrage est assez important car il indique où le paramètre sera affiché pour qu’on puisse compléter sa valeur:
Normal: c’est le paramétrage par défaut. La valeur du paramètre sera utilisée sans qu’on soit obligé de la remplir sur l’écran de lancement d’une build. Toutefois, la valeur peut être modifiée sur l’écran de lancement d’une build.
Hidden: le paramètre ne sera pas affiché sur l’écran de lancement d’une build. Une modification de la valeur n’est possible que dans la configuration.
Prompt: ce paramétrage permet de forcer à remplir une valeur sur l’écran de lancement d’une build.
Type: permet d’affiner le type de paramétrage:
Password: les paramètres de ce type ne seront jamais affichés en clair.
Text: l’intérêt de ce paramétrage est de pouvoir définir des regex pour valider la valeur du paramètre.
Cet écran permet d’ajouter des conditions pour que l’exécution d’une build configuration se fasse spécifiquement sur un agent. La plupart du temps, Teamcity indique lui-même des conditions qui doivent être satisfaites pour permettre l’exécution d’une build. Par exemple, une condition pourrait être la présence de .NET Core ou de JAVA sur un serveur.
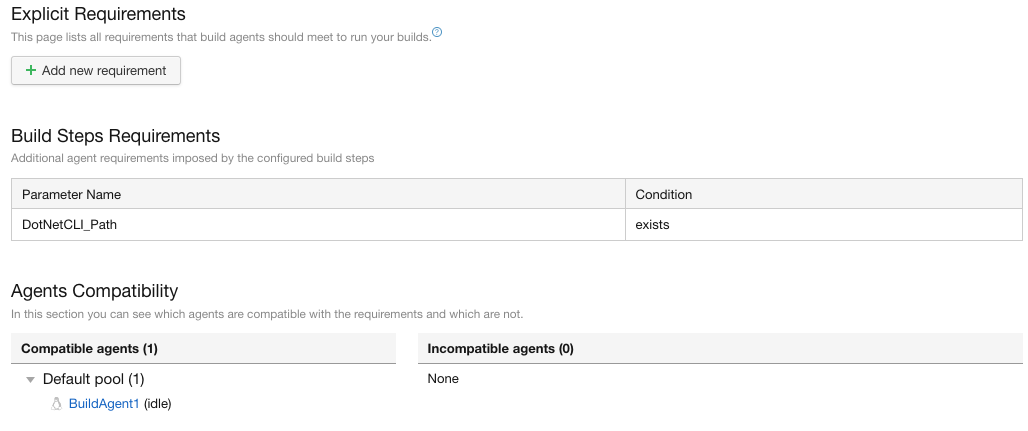
Toutes les conditions sont indiquées dans la partie “Build steps Requirements”:
Ecran “Agent requirements”
Les agents compatibles sont indiqués dans “Agents Compatibility”. L’intérêt majeur de cette partie est d’indiquer la condition non satisfaite qui empêche l’exécution d’une build sur un agent.
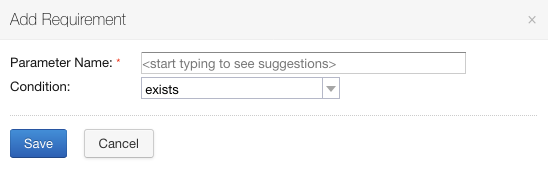
L’ajout d’une condition se fait en cliquant sur “Add new requirement”. On peut ensuite indiquer la condition plus spécifique:
Ajout d’une condition en cliquant sur “Add new requirement”
Perfectionner une chaine de “builds”
De façon à illustrer les éléments de configuration présentés précédemment, on va complexifier la chaine de builds (le terme utilisé dans la documentation est build chain) commencée au début de l’article.
Ajouter une “build configuration” avec une dépendance
Pour illustrer les dépendances, on va ajouter une nouvelle build configuration qui dépendra de la build configuration “Build AnyCpu” créée précédemment.
On se propose de créer une build configuration qui va générer un package NuGet avec la commande dotnet pack.
Cette build configuration utilise le résultat de la compilation de la build configuration “Build AnyCpu”.
Pour créer la nouvelle build configuration:
On va donc dans les paramètres du projet “Pizza Calculator” et on clique sur “Create build configuration”.
Cliquer sur “Manually” et on indique le nom “Nuget package”
On ne précise rien dans l’écran suivant. On clique simplement sur “Build Step”
Cliquer ensuite sur “Add build step”
Sélectionner .NET CLI (dotnet)
On précise les paramètres suivants après avoir cliqué sur “Show advanced options”:
Runner type: .NET CLI (dotnet)
Steps name: Nuget pack
Execute step: If all previous steps finished successfully
Command: pack
Projects: src/pizza-calculator.csproj
Command line parameters: /p:PackageVersion=1.0.0.%build.counter%. Cette valeur permettra d’indiquer un numéro de version en utilisant le paramètre build.counter (ce paramètre est auto-incrémenté par Teamcity à chaque exécution de la build configuration).
Cliquer sur “Save”
On arrive ensuite à la configuration des dépendances à proprement parlé:
On clique sur “Add new snapshot dependancy”. Comme indiqué plus haut, ce paramétrage permet de préciser la build configuration qui doit être exécutée avant la build configuration actuelle.
On précise la valeur Pizza Calculator :: Build AnyCpu correspondant à la build configuration qui compile les sources récupérées à partir de GitHub.
On coche “Do not run new build if there is a suitable one” de façon à indiquer de ne pas ré-exécuter la build configuration précédente si rien n’a changé entre 2 exécutions.
On coche aussi “Only use successful builds from suitable ones” pour indiquer que seules les compilations ayant réussies seront prises en compte.
On coche enfin “Run build on the same agent” pour indiquer que la build configuration précédente et la build configuration courante doivent être exécutées sur le même agent.
Pour la valeur “On failed dependency”, on sélectionne la valeur “Make build failed to start”. Ce paramétrage permet d’empêcher l’exécution de la build configuration courante si la build configuration précédente a échoué.
Pour la valeur “On failed to start/canceled dependancy”, on sélectionne, de même, “Make build failed to start”. De la même façon, si la build configuration précédente a été annulée, la build configuration courante ne sera pas exécutée.
On clique, enfin, sur “Save”.
Sachant que la build configuration doit utiliser les résultats de la compilation de la build configuration “Build AnyCpu”, il faut ajouter des dépendances d’artifacts (le terme utilisé dans la documentation est artifact dependencies).
Dans la partie “Artifact Dependencies”:
Cliquer sur “Add new artifact dependancy”.
On précise la valeur "Pizza Calculator :: Build AnyCpu" correspondant à la build configuration qui compile les sources.
Pour la valeur “Get artifacts from”, on sélectionne la valeur Build from the same chain pour utiliser exactement les artifacts provenant de la build configuration exécutée juste préalablement.
Dans “Artifact rules”, on indique de quelle façon on récupère les artifacts de la build configuration précédente. Sachant qu’on veut récupérer le contenu du répertoire src et le placer dans le répertoire src, on l’indique avec la valeur:
+:src=>src
Sachant que les répertoires de départ et d’arrivée ont le même nom, on peut aussi utiliser la valeur:
+:src
On coche ensuite “Clean destination paths before downloading artifacts” pour que le répertoire d’arrivée des artifacts soit vide avant d’effectuer la copie. Ce paramétrage permet d’éviter des comportements inattendus quand certains fichiers ont été supprimés et ne sont plus présents dans les artifacts.
On termine en cliquant sur “Save”.
On peut tester l’exécution de la build chain en accédant à l’écran d’exécution des build configurations en cliquant sur “Build configuration Home” en haut à droite puis “Pizza Calculator”:
Cliquer sur “Run” au niveau de “Nuget package”
On clique sur “Run” pour lancer l’exécution de la build configuration “Nuget package”. L’exécution de la build configuration “Nuget package” va entraîner l’exécution de la build configuration “Build AnyCpu”.
En cliquant sur l’onglet “Build chains”, on peut voir un résumé de l’exécution de la chaine de build:
Affichage de la chaine de build
Ajouter un paramètre pour indiquer la version
Pour illustrer l’ajout d’un paramètre, on se propose d’ajouter un paramètre contenant un numéro de version. Cette version devra être précisée, dans un premier temps, au moment de générer le package NuGet. Dans un 2e temps, on viendra modifier la version dans les sources pour que le numéro de version soit pris en compte au moment de la compilation dans la build configuration “Build AnyCpu”.
Avant tout, on ajoute le paramètre BuildVersion:
Dans les paramètres du projet “Pizza Calculator”, on clique sur “General Settings” puis sur “Nuget package” pour accéder aux paramètres de la build configuration “Nuget package”.
Cliquer ensuite sur “Parameters”
Ajouter un paramètre en cliquant sur “Add new parameter”
On précise les paramètres suivants:
Name: BuildVersion
Kind: Configuration parameter
Value: on indique une valeur par défaut 0.0.0.
On clique ensuite sur “Edit” et on précise les paramètres suivants:
Label: Numéro de version
Display: Prompt pour que le paramétre apparaisse sur l’écran de lancement de la build configuration.
Type: Text
Allowed Value: Regex
Pattern: ^(\d+\.)?(\d+\.)?(\d+)$
Validation Message: Le numéro de version doit être du type: x.y.z
On clique sur “Save” pour le 1er panneau et “Save” de nouveau pour le 2e panneau.
Pour utiliser le paramètre:
Cliquer sur “Build Step”
Cliquer ensuite sur la build step “Nuget pack” pour en éditer les paramètres.
On modifie la valeur correspondant au paramètre “Command line parameters” avec la valeur suivante:
/p:PackageVersion=%BuildVersion%.%build.counter%
On valide en cliquant sur “Save”.
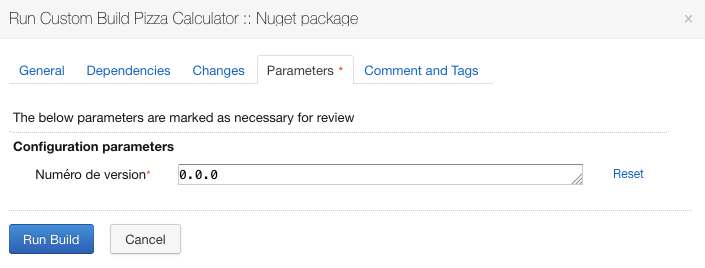
Pour tester le paramètre, on accède à l’écran d’exécution des build configurations en cliquant sur “Build configuration Home” en haut à droite puis “Pizza Calculator”. Cliquer ensuite sur “Run” au niveau de la build configuration “Nuget package”. On obtient l’écran de lancement de la build configuration avec le nouveau paramètre:
Indiquer le numéro de version au lancement de la build
On précise la valeur 1.2.3 et on clique sur “Run”.
Pour vérifier la prise en compte du paramètre, on peut aller dans les logs d’exécution de la build configuration en cliquant sur la dernière exécution:
Cliquer sur la dernière exécution
Puis sur l’onglet “Build log”, on peut voir dans les logs, une ligne du type:
[pack] Successfully created package '/usr/Teamcity/work/371ec8e2dc170c79/src/bin/Debug/pizza-calculator.1.2.3.8.nupkg'.
Le numéro de version est donc bien utilisé.
Prendre en compte le paramètre dans un “build configuration” précédente
On souhaite utiliser le numéro de version au moment de la compilation dans la build configuration “Build AnyCpu”. Cette build configuration est exécutée avant la build configuration “Nuget package”.
La fonctionnalité qui permet d’effectuer ce paramétrage est appelée: reverse dependency parameter (cf. documentation de Teamcity).
Pour ajouter ce type de paramètre, il faut utiliser la syntaxe suivante:
reverse.dep.*.<nom du paramètre>
On va donc modifier le paramétrage de la build configuration “Nuget package”:
Dans les paramètres du projet “Pizza Calculator”, on clique sur “General Settings” puis sur “Nuget package” pour accéder aux paramètres de la build configuration “Nuget package”.
Cliquer sur “Parameters”
Cliquer sur le paramètre “BuildVersion” et modifier le nom de ce paramètre pour avoir:
reverse.dep.*.BuildVersion
On valide en cliquant sur “Save”.
On modifie l’endroit où on utilisait le paramètre “BuildVersion” dans la build configuration “Nuget package”:
Cliquer sur “Build step”
Cliquer ensuite sur la build step “Nuget Pack”
Modifier la valeur du paramètre “Command line parameters” pour obtenir:
Ensuite, il faut rajouter le paramètre BuildVersion au niveau de la build configuration “Build AnyCpu”:
Dans les paramètres du projet “Pizza Calculator”, on clique sur “General Settings” puis sur “Build AnyCpu” pour accéder aux paramètres de la build configuration “Build AnyCpu”.
Cliquer ensuite sur “Parameters”
Ajouter un paramètre en cliquant sur “Add new parameter”
On précise les éléments suivants:
Name: BuildVersion
Kind: Configuration parameter
Value: on indique une valeur par défaut 0.0.0.
Pour prendre en compte cet élément de configuration, il faut ajouter un file content replacer pour remplacer les numéros de version dans le code source.
Ajouter un “file content replacer” pour modifier la version
Cette étape permet de remplacer les numéros de version dans le code source pour qu’il soit pris en compte au moment de la compilation.
Cette configuration s’effectue en ajoutant une build feature au niveau de la build configuration “Build AnyCpu”:
Dans les paramètres du projet “Pizza Calculator”, on clique sur “General Settings” puis sur “Build AnyCpu” pour accéder aux paramètres de la build configuration “Build AnyCpu”.
Cliquer sur “Build features”
Cliquer ensuite sur “Add build feature” pour ajouter une nouvelle build feature.
On sélectionne “File Content Replacer”, ce qui permettra de remplacer le numéro de version dans le fichier pizza-calculator.csproj:
Replace with: $1\%BuildVersion%.%build.counter%$3. Cette valeur est différente de la valeur par défaut.
Cliquer sur “Save”
Ajouter un nouveau “File Content Replacer” pour modifier l’élément FileVersion.
Cliquer sur “Load template” et sélectionner dans la partie .NET Core “FileVersion in csproj (.NET Core)” qui permet d’affecter les valeurs suivantes:
Process files: **/*.csproj
Find what: (<(FileVersion)\s*>).*(<\/\s*\2\s*>)
Replace with: $1\%BuildVersion%.%build.counter%$3. Cette valeur est différente de la valeur par défaut.
Cliquer sur “Save”.
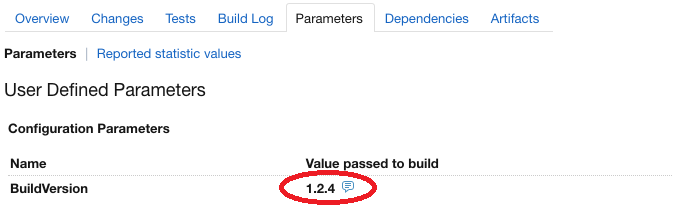
Pour tester le paramètre, on accède à l’écran d’exécution des build configurations en cliquant sur “Build configuration Home” en haut à droite puis “Pizza Calculator”. On clique ensuite sur “Run” au niveau de la build configuration “Nuget package”. On précise la valeur 1.2.4 et on clique sur “Run”.
Pour vérifier la prise en compte du paramètre, on peut aller dans les logs d’exécution de la build configuration “Build AnyCpu” en cliquant sur la dernière exécution, puis sur l’onglet “Parameters”, on peut voir que la valeur de BuildVersion est celle précisée au niveau de la build configuration “Nuget package”:
Valeur de la variable BuildVersion
Ajouter des “build features” pour créer un tag Git
On se propose ensuite de créer une build feature pour apposer un tag Git dans le cas où la build s’est bien passée.
Dans ce cas, on va dans les paramètres de la build configuration “Nuget package”:
Dans les paramètres du projet “Pizza Calculator”, on clique sur “General Settings” puis sur “Nuget package” pour accéder aux paramètres de la build configuration “Nuget package”.
Cliquer sur “Version Control Settings” pour ajouter le VCS correspondant à Git.
Cliquer sur “Attach VCS root”
Sélectionner Pizza-Calculator puis on valide en cliquant sur “Attach”.
Cliquer ensuite sur “Build Features” pour ajouter une nouvelle build feature.
Cliquer sur “Add build feature”.
On sélectionne VCS labeling et on indique les paramètres suivants:
VCS root to label: sélectionner le VCS Pizza-calculator
On coche “Label successful builds only” pour que le tag soit apposé seulement si la build réussit.
On peut ensuite lancer une build pour tester ce paramétrage en cliquant sur “Build configuration Home” en haut à droite puis “Pizza Calculator”. On clique ensuite sur “Run” au niveau de la build configuration “Nuget package”.
A la fin de la build, si on vérifie dans GitHub, on peut se rendre compte que le tag a bien été apposé.
Rendre des “build configurations” plus génériques
Si on souhaite réutiliser des build configurations, il existe 2 méthodes pour les rendre plus génériques:
En créant un modèle de build (le terme utilisé dans la documentation est build template) au niveau du projet
En créant un meta-runner pour exploiter la build configuration en dehors du projet.
Créer un “build template”
Créer un build template est la 1ère méthode pour rendre une build configuration plus générique. Le build template va permettre de réutiliser plus facilement la build configuration sans dupliquer trop d’éléments de configuration.
On peut créer un build template de la même façon que l’on a créé précédement une build configuration:
Dans les paramètres du projet “Pizza Calculator”, cliquer sur “General Settings”
Cliquer ensuite sur “Create template”.
Le reste du paramétrage est similaire à celui d’une build configuration.
Une autre méthode consiste à utiliser une build configuration existante pour créer un build template:
Dans les paramètres du projet “Pizza Calculator”, cliquer sur “General Settings” puis sur “Build AnyCpu” pour accéder aux paramètres de la build configuration “Build AnyCpu”.
On clique sur “Actions” en haut à droite puis on clique sur “Extract template”.
On indique un nom, par exemple Build.
On peut créer, ensuite facilement une nouvelle build configuration en se basant sur le build template:
Dans les paramètres du projet “Pizza Calculator”, cliquer sur “General Settings”.
Cliquer sur “Create build configuration” pour créer une nouvelle build configuration.
Cliquer sur “Manually” puis on précise quelques paramètres:
Name: Build x86
Based on template: on sélectionne Build.
On valide en cliquant sur “Create”.
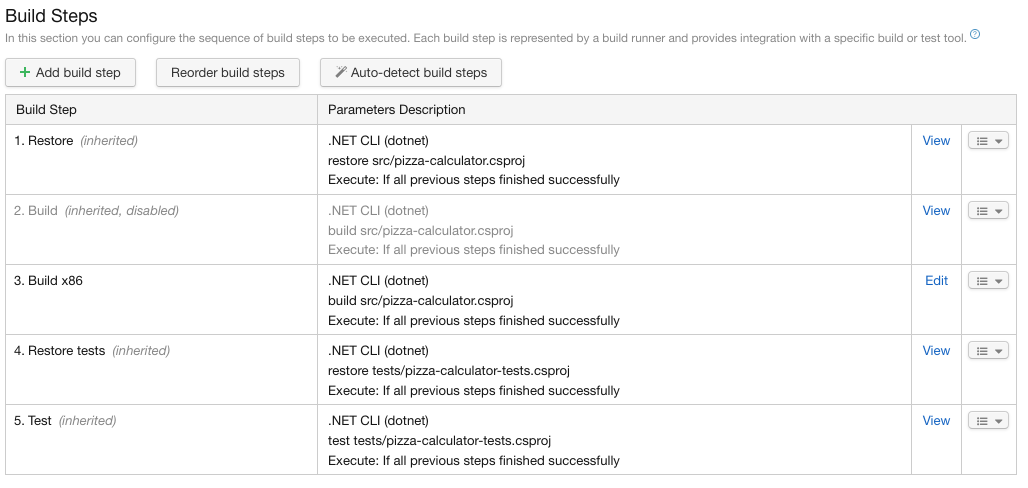
On va ensuite spécialiser cette build configuration pour qu’elle compile avec une configuration de runtime “x86”. 2 approches sont possibles:
1ère approche: désactiver la build step valable pour le runtime “AnyCpu” et créer une build step spécialisée pour le runtime “x86”.
2e approche: créer un paramètre pour la configuration correspondant au runtime et pour surcharger la valeur de ce paramètre dans les build configurations.
On va expliciter les 2 approches: 1ère approche: désactiver la build step valable pour le runtime “AnyCpu”
On va ensuite spécialiser cette build configuration pour qu’elle compile avec le runtime “x86”:
Cliquer alors sur “Build steps”
On ne peut modifier les paramètres des build steps héritées du build template, on va donc créer une nouvelle build step en dupliquant la build stepBuild.
Cliquer donc sur la flèche à droite de la build step “Build” puis on clique sur “Copy build step”: Cliquer sur la flèche à droite de la build step “Build”
On laisse le paramètre “Copy build step to:” sur la valeur Pizza Calculator :: Build x86 correspondant à la build configuration actuelle.
On valide en cliquant sur “Copy”.
Renommer cette build step en cliquant dessus et en modifiant le nom pour Build x86. Après avoir cliqué sur “Show advanced options”, indiquer pour le paramètre “Runtime” la valeur win-x86.
On valide en cliquant sur “Save”.
On désactive la build step “Build” puisqu’elle ne sert plus à rien:
Cliquer sur la flèche à droite de la build stepBuild
Cliquer ensuite sur “Disable build step”.
La build step devient grisée:
Build step désactivée
On peut ensuite lancer l’exécution de la build configuration en cliquant sur “Build configuration Home” en haut à droite puis “Pizza Calculator”. On clique ensuite sur “Run” au niveau de la build configuration “Build x86”.
ATTENTION
Cette approche n’est pas la meilleure car si on modifie le build template, on peut changer le comportement des build configurations qui en dépendent et certains comportements peuvent être inattendus.
2e approche: créer un paramètre pour le runtime
On crée d’abord une variable pour configurer le runtime:
Dans les paramètres du projet “Pizza Calculator”, on clique sur “General Settings” puis sur le build template “Build”.
Cliquer ensuite sur “Parameters”.
Cliquer sur “Add new parameter” avec les paramètres suivants:
Name: BuildRuntime
Kind: Configuration parameter
On clique sur “Edit” pour spécialiser d’autres paramètres.
Label: Configuration runtime dotnet
Display: Normal
Type: Text
Allowed value: Any
On valide en cliquant sur “Save” pour valider les paramètres et cliquer de nouveau sur “Save” pour valider la création du paramètre.
On va ensuite utiliser le paramètre dans la build step qui compile:
Cliquer sur “Build Steps”
Cliquer sur la build step se nommant Build.
Après avoir cliqué sur “Show advanced options” pour afficher toutes les options, on indique la valeur %BuildRuntime% pour l’élément de configuration “Runtime”.
On peut ensuite spécialiser une build configuration pour le runtime “x86”:
Dans les paramètres du projet “Pizza Calculator”, on clique sur “General Settings”.
Si on a créé une build configurationBuild x86 pour la 1ère approche, il faut la supprimer en cliquant sur la flèche à droite au niveau de la build configuration: Supprimer la build configurationBuild x86
Cliquer ensuite sur “Delete build configuration”.
Pour créer une nouvelle build configuration se basant le build templateBuild donc on clique sur “Create build configuration”.
On clique sur “Manually” puis on précise quelques paramètres:
Name: Build x86
Based on template: on sélectionne Build.
Pour le paramètre BuildRuntime, on indique la valeur win-x86.
On valide en cliquant sur “Create”.
On peut ensuite lancer l’exécution de la build configuration en cliquant sur “Build configuration Home” en haut à droite puis “Pizza Calculator”. On clique ensuite sur “Run” au niveau de la build configuration “Build x86”.
Privilégier la 2e approche
Cette approche est à privilégier car elle rend le paramétrage plus clair et il est plus facile de modifier le build template par la suite en maitrisant les impacts sur les build configurations qui en dépendent.
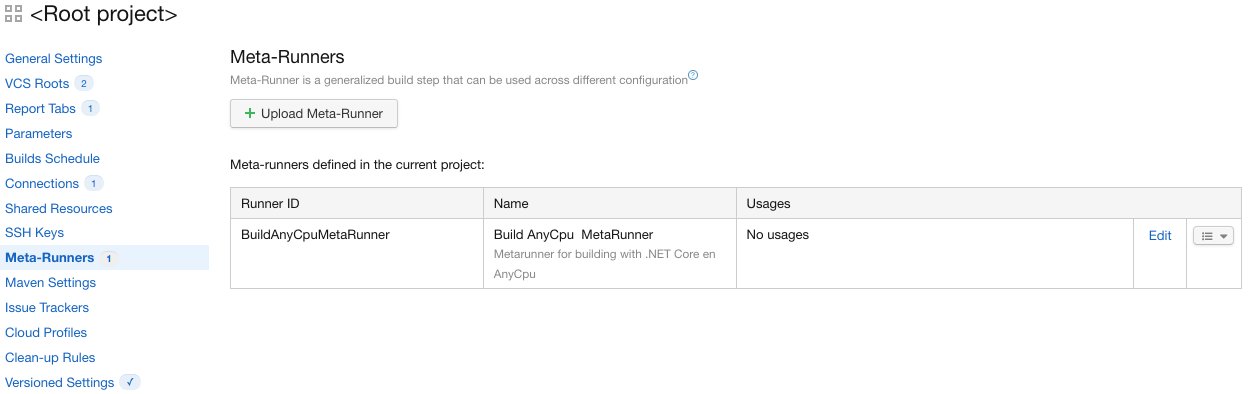
Créer un “meta-runner”
Un meta-runner est une autre méthode pour rendre une build configuration plus générique. Comme un build template, un meta-runner va permettre de réutiliser plus facilement une build configuration sans dupliquer trop d’éléments de configuration.
La différence entre un build template et un meta-runner est que le meta-runner peut se définir et se partager à n’importe quel niveau de l’arborescence alors qu’un build template est limité à un projet.
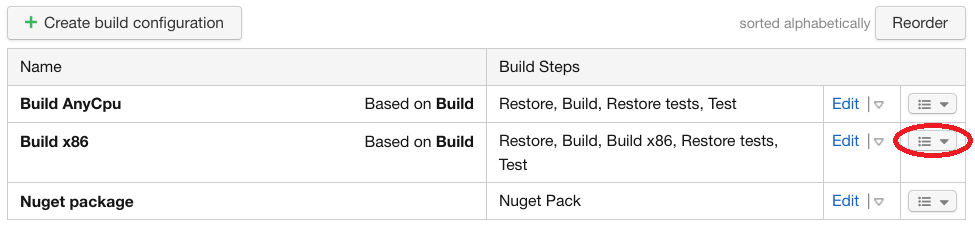
Pour créer un méta-runner, la méthode la plus simple consiste à utiliser une build configuration existante pour le générer:
Dans les paramètres du projet “Pizza Calculator”, on clique sur “General Settings” puis sur “Build AnyCpu” pour accéder aux paramètres de la build configuration “Build AnyCpu”.
Cliquer sur “Actions” en haut à droite puis cliquer sur “Extract template”.
On précise quelques paramètres:
Project: <Root project> on indique un projet plus élevé pour en bénéficier en dehors du projet “Pizza calculator”
Name: Build MetaRunner
Description: Metarunner for building with .NET Core
Valider en cliquant sur “Extract”.
On arrive ensuite au niveau du projet “<Root project>”:
Meta-runners de “<Root project>”
Si on clique sur le meta-runner, on voit une description en XML des différentes build steps:
Le gros intérêt du meta-runner est qu’il est possible d’éditer facilement les éléments directement dans le code XML.
On peut ensuite facilement utiliser le meta-runner dans un autre projet. Par exemple, si on crée un nouveau projet:
Au niveau de “<Root project>”, cliquer sur “Create subproject”
Indiquer le nom SliceCalculator
Valider en cliquant sur “Create”.
On peut utiliser le meta-runner de 2 façons:
Dans le projet “SliceCalculator”, on clique sur “Meta-Runners” puisqu’on hérite du meta-runner se trouvant au niveau de <Root project>.
Cliquer ensuite sur la flèche à droite du meta-runner puis sur “Create build configuration from meta-runner”
Préciser ensuite où la build configuration doit être créée et préciser le nom de la build configuration: Build AnyCpu disconnected from MetaRunner
On valide en cliquant sur “Create”.
On obtient une nouvelle build configuration avec les mêmes build steps que la build configuration “Build Any Cpu” dans le projet “PizzaCalculator”.
ATTENTION: la configuration est dupliquée
Le gros inconvénient de cette méthode est que la build configuration “Build AnyCpu disconnected from MetaRunner” dans le projet “SliceCalculator” est déconnecté du meta-runner:
Si on modifie le meta-runner défini au niveau de “<root project>”, les modifications ne seront pas répercutées sur la nouvelle build configuration.
On perd, un peu l’intérêt du meta-runner puisqu’il s’agit d’une duplication de la configuration.
Une autre méthode pour utiliser le meta-runner consiste à créer une build step qui exécute entièrement le meta-runner:
Dans le projet “SliceCalculator”, on crée une nouvelle build configuration en cliquant “General Settings”.
Cliquer ensuite sur “Create build configuration”.
Cliquer sur “Manually” puis préciser le nom de la build configuration: Build AnyCpu connected to MetaRunner.
Valider en cliquant sur “Create”.
Cliquer sur “Build steps” pour créer un nouveau build step
Cliquer sur “Add build step”
Sélectionner le nom du meta-runner créé au niveau du projet “<Root project>” à savoir “Build AnyCpu MetaRunner”.
Valider en cliquant sur “Create”.
La build step nouvellement créée permet d’exécuter en une seule étape le meta-runner se trouvant au niveau de “<Root project>”. Si on modifie le meta-runner, toutes les modifications seront répercutées dans les build steps qui l’utilisent de cette façon.
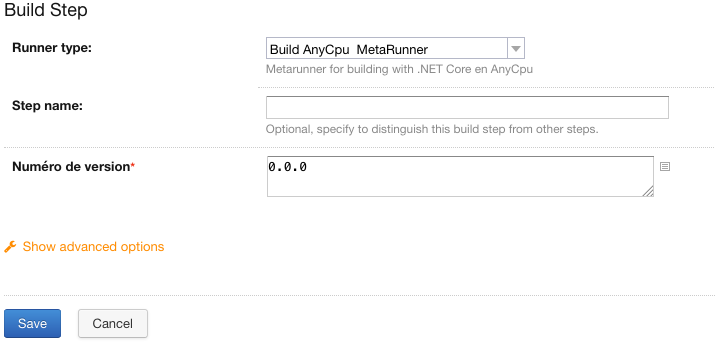
Cette méthode donne aussi la flexibilité de pouvoir surcharger la valeur de certains paramètres définis dans le meta-runner. Par exemple dans notre cas, il est possible de surcharger la valeur du paramètre “Numéro de version” au niveau de la build step:
Surcharger la valeur du paramètre “Numéro de version” au niveau de la build step
Il n’existe pas de “if” dans les meta-runners
Il n’est pas possible d’utiliser des conditions avec des directives “if” dans les meta-runners donc pour spécialiser un meta-runner dans une build configuration, il existe 2 approches:
1ère approche:
Créer une build configuration à partir du meta-runner en cliquant sur “Create build configuration from meta-runner” au niveau du meta-runner.
Désactiver des build steps en cliquant sur “Disable build step” dans l’écran “Build steps” de la build configuration.
On peut de même ajouter de nouveaux build steps en fonction des besoins.
2e approche:
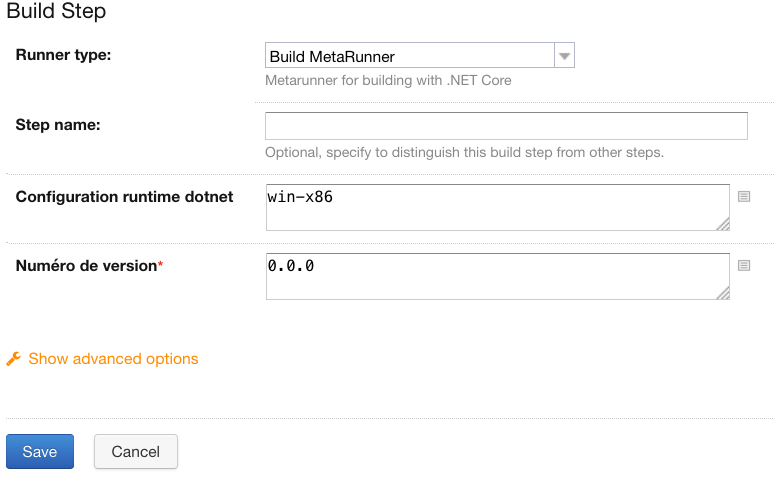
Utiliser les paramètres en niveau du meta-runner pour spécialiser certains éléments de configuration. Par exemple dans le meta-runner définit précédemment, le paramètre “BuildRuntime” peut être spécialisé dans la build step “Build”.
Si on crée une build configuration et qu’on utilise le meta-runner sous forme d’une build step (comme pour la build configuration “Build AnyCpu connected to MetaRunner” définie précédemment), on peut spécialiser la valeur du paramètre: Paramétrer un meta-runner dans une build step
Configurer des “feature branches” Git
Si on utilise Git en tant que VCS, il est possible de configurer Teamcity pour qu’il puisse gérer des features branches. Cette fonctionnalité est particulièrement intéressante puisqu’elle permet de lancer des builds pour une branche spécifique au lieu de la lancer systématiquement pour la branche master.
Si on va dans la configuration du VCS (i.e. Version Control System) du projet “Pizza Calculator” en cliquant sur “VCS Roots” puis sur la configuration “Pizza-calculator”, on peut voir que la valeur du paramètre “Default branch” est refs/heads/master. Ce paramètre indique que la branche par défaut qui sera systématiquement buildée est la branche master.
Pour permettre de builder d’autres branches que la branche principale, on modifie les paramètres suivants:
Cliquer sur “Show advanced options”
Pour le paramètre “Branch specification”, indiquer la valeur +:refs/heads/*.
Ce paramètre signifie qu’on pourra builder toutes les branches du repository Git (dans la cas où on veut limiter à certaines branches, on peut affiner la wildcard*).
Valider en cliquant sur “Save”.
A ce moment, le VCS root “Pizza-calculator” gère les feature branches.
Pour l’illustrer, on va créer une branche dans le repository Git:
Ensuite, on vérifie dans Teamcity si on peut effectivement builder la branche feature_branch:
On accède à l’écran d’exécution des build configurations en cliquant sur “Projects” en haut à gauche et en dépliant le nœud du projet “Pizza Calculator”.
On peut voir qu’on peut sélectionner une branche particulière en dépliant la liste déroulante <Active branches>:
Sélectionner une branche en dépliant la liste déroulante <Active branches>
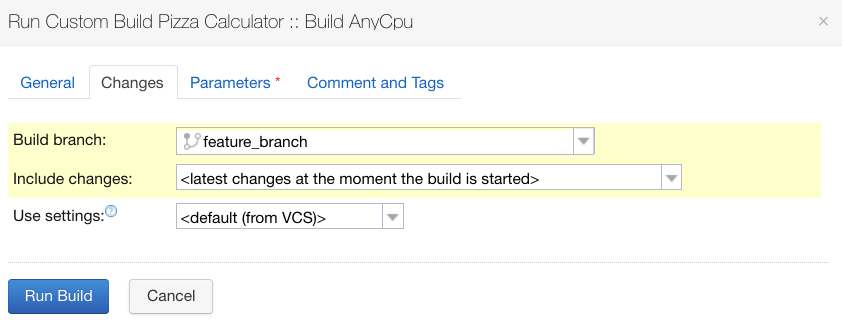
On lance une build sur la branche feature_branch en cliquant sur “Run” à droite de la build configuration “Build AnyCpu”.
Aller dans l’onglet “Changes” et sélectionner la branche feature_branch pour l’élément de configuration “Build branch”: Sélectionner la branche feature_branch dans l’onglet “Changes”
A la fin de la compilation, on peut voir que les lignes de statut des builds sont différentes suivant la branche:
Dans cet article, on a eu l’occasion d’expliquer les fonctionnalités principales de Teamcity comme:
Configurer une build configuration (i.e. configuration de build) avec des build steps (i.e. étapes de build),
Créer une autre build configuration avec des dépendances,
Ajouter des paramètres à une build configuration,
Ajouter des build features pour effectuer des modifications lors de l’exécution d’un build,
Créer un meta-runner.
Toutes ces explications ont pour but de rendre les premières configuration de Teamcity plus aisées de façon à mettre en place des processus de continous delivery rapidement et plus facilement.
Cet article rassemble quelques rappels concernant Powershell pour se remettre en mémoire les instructions principales de ce langage. D’autres fonctionnalités sont détaillées davantage dans Powershell en 10 min.
Quelques remarques en préambule:
Powershell n’est pas sensible à la casse
Pour commenter du code, il faut utiliser le caractère #
# Code Powershell commenté
Variables
Généralement le type n’est pas indiqué explicitement mais le type est déterminé par le type de la valeur d’initialisation:
$var=65
$var2="class string"
On peut forcer un typage particulier de cette façon:
[string]$var = 65 # $var est une chaîne de caractères
Raccourcis pour indiquer explicitement le type
D’autres types peuvent être indiqués de cette façon:
Raccourci
Type de données
[datetime]
Date ou heure
[string]
Chaîne de caractères
[char]
Un seul caractère
[double]
Nombre flottant double précision
[single]
Nombre flottant simple précision
[int]
Entier 32 bits
[Boolean]
Valeur True ou False (Vrai ou Faux)
Typage avec des types .NET
On peut indiquer un typage .NET avec une syntaxe de ce type:
[System.Int32]$var = 5
Utilisation des variables
Quelques exemples d’utilisation de variables:
$var="powershell"
Write-Host "classic $var string" # $var est remplacé par sa valeur
# à cause des double quotes " "
$var2='classic $a string' # $var2 n'est pas interprété car
# on utilise de simples quotes ' '
Write-Host $var2
On peut aussi utiliser le caractère accent grave ([AltGr] + [7]):
$var2="classic `$a string"
Write-Host $var2
“Cmdlets” principales
Affiche de l’aide
D’une façon générale, pour avoir de l’aide concernant une cmdlet (i.e. command let):
La valeur est True si les opérandes ne sont pas égales
-ge
“greater than or equal”
La valeur est True si l’opérande de gauche est supérieure ou égale à l’opérande de droite
-gt
“greater than”
La valeur est True si l’opérande de gauche est strictement supérieure à l’opérande de droite
-le
“less than or equal”
La valeur est True si l’opérande de gauche est inférieure ou égale à l’opérande de droite
-lt
“less than”
La valeur est True si l’opérande de gauche est strictement inférieure à l’opérande de droite
-like et -notlike
Permet d’effectuer des comparaisons d’égalité de chaines de caractères en utilisant des wildcards:
? pour désigner un seul caractère non spécifié
* pour désigner un ou plusieurs caractères non spécifiés
Par exemple: $var -like "*uary"
-match et -notmatch
Permet de vérifier si une chaine de caractères respecte une expression régulière. Par exemple: $string -match "\w"
-contains et -notcontains
Permet de tester si une valeur se trouve dans une liste. Par exemple: $names = "val1", "val2", "val3" $names -Contains "val2"
-is et -isnot
Permet de tester le type d’une variable .NET (même opérateur qu’en C#). Par exemple: $stringToTest = "chaine de caracteres" ($stringToTest -is [System.String])
Teamcity est un serveur de build très puissant et assez flexible. Avec Jenkins et Travis, il fait partie des outils les plus utilisés pour faciliter la mise en place de pratiques d’intégration continue. Teamcity est implémenté en Java toutefois il s’adapte et peut facilement être utilisé pour de très nombreuses technologies comme, par exemple, .NET.
Contrairement à Travis et à Jenkins, Teamcity n’est pas entièrement gratuit, toutefois la licence permet de configurer gratuitement 20 configurations de builds (i.e. build configuration) et 3 agents, ce qui est suffisant pour la plupart des cas d’utilisation. Teamcity peut être installé sur Windows, Linux ou MacOS. Même si le serveur Teamcity est installé sur une machine avec un OS spécifique, il peut s’interfacer avec d’autres machines qui peuvent être dans des OS différents de façon à piloter des builds avec des technologies différentes. Un même serveur Teamcity peut donc effectuer des builds dans des technologies différentes.
Dans cet article, on se propose d’expliquer l’installation d’un serveur Teamcity. Dans un article futur, je présenterai les fonctionnalités principales de Teamcity de façon à être capable de configurer une chaine de build complète.
La documentation de Teamcity est bien faite et très complète. Le but de cet article n’est pas de paraphraser la documentation de l’éditeur mais de permettre de monter rapidement un serveur Teamcity, de comprendre rapidement les fonctionnalités les plus importantes et de se familiariser avec l’interface de Teamcity pour être capable de l’utiliser efficacement. Cet outil est facile à utiliser toutefois il possède énormément de fonctionnalités qui ne sont pas faciles à appréhender aux premiers abords.
Dans un premier temps, on indiquera une méthode pour installer un serveur Teamcity sur une machine Linux avec Docker, ensuite on configurera un build agent et enfin on indiquera quelques éléments de configuration intéressants sur le serveur de build.
L’intérêt d’installer Teamcity en utilisant l’image Docker, est d’avoir une procédure d’installation rapide qui permet une grande flexibilité puisqu’on peut facilement supprimer l’image et reprendre l’installation.
Il n’est pas obligatoire de passer par Docker pour installer Teamcity
Dans notre cas, Debian 9 (Stretch) concerne la partie “Jessie or newer” (Jessie correspond à Debian 8) dans la documentation de Teamcity.
Après l’installation, pour éviter d’exécuter l’image Docker avec l’utilisateur root, on peut créer un utilisateur simple qui aura l’autorisation d’exécuter une image Docker. Cette configuration est facultative mais permet de séparer les responsabilités.
On peut créer un utilisateur et l’ajouter au groupe docker en exécutant en tant qu’utilisateur root la comande:
On peut voir que l’utilisateur dockeruser appartient au groupe docker en exécutant:
root@debian:~% groups dockeruser
L’utilisateur dockeruser peut maintenant exécuter une commande docker.
Erreur “permission denied” quand on tente d’exécuter une image Docker
Si on tente d’exécuter une image Docker avec un utilisateur qui n’appartient pas au groupe docker, on aura une erreur du type:
Got permission denied while trying to connect to the Docker daemon socket
at unix:///var/run/docker.sock
Ceci s’explique par le fait que la lecture ou l’écriture de /var/run/docker.sock nécessite d’appartenir au groupe docker. On peut s’en rendre en compte en exécutant:
-it: permet de démarrer le processus dans le container en attachant la console de l’hôte de façon à ce que les entrées standard, les sorties standard et les erreurs de la console du container soient visibles dans la console de l’hôte.
--name <nom du container>: permet d’indiquer le nom du container dans lequel sera exécuté l’image Docker.
-v /home/dockeruser/data:/data/teamcity_server/datadir: permet de partager le contenu du répertoire /home/dockeruser/data de l’hôte avec le répertoire /data/teamcity_server/datadir du container. Le répertoire de données du container sera ainsi plus facilement accessible sur l’hôte.
-v logs:/opt/teamcity/logs: permet de partager le contenu du répertoire /home/dockeruser/logs de l’hôte avec le répertoire /opt/teamcity/logs du container. Cette option permet d’accéder facilement au répertoire de logs du container à partir de l’hôte.
-p 8111:8111: indique que le port 8111 de l’hôte sera redirigé vers le port 8111 du containerDocker.
Ouvrir un bash dans le “container”
On peut ouvrir un bash dans le containerDocker en exécutant:
Si l’image a déjà été exécutée dans un container avec le nom “teamcity-server-instance” et si on relance la commande précédente:
dockeruser@debian:~% docker run -it --name teamcity-server-instance ...
On peut obtenir une erreur du type:
docker: Error response from daemon: Conflict. The container name
"/teamcity-server-instance" is already in use by container
"ab19821b4d64fb0e221b0a2c898db1745703acb45b96d602caddc3f6b25bfa5c". You have to remove
(or rename) that container to be able to reuse that name.
See 'docker run --help'.
Cette erreur signifie que le container se nommant “teamcity-server-instance” existe déjà. Pour relancer l’exécution de ce container, il suffit d’exécuter la commande:
On peut accéder à l’interface en se connectant avec un browser à l’adresse:
http://localhost:8111
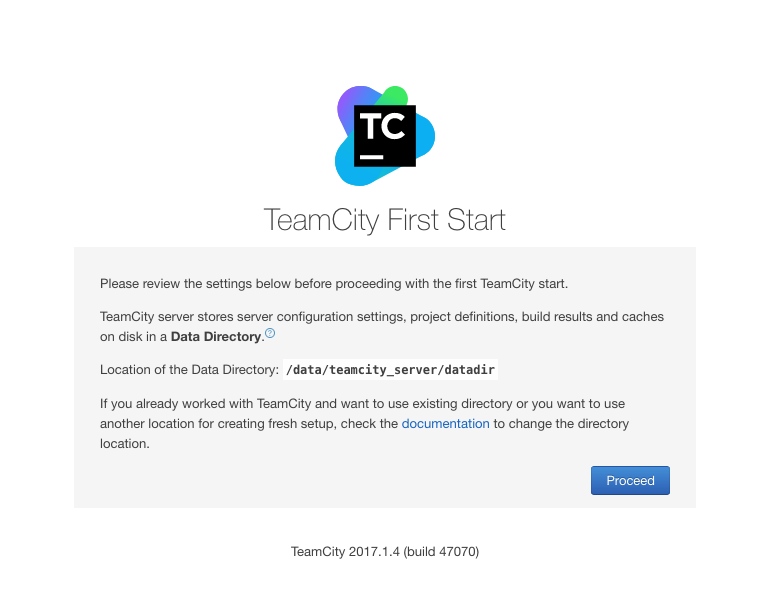
On doit obtenir un écran du type:
Teamcity First Start
En cliquant sur “Proceed”, on peut choisir un type de base de données, dans notre cas, on choisit “Internal (HSQLDB)”:
Teamcity Database connection setup
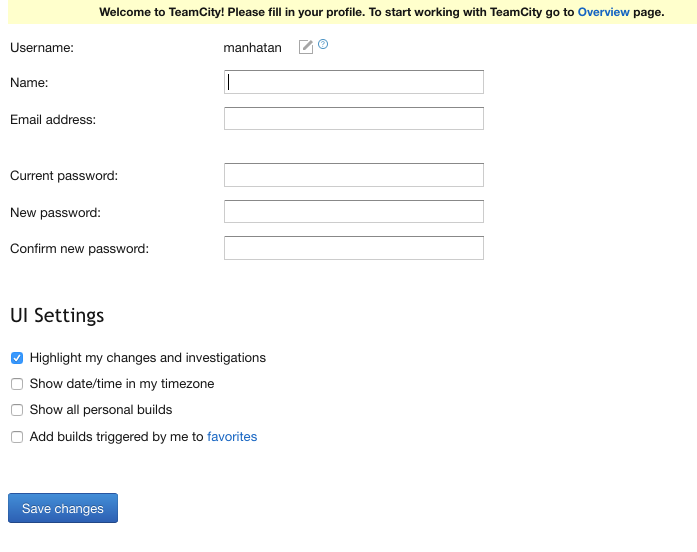
Il faut ensuite répondre à quelques questions avant d’arriver à la création d’un utilisateur avec des droits d’administrateur:
Teamcity Création administrateur
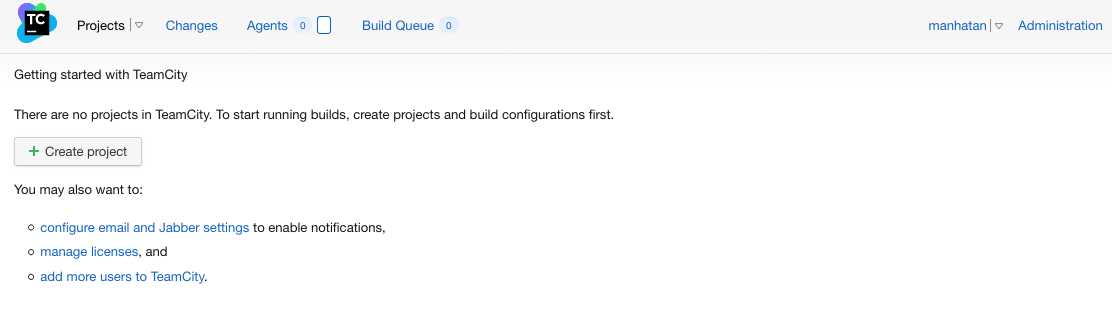
On arrive ensuite sur l’interface principale de Teamcity:
Ecran principal
Versionner la configuration de Teamcity
Teamcity a une fonctionnalité particulièrement intéressante qui permet de versionner la configuration des projets dans un gestionnaire de version (comme SVN ou Git). Cette étape est facultative. Avec cette fonctionnalité, la synchronisation se fait dans les 2 sens:
Teamcity commit lui-même les changements dans le gestionnaire de versions à chaque changement de la configuration.
Si on modifie la configuration dans le gestionnaire de versions en éditant les fichiers, Teamcity rechargera automatiquement sa configuration après le commit des modifications.
L’intérêt de cette fonctionnalité est de:
Pouvoir revenir en arrière facilement dans la configuration si on a fait une erreur,
Importer facilement une configuration sur on installe un nouveau serveur,
Voir la configuration avec des outils comme Github.
Editer directement la configuration dans les fichiers versionnés
Pour effectuer cette configuration à partir de l’interface de Teamcity, il faut cliquer sur “Administration”:
Cliquez sur “Administration”
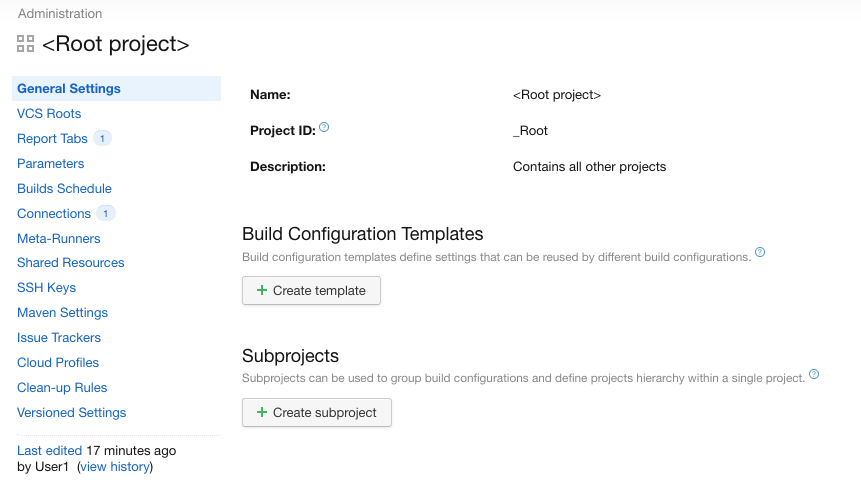
Puis sur “<Root project>”:
Cliquez sur “<Root project>”
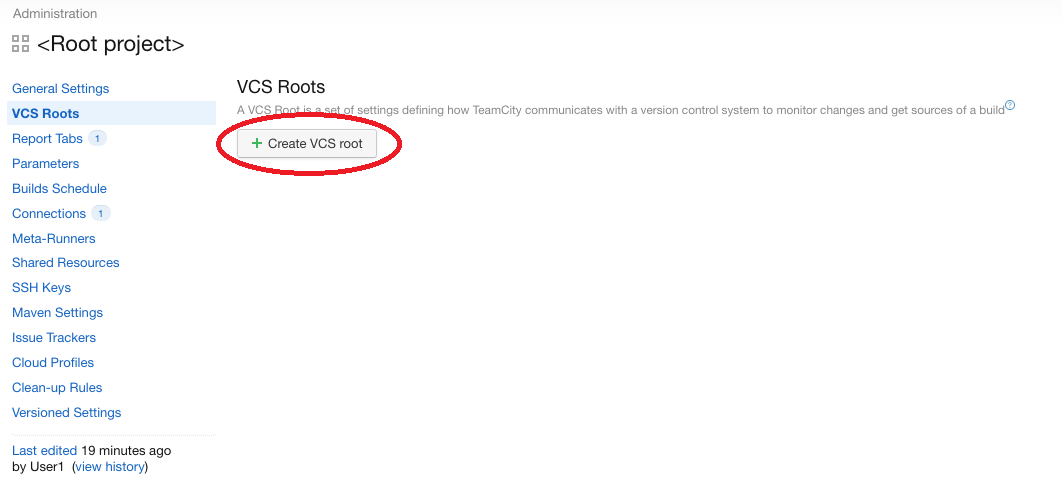
Dans le menu de gauche, il faut cliquer sur “VCS Roots” pour ajouter une configuration pour un gestionnaire de version (VCS signifie “Version Control System”):
Cliquez sur “VCS Roots”
On clique ensuite sur “Create VCS root” et on indique les paramètres d’accès au VCS:
Cliquez sur “Create VCS root”
Dans notre cas, on utilise GitHub. On a donc créé un compte sur GitHub puis un repository de façon à indiquer ces paramètres dans Teamcity.
Si à ce moment, on essaie d’effectuer un test de connexion en cliquant sur “Test connection”, on aura un message d’erreur:
Cannot find revision of the default branch 'refs/heads/master' of vcs root
"jetbrains.git" {instance id=10, parent internal id=-1, parent id=dummy_jetbrains.git,
description: "https://github.com/teamcitytest/teamcityconfig.git#refs/heads/master"}
Cette erreur est due au fait qu’il n’existe pas de branche “master” sur le repository. Pour créer une branche vide, il suffit de créer un fichier README.md sur GitHub et la branche “master” sera créée.
Ne pas confondre le versionnement de la configuration Teamcity et l’accès au “repository” d’un projet
Dans le cas présent, on a configuré un repository pour permettre de versionner la configuration de Teamcity. Le repository de la configuration est différent du repository d’un projet pour lequel on souhaiterait effectuer une build.
Le repository contenant la configuration de Teamcity est mis à jour directement par Teamcity. On peut le voir si on regarde dans GitHub dans le répertoire .teamcity.
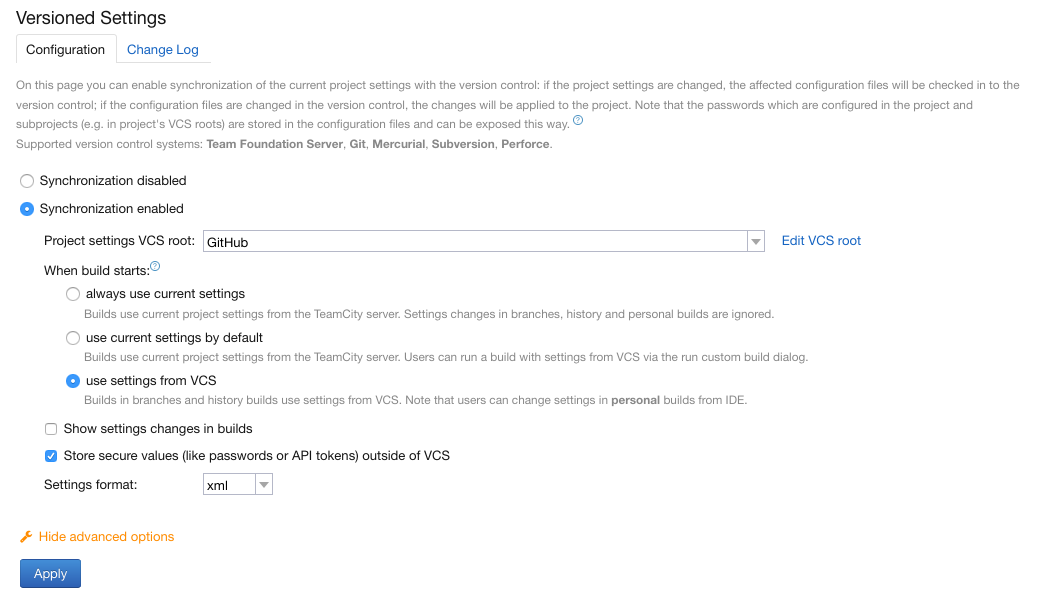
Enfin dans Teamcity, il faut indiquer à Teamcity quel est le paramétrage de gestionnaire de version qui permet de stocker la configuration. On clique donc sur “Versioned Settings” dans le menu à gauche:
Ecran “Versioned Settings”
Puis:
On sélectionne “Synchronization enabled”
On sélectionne le paramétrage de VCS Root qui correspond à la configuration,
On sélectionne “use settings from VCS”.
On valide en cliquant sur “Apply”. Ecran “Versioned Settings”
A la fin de cette étape, Teamcity effectue directement des modifications dans le repository GitHub et les commit.
Installation d’un agent Teamcity
Un agent Teamcity est une machine sur laquelle sera exécutée les différentes builds. Cette machine peut être différente de celle qui héberge le serveur Teamcity. Teamcity permet d’utiliser plusieurs agents avec des architectures différentes. L’intérêt d’avoir plusieurs agents est de:
Pouvoir effectuer des builds dans des architectures et des technologies différentes,
Paralléliser les builds sur plusieurs agents.
Avoir un seul serveur Teamcity qui s’interface avec plusieurs agents, la configuration reste ainsi centralisée.
Comme indiqué plus haut, l’agent peut se trouver sur une autre machine que celle du serveur Teamcity. Dans notre cas, pour simplifier, l’agent se trouvera sur la même machine.
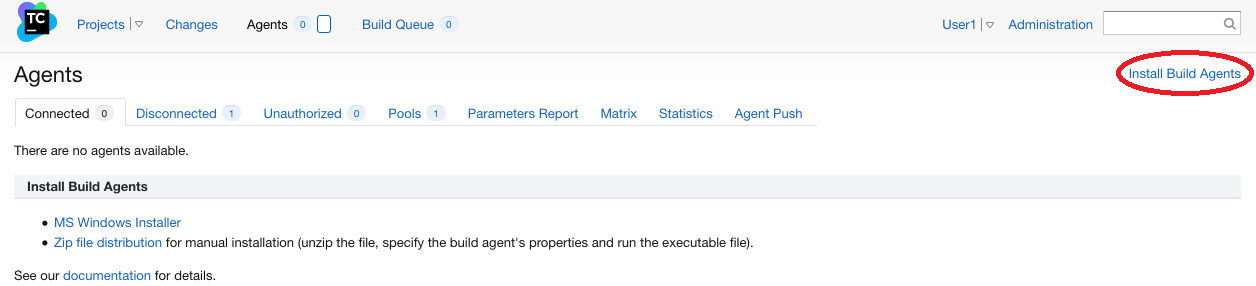
Pour installer l’agent Teamcity, il faut cliquer en haut de l’interface d’administration de Teamcity sur “Agents” puis à droite sur “Install Build Agents”:
Cliquez sur “Install Build Agents”
On télécharge le fichier correspondant à l’architecture sur laquelle on veut installer l’agent. Dans notre cas, on cliquer sur “Zip file distribution” puisqu’on souhaite installer l’agent sur une machine Linux.
On décompresse le fichier en exécutant les commandes suivantes:
dockeruser@debian:~% vi /usr/teamcity_agent/conf/buildAgent.properties
(Pour passer en mode édition dans vi, il faut appuyer sur la touche [i])
Si on installe l’agent sur une machine différente de celle sur laquelle se trouve le serveur Teamcity, il faut modifier le paramètre serverUrl pour qu’il pointe vers le serveur Teamcity:
serverUrl=http://<adresse IP du serveur Teamcity>:8111/
Dans le cas contraire, on peut laisser la valeur:
serverUrl=http://localhost:8111/
Il faut ensuite indiquer le nom de l’agent avec le paramètre name:
name=BuildAgent1
On enregistre en tapant [Echap] puis :wq.
Démarrage de l’agent
Une fois que la configuration est effectuée, on peut démarrer l’agent en exécutant:
Si le démarrage s’est effectué correctement, on devrait voir dans le fichier /usr/teamcity_agent/logs/teamcity-agent.log une phrase du type:
Updating agent parameters on the server
Ajout de l’agent à la configuration Teamcity
A la fin de l’étape précédente, après quelques secondes, l’agent doit apparaître dans l’interface de Teamcity en cliquant sur “Agents” en haut à gauche puis sur l’onglet “Unauthorized”:
Cliquez sur “Agents” puis “Unauthorized”
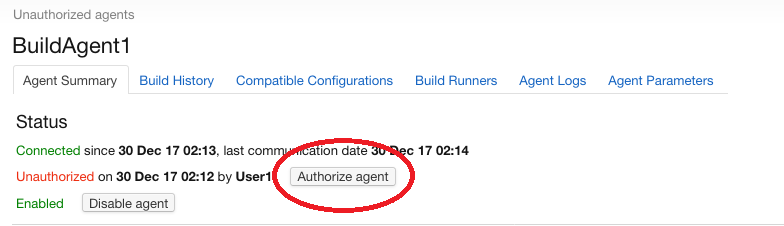
Il faut cliquer sur le nom de l’agent puis sur “Authorize agent”:
Cliquez sur “Authorize agent”
Après cette étape, l’agent est connecté avec le serveur Teamcity.
Configurer les “clean-up rules”
Ce paramétrage est particulièrement traitre dans Teamcity car, par défaut, Teamcity conserve tous les fichiers résultats des builds sur le serveur. La conservation de ces fichiers saturent rapidement la mémoire du serveur en particulier si on effectue souvent des builds et si on possède beaucoup de configurations de build.
Les “clean-up rules” sont des règles permettant d’indiquer quand supprimer ces fichiers.
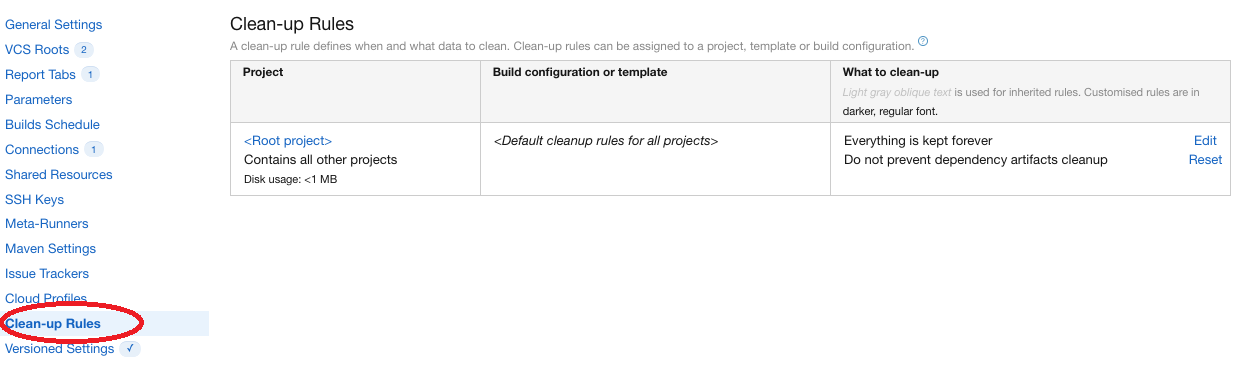
Pour accéder au paramétrage des “clean-up rules”, il faut:
Cliquer sur “Administration”
Puis cliquer sur <Root project>
Cliquer dans le menu de gauche sur “Clean-up rules” Cliquez sur “Clean-up rules”
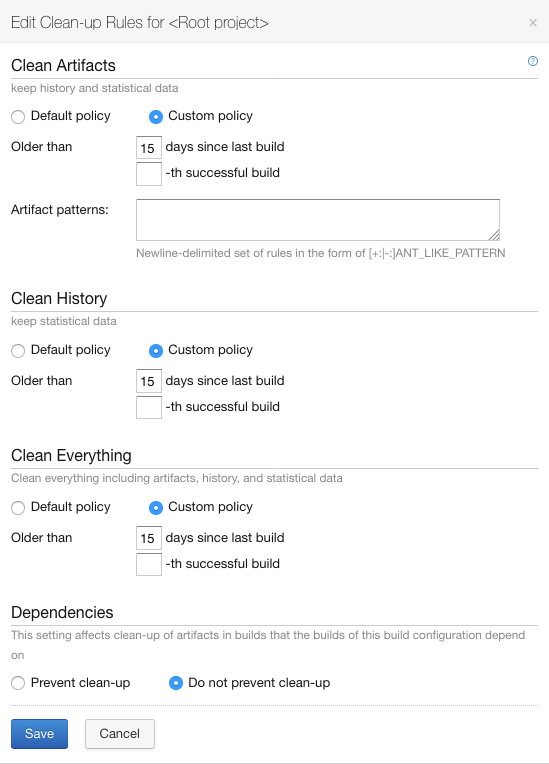
Cliquer sur “Edit” pour affecter des règles valables pour tous les projets,
Affecter des valeurs qui permettront de supprimer périodiquement les fichiers de builds, par exemple: Exemple de paramètres “Clean-Up Rules”
En conclusion
Toutes ces étapes ont permis de paramétrer un serveur Teamcity de façon à ce qu’il soit opérationnel pour exécuter des builds. Dans un prochain article, on indiquera quelles sont les fonctionnalités principales de Teamcity pour paramétrer rapidement une configuration de build dans le cadre de .NET.
L’objectif principal de l’architecture hexagonale est de découpler la partie métier d’une application de ses services techniques. Ceci dans le but de préserver la partie métier pour qu’elle ne contienne que des éléments liés aux traitements fonctionnels. Cette architecture est aussi appelée “Ports et Adaptateurs” car l’interface entre la partie métier et l’extérieur se fait, d’une part, en utilisant les ports qui sont des interfaces définissant les entrées ou sorties et d’autre part, les adaptateurs qui sont des objets adaptant le monde extérieur à la partie métier.
Dans cet article, on va dans un premier temps, expliquer plus en détails l’architecture hexagonale; comparer cette architecture avec une autre architecture moins polyvalente et enfin illustrer concrètement avec un exemple.
Avant de rentrer dans les détails de l’architecture hexagonale, on pourrait se demander ce qui justifie de devoir préserver le modèle.
Dans la plupart des logiciels, la logique métier qui est implémentée est ce qui constitue la plus grande valeur ajoutée puisque c’est cette logique qui rend le logiciel fonctionnel. Pourtant très souvent une grande part des développements se concentrent sur d’autres parties comme l’interface graphique, la persistance des données ou le partage d’informations avec des systèmes externes.
L’idée est donc de tenter de préserver ce qui représente la plus grande valeur ajoutée d’une application: la logique métier.
La première étape consiste à comprendre ce qui correspond à la logique métier et ce qui relève de processus techniques qui n’ont pas de logique fonctionnelle. Toute cette approche peut être approfondie en s’intéressant au Domain-Driven Design (ou DDD) qui donne des indications sur la façon d’arriver à isoler la logique métier.
Architecture en couches
L’architecture hexagonale préconise une version simplifiée de l’architecture en couches pour séparer la logique métier des processus techniques:
Architecture en couches de l’architecture hexagonale
La logique métier doit se trouver à l’intérieur de l’hexagone
La logique fonctionnelle ou ce que le DDD appelle le domaine doit se trouver à l’intérieur de l’hexagone. L’implémentation de ce domaine ne doit faire appel à aucun élément extérieur directement. Le but est d’isoler le domaine de l’extérieur et de définir des interfaces d’entrée et de sortie claires. L’hexagone symbolise la séparation stricte entre le code métier et le code technique.
Ainsi, le domaine doit matérialiser ses besoins, par exemple, en éléments de configuration ou en données d’entrées au moyen d’interfaces sans effectuer d’appels directs à l’extérieur. Ce sont des objets externes qui vont fournir à l’hexagone les données dont il a besoin pour effectuer le traitement fonctionnel.
Dans l’idéal, les technologies utilisées dans l’hexagone ne doivent pas avoir une empreinte trop forte sur l’implémentation de façon à ce que le code métier ne dépende pas de la technologie. Le but est de limiter l’impact de changements technologiques même majeurs sur l’implémentation de la logique fonctionnelle dans l’hexagone. Le domaine est ainsi préservé.
Inversion de dépendances
Pour fournir à l’hexagone, les éléments nécessaires à son traitement fonctionnel, on utilise l’inversion de dépendances. L’hexagone définit ses dépendances au moyen d’interface qui vont régir les entrées et sorties. L’hexagone ne fait aucun appel à l’extérieur mais expose ses interfaces au monde extérieur. Les objets du monde extérieur font des appels à l’hexagone en utilisant ces interfaces et en fournissant les objets nécessaires à son traitement.
La couche application
La couche application est la couche technique qui sépare le monde extérieur de l’hexagone. Elle permet d’adapter les éléments extérieurs à l’application pour effectuer des appels à l’hexagone. Cette couche est appelée application pourtant elle ne représente pas à elle-seule toute l’application.
Par exemple, si la couche métier dans l’hexagone a besoin d’éléments de configuration et de données se trouvant dans la base de données, c’est la couche application qui va récupérer ces éléments et les adapter en objets compréhensibles par les interfaces de l’hexagone. Il va ensuite effectuer les appels à l’hexagone, récupérer les résultats et les traduire de nouveau pour les adapter au monde extérieur.
La couche infrastructure
Cette couche est facultative, elle provient de l’approche DDD. Elle est, parfois, évoquée dans la documentation sur l’architecture hexagonale sous ce nom ou sous le nom de couche Framework. Dans certains cas, elle peut aussi être confondue avec la couche application. D’une façon générale, elle permet de traiter les communications provenant de l’extérieur et de les adresser aux adaptateurs de la couche application.
Par exemple, la couche infrastructure peut s’occuper de l’instanciation d’une SqlConnection pour effectuer des appels en base de données. La couche application, quant à elle, s’occupera de l’élaboration de requêtes SQL. Ensuite la connexion à la base de données peut être effectuée par la couche infrastructure.
Ports et adaptateurs
Ces éléments sont les plus importants de l’architecture hexagonale puisque ce sont eux qui effectuent tout le travail de traduction entre le monde extérieur et l’hexagone. Ils représentent les frontières entre le code métier dans l’hexagone et le code technique de la couche application.
Ports
Les ports sont les interfaces définies par l’hexagone pour s’interfacer avec le monde extérieur.
Il existe 2 types de port, les ports permettant d’appeler des fonctions dans l’hexagone et les ports permettant à l’hexagone d’appeler des éléments extérieurs.
Un autre élément important est que les ports (d’entrée ou de sortie) sont définis dans l’hexagone.
Ports primaires
Ce sont les ports d’entrée de l’hexagone, ce qui signifie que la couche application fait appel aux ports primaires de l’hexagone pour effectuer des traitements en utilisant des adaptateurs. L’hexagone fournit une interface sous la forme d’un port, cette interface est utilisée par un adaptateur pour appeler le traitement métier dans l’hexagone. C’est donc un objet de l’hexagone qui implémente l’interface.
Le port primaire peut être symbolisé de cette façon:
Des objets de type port primaire et adaptateur primaire pourraient être schématisés de cette façon en UML:
Diagramme UML d’un port primaire et d’un adaptateur primaire
Dans cet exemple, l’adaptateur primaire PrimaryAdapter accéde au port primaire IPrimaryPort se trouvant dans l’hexagone. C’est un objet dans l’hexagoneDomainClass qui satisfait le port IPrimaryPort.
Adaptateurs primaires
Ces adaptateurs font appel directement aux ports primaires de l’hexagone. Comme indiqué précédemment, le port est une interface définie dans l’hexagone. L’adaptateur est implémenté à l’extérieur de l’hexagone dans la couche application. L’adaptateur fait appel à l’hexagone en utilisant l’interface fournie par ce dernier.
Concrètement, on passera par un adaptateur primaire pour:
Récupérer les données provenant de l’extérieur
Les adapter pour qu’elles soient compréhensibles pour les interfaces correspondant aux ports primaires
Effectuer l’appel à l’hexagone en utilisant le port primaire et en lui fournissant les données traduites.
Un adaptateur pourrait être symbolisé de cette façon:
Ports secondaires ou plugins
Ce sont les ports de sortie de l’hexagone c’est-à-dire qu’il les utilise pour effectuer des appels vers l’extérieur. Ces ports sont aussi des interfaces définies à l’intérieur de l’hexagone toutefois l’implémentation de ces interfaces ne se trouvent pas dans l’hexagone mais à l’extérieur par des adaptateurs secondaires. Les objets implémentant les ports secondaires sont fournis à l’hexagone par inversion de dépendances.
Pour résumer, des adaptateurs implémentant les ports secondaires sont fournis à l’hexagone qui les utilise pour effectuer ses appels à l’extérieur.
Le port secondaire peut être symbolisé de cette façon:
Par exemple, des objets de type port secondaire et un adaptateur secondaire pourraient être schématisés de cette façon en UML:
Diagramme UML d’un port secondaire et d’un adaptateur secondaire
Dans cet exemple, l’adaptateur secondaire SecondaryAdapter satisfait le port secondaire ISecondaryPort se trouvant dans l’hexagone. C’est un objet dans l’hexagoneDomainPortConsumer qui accède au port secondaire.
Adaptateurs secondaires
Ces adaptateurs font appel aux ports secondaires. Contrairement aux adaptateurs primaires, ils implémentent l’interface correspondant au port secondaires. Ils sont injectés dans l’hexagone au moyen de l’inversion de dépendance. L’hexagone peut, alors, y faire appel pour effectuer des traitements.
Concrètement, on utilisera un adaptateur secondaire pour:
Permettre d’effectuer des appels vers l’extérieur de l’hexagone en fournissant à l’adaptateur des données respectant les interfaces correspondant aux ports secondaires.
L’adaptateur secondaire effectue une conversion de ces données vers un format compréhensible des objets du monde extérieur.
L’adaptateur secondaire effectue des appels au monde extérieur en utilisant les objets convertis.
Nombre de ports de l’hexagone
Dans les schémas de l’architecture hexagonale, l’hexagone est évidemment représenté avec 6 cotés laissant penser qu’il doit être composé de 6 ports. Le nombre de cotés est arbitraire et n’est pas évidemment par limité à 6.
D’une façon générale, on pourrait schématiser les différents objets intervenant dans l’architecture hexagonale et leurs interactions de cette façon:
Interactions entre les objets de l’architecture hexagonale
Avec:
Adaptateur
Port primaire
Port secondaire
Pourquoi utiliser l’architecture hexagonale ?
Après avoir présenté l’architecture hexagonale, on pourrait se demander ce qui justifie d’utiliser cette architecture.
Testabilité
Quand Alistair Cockburn a inventé l’architecture hexagonale en 2005, il cherchait à créer une application testable. Ce type d’architecture répond à ce besoin puisqu’elle permet d’isoler le modèle et d’identifier toutes les entrées et sorties de ce dernier. D’autre part, l’injection de dépendances permet de maîtriser les objets qui seront utilisés par le modèle pour s’interfacer avec l’extérieur. On peut donc facilement injecter des “mock” des adaptateurs et tester complètement le modèle.
Préserver le modèle
Un des objectifs de l’architecture hexagonale est de permettre au modèle de s’affranchir des couches techniques car elles peuvent être amenées à évoluer rapidement. Les adaptateurs sont des objets tampons entre le modèle et le monde extérieur, ainsi ce sont eux qui sont modifiés dans le cas où un élément du monde extérieur l’exige. Le modèle n’est modifié que si la logique métier l’exige. Ainsi l’intérieur de l’hexagone est préservé des changements techniques, on préserve ainsi le modèle.
Comparaison avec l’architecture 3-tiers
Pour se rendre compte de l’intérêt de l’architecture hexagonale, on pourrait la comparer brièvement à l’architecture 3-tiers.
L’architecture 3-tiers a été utilisée très fréquemment il y a une dizaine d’années car elle permettait une séparation franche des responsabilités. Les applications utilisant ce type d’architecture étaient séparées en 3 couches:
La couche présentation: elle concerne la technologie et la logique liées à l’interface graphique. Pour les traitements plus fonctionnels, la couche présentation fait appel à la couche métier.
La couche métier: cette couche abrite la logique métier et mets à disposition de la couche graphique des fonctions et des objets permettant la sauvegarde et la lecture de données. Toutefois elle ne se charge pas directement du stockage ou de la lecture des données. La couche métier s’interface avec la couche présentation et la couche persistance. Pour le stockage et la lecture des données, la couche métier fera appel à la couche persistance
La couche persistance: cette couche se charge de lire et d’écrire les données en base. En principe cette couche ne doit pas contenir de logique métier même si très souvent, une part de cette logique se trouve codée dans les contraintes de base de données relationnelles ou dans des procédures stockées. Cette couche ne s’interface qu’avec la couche métier. Elle est très dépendante de la technologie de la base de données.
Diagramme de l’architecture 3-tiers
Le plus souvent, les utilisateurs effectuent des manipulations sur l’interface graphique. Ces manipulations se traduisent par des appels de fonctions dans la couche présentation qui fait elle-même appel à la couche métier qui, par suite, appelle la couche persistance.
Cette architecture convenait bien dans le cas où les points d’entrée de l’application ne se trouvaient que sur l’interface graphique. Il n’y avait, aussi, qu’une seule façon de stocker des données: soit un stockage en mémoire, soit une persistance dans une base de données. Quoi qu’il en soit, généralement l’architecture restait figée et les nouvelles fonctionnalités ne nécessitaient pas de devoir modifier l’interfaçage entre les couches ou de créer de nouvelles couches.
L’architecture 3-tiers s’est révélée inadaptée à partir du moment où il a été nécessaire d’interfacer l’application avec des multiples technologies. Par exemple, la récupération ou le stockage de données ne passent pas forcément par une base de données mais il peut s’agir d’un service REST, d’un bus de communications, d’une base orientée document etc… La couche persistance devient donc multiple.
D’autre part, les entrée et les sorties de l’application sont plus complexes et ne se font pas uniquement à partir de l’interface graphique.
L’architecture hexagonale s’avère bien plus adaptée pour appréhender la complexité liée à l’utilisation de technologies très différentes. En effet, il n’y a pas qu’une seule couche de persistance mais il y a de multiples objets extérieurs qui appellent ou sont appelés par un adaptateur. Enfin, tous ces objets sont traités sur le même plan d’égalité: la couche présentation devient une couche au même niveau que la couche persistance.
Mise en situation
Pour illustrer l’architecture hexagonale, on se propose d’implémenter un exemple avec les différents types d’adaptateurs et de ports. L’outil que l’on souhaite implémenter permet de déterminer le nombre de pizzas nécessaires en fonction du type de pizza et du nombre de personnes. L’utilisateur indique les informations suivantes:
Nombre de personnes
Type de pizza
L’outil réponds ensuite le nombre entier de pizza nécessaire pour rassasier tout le monde. Arbitrairement on considère qu’une pizza est composée de 6 parts et que tout le monde mange le même type de pizza.
La partie métier de cet outil effectue les étapes suivantes:
Récupère le nombre de personnes et le type de pizza,
Interroge un repository pour obtenir le nombre moyen de parts de pizza nécessaires pour rassasier une personne en fonction du type de pizza.
Calcule le nombre de parts nécessaires pour le nombre de personnes
Renvoie le résultat.
Comme indiqué plus haut, la partie métier correspond à l’intérieur de l’hexagone.
Le code complet de cet exemple se trouve sur Github.
Implémentation de l’hexagone
On va commencer par définir les ports de l’hexagone:
Un port primaire: IPizzaCalculator qui peut être utilisé par des adaptateurs primaires pour interroger la partie métier de l’application. Dans notre cas, cette interface servira à récupérer le nombre de pizzas nécessaires.
Un port secondaire: IPizzaRepository qui doit être implémenté par les adaptateurs secondaires. Les objets satisfaisant IPizzaRepository sont utilisés par la partie métier pour récupérer la liste des statistiques permettant de connaître le nombre moyen de parts nécessaires pour rassasier une personne en fonction du type de pizza.
Port primaire
On définit l’interface IPizzaCalculator de cette façon:
L’implémentation est:
public interface IPizzaCalculator
{
int GetPizzaCount(uint personCount, PizzaKind pizzaKind);
}
public enum PizzaKind
{
Regina,
Vegetarian,
Pepperoni
}
Port secondaire
On définit ensuite IPizzaRepository:
L’implémentation est:
public interface IPizzaRepository
{
IEnumerable<PizzaStat> GetPizzaStatistics();
}
public class PizzaStat
{
public PizzaKind PizzaKind { get; set; }
public int AverageSliceCount { get; set; }
}
IPizzaCalculator doit être implémentée par la fonction métier se trouvant à l’intérieur de l’hexagone.
Dans une démarche TDD, on se propose d’implémenter quelques tests pour vérifier le comportement des fonctions à l’intérieur de l’hexagone. Voici l’implémentation de ces tests:
[TestClass]
public class PizzaCalculatorTests
{
private Mock<IPizzaRepository> repositoryMock;
[TestInitialize]
public void Initialize()
{
this.repositoryMock = new Mock<IPizzaRepository>();
var pizzaStats = new List<PizzaStat>{
new PizzaStat { PizzaKind = PizzaKind.Regina, AverageSliceCount = 6},
new PizzaStat { PizzaKind = PizzaKind.Pepperoni, AverageSliceCount = 4},
new PizzaStat { PizzaKind = PizzaKind.Vegetarian, AverageSliceCount = 7},
};
this.repositoryMock.Setup(r => r.GetPizzaStatistics()).Returns(pizzaStats);
}
[TestMethod]
public void When_Requesting_PizzaCount_For_One_Person_Then_PizzaCalculator_Shall_Return_Proper_Pizza_Count(
{
var pizzaCalculator = new PizzaCalculator(this.repositoryMock.Object);
int pizzaCount = pizzaCalculator.GetPizzaCount(1, PizzaKind.Regina);
Assert.AreEqual(1, pizzaCount);
pizzaCount = pizzaCalculator.GetPizzaCount(1, PizzaKind.Pepperoni);
Assert.AreEqual(1, pizzaCount);
pizzaCount = pizzaCalculator.GetPizzaCount(1, PizzaKind.Vegetarian);
Assert.AreEqual(2, pizzaCount);
}
[TestMethod]
public void When_Requesting_PizzaCount_For_Several_Persons_Then_PizzaCalculator_Shall_Return_Proper_Pizza_Count()
{
var pizzaCalculator = new PizzaCalculator(this.repositoryMock.Object);
int pizzaCount = pizzaCalculator.GetPizzaCount(3, PizzaKind.Regina);
Assert.AreEqual(3, pizzaCount);
pizzaCount = pizzaCalculator.GetPizzaCount(3, PizzaKind.Pepperoni);
Assert.AreEqual(2, pizzaCount);
pizzaCount = pizzaCalculator.GetPizzaCount(3, PizzaKind.Vegetarian);
Assert.AreEqual(4, pizzaCount);
}
}
L’intérêt d’implémenter les tests est de montrer que la partie métier peut être testée puis développée séparément des adaptateurs qui constituent la couche technique de l’application.
On implémente ensuite la classe PizzaCalculator qui satisfait IPizzaCalculator et qui correspond à la partie métier de l’application:
Son implémentation est:
public class PizzaCalculator : IPizzaCalculator
{
private const double sliceCountPerPizza = 6;
private IPizzaRepository pizzaRepository;
public PizzaCalculator(IPizzaRepository pizzaRepository)
{
this.pizzaRepository = pizzaRepository;
}
public int GetPizzaCount(uint personCount, PizzaKind pizzaKind)
{
var pizzaStats = this.pizzaRepository.GetPizzaStatistics();
var foundPizzaStat = pizzaStats.FirstOrDefault(s => s.PizzaKind.Equals(pizzaKind));
if (foundPizzaStat == null)
{
throw new InvalidOperationException("Type de pizza inconnu");
}
double pizzaCount = ((double)foundPizzaStat.AverageSliceCount * personCount)/sliceCountPerPizza;
return (int)Math.Ceiling(pizzaCount);
}
}
Maintenant que l’intérieur de l’hexagone est implémenté, on va implémenter les adaptateurs de la couche application.
Adaptateur primaire
On commence pour un adaptateur primaire qui permet de fournir des informations comme le nombre de personnes et le type de pizza choisie à partir de la Console. Cet adaptateur utilise directement le port primaire de l’hexagoneIPizzaCalculator. Le nom de cet adaptateur primaire est ConsoleAdapter:
L’implémentation de ConsoleAdapter est:
public class ConsoleAdapter
{
private IPizzaCalculator pizzaCalculator;
public ConsoleAdapter(IPizzaCalculator pizzaCalculator)
{
this.pizzaCalculator = pizzaCalculator;
}
public void LaunchPizzaCalculation()
{
Console.WriteLine("Entrez le nombre de personnes: ?");
uint personCount = uint.Parse(Console.ReadLine());
Console.WriteLine(@"Entrez le type de pizza:
1-Vegetarian
2-Peperoni
3-Regina");
int pizzaKindAsInt = int.Parse(Console.ReadLine());
PizzaKind pizzaKind;
switch (pizzaKindAsInt)
{
case 1:
pizzaKind = PizzaKind.Vegetarian;
break;
case 2:
pizzaKind = PizzaKind.Pepperoni;
break;
case 3:
pizzaKind = PizzaKind.Regina;
break;
default:
throw new InvalidOperationException("Le type de pizza n'a pas été compris");
}
int pizzaCount = this.pizzaCalculator.GetPizzaCount(personCount, pizzaKind);
Console.WriteLine("Il faudra {0} pizza(s).", pizzaCount);
}
}
Adaptateur secondaire
On implémente ensuite un adaptateur secondaire de façon à récupérer les informations de statistique sur les pizzas. L’adaptateur secondaire doit satisfaire le port secondaire IPizzaRepository. Cet adaptateur sera utilisé par la fonction métier de l’hexagone. Le nom de cet adaptateur est RepositoryAdapter:
L’implémentation de RepositoryAdapter est:
public class RepositoryAdapter : IPizzaRepository
{
private readonly List<PizzaStat> pizzaStats = new List<PizzaStat>{
new PizzaStat { PizzaKind = PizzaKind.Regina, AverageSliceCount = 6},
new PizzaStat { PizzaKind = PizzaKind.Pepperoni, AverageSliceCount = 4},
new PizzaStat { PizzaKind = PizzaKind.Vegetarian, AverageSliceCount = 7},
};
public IEnumerable<PizzaStat> GetPizzaStatistics()
{
return this.pizzaStats;
}
}
Pour exécuter cet exemple, on doit d’abord instancier l’adaptateur secondaire RepositoryAdapter qui sera injecté dans l’hexagone. On instancie, ensuite, l’hexagone lui-même. En dernier, on instancie l’adaptateur primaire ConsoleAdapter qui utilisera l’hexagone:
static void Main(string[] args)
{
// Adaptateur secondaire
var repositoryAdapter = new RepositoryAdapter();
// Instanciation de l'hexagone et injection de l'adaptateur secondaire
var pizzaCalculator = new PizzaCalculator(repositoryAdapter);
// Adaptateur primaire
var consoleAdapter = new ConsoleAdapter(pizzaCalculator);
consoleAdapter.LaunchPizzaCalculation();
}
Tests des adaptateurs
Il n’y a pas de tests pour les adaptateurs toutefois ils doivent être testés de la même façon que l’intérieur de l’hexagone.
Le code complet de cet exemple se trouve sur Github.
Le diagramme UML de cet exemple est:
Diagramme UML de PizzaCalculator
Dans cet exemple, si on change d’adaptateur, qu’on rajoute de nouveaux adaptateurs ou qu’on remplace ConsoleAdapter ou RepositoryAdapter, le domaine métier n’est pas impacté. A partir du moment où les nouveaux adaptateurs satisfont ou utilisent les ports définis dans le domaine, le code à l’intérieur de l’hexagone ne change pas. C’est l’intérêt de l’architecture hexagonale qui permet de préserver le domaine métier.
Inconvénients de l’architecture hexagonale
Anemic Domain Model
L’architecture hexagonale a beaucoup d’avantages et donne une grande flexibilité, toutefois elle ne convient pas dans toutes les situations. Outre la testabilité, un des objectifs de cette architecture est de permettre d’isoler et de préserver le domaine métier. Dans une application, il peut ne pas y avoir de domaine métier.
Par exemple, si une application ne sert qu’à afficher des données qu’elle récupère d’une ou plusieurs sources. S’il n’y a pas une logique de tri mais simplement une transformation des données pour les afficher, il n’y a pas réellement de domaine métier ou de règles fonctionnelles. Il n’y a donc pas forcément une grande nécessité de préserver des règles métier. Dans ce cas, l’utilisation d’une architecture de type hexagonale peut paraître superflue, voir elle peut amener une complexité complètement inutile.
Isoler un domaine métier qui ne comporte pas de logique fonctionnelle peut amener à développer ce que Martin Fowler avait qualifié d’Anemic Domain Model.
Les frontières du domaine restent floues
On a pu le voir dans l’exemple, les frontières du domaine ne sont pas franches, la séparation reste floue. C’est donc au développeur d’être vigilant et de savoir où il doit implémenter ses ports ou ses adaptateurs ce qui sous-entend une bonne compréhension de l’architecture d’un projet par toute l’équipe. Il faut avoir en tête que cette compréhension ne sera pas tout à fait la même pour tous les membres d’une équipe. Il faut donc marquer de façon plus franche les frontières du domaine, par exemple, en mettant les objets du domaine dans une assembly séparée.
Framework d’injection de dépendances
Dans un projet de grande taille et avec beaucoup d’objets, la quantité d’objets et les liens entre ces objets, peuvent s’avérer compliqués à appréhender. Il est donc préférable, dès le début du projet d’utiliser un framework d’injection de dépendances. Ce framework permettra une instanciation adaptée pour tous les objets en prenant en compte leur interactions et dépendances. De plus, il aidera, au moment d’enregistrer les différents objets, à séparer de façon plus franche les objets du domaine, des adaptateurs et plus généralement du monde extérieur.
En conclusion…
Pour conclure, on peut retenir que l’architecture hexagonale est une façon simple de séparer son domaine fonctionnel d’objets plus techniques destinés aux interactions entre l’extérieur et son application. Ce type d’architecture reste facile à mettre en œuvre et permet une plus grande flexibilité et une plus grande testabilité que des architectures plus monolithiques comme l’architecture 3-tiers. Enfin, ce type d’architecture implique la présence d’un domaine métier à préserver, s’il n’y en a pas son utilisation devient inutil.
Lorsqu’on intervient sur du code existant, la plupart du temps, on manipule des objets sous leur forme générique, par l’intermédiaire de classes abstraites ou d’interfaces. Dans la majorité des cas, les membres exposés par la classe abstraite ou par l’interface suffisent à utiliser l’objet en faisant appel à des fonctions ou des données membres. Toutefois, dans certains cas on peut avoir la nécessité d’accéder à un membre plus spécifique qui n’est pas exposé.
Une solution directe consisterait à caster l’objet vers le type spécifique de façon à utiliser le membre spécifique. Cette solution répond au problème mais elle amène la classe consommatrice à avoir une connaissance du type précis de l’objet alors que l’objet est exposé sous une forme générique. Dans la plupart des cas, cette solution est peu satisfaisante.
Cet article tente d’apporter une solution à ce problème en exposant une méthode générale. Il existe certainement de nombreuses autres méthodes. A défaut de convenir à toutes les situations, la méthode exposée tente de montrer qu’il est possible de résoudre ce problème sans passer par un cast explicite.
Le code source présenté dans cet article se trouve sur GitHub
Mise en situation
Pour illustrer la problématique, imaginons dans un premier temps, une application dont le but est de récupérer des informations à partir d’une page web. Pour configurer cette application, on injecte un objet de configuration générique qui expose quelques membres permettant d’accéder à la page web. La classe effectuant la récupération des informations en utilisant la configuration sera appelée la classe cliente.
L’interface exposant les éléments de configuration peut être définie de cette façon:
L’implémentation de IConnectionConfiguration est:
public interface IConnectionConfiguration
{
string Name { get; }
string Address { get; }
string Port { get; }
}
ConnectionConfiguration est un objet satisfaisant IConnectionConfiguration:
La définition de IConnectionConfiguration est:
public class ConnectionConfiguration : IConnectionConfiguration
{
public string Name { get; }
public string Address { get; }
public string Port { get; }
}
L’objet IConnectionConfiguration est utilisé dans toute l’application et suffit dans la plupart des cas d’utilisation.
On veut étendre les fonctionnalités de l’application et permettre qu’une instance de cette application fonctionne en récupérant des informations à partir d’une base de données. L’objet IConnectionConfiguration devient insuffisant car il n’expose pas d’éléments relatifs à la base de données comme:
Le nom d’une base de données
L’identifiant de connexion,
Un mot de passe
On crée alors la nouvelle interface IDatabaseConfiguration pour exposer des éléments de configuration plus spécifiques à la base de données:
La classe DatabaseConfiguration satisfait IDatabaseConfiguration:
L’implémentation de DatabaseConfiguration est:
public class DatabaseConfiguration : ConnectionConfiguration, IDatabaseConfiguration
{
public string DatabaseName { get; set; }
public string UserId { get; set; }
public string Password { get; set; }
}
De la même façon, l’objet de type IDatabaseConfiguration est injecté dans l’application.
On étend davantage les fonctionnalités de l’application et on cherche à permettre à une instance d’effectuer des connexions vers un service REST. D’autres éléments de configuration sont nécessaires:
Méthode HTTP utilisée: POST, GET, PUT ou DELETE
Format utilisé: JSON ou XML.
L’interface IRestServiceConfiguration permet d’exposer des éléments de configuration spécifiques au service REST:
On définit ensuite la classe RestServiceConfiguration satisfaisant IRestServiceConfiguration:
L’implémentation de RestServiceConfiguration est:
public class RestServiceConfiguration: ConnectionConfiguration, IRestServiceConfiguration
{
public string RestMethod { get; set; }
public string RestFormat { get; set; }
}
L’objet de configuration visible dans toute l’application est IConnectionConfiguration. Cependant:
Pour l’instance de la classe cliente s’interfaçant avec une base de données, on veut que le module de connexion à la base puisse accéder aux membres de IDatabaseConnectionConfiguration.
Pour l’instance s’interfaçant avec un service REST, on veut que le module de connexion au service REST accède aux membres de IRestServiceConfiguration.
On peut définir l’interface IClient commune correspondant aux objets qui doivent récupérer des données auprès de la base de données et du service REST de cette façon:
L’implémentation de IClient est:
public interface IClient
{
IData FetchData(IConfigurationHandler configurationHandler);
}
La définition de IData n’a pas d’importance:
public interface IData {}
On définit la classe FetchedData satisfaisant IData:
public class FetchedData : IData {}
L’implémentation de la classe consommant la configuration qui satisfait IClient et se connecte à la base de données pourrait être:
public class DatabaseClient: IClient
{
public IData FetchData(IConnectionConfiguration configuration)
{
// On souhaite obtenir les informations de connexion spécifiques à la
// base de données dans l'objet 'configuration'
...
// Le reste de l'implémentation n'a pas d'importance
// il consiste à se connecter à la base de données et à récupérer
// des données
return new FetchedData();
}
}
De la même façon, la classe s’interfaçant avec le service REST satisfaisant IClient peut s’implémenter de cette façon:
public class RestServiceClient: IClient
{
public IData FetchData(IConnectionConfiguration configuration)
{
// On souhaite obtenir les informations de connexion spécifiques au
// service REST dans l'objet 'configuration'
...
// Le reste de l'implémentation n'a pas d'importance
// il consiste à se connecter à la base de données et à récupérer
// des données
return new FetchedData();
}
}
Maintenant que les bases du problèmes sont posées, essayons de trouver une solution pour récupérer les éléments de configuration dans les fonctions FetchData() des classes clientes DatabaseClient et RestServiceClient:
1ère solution: effectuer un “cast”
Comme indiqué plus haut, la solution la plus directe est d’effectuer un cast et de pouvoir accéder directement aux membres plus spécifiques.
Par exemple pour la classe s’interfaçant avec la base de données:
public class DatabaseClient: IClient
{
public IData FetchData(IConnectionConfiguration configuration)
{
// On effectue le "cast"
IDatabaseConfiguration databaseConfiguration =
configuration as IDatabaseConfiguration;
// On accède aux éléments de configuration communs:
string name = databaseConfiguration.Name;
string address = databaseConfiguration.Address;
string port = databaseConfiguration.Port;
// On accède aux éléments de configuration spécifiques à la base de données:
string databaseName = databaseConfiguration.DatabaseName;
string userId = databaseConfiguration.UserId;
string password = databaseConfiguration.Password;
// Le reste de l'implémentation n'a pas d'importance
// il consiste à se connecter à la base de données et à récupérer
// des données
return new FetchedData();
}
}
De la même façon pour la classe s’interfaçant avec le service REST:
public class RestServiceClient: IClient
{
public IData FetchData(IConnectionConfiguration configuration)
{
// On effectue le "cast"
IRestServiceConfiguration restServiceConfiguration =
configuration as IRestServiceConfiguration;
// On accède aux éléments de configuration communs:
string name = restServiceConfiguration.Name;
string address = restServiceConfiguration.Address;
string port = restServiceConfiguration.Port;
// On accède aux membres spécifiques au service REST:
string restMethod = restServiceConfiguration.RestMethod;
string format = restServiceConfiguration.Format;
// Le reste de l'implémentation n'a pas d'importance
// il consiste à se connecter à la base de données et à récupérer
// des données
return new FetchedData();
}
}
Le cast est une solution rapide mais elle pose de nombreux problèmes:
Les classes clientes doivent connaître le type précis de l’objet vers lequel le cast doit être effectué. Dans le cas de DatabaseClient c’est IDatabaseConnectionConfiguration et dans le cas de RestServiceClient c’est IRestServiceConfiguration.
Le type de destination du cast est écrit en dur dans chaque classe cliente. En cas de modification du type des objets IDatabaseConnectionConfiguration et IRestServiceConfiguration, il faudra modifier l’implémentation du cast, ce qui est contraire au principe ouvert/fermé de SOLID.
Si le type IDatabaseConnectionConfiguration ne dérive plus IConnectionConfiguration, la compilation ne va pas échouer. C’est seulement à l’exécution qu’on se rendra compte que le cast n’est plus possible ce qui peut introduire des risques de régressions.
Enfin si d’autres classes consomment les objets IDatabaseConnectionConfiguration ou IRestServiceConfiguration de la même façon, elles devront aussi effectuer un cast pour les atteindre à partir de IConnectionConfiguration. On dupliquera alors dans toutes les autres classes le cast ce qui est contraire au principe DRY.
Pour toutes ces raisons, on se propose de chercher une autre solution plus satisfaisante.
2e solution: encapsuler le “cast”
Pour éviter les problèmes de duplication du code correspondant au cast, on peut encapsuler le code effectuant le cast dans une classe qui aura pour but de consommer la configuration. Le pattern Bridge semble être adapté pour effectuer cette modification.
Le design pattern Bridge
Bridge est un pattern permettant de découpler l’interface d’une classe de son implémentation. Ainsi si l’implémentation change, l’interface appelée ne changera pas.
Le pattern Bridge ajoute un objet intermédiaire entre l’objet appelant et l’objet appelé pour découpler l’interface de l’objet appelé de son implémentation.
Ainsi si on considère les objets suivants:
Diagramme théorique de Bridge
Ainsi:
IGenericCalledObject: est l’interface générique appelée par la classe cliente. La classe cliente ne voit que cette interface.
RefinedCalledObject: il s’agit de l’objet qui va appeler concrètement l’objet à découpler. Cette objet n’est pas visible de la classe cliente. C’est lui qui a la connaissance de l’objet qui sera appelé.
IAbstractImplementation: c’est l’interface de l’objet concret possédant l’implémentation à appeler. IAbstractImplementation est visible de l’objet RefinedCalledObject.
ConcreteImplementation: c’est l’objet possédant l’implémentation à appeler. Il n’est, en principe, visible par aucun des autres objets de façon à ce qu’il soit facilement interchangeable.
Le pattern Bridge s’utilise dans le cas où l’implémentation de l’objet ConcreteImplementation change fréquemment et qu’il soit nécessaire de changer la classe ConcreteImplementation. Dans notre cas, on utilise ce pattern pour découpler l’implémentation concrète de l’interface consommée par la classe appelante.
Ainsi, dans le cas de notre exemple de départ, on introduit un nouvel objet qui va correspondre à l’interface générique IGenericCalledObject. L’objet est ConfigurationHandler satisfaisant IConfigurationHandler:
On définit ensuite l’objet correspondant à RefinedCalledObject. C’est l’objet qui va appeler les membres se trouvant dans les objets de configuration, il doit satisfaire IConfigurationHandler:
public class ConfigurationHandler : IConfigurationHandler
{
public ConfigurationHandler(
IConnectionConfiguration databaseConfiguration,
IConnectionConfiguration restServiceConfiguration)
{
this.DatabaseConfiguration = databaseConfiguration as IDatabaseConfiguration;
this.RestServiceConfiguration = restServiceConfiguration as
IRestServiceConfiguration;
}
public IDatabaseConfiguration DatabaseConfiguration { get; private set; }
public IRestServiceConfiguration RestServiceConfiguration { get; private set; }
}
Par suite, les interfaces IDatabaseConfiguration et IRestServiceConfiguration correspondent à l’interface IAbstractImplementation du pattern Bridge défini plus haut.
De même les classes DatabaseConnectionConfiguration et RestServiceConfiguration correspondent à la classe ConcreteImplementation du pattern Bridge.
Du point de vue des classes clientes
Si on cherche à obtenir la configuration à partir des classes clientes, en reprenant le code de ces classes, on utilise IConfigurationHandler pour récupérer les éléments de configuration spécifiques:
public class DatabaseClient: IClient
{
public IData FetchData(IConfigurationHandler configurationHandler)
{
// On accède aux éléments de configuration communs:
string name = configurationHandler.DatabaseConfiguration.Name;
string address = configurationHandler.DatabaseConfiguration.Address;
string port = configurationHandler.DatabaseConfiguration.Port;
// On accède aux éléments de configuration spécifiques à la base de données:
string databaseName = configurationHandler.DatabaseConfiguration.DatabaseName;
string userId = configurationHandler.DatabaseConfiguration.UserId;
string password = configurationHandler.DatabaseConfiguration.Password;
// Le reste de l'implémentation n'a pas d'importance
// il consiste à se connecter à la base de données et à récupérer
// des données
return new FetchedData();
}
}
Et:
public class RestServiceClient: IClient
{
public IData FetchData(IConfigurationHandler configurationHandler)
{
// On accède aux éléments de configuration communs:
string name = configurationHandler.RestServiceConfiguration.Name;
string address = configurationHandler.RestServiceConfiguration.Address;
string port = configurationHandler.RestServiceConfiguration.Port;
// On accède aux membres spécifiques au service REST:
string restMethod = configurationHandler.RestServiceConfiguration.RestMethod;
string format = configurationHandler.RestServiceConfiguration.Format;
// Le reste de l'implémentation n'a pas d'importance
// il consiste à se connecter à la base de données et à récupérer
// des données
return new FetchedData();
}
}
On remarque que le cast n’est plus effectué dans les classes clientes mais dans ConfigurationHandler. Les classes clientes ne voient que l’interface IConfigurationHandler. Cette implémentation permet de résoudre quelques inconvénients de la 1ère solution:
Il n’y pas plus de duplication de code correspondant au cast. Les casts sont effectués seulement dans la classe ConfigurationHandler.
Les classes clientes ne sont plus obligées de connaître le type précis vers lequel le cast doit être effectué. Elles n’ont plus la connaissance de ce type. Cette connaissance est contenue dans une seule classe: ConfigurationHandler.
Tous les problèmes ne sont pas résolus pour autant car si une modification amène à ne plus faire dériver le type IDatabaseConfiguration de IConnectionConfiguration, la compilation ne va pas échouer. De la même façon que pour la 1ère solution, c’est à l’exécution qu’on se rendra compte que le cast n’est pas possible.
Ce dernier problème amène à devoir trouver une solution pour éliminer le cast.
3e solution: éliminer le “cast” en utilisant Visiteur
On cherche à éliminer le cast en appliquant un comportement particulier aux classes clientes en fonction du type de configuration qu’elles veulent consommer. On veut ensuite garantir que la configuration consommée appliquera tous les éléments de configuration qui lui sont spécifiques.
Par exemple, dans le cas de la classe cliente DatabaseClient, on veut que le comportement soit spécifique à la configuration de la base de données. On souhaite ensuite que tous les paramètres gérés par IDatabaseConfiguration soient appliqués quand cette objet est consommé.
Le pattern Visiteur paraît adapté pour permettre d’appliquer ce comportement. Ainsi:
Les classes visitées sont les classes clientes car ce sont elles qui consomment les éléments de configuration. En effet ces classes vont consommer chaque élément de configuration de façon spécifique.
Les classes visiteur correspondent aux classes détenant la configuration car ce sont elles qui savent quels sont les éléments de configuration à paramétrer.
Le diagramme correspondant à Visiteur est:
Diagramme théorique de Visiteur
Dans notre cas:
DatabaseClient et RestServiceClient sont les classes visitées et
IDatabaseConfiguration et IRestServiceConfiguration sont les objets visiteur.
On définit les interfaces IDatabaseConfigurationConsumer et IRestServiceConfigurationConsumer qui vont servir de base pour implémenter le pattern Visiteur. On perfectionne l’interface IConnectionConfiguration en rajoutant les méthodes:
VisitDatabaseConfigurationConsumer(IDatabaseConfigurationConsumer configurationConsumer): permettant d’obtenir la configuration pour la base de données
VisitRestServiceConfigurationConsumer(IRestServiceConfigurationConsumer configurationConsumer): pour obtenir la configuration pour le service REST.
Application de Visiteur
L’interface IDatabaseConfigurationConsumer qui désigne la classe visitée qui doit consommer la configuration correspondant à la base de données se définit de cette façon:
public interface IDatabaseConfigurationConsumer
{
void AcceptConfiguration(IDatabaseConfiguration configuration);
}
De même, on définit l’interface IRestServiceConfigurationConsumer qui désigne la classe visitée qui doit consommer la configuration correspondant au service REST:
public interface IRestServiceConfigurationConsumer
{
void AcceptConfiguration(IRestServiceConfiguration configuration);
}
On définit ensuite les interfaces pour les visiteurs c’est-à-dire IConnectionConfiguration:
public interface IConnectionConfiguration
{
string Name { get; }
string Address { get; }
string Port { get; }
void VisitDatabaseConfigurationConsumer(
IDatabaseConfigurationConsumer configurationConsumer);
void VisitRestServiceConfigurationConsumer(
IRestServiceConfigurationConsumer configurationConsumer);
}
Ensuite on modifie ConnectionConfiguration pour que cette classe devienne un visiteur. Elle doit donc satisfaire les nouvelles méthodes de IConnectionConfiguration:
public class ConnectionConfiguration : IConnectionConfiguration
{
public string Name { get; }
public string Address { get; }
public string Port { get; }
public virtual void VisitDatabaseConfigurationConsumer(
IDatabaseConfigurationConsumer configurationConsumer)
{
}
public virtual void VisitRestServiceConfigurationConsumer(
IRestServiceConfigurationConsumer configurationConsumer)
{
}
}
L’implémentation de DatabaseConfiguration doit être adaptée pour devenir un visiteur:
public class DatabaseConfiguration : ConnectionConfiguration, IDatabaseConfiguration
{
public string DatabaseName { get; set; }
public string UserId { get; set; }
public string Password { get; set; }
public override void VisitDatabaseConfigurationConsumer(
IDatabaseConfigurationConsumer configurationConsumer)
{
configurationConsumer.AcceptConfiguration(this);
}
}
De même, l’implémentation de RestServiceConfiguration devient:
public class RestServiceConfiguration: ConnectionConfiguration, IRestServiceConfiguration
{
public string RestMethod { get; set; }
public string RestFormat { get; set; }
public override void VisitRestServiceConfigurationConsumer(
IRestServiceConfigurationConsumer configurationConsumer)
{
configurationConsumer.AcceptConfiguration(this);
}
}
On doit aussi modifier IConfigurationHandler pour permettre de récupérer les éléments de configuration spécifiques:
public class ConfigurationHandler : IConfigurationHandler
{
private IConnectionConfiguration databaseConfiguration;
private IConnectionConfiguration restServiceConfiguration;
public ConfigurationHandler(
IConnectionConfiguration databaseConfiguration,
IConnectionConfiguration restServiceConfiguration)
{
// Il n'y a plus de "cast"
this.databaseConfiguration = databaseConfiguration;
this.restServiceConfiguration = restServiceConfiguration;
}
public void GetDatabaseConfiguration(
IDatabaseConfigurationConsumer configurationConsumer)
{
this.databaseConfiguration.VisitDatabaseConfigurationConsumer(
configurationConsumer);
}
public void GetRestServiceConfiguration(
IRestServiceConfigurationConsumer configurationConsumer)
{
this.restServiceConfiguration.VisitRestServiceConfigurationConsumer(
configurationConsumer);
}
}
Au niveau des classes clientes, DatabaseClient (respectivement RestServiceClient) doit satisfaire IDatabaseConfigurationConsumer (resp. IRestServiceConfigurationConsumer) pour devenir une classe visitée.
Pour DatabaseClient, on rajoute l’interface IDatabaseConfigurationConsumer et on effectue l’implémentation correspondante:
public class DatabaseClient: IClient, IDatabaseConfigurationConsumer
{
private string name;
private string address;
private string port;
private string databaseName;
private string userId;
private string password;
public void AcceptConfiguration(IDatabaseConfiguration configuration)
{
// On affecte les éléments de configuration communs
this.name = configuration.Name;
this.address = configuration.Address;
this.port = configuration.Port;
// On affecte les éléments de configuration spécifiques à la base de données
this.databaseName = configuration.DatabaseName;
this.userId = configuration.UserId;
this.password = configuration.Password;
}
public IData FetchData(IConfigurationHandler configurationHandler)
{
// On récupère la configuration
configurationHandler.GetDatabaseConfiguration(this);
// Le reste de l'implémentation n'a pas d'importance
// il consiste à se connecter à la base de données et à récupérer
// des données
return new FetchedData();
}
}
De même pour RestServiceClient, on rajoute l’interface IRestServiceConfigurationConsumer et on effectue l’implémentation correspondante:
public class RestServiceClient: IClient, IRestServiceConfigurationConsumer
{
private string name;
private string address;
private string port;
private string restMethod;
private string restFormat;
public void AcceptConfiguration(IRestServiceConfiguration configuration)
{
// On affecte les éléments de configuration communs
this.name = configuration.Name;
this.address = configuration.Address;
this.port = configuration.Port;
// On affecte les éléments de configuration spécifiques au service REST
this.restMethod = configuration.RestMethod;
this.restFormat = configuration.RestFormat;
}
public IData FetchData(IConfigurationHandler configurationHandler)
{
// On récupère la configuration
configurationHandler.GetRestServiceConfiguration(this);
// Le reste de l'implémentation n'a pas d'importance
// il consiste à se connecter à la base de données et à récupérer
// des données
return new FetchedData();
}
}
La récupération de la configuration par DatabaseClient et de RestServiceClient peut se résumer de cette façon:
Appel à IConfigurationHandler à partir de DatabaseClient et RestServiceClient
Le code suivante permet d’exécuter cet exemple:
static void Main(string[] args)
{
IConnectionConfiguration databaseConfiguration = new DatabaseConfiguration{
Name = "Config1",
Address = "server1",
Port = "1433",
DatabaseName = "MyDataBase",
UserId = "User1",
Password = "MyPassword"
};
IConnectionConfiguration restServiceConfiguration = new RestServiceConfiguration{
Name = "Config2",
Address = "server2.com/api/v1",
Port = "9001",
RestMethod = "GET",
RestFormat = "json"
};
IConfigurationHandler configurationHandler = new ConfigurationHandler(
databaseConfiguration, restServiceConfiguration);
DatabaseClient databaseClient = new DatabaseClient();
databaseClient.FetchData(configurationHandler);
RestServiceClient restServiceClient = new RestServiceClient();
restServiceClient.FetchData(configurationHandler);
}
On remarque que:
Aucune classe n’effectue de casts.
Les classes clientes manipulent directement un objet générique qui est IConfigurationHandler. Toutefois elles consomment la configuration plus spécifique par l’intermédiaire de la fonction AcceptConfiguration(). Elles sont donc libres de s’adapter et de récupérer les éléments de configuration qui les intéressent.
Pour conclure…
Outre l’absence de cast, le grand intérêt de la 3e solution est que si une modification amène à faire une classe de configuration satisfaire une autre interface que celle attendue par une classe cliente, la compilation va échouer. De cette façon, on voit directement les adaptations qui sont nécessaires dans toutes les classes clientes.
Par exemple, si on décide que DatabaseConfiguration ne doit plus satisfaire IDatabaseConfiguration mais une autre interface IAzureConfiguration qui se définit de cette façon:
Des paires de clé/valeur sont échangées lors de la phase shuffle/sort. Plus il y a des paires qui sont échangées entre des nœuds et moins le job sera exécuté de façon efficace. Utiliser des combiners peut aider à réduire les données échangées.
Explication du “combiner”
Le combiner est un composant logiciel qui va agréger les paires de clé/valeur à la sortie d’un mapper avant la phase shuffle/sort. Cette première agrégation permet de réduire le nombre de clé/valeur qui seront transmises à la phase shuffle/sort et par suite au reducer. Réduire le nombre de paires de clé/valeur transitant d’un nœud à l’autre permet d’optimiser l’exécution du job.
Concrètement, le combiner est placé juste après chaque mapper et est exécuté avant la phase shuffle/sort:
Exemple d’utilisation du “combiner”
En utilisant l’exemple du job Word count et en considérant le comptage des mots de la phase:
"Hadoop est un outil puissant toutefois cet outil
a des limites qui le rendent moins puissant."
Dans le cas où le cluster est composé de 2 nœuds, le comptage de la phrase sera réparti sur 2 mappers. A la sortie des mappers, les paires de clé/valeur seront:
Nœud 1 après exécution du mapper: ("Hadoop"/1), ("est"/1), ("un"/1), ("outil"/1), ("puissant"/1), ("toutefois"/1), ("cet"/1), ("outil"/1)
Nœud 2 après exécution du mapper: ("a"/1), ("des"/1), ("limites"/1), ("qui"/1), ("le"/1), ("rendent"/1), ("moins"/1), ("puissant"/1)
Après exécution des combiners qui se trouvent à la sortie des mappers:
Nœud 1 après exécution du combiner: ("Hadoop"/1), ("est"/1), ("un"/1), ("outil"/2), ("puissant"/1), ("toutefois"/1), ("cet"/1)
Nœud 2 après exécution du combiner: ("a"/1), ("des"/1), ("limites"/1), ("qui"/1), ("le"/1), ("rendent"/1), ("moins"/1), ("puissant"/1)
On remarque que dans le cas du nœud 1, les paires avec la clé "outil" ont été agrégées.
Les paires clé/valeur sont triées et réparties sur les 2 nœuds.
Dans le cas d’un seul reducer, toutes les clés sont adressées au seul reducer pour être agrégées. On obtient après exécution du reducer:
Le reducer n’a effectué qu’une seule agrégation: les paires avec la clé "puissant". S’il n’y avait pas de combiners, le reducer aurait dû agréger les paires correspondant aux clés "outil" et "puissant".
Le combiner permet donc de:
Réduire les données échangées entre nœud
Réduire le nombre de traitements effectués par le reducer.
Dans le cadre du comptage de mots, l’implémentation du combiner est la même que celle du reducer (l’implémentation du reducer se trouve dans l’article Exécuter un job Hadoop MapReduce avec .NET Core:
using System;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
string currentWord = string.Empty;
int currentWordCount = 0;
string word = string.Empty;
string valueFromMapper = Console.ReadLine();
while (valueFromMapper != null)
{
var splitLine = valueFromMapper.Split('\t');
if (splitLine.Length == 2)
{
word = splitLine[0];
int count;
if (Int32.TryParse(splitLine[1], out count))
{
if (currentWord == word)
{
currentWordCount += count;
}
else
{
if (!string.IsNullOrWhiteSpace(currentWord))
{
Console.WriteLine($"{currentWord}\t{currentWordCount}");
}
currentWord = word;
currentWordCount = count;
}
}
}
valueFromMapper = Console.ReadLine();
}
if (currentWord == word && !string.IsNullOrWhiteSpace(currentWord))
{
Console.WriteLine($"{currentWord}\t{currentWordCount}");
}
}
}
}
Exécution du job MapReduce avec un “combiner”
Pour exécuter un job MapReduce avec Hadoop Streaming en fournissant un combiner, il faut, dans une premier temps, créer un projet console avec .Net Core:
% dotnet new console –n combiner
Après avoir modifié l’implémentation dans combiner/Program.cs:
File System Counters
FILE: Number of bytes read=375438
FILE: Number of bytes written=1171439
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3363856
HDFS: Number of bytes written=227620
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=76630
Total time spent by all reduces in occupied slots (ms)=12702
Total time spent by all map tasks (ms)=38315
Total time spent by all reduce tasks (ms)=6351
Total vcore-milliseconds taken by all map tasks=38315
Total vcore-milliseconds taken by all reduce tasks=6351
Total megabyte-milliseconds taken by all map tasks=78469120
Total megabyte-milliseconds taken by all reduce tasks=13006848
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=4242981
Map output materialized bytes=375444
Input split bytes=210
Combine input records=566308
Combine output records=29157
Reduce input groups=20470
Reduce shuffle bytes=375444
Reduce input records=29157
Reduce output records=20470
Spilled Records=58314
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=323
CPU time spent (ms)=7770
Physical memory (bytes) snapshot=571236352
Virtual memory (bytes) snapshot=8277688320
Total committed heap usage (bytes)=398663680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3363646
File Output Format Counters
Bytes Written=227620
Comparaison entre l’exécution avec et sans “combiner”
Si on considère le résumé de l’exécution du job MapReduce word count sans combiner:
Sur la quantité de données échangées, on constate une diminution assez conséquente (l’unité utilisée est l’octet):
Sans combiner: Map output materialized bytes=5375609
Avec combiner: Map output materialized bytes=375444
Soit un gain de 93% ce qui est considérable.
Le temps d’exécution est le même avec ou sans combiner (50 sec).
Dans le cadre du job Word Count, on constate que la quantité de données échangées est considérablement réduite. Le temps d’exécution est, quant à lui, inchangé.
Le combiner est donc une option à prendre en compte lors de l’exécution d’une job MapReduce, en particulier si on cherche à limiter la quantité de données transitant d’un nœud à l’autre.
Lors de l’exécution d’un job MapReduce, il peut être nécessaire de consulter des données régulièrement de façon à les utiliser pour les traitements effectués par le mapper ou le reducer. Par exemple, on peut avoir la nécessité de mettre en place un dictionnaire et y accéder pendant l’exécution du mapper et du reducer.
Hadoop possède une fonctionnalité qui permet de répondre à ce besoin avec le cache distribué (i.e. distributed cache). Ce cache est accessible à partir du système de fichier distribué HDFS ce qui permet à tous les jobs qui s’exécutent de pouvoir y accéder. Il suffit de lire les fichiers sur HDFS.
Le gros intérêt du cache distribué est d’avoir des fichiers de travail consultables par les jobs:
Pour réduire la quantité de traitements effectués par les jobs,
Pour limiter la quantité de données transmises entre les mappers et le reducer,
Pour éventuellement utiliser les résultats d’autres jobs.
Réduire la quantité de traitement ou limiter la quantité de données transitant dans le réseau sont des facteurs qui permettent de rendre l’exécution d’un job MapReduce plus efficace.
Cet article va montrer un exemple d’utilisation du cache distribué avec Hadoop Streaming et une implémentation du mapper et du reducer en C# avec .NET Core.
Explication du cache distribué
Comme indiqué plus haut, le cache distribué (i.e. distributed cache) sont des fichiers accessibles par les jobs sur HDFS. On y accède à partir du mapper ou du reducer en les lisant directement sur le système de fichiers HDFS. Par exemple si un fichier du cache se trouve sur HDFS avec le path suivant:
refdata/distributed_cache_file.txt
On peut y accéder dans l’implémentation du mapper et du reducer en exécutant simplement:
var cacheFileLines = System.IO.File.ReadAllLines("refdata/distributed_cache_file.txt")
Dans l’article Hadoop MapReduce en 5 min, on avait expliqué le fonctionnement d’un job MapReduce en indiquant que les données traitées par les mappers étaient envoyées au reducer. Plus il y a des données à transmettre et plus l’exécution du job sera lente puisque ces données transitent à travers le réseau. On peut donc utiliser le cache distribué pour réduire la quantité de données transitant dans le réseau entre les mappers et le reducer.
Dans le schéma précédent, les flèches noires indiquent la transmission des données à travers le réseau.
Exemple d’utilisation du cache distribué
On se propose d’illustrer l’utilisation du cache distribué avec le job Word count. Le but est de réduire la quantité de données entre les mappers et le reducer. Les données transmises entre les différents jobs correspondent aux mots. Ainsi si on réduit la taille des mots, on peut réduire la quantité de données transmises.
Une méthode pour réduire la taille des mots est de considérer un dictionnaire comportant pour chaque mot un code. Si la taille de ce code est inférieure à celle du mot, on peut réduire la taille du mot.
Par exemple, si on considère le comptage des mots de la phrase:
"Hadoop est un outil puissant toutefois cet outil a des limites
qui le rendent moins puissant"
Normalement, à la sortie du mapper, on obtient les paires clé/valeur suivantes:
Si on affecte un code unique à chacun de ces mots:
hadoop 1
est 2
un 3
outil 4
puissant 5
toutefois 6
cet 7
a 8
des 9
limites A
qui B
le C
rendent D
moins E
On remarque que pour la plupart des mots, le code est plus court en nombre de lettres que le mot. Ainsi, en utilisant le code pour désigner le mot en tant que clé dans le job MapReduce, on économise des lettres lors de la transmission des paires clé/valeur entre les mappers et le reducer.
Dans cet exemple les paires de clé/valeur transmises au reducer seraient:
On peut créer un dictionnaire pour affecter à chaque mot un code dont la taille sera réduite par rapport à la taille du mot.
Le code doit être unique pour chaque mot.
Ainsi:
Chaque mapper lit le dictionnaire et génère des paires clé/valeur avec code/1 au lieu de mot/1.
Le reducer lit aussi le dictionnaire pour compter le nombre d’occurrences du code (qui est le même que celui du mot correspondant) et ensuite affecter pour chaque code le mot qui correspond.
La sortie du reducer est donc la même que si on n’utilise pas de dictionnaire. L’échange de données entre les mappers et le reducer ne comporte que des paires code/1 dont la taille est plus faible que les paires mot/1.
Génération du dictionnaire de mots
La 1ère étape consiste à générer des codes uniques pour chaque mot. On affecte à chaque mot un nombre décimal et on convertit ce nombre décimal vers un nombre hexadécimal pour en réduire la taille.
Dans l’exemple évoqué précédemment, on effectue ce traitement:
hadoop 1
est 2
un 3
outil 4
puissant 5
toutefois 6
cet 7
a 8
des 9
limites A
qui B
le C
rendent D
moins E
Si on va plus loin, et au lieu de convertir en hexadécimal, on utilise davantage la table de caractères ASCII en considérant les caractères du code 48 à 122:
Les chiffres de 0 à 9 du code ASCII 48 à 57.
Les lettres majuscules de A à Z du code ASCII 65 à 90.
Les caractères “[“, “\”, “]”, “^”, “_” et “`” du code ASCII 91 à 96.
Les lettres minuscules de a à z du code ASCII 97 à 122.
Avec ces caractères, le code comporte moins de lettres que les nombres en hexadécimal.
Pour convertir le nombre décimal du mot vers la suite de caractères qui sera le code, on propose donc l’algorithme suivant:
public static string ConvertIntToCode(int number)
{
if (number < 1) return "0";
int codeAsInt = number;
string code = string.Empty;
while (number > 0)
{
codeAsInt = number % 68;
if (codeAsInt < 10)
code = code.Insert(0, Convert.ToChar(codeAsInt + 48).ToString());
else
code = code.Insert(0, Convert.ToChar(codeAsInt + 55).ToString());
number /= 68;
}
return code;
}
Le nombre 68 dans l’algorithme est utilisé parce qu’on considère les caractères de la table ASCII du code 65 à 122.
Pour générer le dictionnaire, on utilise les mots provenant d’un précédent comptage de façon à avoir un exemple de listes de mots.
Par exemple si on considère une liste de mots provenant d’un précédent comptage:
Adaptation du “mapper” pour utiliser le dictionnaire
Comme indiqué plus haut, on modifie le mapper pour lire le dictionnaire et affecter un code à chaque mot trouvé. Le mapper génère des paires code/1 au lieu de génèrer des paires mot/1.
using System;
using System.IO;
using System.Text;
using System.Collections.Generic;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
Dictionary<string, string> wordCounts = GetCachedWordCodes();
var fileLine = Console.ReadLine();
while (fileLine != null)
{
var words = fileLine.Split(' ');
foreach (var word in words)
{
if (string.IsNullOrWhiteSpace(word)) continue;
var wordToWrite = StripPunctuation(word.Trim().ToLower());
string wordCode;
if (wordCounts.TryGetValue(wordToWrite, out wordCode))
{
wordToWrite = wordCode;
}
Console.WriteLine($"{wordToWrite}\t1");
}
fileLine = Console.ReadLine();
}
}
// Permet de lire le dictionnaire se trouvant dans le cache distribué
public static Dictionary<string, string> GetCachedWordCodes()
{
Dictionary<string, string> wordCounts = new Dictionary<string, string>();
var lines = File.ReadAllLines("refdata/word_codes.txt");
foreach (var line in lines)
{
var splitLine = line.Split('\t', StringSplitOptions.RemoveEmptyEntries);
if (splitLine.Length < 2) continue;
string word = splitLine[0];
string wordCode = splitLine[1];
wordCounts[word] = wordCode;
}
return wordCounts;
}
// Supprime la ponctuation
public static string StripPunctuation(string inputString)
{
var outputString = new StringBuilder();
foreach (char character in inputString)
{
if (!char.IsPunctuation(character))
outputString.Append(character);
}
return outputString.ToString();
}
}
}
Dans cet algorithme, File.ReadAllLines("refdata/word_codes.txt") permet de lire le dictionnaire qui se trouve dans le cache distribué sur HDFS.
Exécution du job MapReduce sans adaptation du “reducer”
Si on exécute à cette étape le job MapReduce sur adapter le reducer, on obtiendra la liste de codes avec le nombre d’occurrences.
Il faut placer le dictionnaire word_codes.txt obtenu à l’étape précédente dans le répertoire refdata sur HDFS.
En compilant le mapper et en le plaçant dans le répertoire mapper_distributed_cache:
% dotnet new console –n mapper_distributed_cache
Après avoir modifié l’implémentation dans mapper_distributed_cache/Program.cs:
File System Counters
FILE: Number of bytes read=4311878
FILE: Number of bytes written=9044253
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3363856
HDFS: Number of bytes written=122053
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=78664
Total time spent by all reduces in occupied slots (ms)=15192
Total time spent by all map tasks (ms)=39332
Total time spent by all reduce tasks (ms)=7596
Total vcore-milliseconds taken by all map tasks=39332
Total vcore-milliseconds taken by all reduce tasks=7596
Total megabyte-milliseconds taken by all map tasks=80551936
Total megabyte-milliseconds taken by all reduce tasks=15556608
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=3179256
Map output materialized bytes=4311884
Input split bytes=210
Combine input records=0
Combine output records=0
Reduce input groups=20311
Reduce shuffle bytes=4311884
Reduce input records=566308
Reduce output records=20310
Spilled Records=1132616
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=328
CPU time spent (ms)=9270
Physical memory (bytes) snapshot=572051456
Virtual memory (bytes) snapshot=8277377024
Total committed heap usage (bytes)=398663680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3363646
File Output Format Counters
Bytes Written=122053
Adaptation du “reducer”
On adapte le reducer pour lire le dictionnaire, et affecter le mot correspondant à chaque code trouvé. L’implémentation de départ du reducer est celle se trouvant dans l’article Exécuter un job Hadoop MapReduce avec .NET Core.
Après adaptation, le reducer devient:
using System;
using System.Collections.Generic;
using System.IO;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
Dictionary<string, string> word_codes = GetCachedWordCodes();
string currentWord = string.Empty;
int currentWordCount = 0;
string word = string.Empty;
string valueFromMapper = Console.ReadLine();
while (valueFromMapper != null)
{
var splitLine = valueFromMapper.Split('\t');
if (splitLine.Length == 2)
{
word = splitLine[0];
int count;
if (Int32.TryParse(splitLine[1], out count))
{
if (currentWord == word)
{
currentWordCount += count;
}
else
{
if (!string.IsNullOrWhiteSpace(currentWord))
{
string wordToWrite = currentWord;
word_codes.TryGetValue(currentWord, out wordToWrite);
Console.WriteLine($"{wordToWrite}\t{currentWordCount}");
}
currentWord = word;
currentWordCount = count;
}
}
}
valueFromMapper = Console.ReadLine();
}
if (currentWord == word && !string.IsNullOrWhiteSpace(currentWord))
{
string wordToWrite = currentWord;
word_codes.TryGetValue(currentWord, out wordToWrite);
Console.WriteLine($"{wordToWrite}\t{currentWordCount}");
}
}
// Permet de lire le dictionnaire se trouvant dans le cache distribué
public static Dictionary<string, string> GetCachedWordCodes()
{
Dictionary<string, string> wordCounts = new Dictionary<string, string>();
var lines = File.ReadAllLines("refdata/word_codes.txt");
foreach (var line in lines)
{
var splitLine = line.Split('\t', StringSplitOptions.RemoveEmptyEntries);
if (splitLine.Length < 2) continue;
string word = splitLine[0];
string wordCode = splitLine[1];
wordCounts[wordCode] = word;
}
return wordCounts;
}
}
}
De la même façon que le mapper, File.ReadAllLines("refdata/word_codes.txt") permet de lire le dictionnaire qui se trouve dans le cache distribué sur HDFS.
Exécution du job MapReduce avec le “reducer” adapté
On compile le reducer et on le place dans le répertoire reducer_distributed_cache:
% dotnet new console –n reducer_distributed_cache
Après avoir modifié l’implémentation dans reducer_distributed_cache/Program.cs:
File System Counters
FILE: Number of bytes read=4311878
FILE: Number of bytes written=9044253
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3363856
HDFS: Number of bytes written=122053
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=78664
Total time spent by all reduces in occupied slots (ms)=15192
Total time spent by all map tasks (ms)=39332
Total time spent by all reduce tasks (ms)=7596
Total vcore-milliseconds taken by all map tasks=39332
Total vcore-milliseconds taken by all reduce tasks=7596
Total megabyte-milliseconds taken by all map tasks=80551936
Total megabyte-milliseconds taken by all reduce tasks=15556608
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=3179256
Map output materialized bytes=4311884
Input split bytes=210
Combine input records=0
Combine output records=0
Reduce input groups=20311
Reduce shuffle bytes=4311884
Reduce input records=566308
Reduce output records=20310
Spilled Records=1132616
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=328
CPU time spent (ms)=9270
Physical memory (bytes) snapshot=572051456
Virtual memory (bytes) snapshot=8277377024
Total committed heap usage (bytes)=398663680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3363646
File Output Format Counters
Bytes Written=122053
Comparaison entre l’exécution avec et sans cache distribué
L’intérêt de l’utilisation du cache distribué n’est pas dans le résultat obtenu puisqu’il est le même, mais dans le temps et la quantité de données échangées entre les mappers et le reducer.
Ainsi si on considère le résumé de l’exécution du job MapReduce word count sans cache distribué:
File System Counters
FILE: Number of bytes read=5375603
FILE: Number of bytes written=11170764
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3363856
HDFS: Number of bytes written=227620
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=68848
Total time spent by all reduces in occupied slots (ms)=15542
Total time spent by all map tasks (ms)=34424
Total time spent by all reduce tasks (ms)=7771
Total vcore-milliseconds taken by all map tasks=34424
Total vcore-milliseconds taken by all reduce tasks=7771
Total megabyte-milliseconds taken by all map tasks=70500352
Total megabyte-milliseconds taken by all reduce tasks=15915008
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=4242981
Map output materialized bytes=5375609
Input split bytes=210
Combine input records=0
Combine output records=0
Reduce input groups=20471
Reduce shuffle bytes=5375609
Reduce input records=566308
Reduce output records=20470
Spilled Records=1132616
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=327
CPU time spent (ms)=8530
Physical memory (bytes) snapshot=574074880
Virtual memory (bytes) snapshot=8277377024
Total committed heap usage (bytes)=398663680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3363646
File Output Format Counters
Bytes Written=227620
Sur la quantité de données échangées, on constate une légère diminution:
Sans cache distribué: Map output materialized bytes=5375609
Avec cache distribué: Map output materialized bytes=4311884
Soit un gain de 20% par rapport à l’utilisation sans cache distribué.
Au niveau du temps d’exécution:
Sans cache distribué: 49 sec
Avec cache distribué: 53 sec
On constate une légère pénalité dans le temps d’exécution qui peut s’expliquer par les traitements supplémentaires effectués pour faire la conversion mot → code dans les mappers et code → mot dans le reducer.
Dans cet exemple, le temps d’exécution n’a pas été réduit toutefois, suivant la quantité de données transitant dans le réseau, on peut imaginer que dans certains cas, le cache distribué permet de limiter les échanges de données.