L’objectif principal de l’architecture hexagonale est de découpler la partie métier d’une application de ses services techniques. Ceci dans le but de préserver la partie métier pour qu’elle ne contienne que des éléments liés aux traitements fonctionnels. Cette architecture est aussi appelée “Ports et Adaptateurs” car l’interface entre la partie métier et l’extérieur se fait, d’une part, en utilisant les ports qui sont des interfaces définissant les entrées ou sorties et d’autre part, les adaptateurs qui sont des objets adaptant le monde extérieur à la partie métier.
Dans cet article, on va dans un premier temps, expliquer plus en détails l’architecture hexagonale; comparer cette architecture avec une autre architecture moins polyvalente et enfin illustrer concrètement avec un exemple.
Préserver le modèle
Architecture en couches
La logique métier doit se trouver à l’intérieur de l’hexagone
Inversion de dépendances
La couche application
La couche infrastructure
Ports et adaptateurs
Ports
Ports primaires
Adaptateurs primaires
Ports secondaires ou plugins
Adaptateurs secondaires
Pourquoi utiliser l’architecture hexagonale ?
Testabilité
Préserver le modèle
Comparaison avec l’architecture 3-tiers
Mise en situation
Implémentation de l’hexagone
Port primaire
Port secondaire
Adaptateur primaire
Adaptateur secondaire
Inconvénients de l’architecture hexagonale
Anemic Domain Model
Les frontières du domaine restent floues
Framework d’injection de dépendances
Préserver le modèle
Avant de rentrer dans les détails de l’architecture hexagonale, on pourrait se demander ce qui justifie de devoir préserver le modèle.
Dans la plupart des logiciels, la logique métier qui est implémentée est ce qui constitue la plus grande valeur ajoutée puisque c’est cette logique qui rend le logiciel fonctionnel. Pourtant très souvent une grande part des développements se concentrent sur d’autres parties comme l’interface graphique, la persistance des données ou le partage d’informations avec des systèmes externes.
L’idée est donc de tenter de préserver ce qui représente la plus grande valeur ajoutée d’une application: la logique métier.
La première étape consiste à comprendre ce qui correspond à la logique métier et ce qui relève de processus techniques qui n’ont pas de logique fonctionnelle. Toute cette approche peut être approfondie en s’intéressant au Domain-Driven Design (ou DDD) qui donne des indications sur la façon d’arriver à isoler la logique métier.
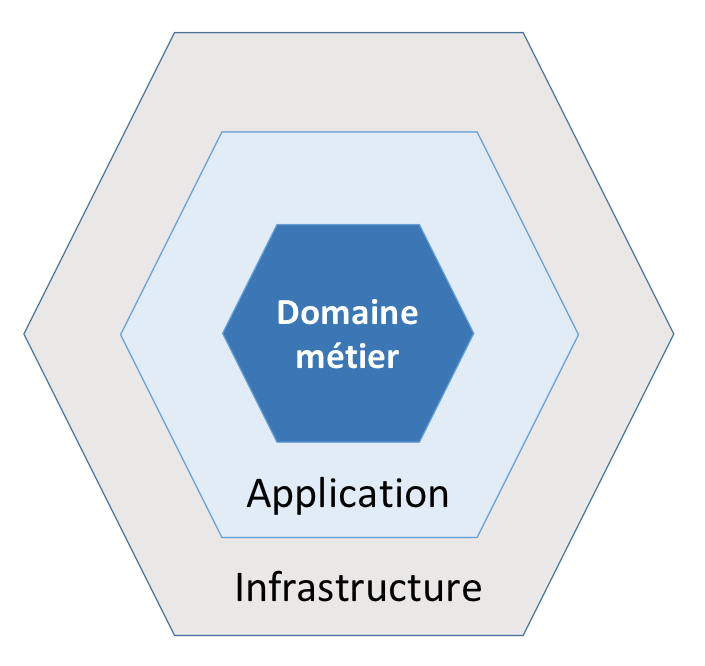
Architecture en couches
L’architecture hexagonale préconise une version simplifiée de l’architecture en couches pour séparer la logique métier des processus techniques:
La logique métier doit se trouver à l’intérieur de l’hexagone
La logique fonctionnelle ou ce que le DDD appelle le domaine doit se trouver à l’intérieur de l’hexagone. L’implémentation de ce domaine ne doit faire appel à aucun élément extérieur directement. Le but est d’isoler le domaine de l’extérieur et de définir des interfaces d’entrée et de sortie claires. L’hexagone symbolise la séparation stricte entre le code métier et le code technique.
Ainsi, le domaine doit matérialiser ses besoins, par exemple, en éléments de configuration ou en données d’entrées au moyen d’interfaces sans effectuer d’appels directs à l’extérieur. Ce sont des objets externes qui vont fournir à l’hexagone les données dont il a besoin pour effectuer le traitement fonctionnel.
Dans l’idéal, les technologies utilisées dans l’hexagone ne doivent pas avoir une empreinte trop forte sur l’implémentation de façon à ce que le code métier ne dépende pas de la technologie. Le but est de limiter l’impact de changements technologiques même majeurs sur l’implémentation de la logique fonctionnelle dans l’hexagone. Le domaine est ainsi préservé.
Inversion de dépendances
Pour fournir à l’hexagone, les éléments nécessaires à son traitement fonctionnel, on utilise l’inversion de dépendances. L’hexagone définit ses dépendances au moyen d’interface qui vont régir les entrées et sorties. L’hexagone ne fait aucun appel à l’extérieur mais expose ses interfaces au monde extérieur. Les objets du monde extérieur font des appels à l’hexagone en utilisant ces interfaces et en fournissant les objets nécessaires à son traitement.
La couche application
La couche application est la couche technique qui sépare le monde extérieur de l’hexagone. Elle permet d’adapter les éléments extérieurs à l’application pour effectuer des appels à l’hexagone. Cette couche est appelée application pourtant elle ne représente pas à elle-seule toute l’application.
Par exemple, si la couche métier dans l’hexagone a besoin d’éléments de configuration et de données se trouvant dans la base de données, c’est la couche application qui va récupérer ces éléments et les adapter en objets compréhensibles par les interfaces de l’hexagone. Il va ensuite effectuer les appels à l’hexagone, récupérer les résultats et les traduire de nouveau pour les adapter au monde extérieur.
La couche infrastructure
Cette couche est facultative, elle provient de l’approche DDD. Elle est, parfois, évoquée dans la documentation sur l’architecture hexagonale sous ce nom ou sous le nom de couche Framework. Dans certains cas, elle peut aussi être confondue avec la couche application. D’une façon générale, elle permet de traiter les communications provenant de l’extérieur et de les adresser aux adaptateurs de la couche application.
Par exemple, la couche infrastructure peut s’occuper de l’instanciation d’une SqlConnection pour effectuer des appels en base de données. La couche application, quant à elle, s’occupera de l’élaboration de requêtes SQL. Ensuite la connexion à la base de données peut être effectuée par la couche infrastructure.
Ports et adaptateurs
Ces éléments sont les plus importants de l’architecture hexagonale puisque ce sont eux qui effectuent tout le travail de traduction entre le monde extérieur et l’hexagone. Ils représentent les frontières entre le code métier dans l’hexagone et le code technique de la couche application.
Ports
Les ports sont les interfaces définies par l’hexagone pour s’interfacer avec le monde extérieur.
Il existe 2 types de port, les ports permettant d’appeler des fonctions dans l’hexagone et les ports permettant à l’hexagone d’appeler des éléments extérieurs.
Un autre élément important est que les ports (d’entrée ou de sortie) sont définis dans l’hexagone.
Ports primaires
Ce sont les ports d’entrée de l’hexagone, ce qui signifie que la couche application fait appel aux ports primaires de l’hexagone pour effectuer des traitements en utilisant des adaptateurs.
L’hexagone fournit une interface sous la forme d’un port, cette interface est utilisée par un adaptateur pour appeler le traitement métier dans l’hexagone. C’est donc un objet de l’hexagone qui implémente l’interface.
Le port primaire peut être symbolisé de cette façon:

Des objets de type port primaire et adaptateur primaire pourraient être schématisés de cette façon en UML:
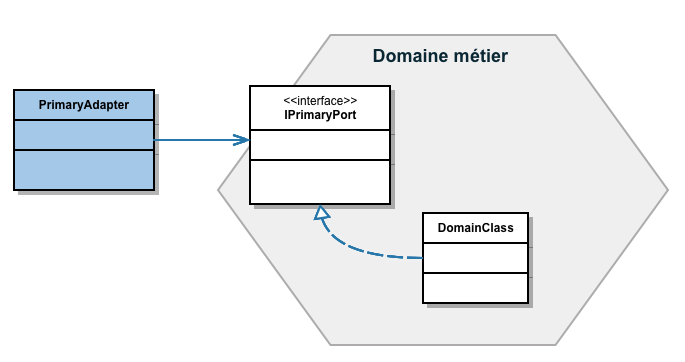
Dans cet exemple, l’adaptateur primaire PrimaryAdapter accéde au port primaire IPrimaryPort se trouvant dans l’hexagone. C’est un objet dans l’hexagone DomainClass qui satisfait le port IPrimaryPort.
Adaptateurs primaires
Ces adaptateurs font appel directement aux ports primaires de l’hexagone. Comme indiqué précédemment, le port est une interface définie dans l’hexagone. L’adaptateur est implémenté à l’extérieur de l’hexagone dans la couche application. L’adaptateur fait appel à l’hexagone en utilisant l’interface fournie par ce dernier.
Concrètement, on passera par un adaptateur primaire pour:
- Récupérer les données provenant de l’extérieur
- Les adapter pour qu’elles soient compréhensibles pour les interfaces correspondant aux ports primaires
- Effectuer l’appel à l’hexagone en utilisant le port primaire et en lui fournissant les données traduites.
Un adaptateur pourrait être symbolisé de cette façon:

Ports secondaires ou plugins
Ce sont les ports de sortie de l’hexagone c’est-à-dire qu’il les utilise pour effectuer des appels vers l’extérieur. Ces ports sont aussi des interfaces définies à l’intérieur de l’hexagone toutefois l’implémentation de ces interfaces ne se trouvent pas dans l’hexagone mais à l’extérieur par des adaptateurs secondaires. Les objets implémentant les ports secondaires sont fournis à l’hexagone par inversion de dépendances.
Pour résumer, des adaptateurs implémentant les ports secondaires sont fournis à l’hexagone qui les utilise pour effectuer ses appels à l’extérieur.
Le port secondaire peut être symbolisé de cette façon:

Par exemple, des objets de type port secondaire et un adaptateur secondaire pourraient être schématisés de cette façon en UML:
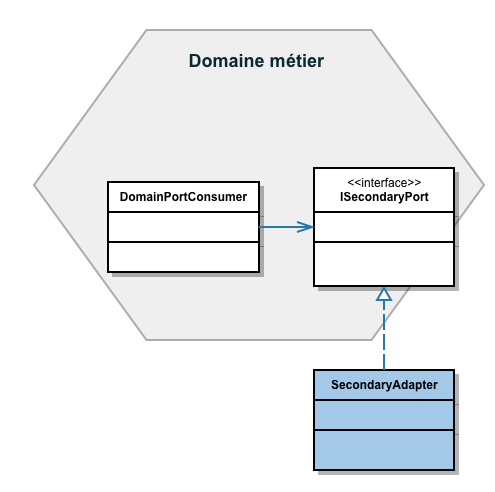
Dans cet exemple, l’adaptateur secondaire SecondaryAdapter satisfait le port secondaire ISecondaryPort se trouvant dans l’hexagone. C’est un objet dans l’hexagone DomainPortConsumer qui accède au port secondaire.
Adaptateurs secondaires
Ces adaptateurs font appel aux ports secondaires. Contrairement aux adaptateurs primaires, ils implémentent l’interface correspondant au port secondaires. Ils sont injectés dans l’hexagone au moyen de l’inversion de dépendance. L’hexagone peut, alors, y faire appel pour effectuer des traitements.
Concrètement, on utilisera un adaptateur secondaire pour:
- Permettre d’effectuer des appels vers l’extérieur de l’hexagone en fournissant à l’adaptateur des données respectant les interfaces correspondant aux ports secondaires.
- L’adaptateur secondaire effectue une conversion de ces données vers un format compréhensible des objets du monde extérieur.
- L’adaptateur secondaire effectue des appels au monde extérieur en utilisant les objets convertis.
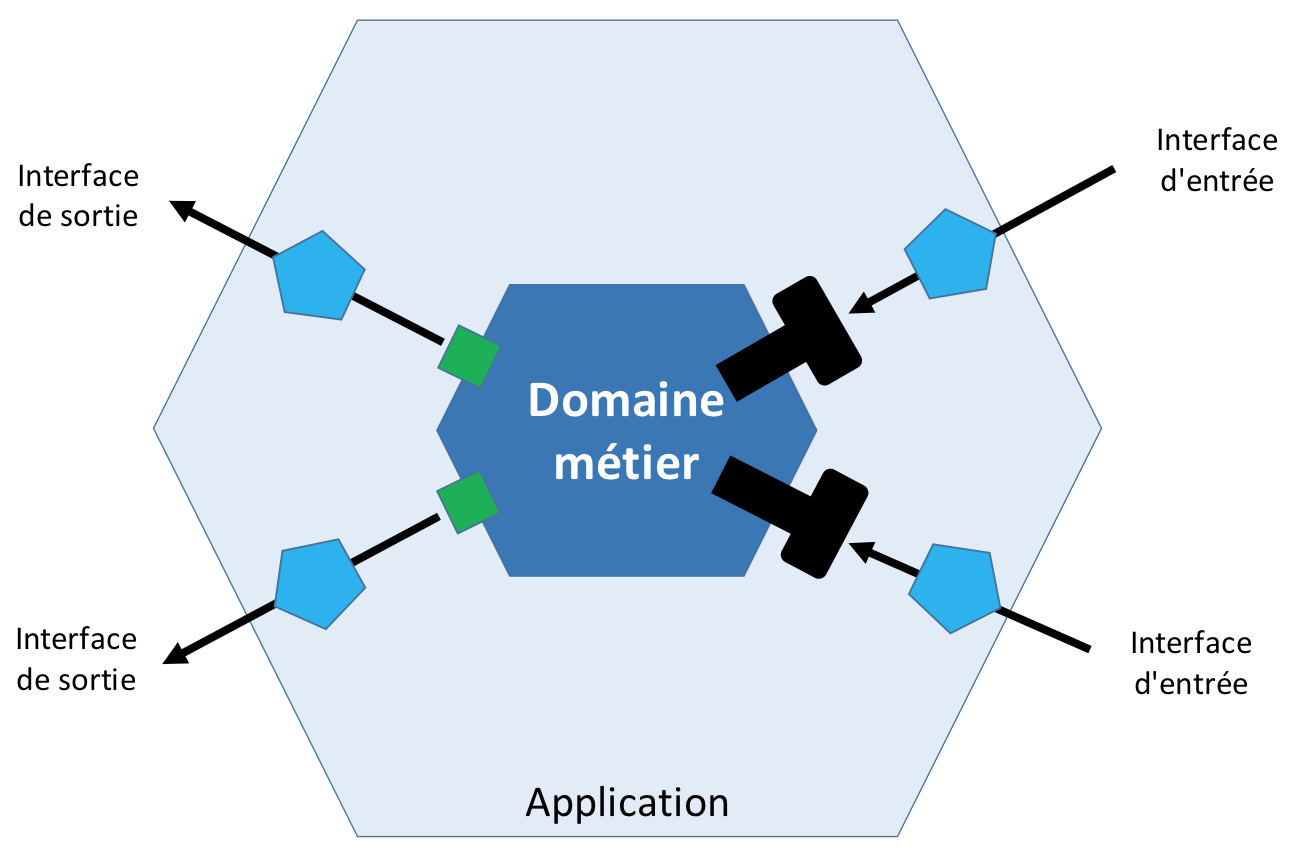
Dans les schémas de l’architecture hexagonale, l’hexagone est évidemment représenté avec 6 cotés laissant penser qu’il doit être composé de 6 ports. Le nombre de cotés est arbitraire et n’est pas évidemment par limité à 6.
D’une façon générale, on pourrait schématiser les différents objets intervenant dans l’architecture hexagonale et leurs interactions de cette façon:
 |
Avec:
|
Pourquoi utiliser l’architecture hexagonale ?
Après avoir présenté l’architecture hexagonale, on pourrait se demander ce qui justifie d’utiliser cette architecture.
Testabilité
Quand Alistair Cockburn a inventé l’architecture hexagonale en 2005, il cherchait à créer une application testable. Ce type d’architecture répond à ce besoin puisqu’elle permet d’isoler le modèle et d’identifier toutes les entrées et sorties de ce dernier. D’autre part, l’injection de dépendances permet de maîtriser les objets qui seront utilisés par le modèle pour s’interfacer avec l’extérieur. On peut donc facilement injecter des “mock” des adaptateurs et tester complètement le modèle.
Préserver le modèle
Un des objectifs de l’architecture hexagonale est de permettre au modèle de s’affranchir des couches techniques car elles peuvent être amenées à évoluer rapidement. Les adaptateurs sont des objets tampons entre le modèle et le monde extérieur, ainsi ce sont eux qui sont modifiés dans le cas où un élément du monde extérieur l’exige. Le modèle n’est modifié que si la logique métier l’exige. Ainsi l’intérieur de l’hexagone est préservé des changements techniques, on préserve ainsi le modèle.
Comparaison avec l’architecture 3-tiers
Pour se rendre compte de l’intérêt de l’architecture hexagonale, on pourrait la comparer brièvement à l’architecture 3-tiers.
L’architecture 3-tiers a été utilisée très fréquemment il y a une dizaine d’années car elle permettait une séparation franche des responsabilités. Les applications utilisant ce type d’architecture étaient séparées en 3 couches:
- La couche présentation: elle concerne la technologie et la logique liées à l’interface graphique. Pour les traitements plus fonctionnels, la couche présentation fait appel à la couche métier.
- La couche métier: cette couche abrite la logique métier et mets à disposition de la couche graphique des fonctions et des objets permettant la sauvegarde et la lecture de données. Toutefois elle ne se charge pas directement du stockage ou de la lecture des données. La couche métier s’interface avec la couche présentation et la couche persistance. Pour le stockage et la lecture des données, la couche métier fera appel à la couche persistance
- La couche persistance: cette couche se charge de lire et d’écrire les données en base. En principe cette couche ne doit pas contenir de logique métier même si très souvent, une part de cette logique se trouve codée dans les contraintes de base de données relationnelles ou dans des procédures stockées. Cette couche ne s’interface qu’avec la couche métier. Elle est très dépendante de la technologie de la base de données.
Le plus souvent, les utilisateurs effectuent des manipulations sur l’interface graphique. Ces manipulations se traduisent par des appels de fonctions dans la couche présentation qui fait elle-même appel à la couche métier qui, par suite, appelle la couche persistance.
Cette architecture convenait bien dans le cas où les points d’entrée de l’application ne se trouvaient que sur l’interface graphique. Il n’y avait, aussi, qu’une seule façon de stocker des données: soit un stockage en mémoire, soit une persistance dans une base de données. Quoi qu’il en soit, généralement l’architecture restait figée et les nouvelles fonctionnalités ne nécessitaient pas de devoir modifier l’interfaçage entre les couches ou de créer de nouvelles couches.
L’architecture 3-tiers s’est révélée inadaptée à partir du moment où il a été nécessaire d’interfacer l’application avec des multiples technologies. Par exemple, la récupération ou le stockage de données ne passent pas forcément par une base de données mais il peut s’agir d’un service REST, d’un bus de communications, d’une base orientée document etc… La couche persistance devient donc multiple.
D’autre part, les entrée et les sorties de l’application sont plus complexes et ne se font pas uniquement à partir de l’interface graphique.
L’architecture hexagonale s’avère bien plus adaptée pour appréhender la complexité liée à l’utilisation de technologies très différentes. En effet, il n’y a pas qu’une seule couche de persistance mais il y a de multiples objets extérieurs qui appellent ou sont appelés par un adaptateur. Enfin, tous ces objets sont traités sur le même plan d’égalité: la couche présentation devient une couche au même niveau que la couche persistance.
Mise en situation
Pour illustrer l’architecture hexagonale, on se propose d’implémenter un exemple avec les différents types d’adaptateurs et de ports. L’outil que l’on souhaite implémenter permet de déterminer le nombre de pizzas nécessaires en fonction du type de pizza et du nombre de personnes. L’utilisateur indique les informations suivantes:
- Nombre de personnes
- Type de pizza
L’outil réponds ensuite le nombre entier de pizza nécessaire pour rassasier tout le monde. Arbitrairement on considère qu’une pizza est composée de 6 parts et que tout le monde mange le même type de pizza.
La partie métier de cet outil effectue les étapes suivantes:
- Récupère le nombre de personnes et le type de pizza,
- Interroge un repository pour obtenir le nombre moyen de parts de pizza nécessaires pour rassasier une personne en fonction du type de pizza.
- Calcule le nombre de parts nécessaires pour le nombre de personnes
- Renvoie le résultat.
Comme indiqué plus haut, la partie métier correspond à l’intérieur de l’hexagone.
Le code complet de cet exemple se trouve sur Github.
Implémentation de l’hexagone
On va commencer par définir les ports de l’hexagone:
- Un port primaire:
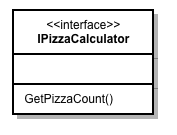
IPizzaCalculatorqui peut être utilisé par des adaptateurs primaires pour interroger la partie métier de l’application. Dans notre cas, cette interface servira à récupérer le nombre de pizzas nécessaires. - Un port secondaire:
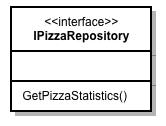
IPizzaRepositoryqui doit être implémenté par les adaptateurs secondaires. Les objets satisfaisantIPizzaRepositorysont utilisés par la partie métier pour récupérer la liste des statistiques permettant de connaître le nombre moyen de parts nécessaires pour rassasier une personne en fonction du type de pizza.
Port primaire
On définit l’interface IPizzaCalculator de cette façon:
L’implémentation est:
public interface IPizzaCalculator
{
int GetPizzaCount(uint personCount, PizzaKind pizzaKind);
}
public enum PizzaKind
{
Regina,
Vegetarian,
Pepperoni
}
Port secondaire
On définit ensuite IPizzaRepository:
L’implémentation est:
public interface IPizzaRepository
{
IEnumerable<PizzaStat> GetPizzaStatistics();
}
public class PizzaStat
{
public PizzaKind PizzaKind { get; set; }
public int AverageSliceCount { get; set; }
}
IPizzaCalculator doit être implémentée par la fonction métier se trouvant à l’intérieur de l’hexagone.
Dans une démarche TDD, on se propose d’implémenter quelques tests pour vérifier le comportement des fonctions à l’intérieur de l’hexagone. Voici l’implémentation de ces tests:
[TestClass]
public class PizzaCalculatorTests
{
private Mock<IPizzaRepository> repositoryMock;
[TestInitialize]
public void Initialize()
{
this.repositoryMock = new Mock<IPizzaRepository>();
var pizzaStats = new List<PizzaStat>{
new PizzaStat { PizzaKind = PizzaKind.Regina, AverageSliceCount = 6},
new PizzaStat { PizzaKind = PizzaKind.Pepperoni, AverageSliceCount = 4},
new PizzaStat { PizzaKind = PizzaKind.Vegetarian, AverageSliceCount = 7},
};
this.repositoryMock.Setup(r => r.GetPizzaStatistics()).Returns(pizzaStats);
}
[TestMethod]
public void When_Requesting_PizzaCount_For_One_Person_Then_PizzaCalculator_Shall_Return_Proper_Pizza_Count(
{
var pizzaCalculator = new PizzaCalculator(this.repositoryMock.Object);
int pizzaCount = pizzaCalculator.GetPizzaCount(1, PizzaKind.Regina);
Assert.AreEqual(1, pizzaCount);
pizzaCount = pizzaCalculator.GetPizzaCount(1, PizzaKind.Pepperoni);
Assert.AreEqual(1, pizzaCount);
pizzaCount = pizzaCalculator.GetPizzaCount(1, PizzaKind.Vegetarian);
Assert.AreEqual(2, pizzaCount);
}
[TestMethod]
public void When_Requesting_PizzaCount_For_Several_Persons_Then_PizzaCalculator_Shall_Return_Proper_Pizza_Count()
{
var pizzaCalculator = new PizzaCalculator(this.repositoryMock.Object);
int pizzaCount = pizzaCalculator.GetPizzaCount(3, PizzaKind.Regina);
Assert.AreEqual(3, pizzaCount);
pizzaCount = pizzaCalculator.GetPizzaCount(3, PizzaKind.Pepperoni);
Assert.AreEqual(2, pizzaCount);
pizzaCount = pizzaCalculator.GetPizzaCount(3, PizzaKind.Vegetarian);
Assert.AreEqual(4, pizzaCount);
}
}
L’intérêt d’implémenter les tests est de montrer que la partie métier peut être testée puis développée séparément des adaptateurs qui constituent la couche technique de l’application.
On implémente ensuite la classe PizzaCalculator qui satisfait IPizzaCalculator et qui correspond à la partie métier de l’application:
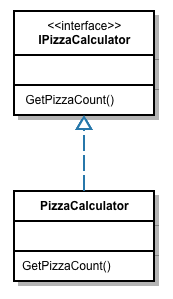
Son implémentation est:
public class PizzaCalculator : IPizzaCalculator
{
private const double sliceCountPerPizza = 6;
private IPizzaRepository pizzaRepository;
public PizzaCalculator(IPizzaRepository pizzaRepository)
{
this.pizzaRepository = pizzaRepository;
}
public int GetPizzaCount(uint personCount, PizzaKind pizzaKind)
{
var pizzaStats = this.pizzaRepository.GetPizzaStatistics();
var foundPizzaStat = pizzaStats.FirstOrDefault(s => s.PizzaKind.Equals(pizzaKind));
if (foundPizzaStat == null)
{
throw new InvalidOperationException("Type de pizza inconnu");
}
double pizzaCount = ((double)foundPizzaStat.AverageSliceCount * personCount)/sliceCountPerPizza;
return (int)Math.Ceiling(pizzaCount);
}
}
Maintenant que l’intérieur de l’hexagone est implémenté, on va implémenter les adaptateurs de la couche application.
Adaptateur primaire
On commence pour un adaptateur primaire qui permet de fournir des informations comme le nombre de personnes et le type de pizza choisie à partir de la Console. Cet adaptateur utilise directement le port primaire de l’hexagone IPizzaCalculator. Le nom de cet adaptateur primaire est ConsoleAdapter:
L’implémentation de ConsoleAdapter est:
public class ConsoleAdapter
{
private IPizzaCalculator pizzaCalculator;
public ConsoleAdapter(IPizzaCalculator pizzaCalculator)
{
this.pizzaCalculator = pizzaCalculator;
}
public void LaunchPizzaCalculation()
{
Console.WriteLine("Entrez le nombre de personnes: ?");
uint personCount = uint.Parse(Console.ReadLine());
Console.WriteLine(@"Entrez le type de pizza:
1-Vegetarian
2-Peperoni
3-Regina");
int pizzaKindAsInt = int.Parse(Console.ReadLine());
PizzaKind pizzaKind;
switch (pizzaKindAsInt)
{
case 1:
pizzaKind = PizzaKind.Vegetarian;
break;
case 2:
pizzaKind = PizzaKind.Pepperoni;
break;
case 3:
pizzaKind = PizzaKind.Regina;
break;
default:
throw new InvalidOperationException("Le type de pizza n'a pas été compris");
}
int pizzaCount = this.pizzaCalculator.GetPizzaCount(personCount, pizzaKind);
Console.WriteLine("Il faudra {0} pizza(s).", pizzaCount);
}
}
Adaptateur secondaire
On implémente ensuite un adaptateur secondaire de façon à récupérer les informations de statistique sur les pizzas. L’adaptateur secondaire doit satisfaire le port secondaire IPizzaRepository. Cet adaptateur sera utilisé par la fonction métier de l’hexagone. Le nom de cet adaptateur est RepositoryAdapter:
L’implémentation de RepositoryAdapter est:
public class RepositoryAdapter : IPizzaRepository
{
private readonly List<PizzaStat> pizzaStats = new List<PizzaStat>{
new PizzaStat { PizzaKind = PizzaKind.Regina, AverageSliceCount = 6},
new PizzaStat { PizzaKind = PizzaKind.Pepperoni, AverageSliceCount = 4},
new PizzaStat { PizzaKind = PizzaKind.Vegetarian, AverageSliceCount = 7},
};
public IEnumerable<PizzaStat> GetPizzaStatistics()
{
return this.pizzaStats;
}
}
Pour exécuter cet exemple, on doit d’abord instancier l’adaptateur secondaire RepositoryAdapter qui sera injecté dans l’hexagone. On instancie, ensuite, l’hexagone lui-même. En dernier, on instancie l’adaptateur primaire ConsoleAdapter qui utilisera l’hexagone:
static void Main(string[] args)
{
// Adaptateur secondaire
var repositoryAdapter = new RepositoryAdapter();
// Instanciation de l'hexagone et injection de l'adaptateur secondaire
var pizzaCalculator = new PizzaCalculator(repositoryAdapter);
// Adaptateur primaire
var consoleAdapter = new ConsoleAdapter(pizzaCalculator);
consoleAdapter.LaunchPizzaCalculation();
}
Il n’y a pas de tests pour les adaptateurs toutefois ils doivent être testés de la même façon que l’intérieur de l’hexagone.
Le code complet de cet exemple se trouve sur Github.
Le diagramme UML de cet exemple est:
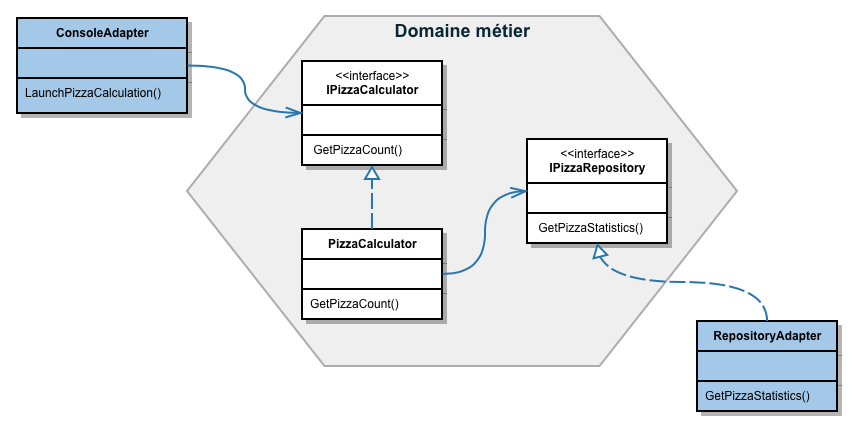
Dans cet exemple, si on change d’adaptateur, qu’on rajoute de nouveaux adaptateurs ou qu’on remplace ConsoleAdapter ou RepositoryAdapter, le domaine métier n’est pas impacté. A partir du moment où les nouveaux adaptateurs satisfont ou utilisent les ports définis dans le domaine, le code à l’intérieur de l’hexagone ne change pas. C’est l’intérêt de l’architecture hexagonale qui permet de préserver le domaine métier.
Inconvénients de l’architecture hexagonale
Anemic Domain Model
L’architecture hexagonale a beaucoup d’avantages et donne une grande flexibilité, toutefois elle ne convient pas dans toutes les situations. Outre la testabilité, un des objectifs de cette architecture est de permettre d’isoler et de préserver le domaine métier. Dans une application, il peut ne pas y avoir de domaine métier.
Par exemple, si une application ne sert qu’à afficher des données qu’elle récupère d’une ou plusieurs sources. S’il n’y a pas une logique de tri mais simplement une transformation des données pour les afficher, il n’y a pas réellement de domaine métier ou de règles fonctionnelles. Il n’y a donc pas forcément une grande nécessité de préserver des règles métier. Dans ce cas, l’utilisation d’une architecture de type hexagonale peut paraître superflue, voir elle peut amener une complexité complètement inutile.
Isoler un domaine métier qui ne comporte pas de logique fonctionnelle peut amener à développer ce que Martin Fowler avait qualifié d’Anemic Domain Model.
Les frontières du domaine restent floues
On a pu le voir dans l’exemple, les frontières du domaine ne sont pas franches, la séparation reste floue. C’est donc au développeur d’être vigilant et de savoir où il doit implémenter ses ports ou ses adaptateurs ce qui sous-entend une bonne compréhension de l’architecture d’un projet par toute l’équipe. Il faut avoir en tête que cette compréhension ne sera pas tout à fait la même pour tous les membres d’une équipe. Il faut donc marquer de façon plus franche les frontières du domaine, par exemple, en mettant les objets du domaine dans une assembly séparée.
Framework d’injection de dépendances
Dans un projet de grande taille et avec beaucoup d’objets, la quantité d’objets et les liens entre ces objets, peuvent s’avérer compliqués à appréhender. Il est donc préférable, dès le début du projet d’utiliser un framework d’injection de dépendances. Ce framework permettra une instanciation adaptée pour tous les objets en prenant en compte leur interactions et dépendances. De plus, il aidera, au moment d’enregistrer les différents objets, à séparer de façon plus franche les objets du domaine, des adaptateurs et plus généralement du monde extérieur.
En conclusion…
Pour conclure, on peut retenir que l’architecture hexagonale est une façon simple de séparer son domaine fonctionnel d’objets plus techniques destinés aux interactions entre l’extérieur et son application. Ce type d’architecture reste facile à mettre en œuvre et permet une plus grande flexibilité et une plus grande testabilité que des architectures plus monolithiques comme l’architecture 3-tiers. Enfin, ce type d’architecture implique la présence d’un domaine métier à préserver, s’il n’y en a pas son utilisation devient inutil.
- Article d’Alistair Cockburn: http://alistair.cockburn.us/Hexagonal+architecture
- Alistair Cockburn presenting Alistair in the “Hexagone” 1/3: https://www.youtube.com/watch?v=th4AgBcrEHA
- Alistair Cockburn presenting Alistair in the “Hexagone” 2/3: https://www.youtube.com/watch?v=iALcE8BPs94
- Alistair Cockburn presenting Alistair in the “Hexagone” 3/3: https://www.youtube.com/watch?v=DAe0Bmcyt-4
- Coder sans peur du changement avec la meme pas mal hexagonal architecture de Thomas Pierrain: https://www.slideshare.net/ThomasPierrain/coder-sans-peur-du-changement-avec-la-meme-pas-mal-hexagonal-architecture
- Ports-And-Adapters / Hexagonal Architecture: http://www.dossier-andreas.net/software_architecture/ports_and_adapters.html
- L’architecture hexagonale: https://medium.com/@marc.bojakowski/l-architecture-hexagonale-d151573b4185
- Pérennisez votre métier avec l’architecture hexagonale ! : http://blog.xebia.fr/2016/03/16/perennisez-votre-metier-avec-larchitecture-hexagonale/
- Hexagonal Architecture: https://marcus-biel.com/hexagonal-architecture/
- Hexagonal Architecture FAQ: http://alistair.cockburn.us/Hexagonal+Architecture+FAQ
- Hexagonal Architecture Is Powerful : https://dzone.com/articles/hexagonal-architecture-is-powerful
- Exploring the Hexagonal Architecture: https://www.infoq.com/news/2014/10/exploring-hexagonal-architecture
- Hexawhat Architecture?: https://www.novoda.com/blog/hexawhat-architecture/
- Ports and Adapter Pattern / Hexagonal Architecture : http://codingcanvas.com/hexagonal-architecture/
- Creating Clean Code with Hexagonal Architecture: https://www.viewfromthecodeface.com/portfolio/clean-code-hexagonal-architecture/
- Hello, Hexagonal Architecture: http://javaonfly.blogspot.fr/2017/02/hello-hexagonal-architecture.html
Très bon article, merci!
Simple, et bien exprime, merci!
Bon article mais un peu brouillon avec quelques contre vérité. Ca aurait mérité une relecture.
Je vais suivre votre conseil.
Je suis intéressé si vous avez 2 min pour m’indiquer les erreurs que vous avez relevé.
Bonjour,
Un bon article.
Je me permets juste quelques remarques par rapport à mon expérience personnelle.
Dans les faits j’utilise exactement cette architecture depuis des années, avec abstractions (interfaces) entre chaque couches, et transformation des entités passées entre les couches (Business en DTO dans le cas d’une application REST par exemple)….et j’ai toujours appelé ça n-tiers…
Je ne vois rien de différent dans ce concept d’hexagone (Ou alors je n’ai pas bien compris le passage sur la comparaison avec le 3-tiers).
J’ai toujours mes layers implémentants une interface pour pouvoir être injectés dans un autre layer, avec leurs dépendances injectées via le ctor (interfaces). Un Data Access Layer pour moi a toujours été une abstraction qui peut être implémenté par un accès à une DB, comme à un fichier ou une DB en mémoire (pour le Unit testing par exemple) ou même un autre appel REST ou RPC.
J’aurais aimé une comparaison d’exemple d’implémentation entre 3 tiers et Hexagonale pour mieux comprendre la différence, car j’ai l’impression que vous décrivez l’architecture 3 tiers comme une architecture hexagonale mais fortement couplée, ce qui depuis l’utilisation des frameworks de DI et Unit tests ne se fait plus forcement selon moi, et depuis pas mal d’années.