Cet article est un aide mémoire sur le Domain-Driven Design (DDD), il ne vise pas à expliquer le DDD mais simplement à rappeler les concepts clés.
Certains termes sont laissés volontairement en anglais en particulier lorsque leur traduction n’est pas très claire en français ou lorsque que le terme français n’est pas très utilisé.
Comprendre le domaine et le communiquer
Ubiquitous language
Extraire les domain models à partir du domaine
Analysis model
Model Driven Design
Patterns permettant d’implémenter un domain model
Les objets ou blocs d’objets préconisés par le DDD
Entité
Value-object
Service
Module
Aggregate
Factory
Repository
Concevoir une architecture compatible avec le DDD
Architecture en couches
La couche utilisateur
La couche application
La couche domaine
La couche infrastructure
Préserver la couche domaine
Aspects de conception utiles pour le DDD
Programmation orientée objet
Injection de dépendances
Garder les frontières du domaine
Persister des données
Utiliser des DTO
Intégrer les règles métier
Gestion de projet
Comment préserver le modèle
Bounded context
Intégration continue
Context map
Quelques patterns pour préserver le modèle
Shared kernel
Customer-Supplier
Anticorruption layer
Open Host Service
Separate Ways
Conformist
Erreurs lors de l’implémentation d’un projet DDD
Inconvénients du DDD
Difficile de convaincre les acteurs métier
Apprentissage de l’ubiquitous language et du domaine
Représenter le domain model
Le domain model doit rester couplé au modèle du code
Définition
La conception pilotée par le domaine (i.e. Domain-Driven Design ou DDD) est une approche de conception logicielle définie par Eric Evans qui vise à accorder de l’importance au domaine métier.En effet, dans la plupart des logiciels, la logique métier qui est implémentée est ce qui constitue la plus grande valeur ajoutée puisque c’est cette logique qui rend le logiciel fonctionnel.
Pourtant très souvent une grande part des développements se concentrent sur d’autres parties comme l’interface graphique, à la persistance des données ou au partage d’informations avec des systèmes externes.
DDD n’est pas une méthode pour concevoir des logiciels mais juste une approche qui permet d’indiquer comment concevoir un logiciel en prenant davantage en compte le domaine métier.
L’intérêt de DDD est:
- Permettre à l’équipe de créer un modèle et de le communiquer aux experts métier mais aussi à d’autres acteurs de l’entreprise avec les spécifications fonctionnelles, les entités du modèle de données et la modélisation de processus.
- Le modèle est modulaire et plus facile à maintenir.
- Il améliore la testabilité et la généricité des objets du domaine métier.
L’approche DDD vise, dans un premier temps, à isoler un domaine métier. Un domaine métier riche comporte les caractéristiques suivantes:
- Il approfondit les règles métier spécifiques et il est en accord avec le modèle d’entreprise, avec la stratégie et les processus métier.
- Il doit être isolé des autres domaines métier et des autres couches de l’architecture de l’application.
- Le modèle doit être construit avec un couplage faible avec les autres couches de l’application
- Il doit être une couche abstraite et assez séparée pour être facilement maintenue, testée et versionnée.
- Le modèle doit être concu avec le moins de dépendances possibles avec une technologie ou un framework. Il devrait être constitué par des objets POCO (Plain Old C# Object). Les POCO sont des objets métier disposant de données, de logique de validation et de logiques métier. Il ne doit pas comporter de logique de persistance.
- Le domaine métier ne doit pas comporter de détails d’implémentation de la persistance.
Comprendre le domaine et le communiquer
Le domaine est connu par les spécialistes du domaine qui sont des experts. Il faut donc rencontrer ces experts pour comprendre toutes les subtilités du domaine. A terme, le logiciel implémenté modélisera le domaine. Toutefois avant que le logiciel ne devienne le reflet du domaine, il faut le comprendre.
Cette compréhension permettra, dans un premier temps, de modéliser le domaine (c’est-à-dire extraire le modèle). Il n’y a pas de méthode pour modéliser le domaine mais on peut s’aider de dessins, diagrammes, simplement un texte écrit etc… Le plus important est de comprendre le domaine pour le communiquer.
La communication du modèle passe par des entrevues entre experts du domaine, concepteurs logiciels et développeurs.
Ubiquitous language
Un frein à la communication du modèle pourrait être l’utilisation d’un langage spécialisé ou technique de la part des experts ou des développeurs. Ce langage spécialisé tend à rendre la compréhension du domaine compliqué pour chacun des acteurs. Il est donc important de se mettre d’accord sur un vocabulaire commun et compréhensible de tous dont le but ultime est un domaine compréhensible et exploitable.
Ce vocabulaire commun est l’ubiquitous language (i.e. “langage omniprésent”), il permet de:
- Trouver les concepts clés qui définissent le domaine et ensuite la conception
- Révéler les expressions utilisées dans le domaine
- Chercher à résoudre les ambiguités et inconnues
L’ubiquitous language ne s’élabore pas en une seule itération, il est le fruit de plusieurs discutions avec les experts du domaine.
Pour l’élaborer, il faut:
- Eviter d’utiliser des termes que les experts n’ont pas prononcés.
- Créer un glossaire contenant les termes utilisés par les experts du domaine de façon à les expliquer.
- Vérifier qu’un terme est utilisé pour un seul concept.
- Eviter d’utiliser des termes trop proches de solutions techniques ou de “design patterns”. Ces termes peuvent diriger les développeurs vers une solution particulière et ils peuvent être incompréhensible par les experts du domaine.
- Les termes de l’ubiquitous language doivent se retrouver dans le code pour qualifier des propriétés, des comportements qui implémentent une partie du domaine et surtout les tests. Si l’ubiquitous language est compris, le code sera plus clair.
- Les évolutions de l’ubiquitous language peuvent se traduire par des modifications des noms ou comportements utilisés dans le code.
- Il n’est pas nécessaire d’élaborer un ubiquitous language pour toute l’application. Il est préférable de réserver cette démarche aux parties complexes du domaine.
Extraire les domain models à partir du domaine
Le domain model (i.e. modèle du domaine) est une version simplifiée et implémentable du domaine. Le domain model ne contient que la partie du domaine pour laquelle le logiciel doit apporté une solution. Le domain model sera utile s’il représente efficacement la logique complexe du domaine pour permettre la résolution du problème tout en étant compréhensible des experts du domaine.
Dans une approche idéale, et dans une première version, le domain model ne doit pas trop prendre en compte la solution technique mise en œuvre pour l’implémentation. Toutefois, lors des phases suivantes de traduction du domain model, l’équipe de développement va probablement lever des incohérences, des ambiguités ou des points techniques bloquants qui vont remettre en cause le domain model. Après des entrevues avec les experts du domaine, des refactorings successifs permettront d’aboutir à un domain model implémentable tout en étant fidèle au domain dont il est censé être la réduction.
Ainsi, l’approche DDD insiste sur 3 points qui sont essentiels à la bonne marche d’un projet:
- La connaissance du domaine.
- L’ubiquitous language.
- La collaboration entre les développeurs et les experts du domaine.
La représentation du domain model peut se faire en utilisant UML. Pour avoir plus de détails sur l’UML: UML en français.
Plus le domaine est complexe et plus le domain model devra résoudre des problèmes complexes. Dans la pratique, pour un domaine complexe, il faut pas utiliser qu’un seul mais plusieurs domain models qui adresseront chacun un problème différent.
Analysis model
Le domain model permet d’élaborer le modèle d’analyse (i.e. “analysis model”) qui va aider les développeurs à comprendre les problèmes du domaine.
Code model
Le modèle du code (i.e. “code model”) est une version du domaine utilisée pour l’implémentation. Il est différent du domain model puisqu’il n’est compréhensible que par les développeurs. Il est le lien entre le domain model qui est loin des considérations d’implémentation et le code.
Lors de la traduction du domain model en code:
- Ce sont les développeurs qui effectuent la traduction du modèle en code.
- Des défauts peuvent apparaître dans l’implémentation, ces défauts doiven faire l’objet de “refactorings”.
- Plus le code est lié au domain model et à l’ubiquitous language et plus les développeurs comprendront facilement le modèle.
- Les développeurs doivent faire des feedbacks pouvant mener, éventuellement, à des “refactorings”.
- Il faut éviter des trop grandes différences entre le code et le domain model sinon le modèle pourrait ne plus être compréhensible en cas de “refactoring” par les autres acteurs que les développeurs.
Model Driven Design
La conception dirigée par le modèle (i.e. “Model Driven Design”) permet d’assurer le lien entre le modèle d’analyse et le modèle de code. Cette approche se focalise davantage sur l’implémentation par rapport à l’approche DDD qui plus des indications sur l’élaboration de l’ubiquitous language, de la collaboration avec les experts du domaine et la connaissance partagée du domaine.
La conception dirigée par le modèle permet à la connaissance du domaine et de l’ubiquitous language d’être incorporés dans le modèle de code. Il devient alors, une interprétation du langage et du modèle mental des experts du domaine.
- Des problèmes simples ne nécessitent pas forcément l’approche plus complexe de la conception dirigée par le modèle.
- Il n’est pas nécessaire de concevoir toute l’application en utilisant la conception dirigée par le modèle.
- Cette approche convient davantage pour résoudre les problèmes du domaine les plus complexes.
Patterns permettant d’implémenter un domain model
Quelques patterns peuvent convenir pour implémenter un domain model:
- Domain Model: pattern définit par Martin Fowler dans Patterns of Entreprise Application Architecture. Il permet de concevoir un modèle en utilisant la conception dirigée par le modèle en opposition à la conception dirigée par la base de données.
En utilisant ce pattern, la persistence des données vient après la conception des objets du domaine. Les objets du domaine sont de type POCO (Plain Old C# Objects). DDD permet d’étoffer ce pattern en préconisant des objets ou des blocs d’objets particuliers.
Ce pattern impose que les objets du domaine soient décorélés de l’infrastructure technique avec une architecture en couches. - Transaction Script: ce pattern est beaucoup plus simple que domain model. Il envisage de tout mettre dans un seul objet : workflow métier, règles métier, règles de validation et persistence en base de données. L’accès à l’implémentation de l’objet se fait de façon procédurale. Ce pattern convient pour les cas très simples où la logique métier est très faible. Toutefois il n’apporte pas de solutions génériques pour certaines problématiques techniques comme les accès concurrents, les problèmes de cohérence entre objets ou la logique de persistence. C’est la raison pour laquelle il doit s’appliquer seulement dans le cas où la logique métier est appliquée de façon procédurale.
- Table Module: un objet du modèle correspond à un objet en base de données comme une vue ou une table. Chaque objet est responsable de sa persistence en base. Ce pattern ne convient pas forcèment bien dans une approche DDD mais il peut s’avérer facile à implémenter dans le cas simple où un objet métier est très lié à la base de données.
- Active Record: un object du modèle correspond à une ligne dans un objet en base de données. Ce pattern convient s’il y a un mapping un à un entre le modèle de données et le modèle métier. Chaque objet est responsable de sa persistence en base.
- Anemic Domain Model: ce pattern correspond au cas où l’objet du modèle ne possède aucune logique, il ne contient que des propriétés. Toute la logique de gestion de ces objets (comme la persistence par exemple) se trouve à l’extérieur de l’objet, dans la couche de service. Même si un domain model implémenté suivant Anemic Domain Model n’est que conteneur sans logique métier, il peut incorporer des éléments de l’ubiquitous language par la seule présence de propriétés.
Les objets ou blocs d’objets préconisés par le DDD
Pour aider à l’élaboration du domain model, DDD préconise un certain nombre d’objets, toutefois elle n’impose pas des les utiliser absolument. Comme dans la plupart des cas, on est libre d’envisager une architecture n’utilisant ces différents objets.
Entité
Les objets entités contiennent une identité:
- L’identité est identique durant tous les états du logiciel
- La référence à l’objet est de préférence unique pour assure une certaine cohérence.
- Il ne devrait pas exister 2 entités avec la même identité sous peine d’avoir un logiciel dans un état incohérent.
- L’identité peut être un identifiant unique ou une combinaison de plusieurs membres de l’entité.
Value-object
Ce sont des objets n’ayant pas d’identité:
- Les value-objects n’ont pas d’identité car ils sont utilisés principalement pour les valeurs de leurs membres.
- Ces objets peuvent facilement créés ou supprimés car il n’y a pas de nécessité de maintenir une identité.
- L’absence d’identité permet d’éviter de dégrader les performances durant la création et l’utilisation de ces objets par rapport aux entités.
- Les value-objects peuvent être partagés
- Dans le cas de partage de value-objects, il faut qu’ils soient immuables c’est-à-dire qu’on ne puisse pas les modifier durant toute leur durée de vie.
- Les value-objects peuvent contenir d’autres value-objects.
Service
Lorsqu’on définit l’ubiquitous language, le nom des concept-clés permettent de definir les objets qui seront utilisés. Les verbes utilisés qui sont associés aux noms permettront de définir les comportements de l’objet. Ces comportements seront implémentés directement dans l’objet.
Ainsi, lorsque des comportements ne peuvent être associés à un objet, ils doivent être implémentés en dehors de tout objet, dans un service:
- L’opération dans le service fait référence à un concept du domaine qui n’appartient pas à une entité ou à un value-object.
- Un service peut effectuer un traitement sur plusieurs entités ou value-objects.
- Les opérations n’ont pas d’états.
- Les services ne doivent pas casser la séparation en couche, ainsi un service doit être spécifique à une couche.
Module
Permet de regrouper les classes pour assurer une cohésion:
- dans les relations entre les objets
- dans les fonctionnalités gérées par ces objets.
L’intérêt est d’avoir une vue d’ensemble en regardant les modules, on peut ensuite s’intéresser aux relations entre les modules.
Les modules doivent:
- former un ensemble de concepts cohérents, de façon à réduire le couplage entre les modules.
- Le couplage faible permet de réduire la complexité et d’avoir des modules sur lesquels on peut réfléchir indépendamment.
- Etre capable d’évoluer durant la durée de vie du logiciel.
- Etre nommés suivant des termes de l’ubiquitous language.
Aggregate
Les objets du modèle ont une durée de vie:
- Ils peuvent être créés, placés en mémoire pour être utilisés puis détruits ensuite.
- Ils peuvent aussi être persistés en mémoire ou dans une base de données.
La gestion de cette durée de vie n’est pas facile car:
- Les objets peuvent avoir des relations entre eux : 1 à plusieurs, plusieurs à plusieurs.
- Il peut exister des contraintes entres les objets au niveau de leur relation : par exemple unidirectionnel ou bidirectionnel.
- Il peut être nécessaire de maintenir des invariants c’est-à-dire des règles qui sont maintenues même si les données changent.
- Il faut assurer une cohésion du modèle même dans le cas d’association complexe.
Une méthode est d’utiliser un groupe d’objets comme les agrégats (i.e. “aggregate”). Les agrégats sont des groupes d’objets associés qui sont considérés comme un tout unique vis-à-vis des modifications des données, ainsi:
- Une frontière sépare l’agrégat du reste des objets du modèle,
- Chaque agrégat a une racine qui est une entité qui sera le lien entre les objets à l’intérieur et les objets à l’extérieur de l’agrégat.
- Seule la racine possède une référence vers les autres objets de l’agrégat.
- L’identité des entités à l’intérieur de l’agrégat doivent être locale et non visible de l’extérieur.
- La durée de vie des objets de l’agrégat est liée à celle de la racine.
- La gestion des invariants est plus facile car c’est la racine qui le fait.
- La racine utilise des références éphémères si elle doit passer des références d’objets internes à des objets externes. L’intégrité de l’agrégat est, ainsi, maintenue.
- On peut utiliser des copies des value-objects.
Factory
Les fabriques sont inspirées du “design pattern” pour créer des objets complexes:
- Elles permettent d’éviter que toute la logique de création des objets ne se trouve dans l’agrégat.
- Permet d’éviter de dupliquer la logique de règles s’appliquant aux relations des objets.
- Il est plus facile de déléguer à une fabrique la création d’une agrégat de façon atomique.
- La gestion des identités des entités n’est pas forcément triviale car des objets peuvent être créés à partir de rien, ils peuvent aussi avoir déjà existé (il faut être sûr qu’il n’existe pas encore une autre entité avec le même identifiant) ou il peut être nécessaire d’effectuer des traitements pour récupérer les données de l’entité en base de données par exemple.
L’utilisation de fabriques n’est pas indispensables, on peut privilégier un constructeur simple quand:
- La construction n’est pas compliquée : pas d’invariants, de contraintes, de relations avec d’autres objets.
- La création n’implique pas la création d’autres objets et que toutes les données membres soient passées par le constructeur.
- Il n’y a pas de nécessité de choisir parmi plusieurs implémentations concrètes.
Repository
Dans le cas d’utilisation d’agrégats, si un objet externe veut avoir une référence vers un objet à l’intérieur, il doit passer par la racine et ainsi, avoir une référence vers la racine de l’agrégat, ainsi:
- Maintenir une liste de références vers des racines d’agrégat peut s’avérer compliqué dans le cas où beaucoup d’objets sont utilisés. Une mise à jour de la référence de la racine auprès de plusieurs objets peut s’avérer couteux.
- L’accès à des objets de persistance se fait dans la couche infrastructure, les implémentations permettant d’y accéder peuvent se trouver dans plusieurs objets et ainsi être dupliquées.
- Un objet du modèle ne doit contenir que des logiques du modèle et non les logiques permettant d’accéder à une base de persistance.
Utiliser un repository permet:
- D’encapsuler la logique permettant d’obtenir des références d’objets.
- Stocker des objets
- D’utiliser une stratégie particulière à appliquer pour accéder à un objet.
L’implémentation d’un repository peut se faire dans la couche infrastructure toutefois l’interface de ce repository fait partie du modèle.
Le repository et la fabrique permettent, tout deux, de gérer le cycle de vie des objets du domaine:
- La fabrique permet de créer les objets
- Le repository se charge de gérer des objets déjà existants.
Concevoir une architecture compatible avec le DDD
Architecture en couches
DDD préconise de séparer le code en couche pour ne pas diluer la logique métier dans plusieurs endroits. Chaque couche a une fonction particulière qui est utilisable par d’autres couches de façon à:
- Mutualiser le code suivant une logique
- Éviter la duplication de code métier
Les 4 couches sont:
- la couche utilisateur,
- la couche application,
- la couche domaine et
- la couche infrastructure.
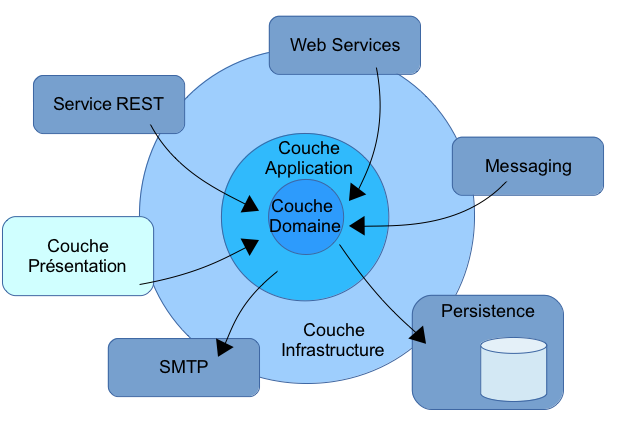
La couche utilisateur
Elle présente l’information à l’utilisateur et réceptionne ses commandes. Cette couche peut faire appel à toutes les autres.
La couche application
La couche application (i.e. “application service layer”) sépare la couche utilisateur de la couche domaine:
- Elle ne contient pas de code métier mais peut être amenée à contenir du code permettant de gérer des changements dans la couche utilisateur.
- Elle ne doit pas garder l’état des objets métier mais peut stocker l’état d’avancement d’une tâche de l’application.
- Elle permet d’effectuer la navigation entre les écrans de l’interface graphique et les interactions avec les couches application d’autres systèmes.
- Elle peut effectuer des validations basiques (non liées à des règles métier) sur les entrées de l’utilisateur avant de les transmettre aux autres couches de l’application.
- Elle ne doit pas contenir de logique métier ni de logique d’accès aux données.
- Cette couche peut faire appel à la couche domaine et à la couche infrastructure.
Cette couche peut permettre d’isoler la couche domaine des aspects techniques nécessaires à son fonctionnement. Elle peut contenir les services applicatifs et servir d’intermédiaire entre la couche domaine et les objets qui y font appels. Elle expose les capacités du système en proposant une abstraction à la logique du domaine contenue dans la couche domaine. Elle tends grandement à préserver le domaine en concentrant de nombreux éléments de logique applicative.
Cette couche de services sert aussi d’implémentation concrête à la frontière du contexte borné, elle peut assurer les échanges avec les autres contextes bornés en utilisant, par exemple, des services REST, des web services ou par l’intermédiaire d’un bus de communication.
La couche domaine
Elle contient les informations sur le domaine et la logique métier:
- Elle détient tous les concepts du modèle métier, les cas d’utilisation et les règles métier.
- Elle contient l’état des objets métier toutefois elle n’effectue pas directement la persistance des objets métier.
- Elle peut aussi contenir l’état d’un cas d’utilisation métier si celui-ci est formé de plusieurs requêtes de l’utilisateur.
- Elle peut contenir des objets de service si leur comportement ne peut être implémenté dans un objet métier. Les services contiennent des comportements métier qui ne peuvent pas faire partie d’un objet du modèle.
- Cette couche est le coeur du métier, elle doit être isolée des autres couches et ne peut être dépendantes de framework.
- Cette couche ne peut faire appel qu’à la couche infrastructure.
La couche infrastructure
Elle permet de fournir un lien de communication entre toutes les autres couches. D’autre part, elle contient le code de persistance des objets métier. Cette persistance n’est pas forcément dans une base de données.
Les relations entre les couches peuvent être directes toutefois il est préférable que les relations se fassent des couches hautes (par exemple la couche utilisateur) vers les couches basses (couche infrastructure).
L’approche SOA (pour “Service-Oriented Architecture”) ne dispense pas d’une réflexion sur le modèle métier. On pourrait croire que cette approche permet d’isoler par construction un modèle métier, pourtant dans le cas où on accorde pas assez d’importance à la conception du modèle, une approche SOA entraînera une implémentation avec les mêmes conséquences que pour architecture classique : une couche de service hypertrophiée (Fat Service Layer) et une modèle métier anémique (Anemic Domain Model).
Dans l’approche SOA, il faut donc accorder le même degré d’effort à la conception d’un domain model:
- Avant tout, isoler un domain model qui encapsulera la logique métier et les règles métiers des objets
- Implémenter le service en même temps que la couche application de façon à ce que les composants du service puissent consommer les éléments du modèle métier.
- Le service deviendra juste un “proxy” pour atteindre le modèle métier.
Préserver la couche domaine
La couche domaine ne doit pas être influencée par des éléments de la logique applicative. La logique applicative comprends la coordination entre le domaine et les services qui se trouvent dans la couche infrastructure.
Cette logique vise à répondre à des sollicitations provenant de la couche utilisateur, de la couche application mais aussi provenant d’autres domain models et de les présenter à la couche domaine. Les sollicitations peuvent aussi provenir de la couche domaine, par exemple pour notifier des changements de l’état du domaine.
Ainsi, pour préserver la couche domaine, cette logique applicative doit se trouver dans les services de la couche application ou infrastructure.
Aspects de conception utiles pour le DDD
Programmation orientée objet
Les concepts de la programmation orientée objet (comme l’héritage, l’encapsulation ou le polymorphisme) sont utiles à la conception d’objets métier car ils permettent d’étendre des comportements ou des états à plusieurs objets ou au contraire à les spécialiser. Les objets utilisés en DDD comportent des états au travers des données membres et de comportements avec les fonctions et méthodes.
Les objets du modèle métier ont besoin de collaborer avec d’autres objets comme les services, les repositories ou les factories. Ces objets ont aussi besoin de gérer des états ou comportements communs comme le suivi, de l’audit, effectuer de la mise en cache ou la gestion de transaction qui sont transverses. La programmation orientée objet permet de ne pas trop alourdir l’implémentation des objets du modèle en fournissant des solutions pour apporter ce type de caractéristiques (appliquer le principe SOLID).
Injection de dépendances
Permet de réduire le couplage entre les objets en injectant les dépendances. La plupart des objets du modèle peuvent avoir besoin d’accéder à d’autres objets comme les repositories ou les services. Ces besoins récurrents pour beaucoup d’objets du domaine peuvent mener à un fort couplage. L’injection de dépendances permet de réduire ce couplage.
Dans le cadre du DDD et avec l’utilisation de l’architecture en couches, il peut être nécessaire d’injecter dans la couche du domaine des objets de la couche infrastructure (par exemple si on veut persister des objets dans une base de données). Or la couche domaine ne doit pas avec de dépendances vers la couche infrastructure. Ainsi l’injection de dépendances va permettre d’effectuer une inversion de dépendances entre la couche domaine et la couche infrastructure pour que la couche domaine puisse accéder à des objets de la couche instructure.
Plus de détails sur l’injection de dépendances dans Injection de dépendances en utilisant Unity en 10 min.
Garder les frontières du domaine
Il faut définir une frontière entre le domaine et le reste de l’application pour éviter que la couche du domaine soit trop facilement corrompue avec des objets qui n’ont pas de liens avec le domaine métier. Les états (les données) et les comportements (les opérations) du domaine doivent être stockés dans les objets du domaine suivant leur nature:
- Les entités, les value-objects et les agrégats peuvent stocker un état et implémeter un comportement.
- Les DTO stockent seulement des états.
- Les services et les repositories implémentent des comportements.
Ainsi, il faut observer certaines règles:
- Les comportements ne doivent pas dépassés la frontière des objets qui les implémentent.
- Les entités doivent gérer leur état propre.
- On doit éviter de pouvoir modifier directement l’état d’un objet : si on veut modifier l’état d’un objet, on en crée un nouveau avec un état modifié.
- Les agrégats permettent de cacher la collaboration de plusieurs classes à l’objet appelant ce qui permet d’encapsuler la complexité de la gestion des états des classes du domaine.
Persister des données
Pour éviter d’être trop couplé à des technologies de persistance (base de données relationnelles, Big Data, Cloud etc), on peut s’aider de DAO (Data Access Object) et des repositories qui permettent d’encapsuler des opérations CRUD.
Les repositories utilisent l’ubiquitous language et utilisent, le cas échéant, des DAO qui sont proches de la technologie utilisée pour le stockage de données. Les objets du domaine accèdent aux repositories seulement, ce qui permet de rester découpler par rapport aux technologies de persistance. Les repositories peuvent être injectés dans les objets du domaine en utilisant, par exemple, de l’injection de dépendances.
Utiliser des DTO
Les DTO (pour “Data Transfer Object”) peuvent être utilisés pour garantir une séparation entre les différentes couches. Utiliser des DTO permet d’isoler les couches basses (par exemple Infrastructure) des autres couches.
Intégrer les règles métier
Les règles métier font partie d’une des catégories suivantes:
- Validation de données
- Transformation de données
- Prise de décision métier
- Traitement de workflows
Ces règles sont généralement dépendantes d’un contexte métier. Dans un contexte différent, d’autres règles métiers émergeront.
Les règles métier doivent être implémentées dans la couche du domaine, chaque règle devrait être implémentée dans un objet de type Entité. Si une règle doit être partagée entre plusieurs objets, elle devrait être implémentée dans un objet de type Service.
Pour intégrer des règles métier, des moteurs de règles ne sont pas forcément nécessaires, il faut trouver un moyen pour:
- Prendre en compte la complexité des règles, un langage comme le C# permet d’implémenter une logique complexe.
- Rendre flexible la modification, l’ajout ou la suppression des règles en fonction de certaines critères.
- Tester l’exécution des règles.
On peut éventuellement s’aider de langage scripté comme Dynamic Language Runtime (DLR) pour apporter une solution technique à l’aspect dynamique des règles métier.
Gestion de projet
Les étapes de la conception du modèle sont:
- Conception et documentation les processus métier.
- On sélectionne un processus métier et on discute avec les experts métier pour documenter ce processus en utilisant l’ubiquitous language.
- On identifie tous les services qui sont nécessaires au processus métier. Les services peuvent être consommés de façon unitaire ou couplés avec d’autres services (par exemple en faisant intervenir un workflow).
- On identifie et on documente les états et comportements des objets utilisés par les services identifiés dans l’étape précédente.
La gestion d’un projet DDD comprends les mêmes étapes qu’un projet de développement logiciel classique:
- Modélisation du modèle métier
- Conception
- Développement
- Tests unitaires et tests d’intégration
- Etapes de “refactoring” pour affiner le modèle métier basées sur la conception et le développement (intégration continue).
- L’étape précédente est répétée en fonction des mises à jour du modèle métier.
La méthodologie agile convient bien à ce type de projet car:
- Elle préconise des “refactorings” du code pour arriver à une compréhension du domaine,
- Elle permet aux développeurs de remonter les éventuels problèmes pour encourager les “refactorings”.
- Elle permet d’éviter les effets tunnel qui peuvent fatals à une équipe de développement dans la maîtrise de ses coûts.
Comment préserver le modèle
Les gros projets sont généralement composés de plusieurs équipes. Pour que le modèle reste cohérent malgré la division en plusieurs équipes séparées:
- Chaque partie du projet doit être assignée à une équipe
- Une modification dans une partie du modèle maintenue par une équipe ne doit pas déstabiliser le modèle en le rendant incohérent.
- Il faut diviser le domaine en plusieurs modèles, définir des frontières entre les modèles et les liaisons entre eux.
Cette partie indique quelques patterns généraux permettant d’organiser une équipe de développement pour préserver le modèle général.
Bounded context
Un domaine s’applique implicitement à un contexte particulier. Diviser le domaine en plusieurs sous-domaine implique d’appliquer un contexte différent à chaque sous-domaine. Chaque sous-domaine devient donc limité à un contexte d’où le contexte borné (i.e. “bounded context”). La division en contexte borné est une des étapes les plus importantes dans un projet DDD.
Ainsi:
- Les sous-modèles doivent être assez petits pour être applicable à une équipe.
- Le contexte d’un modèle est l’ensemble des conditions qu’on doit appliquer pour s’assurer que les termes utilisés dans le modèle prennent une sens précis.
- Définir les limites du contexte permet de préserver l’unité du modèle.
- Il est plus facile de maintenir un modèle quand son périmètre est connu.
- Il faut bien délimiter le contexte pour éviter des duplications de logique métier si un sous-modèle empiète sur un autre.
- Les échanges entre sous-domaine peuvent se faire avec des value-objects par exemples.
- Un contexte englobe la notion de module.
Les divisions en contexte borné peuvent se faire suivant des critères différents:
- Si une ambiguité est apparue dans l’ubiquitous language ou dans les concepts métier et qu’elle nécessite d’envisager deux contextes différents.
- Pour être plus en phase avec l’organisation de plusieurs équipes ou leur emplacement physique.
- Pour qu’un sous-domaine soit lié à sa fonction métier.
- Intégrer du code “legacy” ou du code tiers.
- Si plusieurs langages de programmation ou plusieurs technologies sont utilisés.
Un sous-domaine ne correspond pas forcément précisement à un contexte borné. En effet, un sous-domaine résulte d’une séparation fonctionnelle du domaine. Idéalement il faudrait un domain model pour chaque sous-domaine toutefois un sous-domaine peut contenir plusieurs domain models. Un contexte borné correspond à une implémentation concrète et à une séparation technique qui applique des frontières aux objets du domain model. Ainsi, un sous-domaine comporte un ou plusieurs contextes bornés et un contexte borné comporte un ou plusieurs domain models.
Le partage d’objets entre contextes bornés peut mener à des incohérences dans le domain model. En effet des objets provenant d’autres contextes bornés peuvent avoir été concus avec un ubiquitous language différent. Il faut donc éviter de partager directement des données entre contexte borné. Les échanges de données doivent se faire avec des DTO ou par l’intermédiaire d’une couche anticorruption.
Intégration continue
L’intégration continue (i.e. “continuous delivery”) est un outil important dans un projet DDD car il permet de maintenir la cohérence du modèle malgré les changements dans les sous-modèles. Les “refactorings” successifs par les différentes équipes doivent préserver les fonctionnalités. Ainsi l’intégration continue doit:
- Effectuer une compilation automatique du code de chaque équipe.
- Notifier des erreurs de compilation aux membres des équipes.
- Appliquer des tests automatiques.
- Permettre d’intégrer régulièrement le travail de toutes les équipes.
Context map
Un contexte borné peut correspondre à une équipe toutefois tout le monde doit garder une vue d’ensemble du projet. Ainsi la carte de contexte (i.e. “context map”) permet d’indiquer les liaisons entre les contextes bornés. Sur la carte de contexte, chaque contexte borné possède un nom qui fait partie de l’ubiquitous language.
Quelques patterns pour préserver le modèle
Des problèmes peuvent se poser lors des “refactorings” successifs en particulier si:
- On utilise un seul domain model pour répondre à toutes les problématiques.
- Plusieurs équipes sont impliquées dans le projet.
- La logique métier est particulièrement complexe.
- Il est nécessaire d’intéger du code “legacy” ou du code provenant de tiers.
Shared kernel
Le noyau partagé (i.e. “shared kernel”) est un pattern qui permet à 2 équipes de se partager un sous-ensemble du modèle, ainsi:
- Chaque modification doit impliquer les deux équipes.
- Chaque équipe à un contexte borné mais elles se coordonnent pour une partie du modèle qu’elles ont en commun.
- Le noyau partagé permet d’éviter d’avoir du code d’une autre équipe à intégrer.
- Ce pattern permet d’éviter les doublons tout en gardant des contextes séparés.
- Des tests permettent de garantir que le code partagé ne sera pas cassé lors d’un “refactoring” par une des équipes.
Customer-Supplier
Client-Fournisseur (i.e. “Customer-Supplier”) s’applique lorsqu’une équipe dépend d’une autre et qu’il n’est pas possible d’appliquer le noyau partagé:
- Cette organisation est plus difficile à maintenir car il est plus difficile d’identifier les éventuelles régressions amenées par l’équipe “fournisseur”.
- Les tests sont particulièrement importants pour limiter les régressions dues aux “refactorings”.
- L’équipe cliente doit énoncer des besoins et l’équipe “fournisseur” doit y répondre avec des plans.
- Une interface définie au préalable permet de coordonner les deux équipes.
Anticorruption layer
Un domain model peut devoir s’interfacer avec d’autres domain models développés par d’autres équipes dans un contexte différent. Sachant que le contexte est différent, les autres équipes ont développés un ubiquitous language qui est peut-être différent. Pour éviter d’introduire des termes de l’ubiquitous language des autres domain models, on peut être amené à developper une couche anticorruption (i.e. “anticorruption layer”). Cette couche permet d’adapter et de convertir les objets nécessaires à l’interface avec d’autres domain models dans un contexte borné différent.
La couche anticorruption peut aussi servir si on doit s’interfacer avec du code “legacy” ou du code tiers qui n’a pas été conçu avec l’ubiquitous language.
Open Host Service
L’Open Host Service (i.e. Service Hôte ouvert) est équivalent à la couche anticorruption. La couche anticorruption sert à adapter les appels vers d’autres contextes en introduisant une couche de traduction, si un contexte doit s’interfacer avec plusieurs autres contextes, il y aura autant de couches anticorruption que d’interfaces entre les contextes. Le pattern Open Host Service sert aussi de couche d’interface entre 2 contextes toutefois il préconise d’utiliser une seule couche pour plusieurs contextes. Ainsi la logique de transformation doit être commune à tous les contextes client. Tous les clients seront alors concernés dans le cas d’un changement de l’interface.
L’intérêt du pattern Open Host Service est d’éviter de dupliquer une logique de transformation pour plusieurs couches en particulier si elle est semblable d’un contexte client à l’autre.
Separate Ways
Lorsque 2 contextes s’interfacent suivant des patterns comme Shared Kernel ou Customer-Provider, il peut être de plus en plus couteux de maintenir une implémentation commune avec un autre contexte ou d’intégrer les nouvelles interfaces de l’autre contexte. Ainsi il peut être plus efficace d’envisager une séparation franche entre les deux contextes. Cette séparation peut avoir des conséquences importantes qui peuvent se traduire par des divergences dans plusieurs couches de haut niveau comme la couche utilisateur. Dans le cas où le pattern Chemin Séparé (i.e. Separate Ways) est adopté par 2 contextes qui veulent se séparer, il faut réfléchir sur toutes les conséquences de la séparation sur le long terme parce qu’il peut être très compliqué de revenir en arrière.
Conformist
Le pattern Conformiste s’applique dans le cas où un contexte consomme des objets d’un autre contexte. Il doit alors se conformer à l’interface du contexte qu’il consomme. L’exemple le plus courant de ce pattern consiste à consommer des données externes provenant d’applications tiers. On a pas le choix de l’interface et il est compliqué d’obliger l’application tiers à adapter son interface à ses besoins. Contrairement au pattern Client-Fournisseur, ce pattern préconise de s’adapter aux interfaces de l’application que l’on consomme.
Erreurs lors de l’implémentation d’un projet DDD
L’approche DDD est complexe à mettre en place tant au niveau de la collaboration avec les experts du domaine et que sur l’aspect plus technique de l’architecture. Ainsi quelques erreurs peuvent être éviter pour se focaliser sur ces points de complexité:
- Eviter d’utiliser la même architecture pour tous les contextes bornés. Certains contextes sont moins complexes que d’autres.
- De la même façon, on ne doit pas réutiliser un modèle existant. Dans le cas d’une réutilisation, on essaie peut-être de résoudre une problématique qui a déjà été résolue (appliquer le principe DRY pour “Don’t Repeat Yourself”).
- Tenter de comprendre les problèmes métier et leur origine plutôt que d’essayer des résoudre une problématique sans chercher à en comprendre l’origine. Une mauvaise compréhension peut mener à une mauvaise définition de l’ubiquitous language, à une mauvaise division en contexte borné etc.
- Ne pas négliger la carte de contexte qui permet d’aider à comprendre les relations entre contextes bornés.
- Eviter de se concentrer sur le code ou des aspects techniques plutôt que sur les principes de DDD. Si on ne tient pas assez en compte le modèle alors on risque d’empiéter sur d’autres contextes bornés et résoudre des problématiques appartenant à d’autres contextes bornés.
- Accorder de l’importance aux limites du contexte et qu’elles soient clairement définies et comprises.
- Résoudre les problèmes d’ambiguités de l’ubiquitous language car il a un fort impact sur le développement du logiciel. Il faut lever les ambiguités en particulier lorsque la logique métier est complexe.
- Eviter d’appliquer trop d’abstraction à des endroits où ce n’est pas nécessaire peut rendre l’application difficile à maintenir. DDD n’a pas pour but de rajouter des couches d’abstraction inutile mais d’isoler la couche métier.
- Eviter d’appliquer le DDD lorsque le domaine est simple ou lorsque les acteurs du métier ne perçoivent pas l’intérêt du DDD. Dans ce cas tout le monde ne s’investira pas dans une démarche d’application du DDD. Il faut appliquer le DDD sur les problèmes métier complexes où la compléxité nécessite une réflexion entre les développeurs et les acteurs du métier.
- Ne pas sous-estimer le coût pour appliquer une démarche DDD, en effet DDD est coûteux en ressources et en temps car il faut impliquer les acteurs du métier et les développeurs dans l’élaboration de l’ubiquitous language et dans la connaissance du domaine.
Inconvénients du DDD
DDD a quelques inconvénients qui peuvent grandement limiter son application pour un projet.
Difficile de convaincre les acteurs métier
Il peut être difficile de convaincre les experts du domaine de collaborer pour élaborer l’ubiquitous language et pour affiner la connaissance du domaine. La raison est que les acteurs du métier n’ont pas un intérêt direct à participer à ce travail. Ils énoncent des besoins et considère que c’est aux acteurs techniques de résoudre les problèmes pour répondre à ces besoins. Ils peuvent estimer que la compréhension du problème est du ressort des acteurs techniques.
L’intérêt du DDD pour les experts du domaine est de permettre de comprendre davantage leurs problématiques métier. Cette compréhension permet une plus grande maîtrise des processus et solutions qui seront mis en place par la suite par l’implémentation de l’application. Elle permet aussi de mieux comprendre les besoins du métier de façon à mieux anticiper les solutions qui seront mis en place.
Enfin plus les acteurs du métier sont impliqués dans le domain model et plus ils pourront guider efficacement des “refactorings” fonctionnelles éventuels ou des évolutions techniques. L’intérêt est direct puisque les développeurs pourront répondre aux nouveaux besoins plus rapidement.
Apprentissage de l’ubiquitous language et du domaine
Un autre inconvénient de DDD est l’apprentissage de l’ubiquitous language et du domaine pour les nouveaux. Dans tout projet même en dehors de la démarche DDD, il y a une certaine quantité d’information technique et fonctionnelle à accumuler pour un développeur avant de pouvoir intervenir directement sur le code. Dans le cas de DDD, cette apprentissage est presque obligatoire puisque l’ubiquitous language utilise une terminologie spécifique au domain model. Sans une maîtrise de l’ubiquitous language et une bonne compréhension du domain model, le code développé par un nouvel arrivant pourrait ne pas être en phase avec le code existant, ce qui peut se traduire par des ambiguités dans le code, des incompréhensions et au pire des régressions.
L’autre défaut de l’ubiquitous language est qu’il ne s’arrête pas tout à fait à la couche domaine. Par exemple, dans le cas où on doit stocker des objets du domaine dans une base de données. La base de données se trouvant dans la couche infrastructure, en dehors de la couche domaine, on peut être amené à utiliser des termes de l’ubiquitous language dans les noms d’objets de la couche domaine pour leur équivalent dans la couche infrastructure. L’ubiquitous language dépasse donc le périmètre de la couche domaine.
Enfin si un développeur est amené à intervenir sur plusieurs contextes, il peut être confronté à plusieurs ubiquitous languages qui utilisent des termes communs mais ayant un sens différent d’un contexte à l’autre. D’où une source éventuelle d’incompréhensions.
Représenter le domain model
DDD ne donne pas de méthode directe pour représenter le domain model. Sachant que le domain model doit rester compréhensible aux experts du domaine, on doit trouver une façon de la réprésenter pour les experts puissent le comprendre et participer à son élaboration. DDD préconise l’utilisation d’UML pourtant l’apprentissage d’UML n’est pas forcément simple pour des personnes non techniques et en particulier pour des personnes n’étant pas familiarisées avec la conception orientée objet.
De même UML reste proche du modèle de code puisqu’il permet de représenter des relations entre des objets et des utilisations de ces objets. Il rentre donc dans les détails d’implémentation du domain model qui peuvent difficiles à comprendre aux experts du domaine.
Dans une démarche DDD, il faut arriver à trouver une façon de représenter le domain model pour qu’il soit compréhensible par les experts du domaine ce qui n’est pas forcément trivial.
Le domain model doit rester couplé au modèle du code
La tâche la plus compliquée pour une équipe qui entreprend une démarche DDD peut être de garantir que le domain model reste couplé au modèle de code. En effet au fur et à mesure des “refactorings”, le code va évoluer mais il faudra, dans le même temps, faire évoluer aussi le domain model. Dans le cas où le domain model n’est plus couplé au code, les experts du domaine n’auront plus la possibilité de le comprendre puisqu’il n’est plus à jour. La démarche de collaboration avec les experts du domaine peut être largement compromise dans le cas d’un “refactoring” ou d’évolution fonctionnelle.
Pour donner un exemple plus concret, rares sont les projets qui documentent leur code de façon rigoureuse. Il est encore plus rare d’avoir une documentation du code à jour. Au fil du temps, généralement la documentation devient obsolète et découplé du code. Dans la même idée, comment garantir efficacement qu’au fil du temps et des différents développeurs qui interviendront sur le projet, que le domain model restera couplé au modèle du code.
- Domain-Driven Design Vite Fait de Abel Avram et Floyd Marinescu: http://blog.infosaurus.fr/public/docs/DDDViteFait.pdf
- Patterns, Principles, and Practices of Domain-Driven Design de Scott Millett et Nick Tune: https://www.amazon.fr/Patterns-Principles-Practices-Domain-Driven-Design/dp/1118714709
- Domain Driven Design and Development In Practice: https://www.infoq.com/articles/ddd-in-practice
- Patterns of Entreprise Application Architecture de Martin Fowler: http://martinfowler.com/books/eaa.html
- UML en français: http://uml.free.fr/
- Rules engine for .NET: http://stackoverflow.com/questions/7506163/rules-engine-for-net
- Extending a C# Application Through a Scripted DLR Language: https://visualstudiomagazine.com/articles/2011/04/26/wccsp_dlr-extensibility.aspx
- Domain Driven Design : des armes pour affronter la complexité: http://blog.octo.com/domain-driven-design-des-armes-pour-affronter-la-complexite/
- What’s the difference between domain model and conceptual model: http://stackoverflow.com/questions/16854394/whats-the-difference-between-domain-model-and-conceptual-model
- Domain-Driven Development: Where Does the Code Go?: https://visualstudiomagazine.com/articles/2015/09/01/domain-driven-development.aspx
- Domain-Driven Design: Everything You Believe Is Wrong!: https://visualstudiomagazine.com/articles/2015/07/01/domain-driven-design.aspx