Cet article fait suite à l’article Hadoop MapReduce en 5 min qui expliquait de façon théorique le mécanisme des jobs MapReduce. Dans ce présent article, le but est de rentrer un peu plus dans les détails de l’implémentation d’un job Hadoop MapReduce avec une technologie .NET.
Dans un premier temps, on va expliciter les différentes méthodes pour exécuter un job MapReduce. Ensuite on va présenter une méthode pour exécuter un job avec une technologie .NET.
Quelques méthodes pour exécuter un job MapReduce
Préparation de l’environnement de dévelopement
Installation du SDK .NET Core
Installation de Visual Studio Code (facultatif)
Installation de l’extension C# pour Visual Studio Code (facultatif)
Implémentation d’un job MapReduce avec .NET Core
Hadoop Streaming
Implémentation du “mapper”
Implémentation seulement avec le SDK .Net Core
Implémentation avec Visual Studio Code
Tester les assemblies générées
Exécuter le job MapReduce avec seulement le “mapper”
Implémentation du “reducer”
Compiler le “reducer”
Exécuter le job MapReduce
Amélioration du “mapper” pour ignorer les majuscules et la ponctuation
Comparaison des performances entre Hadoop et Hadoop Streaming avec .NET Core
Quelques méthodes pour exécuter un job MapReduce
Plusieurs méthodes sont possibles pour exécuter une job MapReduce avec ou sans technologie .NET:
- Syncfusion Big Data Platform: ce cluster peut être exécuté en local sur Windows et permet d’exécuter des jobs Hadoop MapReduce avec le framework .NET.
- Microsoft .NET SDK For Hadoop il existait un SDK implémenté par Microsoft pour exécuter un job MapReduce. Malheureusement ce projet n’est officiellement plus supporté depuis janvier 2017.
- Hortonworks: cet éditeur propose des solutions pour faciliter l’utilisation de l’environnement Hadoop sur la plateforme Cloud de Microsoft avec HDInsight.
- Ecosystème Hadoop de Cloudera: Cloudera propose une suite complète composée de plusieurs outils Big Data. Cette suite est livrée sous forme de machines virtuelles sur lesquelles on peut accéder aux différents outils. Il est possible d’exécuter des jobs MapReduce sur cette plateforme avec .NET Core.
- Microsoft Azure avec son produit HDInsight: il permet d’accéder à un grand nombre d’outils Big Data avec des langages très différents dont des langages .NET. Hadoop fait partie des outils proposés par le service HDInsight qui permet de créer facilement des clusters.
- La plateforme Cloud d’Amazon AWS permet aussi d’accéder à une panoplie d’outils Big Data avec Amazon EMR dont Apache Hadoop.
- Google Cloud fait aussi partie des plateformes Cloud permettant d’exécuter des jobs MapReduce avec Cloud Dataproc.
Certaines de ces solutions sont utilisables gratuitement et peuvent suffire à effectuer des tests. Une dernière solution est d’installer directement Hadoop directement sur sa machine ou sur une machine virtuelle. La solution de la machine virtuelle est particulièrement intéressante puisqu’elle donne la possibilité de:
- Dupliquer des machines virtuelles dans le cas où on veut réutiliser une configuration intéressante,
- Installer différents outils sans polluer son système d’exploitation principal,
- Reprendre une installation en créant une nouvelle machine virtuelle et
- De tenter facilement différentes configurations.
Enfin l’intérêt d’utiliser directement la suite Apache Hadoop est de bénéficier de sa gratuité.
Préparation de l’environnement de dévelopement
Dans le cadre de cet article, on utilisera, une version d’Apache Hadoop installée sur un système Debian GNU/Linux. En préambule, il faut:
Pour permettre d’exécuter un job Map Reduce avec une technologie .NET sur Linux, on se propose d’utiliser .NET Core. Ainsi, avant d’implémenter le job il faut installer quelques éléments pour exécuter du code C# avec .NET Core.
Installation du SDK .NET Core
Le SDK est le seul élément indispensable à installer. Son installation est assez rapide, il suffit de suivre les instructions pour une distribution Debian: https://www.microsoft.com/net/core#linuxdebian.
Dans le cas du système Debian que l’on a installé sur la machine virtuelle VirtualBox, il faut réaliser les étapes suivantes:
- Ouvrir un terminal et se connecter en tant qu’utilisateur root en tapant:
su - Installer quelques outils comme curl en exécutant:
apt-get install curl libunwind8 gettext apt-transport-httpscurlpermettra le téléchargement de la clé publique des produits Microsoft. - Télécharger la clé publique des produits Microsoft en faisant:
curl https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > microsoft.gpg - Déplacer la clé pour qu’elle soit considérée comme une clé de confiance par le système de packages APT:
mv microsoft.gpg /etc/apt/trusted.gpg.d/microsoft.gpg - Il faut ensuite éditer le fichier /etc/apt/sources.list.d/dotnetdev.list, par exemple avec
vien exécutant:vi /etc/apt/sources.list.d/dotnetdev.listIl faut ensuite aller vers les dernières lignes du fichier, de passer en mode insertion en tapant [i] et ajouter la ligne suivante:
deb [arch=amd64] https://packages.microsoft.com/repos/microsoft-debian-stretch-prod stretch mainOn peut enregistrer le fichier en faisant [echap] et en tapant la commande suivante:
:wqpuis [entrée] - On met à jour la liste des packages présents dans les différentes sources de APT en tapant:
apt-get update - Enfin, on installe le package correspondant au SDK .NET Core en tapant:
apt-get install dotnet-sdk-2.0.0
Installation de Visual Studio Code (facultatif)
L’installation de Visual Studio Code n’est pas indispensable toutefois Visual Studio Code est un éditeur qui va faciliter l’implémentation du job par la suite.
Pour installer Visual Studio Code, il suffit de suivre les instructions sur:
https://code.visualstudio.com/docs/setup/linux.
Dans notre cas, il faut exécuter les étapes suivantes en tant qu’utilisateur root:
- Editer le fichier /etc/apt/sources.list.d/vscode.list en tapant:
vi /etc/apt/sources.list.d/vscode.listPasser en mode insertion en tapant [i] et ajouter la ligne:
deb [arch=amd64] https://packages.microsoft.com/repos/vscode stable mainIl faut enregistrer et quitter en tapant la touche [echap], en écrivant
:wqpuis [entrée]. - On met à jour la liste des packages présents dans les différentes sources de APT en tapant:
apt-get update - On installe le package code en tapant:
apt-get install code - On peut démarrer Visual Studio Code en tapant:
code
Installation de l’extension C# pour Visual Studio Code (facultatif)
Cette étape est aussi facultative toutefois l’extension C# facilite grandement l’implémentation.
Pour installer l’extension C#, il faut:
- Cliquer sur View puis Extensions
- Taper ensuite:
c# - Cliquer ensuite sur “install”.
A la fin de cette étape, l’extension est prête à être exécutée.
Implémentation d’un job MapReduce avec .NET Core
Dans cette partie, on se propose d’implémenter l’exemple classique d’un job MapReduce: Wordcount. Il consiste à compter le nombre de mots dans un texte.
Cet exemple est très classique toutefois son grand intérêt est d’être facile à mettre en oeuvre car il ne nécessite qu’un fragment de texte sous forme de fichier texte en entrée. Il n’y a, par exemple, pas d’appels à une base de données ou à d’autres services tiers qui pourraient compliquer l’implémentation de ce traitement.
Brièvement, un job MapReduce est principalement composé de 2 séries d’opérations:
- Des opérations Map qui permettent de lire les données en entrée et d’appliquer des opérations à toutes les données lues.
- Une ou plusieurs opérations Reduce qui agrègent les résultats provenant des opérations Map et les écrit.
Le fonctionnement de MapReduce est expliqué plus en détails dans l’article Hadoop MapReduce en 5 min.
Hadoop est implémenté en Java et propose un SDK pour ce langage. Dans le cas de .NET Core, il n’y a pas de SDK similaire, il faut donc exécuter le job de façon différente en utilisant Hadoop Streaming.
Hadoop Streaming
Hadoop Streaming est une API générique qui permet à Hadoop de s’interfacer avec n’importe quel type de langage.
On l’a vu précédemment, l’implémentation d’un job MapReduce passe au moins par l’implémentation d’un mapper. Dans la plupart des cas, il faudra aussi implémenter un reducer même si ce n’est pas obligatoire.
Dans le cas d’Hadoop Streaming, Hadoop s’interface avec le mapper et le reducer en passant par l’entrée et la sortie standard stdin et stout. C’est ce qui permet à Hadoop Streaming de s’interfacer avec n’importe quel type de langage ou de technologie. Dans la pratique, il faut implémenter 2 exécutables correspondant au mapper et au reducer, Hadoop exécute ces exécutables dans des processus différents et leur fournit les données ligne après ligne par l’intermédiaire de l’entrée standard. La sortie des exécutables doit aussi passer par la sortie standard.
Le mapper doit donc lire le contenu de l’entrée standard par ligne. De la même façon, pour écrire le résultat, le mapper passe par la sortie en utilise la syntaxe suivante:
- Une ligne représente un paire de clé/valeur
- La clé et la valeur sont séparées par le caractère tabulation.
Le reducer fonctionne de la même façon et s’interface avec Hadoop suivant la même méthode:
- En entrée, il reçoit des paires de clé/valeur séparées par le caractère tabulation.
- En sortie, il doit fournir les paires de clé/valeur en les séparant par le caractère tabulation.
Dans la suite, on va donc implémenter un mapper et un reducer du job Wordcount avec .NET Core de façon à produire 2 exécutables utilisables avec Hadoop Streaming.
Implémentation du “mapper”
Dans un premier temps, on va implémenter seulement le mapper du job Wordcount en considérant que:
- Une ligne de l’entrée standard correspond à une ligne du fichier texte en entrée.
- Chaque ligne en sortie correspond à une paire de clé/valeur et on sépare les 2 avec le caractère tabulation.
Dans le cas du job Wordcount, le mapper reçoit un ligne de texte et considère les mots comme étant des clés. Il va associer la valeur “1” à chacun des mots. Le résultat produit est donc des paires de clé/valeur avec une clé pour chaque mot et “1” étant la valeur de chaque paire.
Voici donc l’implémentation du mapper:
using System;
using System.Text;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
// Récupération de l'entrée standard
var fileLine = Console.ReadLine();
// Tant qu'Hadoop fournit des lignes
while (fileLine != null) // il faut tester la nullité et non string.isNullOrEmpty()
{
var words = fileLine.Split(' ');
foreach (var word in words)
{
if (string.IsNullOrWhiteSpace(word)) continue;
// On fournit le résultat par la sortie standard en séparant
// la clé (le mot) et la valeur 1 avec une tabulation
Console.WriteLine($"{word}\t1");
}
// Récupération de l'entrée standard
fileLine = Console.ReadLine();
}
}
}
}
Implémentation seulement avec le SDK .Net Core
Pour implémenter sans passer par Visual Studio Code, il faut effectuer les étapes suivantes:
- Créer le projet console .NET Core du mapper en exécutant:
% dotnet new console -n mapper The template "Console Application" was created successfully. Processing post-creation actions... Running 'dotnet restore' on mapper/mapper.csproj... Restoring packages for /home/mat/Documents/mapper/mapper.csproj... Generating MSBuild file /home/mat/Documents/mapper/obj/mapper.csproj.nuget.g.props. Generating MSBuild file /home/mat/Documents/mapper/obj/mapper.csproj.nuget.g.targets. Restore completed in 288.37 ms for /home/mat/Documents/mapper/mapper.csproj. Restore succeeded.Cette ligne produit un répertoire nommé
mapperavec les fichiers suivants:% ls mapper mapper.csproj obj Program.cs - Il faut éditer le fichier mapper/Program.cs avec le code plus haut.
- On compile en exécutant:
% dotnet build Microsoft (R) Build Engine version 15.3.409.57025 for .NET Core Copyright (C) Microsoft Corporation. All rights reserved. mapper -> /home/mat/Documents/mapper/bin/Debug/netcoreapp2.0/mapper.dll Build succeeded. 0 Warning(s) 0 Error(s) Time Elapsed 00:00:03.34 - Pour produire l’assembly à déployer, on peut exécuter:
% dotnet publish -c "Release" Microsoft (R) Build Engine version 15.3.409.57025 for .NET Core Copyright (C) Microsoft Corporation. All rights reserved. mapper -> /home/mat/Documents/mapper/bin/Release/netcoreapp2.0/mapper.dll mapper -> /home/mat/Documents/mapper/bin/Release/netcoreapp2.0/publish
L’assembly à exécuter se trouve dans le répertoire mapper/bin/Release/netcoreapp2.0/publish.
Implémentation avec Visual Studio Code
Une autre possibilité est d’utiliser Visual Studio Code:
- Ouvrir Visual Studio Code en exécutant à la ligne de commandes:
code - Créer un répertoire vide et l’ouvrir en cliquant sur File ⇒ Open Folder ou avec le raccourci clavier [Ctrl] + [K] et [Ctrl] + [O].
- Ouvrir ensuite la ligne de commandes dans Visual Studio Code en cliquant sur View ⇒ Integrated terminal.
Le terminal se trouve directement dans le répertoire ouvert précédemment.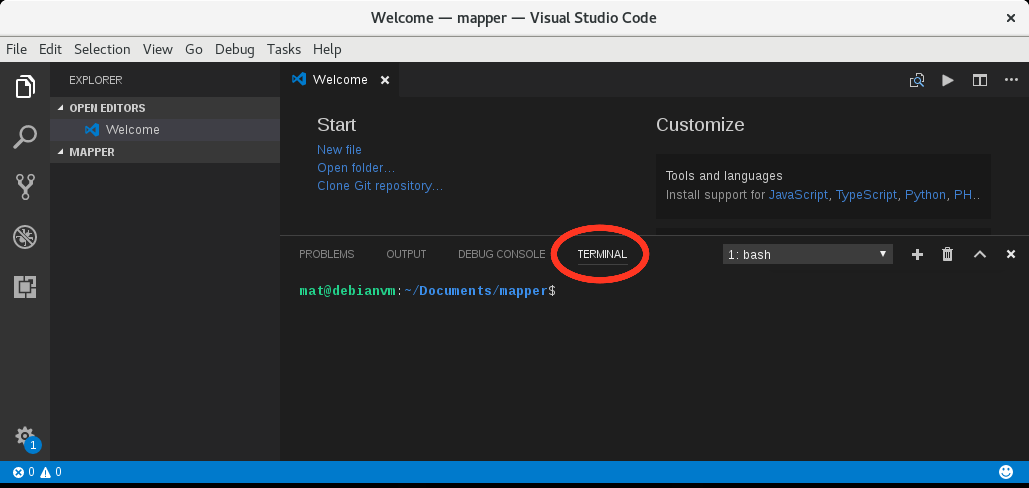
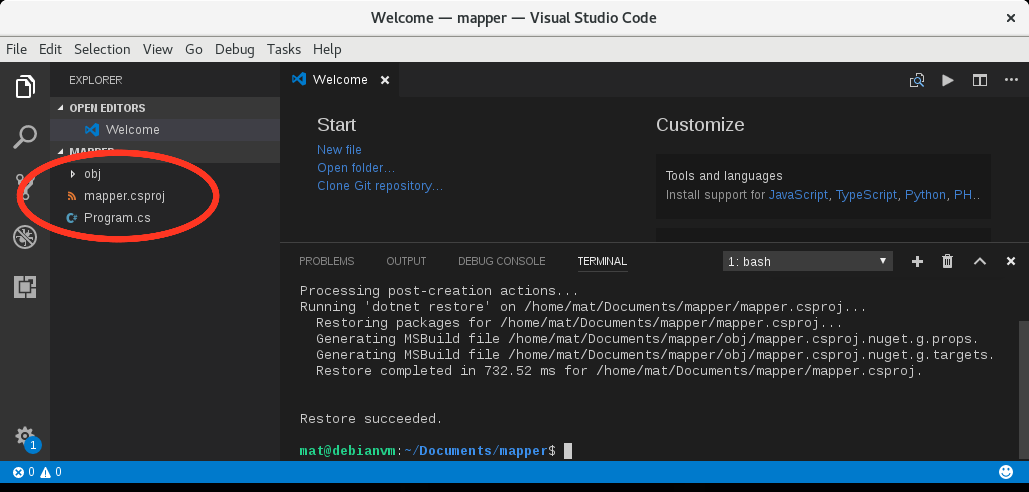
- Dans le terminal de Visual Studio Code, taper:
dotnet new consoleLe projet sera directement créer dans le répertoire mapper et les fichiers apparaîtront dans Visual Studio Code:
Si l’explorateur à gauche n’apparait pas il faut cliquer sur l’icône ou exécuter la raccourci clavier [Ctrl] + [Maj] + [E]:
- On peut alors cliquer sur le fichier Program.cs et l’éditer directement en copiant collant l’implémentation précédente.
- Un message apparaît dans Visual Studio Code: “Required assets to build and debug are missing for ‘mapper’. Add them ?”
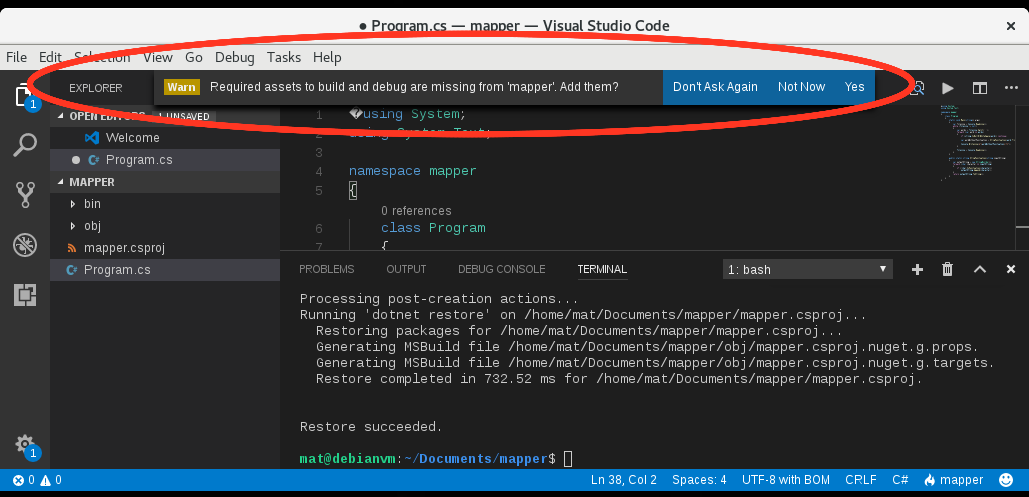
Il faut répondre [Yes] pour que Visual Studio Code crée un répertoire nommé .vscode qui contiendra des éléments pour compiler et débuguer.
- On peut ensuite compiler en effectuant une parmi les opérations suivantes:
- Cliquer sur Tasks ⇒ Run build tasks
- Utiliser le raccourci clavier [Ctrl] + [Maj] + [B]
- Taper dans le terminal Visual Studio Code:
dotnet build(il faut enregistrer le fichier avant d’effectuer cette étape car, contrairement aux autres méthodes, l’enregistrement n’est pas automatique).
A la fin de cette étape, une assembly est produite dans le répertoire
mapper/bin/Debug/netcoreapp2.0/.Pour débugger… On peut à ce moment débugguer directement dans Visual Studio Code en ajoutant un point d’arrêt et en cliquant sur Debug ⇒ Start debugging ou en tapant sur [F5] directement.
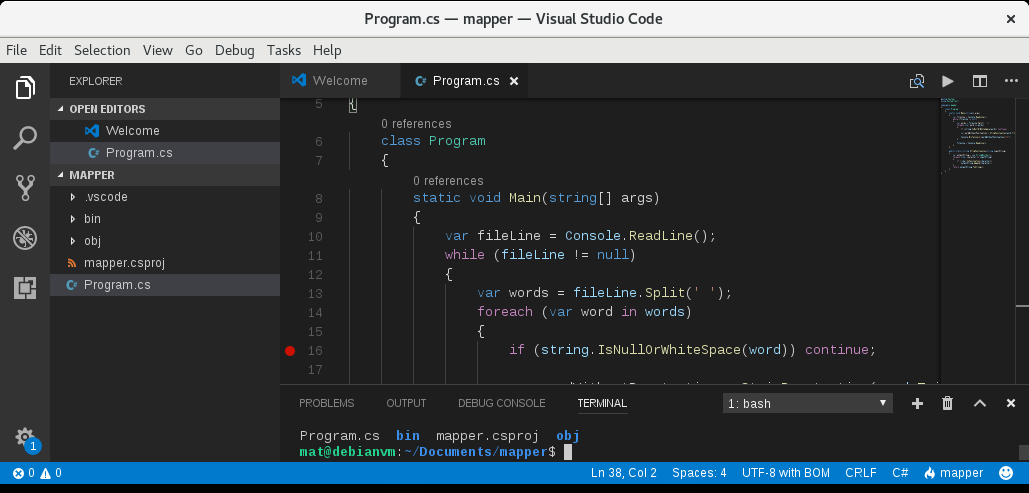
- On peut ensuite produire l’assembly qui sera déployée en exécutant dans le terminal Visual Studio Code:
dotnet publish –c "Release"L’assembly produite sera dans le répertoire
mapper/bin/Release/netcoreapp2.0/publish.
On peut trouver la liste des raccourcis clavier utilisables sur Visual Studio Code dans sa version Linux dans le document suivant: Visual Studio Code Keyboard shortcuts for Linux.
Tester les assemblies générées
On peut tester l’implémentation en simulant une ligne de fichier texte produite par Hadoop:
% echo "Hadoop est un outil puissant toutefois cet outil a des limites qui le rendent moins puissant" | dotnet bin/Debug/netcoreapp2.0/mapper.dll
Hadoop 1
est 1
un 1
outil 1
puissant 1
toutefois 1
cet 1
outil 1
a 1
des 1
limites 1
qui 1
le 1
rendent 1
moins 1
puissant 1
Le résultat produit donc bien une paire de clé/valeur par ligne et pour chaque ligne la clé est séparée de la valeur avec une tabulation.
Exécuter le job MapReduce avec seulement le “mapper”
Maintenant on va exécuter le job MapReduce sans reducer. Dans un premier temps, il faut mettre sur HDFS le fichier correspondant à l’entrée du job.
La manipulation des fichiers sur HDFS peut se faire en utilisant quelques commandes explicitées dans Commandes shell courantes pour HDFS.
Si on utilise le même fichier que celui utilisé à l’installation de Hadoop (ce fichier est téléchargeable sur http://www.gutenberg.org/files/2600/2600-0.txt) il suffit d’exécuter les commandes suivantes (avec l’utilisateur permettant d’exécuter Hadoop, dans notre cas c’est “hduser”):
hdfs dfs -mkdir /user
hdfs dfs -put 2600-0.txt /user
Ces commandes permettent de mettre le fichier sur HDFS dans le répertoire /user.
Dans le cas de notre installation, Hadoop a été installé dans le répertoire /usr/hadoop/hadoop-2.8.1/ et donc Hadoop Streaming se trouve dans le répertoire /usr/hadoop/hadoop-2.8.1/share/hadoop/tools/lib/hadoop-streaming-2.8.1.jar.
On peut donc lancer le job en exécutant:
% hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/tools/lib/hadoop-streaming-2.8.1.jar \
-D mapreduce.job.reduce=0 \
-files "bin/Release/netcoreapp2.0/publish" \
-mapper "dotnet bin/Release/netcoreapp2.0/publish/mapper.dll" \
-input /user/2600-0.txt \
-output /output_mapper
Pour le détail:
-D mapreduce.job.reduce=0: permet de préciser qu’on ne veut pas d’étape reduce.-files "bin/Release/netcoreapp2.0/publish": le job va considérer les fichiers du mapper se trouvant dans ce répertoire.-mapper "dotnet bin/Release/netcoreapp2.0/publish/mapper.dll": instruction permettant d’exécuter le mapper.-input /user/2600-0.txt: le fichier en entrée.-output /output_mapper: le répertoire de sortie.
Si le job s’est correctement exécuté, le contenu du répertoire /output_mapper sur HDFS devrait être:
% hdfs dfs -ls /output_mapper
Found 2 items
-rw-r--r-- 1 hduser supergroup 0 2017-10-21 10:49 /output_mapper/_SUCCESS
-rw-r--r-- 1 hduser supergroup 4242981 2017-10-21 10:49 /output_mapper/part-00000
Pour récupérer le fichier résultat qui se trouve dans le répertoire /output_mapper sur HDFS, il faut exécuter:
hdfs dfs –get /output_mapper/part-00000
Si on regarde le contenu du fichier part-00000, on voit donc toutes les clés correspondant aux mots et la valeur 1 séparées par une tabulation.
Implémentation du “reducer”
Dans le cas du job Wordcount, il faut implémenter le reducer en considérant que:
- Chaque ligne en entrée contient une clé et sa valeur séparées par le caractère tabulation
- Les lignes en entrée sont triées par ordre alphabétique (à cause de l’étape sort).
- Chaque ligne de sortie doit comprendre une clé correspondant au mot et la valeur qui doit être le nombre d’occurrences trouvées de ce mot. La clé et la valeur sont aussi séparées par une tabulation.
L’implémentation du reducer est donc:
using System;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
string currentWord = string.Empty;
int currentWordCount = 0;
string word = string.Empty;
// Récupération de l'entrée standard
string valueFromMapper = Console.ReadLine();
// Tant qu'Hadoop fournit des lignes
while (valueFromMapper != null) // il faut tester la nullité et non string.isNullOrEmpty()
{
// On sépare le mot de la valeur
var splitLine = valueFromMapper.Split('\t');
if (splitLine.Length == 2)
{
word = splitLine[0];
int count;
// Tant qu'on obtient le même mot, on augmente le nombre d'occurences
if (Int32.TryParse(splitLine[1], out count))
{
if (currentWord == word)
{
currentWordCount += count;
}
else
{
// Si le mot change alors on écrit le nombre d'occurrences trouvé pour le mot précédent
if (!string.IsNullOrWhiteSpace(currentWord))
{
Console.WriteLine($"{currentWord}\t{currentWordCount}");
}
currentWord = word;
currentWordCount = count;
}
}
}
// Récupération de l'entrée standard
valueFromMapper = Console.ReadLine();
}
// On n'oublie pas d'écrire la ligne correspondant au dernier mot
if (currentWord == word && !string.IsNullOrWhiteSpace(currentWord))
{
Console.WriteLine($"{currentWord}\t{currentWordCount}");
}
}
}
}
Compiler le “reducer”
Pour compiler ce code avec .NET Core, on procède comme pour le mapper:
- On crée un projet console vide:
dotnet new console –n reducerDans Visual Studio Code, il faut fermer le dossier du mapper en cliquant sur File ⇒ Close Folder.
Puis il faut ouvrir un nouveau dossier: File ⇒ Open Folder pour ouvrir un répertoire vide correspondant à celui du reducer. Dans le terminal de Visual Studio Code, on peut ensuite taper la ligne précédente pour créer un projet console. - On édite le fichier Program.cs avec le code du reducer.
- On compile en exécutant:
dotnet buildLe répertoire de sortie de l’assembly est:
reducer/bin/Debug/netcoreapp2.0/
On considère qu’à ce stade, on a 2 répertoires mapper et reducer contenant respectivement l’implémentation du mapper et du reducer:
% ls
mapper reducer
On peut tester l’implémentation du reducer en exécutant la ligne suivante:
% echo "Hadoop est un outil puissant toutefois cet outil a des limites qui le rendent moins puissant" | dotnet mapper/bin/Debug/netcoreapp2.0/mapper.dll | sort -k1,1 | dotnet reducer/bin/Debug/netcoreapp2.0/reducer.dll
a 1
cet 1
des 1
est 1
Hadoop 1
le 1
limites 1
moins 1
outil 2
puissant 2
qui 1
rendent 1
toutefois 1
un 1
Enfin pour produire l’assembly du reducer qui servira lors de l’exécution du job MapReduce, il suffit d’exécuter dans le répertoire du reducer la ligne:
% dotnet publish -c "Release"
Microsoft (R) Build Engine version 15.3.409.57025 for .NET Core
Copyright (C) Microsoft Corporation. All rights reserved.
reducer -> /home/mat/Documents/reducer/bin/Release/netcoreapp2.0/reducer.dll
reducer -> /home/mat/Documents/reducer/bin/Release/netcoreapp2.0/publish/
Le répertoire de sortie de l’assembly du reducer est donc reducer/bin/Release/netcoreapp2.0/publish/.
Exécuter le job MapReduce
Avant d’exécuter le job MapReduce, on va copier les fichiers du mapper et du reducer dans un même répertoire:
% ls
mapper reducer
% mkdir publish
% cp mapper/bin/Release/netcoreapp2.0/publish/* publish
% cp reducer/bin/Release/netcoreapp2.0/publish/* publish
% ls publish
mapper.deps.json mapper.pdb reducer.deps.json reducer.pdb
mapper.dll mapper.runtimeconfig.json reducer.dll reducer.runtimeconfig.json
On lance l’exécution en tant qu’utilisateur permettant d’exécuter un job MapReduce (dans notre cas c’est “hduser”) en exécutant la ligne:
% hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/tools/lib/hadoop-streaming-2.8.1.jar \
-files "publish" \
-mapper "dotnet publish/mapper.dll" \
-reducer "dotnet publish/reducer.dll" \
-input /user/2600-0.txt \
-output /output_mapreduce
La différence avec la ligne précédente est qu’on précise un reducer:
-reducer "dotnet publish/reducer.dll"
On supprime aussi l’option indiquant de ne pas utiliser d’étape reduce:
-D mapreduce.job.reduce=0
Si le job s’est correctement exécuté, le contenu du répertoire /output_mapreduce sur HDFS devrait être:
% hdfs dfs -ls /output_mapreduce
Found 2 items
-rw-r--r-- 1 hduser supergroup 0 2017-10-21 11:44 /output_mapreduce/_SUCCESS
-rw-r--r-- 1 hduser supergroup 487290 2017-10-21 11:44 /output_mapreduce/part-00000
Pour récupérer le fichier résultat qui se trouve dans le répertoire /output_mapreduce sur HDFS, il faut exécuter:
hdfs dfs –get /output_reduce/part-00000
Si on regarde le contenu du fichier, on voit donc les mots et le nombre d’occurrences de ces mots:
#2600] 1
$5,000) 1
($1 1
(1) 17
(2) 27
(3) 12
(4) 1
(5) 1
(801) 1
(At 1
(Barclay 1
(Berg 3
(Borodinó) 1
(Borís 1
(By 1
(Daniel 1
(Davout). 1
(Denísov’s 1
(Ermólov 1
(God) 1
(He 18
(His 1
(How 1
(I 3
(In 1
(Instructions 1
(It 4
(Joseph 1
(Karáy 2
(Kochubéy 1
(Konovnítsyn 1
(Kutúzov 1
(Madame 1
(Mademoiselle 2
(Mary 1
(Moscou, 1
(Murat) 1
(Márya 1
(Natásha 2
(Ney) 1
...
En observant ce fichier, on constate que les caractères de ponctuation et les majuscules gênent le comptage des mots. On se propose, par la suite, une petite amélioration dans le mapper pour éviter que le comptage ne soit perturbé par la ponctuation et les majuscules.
Amélioration du “mapper” pour ignorer les majuscules et la ponctuation
Pour éviter de différencier des mots à cause d’un majuscule ou de caractères de ponctuation, on modifie le mapper avec l’implémentation suivante:
using System;
using System.Text;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
var fileLine = Console.ReadLine();
while (fileLine != null)
{
var words = fileLine.Split(' ');
foreach (var word in words)
{
if (string.IsNullOrWhiteSpace(word)) continue;
var wordWithoutPunctuation = StripPunctuation(word.Trim().ToLower());
Console.WriteLine($"{wordWithoutPunctuation}\t1");
}
fileLine = Console.ReadLine();
}
}
public static string StripPunctuation(string inputString)
{
var outputString = new StringBuilder();
foreach (char character in inputString)
{
if (!char.IsPunctuation(character))
outputString.Append(character);
}
return outputString.ToString();
}
}
}
En ré-exécutant le job, on obtient un comptage plus précis:
...
a 10494
aah 1
ab 1
aback 3
abacus 1
abandon 25
abandoned 54
abandoning 26
abandonment 14
abandons 1
abashed 12
abate 2
abbreviations 1
abbé 18
abbés 1
abc 1
abdicate 1
abdomen 2
abdomens 2
abduction 3
abductors 1
abhorrence 1
abide 1
ability 4
ablaze 2
able 107
abnormal 1
abnormally 1
abodes 1
abolition 1
abominable 7
abominably 1
abounding 1
about 1016
abouti 2
above 146
aboveboard 1
abreast 5
abroad 33
abrupt 6
abruptly 10
abrámovna 1
absence 48
absent 4
absentees 1
absently 6
absentminded 14
absentmindedly 10
absentmindedness 8
absolute 16
absolutely 21
absolved 1
absorb 1
absorbed 32
absorption 2
abstain 2
abstained 2
abstaining 2
abstemious 1
...
Une autre amélioration pourrait être de ne pas prendre en compte les nombres lors du comptage.
Comparaison des performances entre Hadoop et Hadoop Streaming avec .NET Core
Pour terminer, on peut essayer de comparer la vitesse d’exécution du job MapReduce entre:
- Hadoop avec l’implémentation en Java et
- Hadoop Streaming avec une implémentation du mapper et reducer en .Net Core.
Etant donné que l’exécution du job avec les données précédentes est rapide, on va dupliquer ce fichier pour augmenter les données d’entrée. On effectue alors une trentaine de copies du même fichier et on place ces fichiers dans HDFS:
% ls comparison
2600-0.txt 2600-12.txt 2600-15.txt 2600-18.txt 2600-20.txt 2600-23.txt 2600-26.txt 2600-29.txt 2600-3.txt 2600-6.txt 2600-9.txt
2600-10.txt 2600-13.txt 2600-16.txt 2600-19.txt 2600-21.txt 2600-24.txt 2600-27.txt 2600-2.txt 2600-4.txt 2600-7.txt
2600-11.txt 2600-14.txt 2600-17.txt 2600-1.txt 2600-22.txt 2600-25.txt 2600-28.txt 2600-30.txt 2600-5.txt 2600-8.txt
% hdfs dfs -put comparison /user/
On exécute ensuite le job wordcount en Java sur le répertoire:
% hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /user/comparison/ output_java
On effectue la même exécution avec Hadoop Streaming et .NET Core sans l’amélioration précédente:
% hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/tools/lib/hadoop-streaming-2.8.1.jar -files "publish" -mapper "dotnet publish/mapper.dll" -reducer "dotnet publish/reducer.dll" -input /user/comparison/ -output /output_dotnetcore
L’exécution en Java a pris 56 secondes et l’exécution avec Hadoop Streaming s’est déroulée en 138 secondes dans les mêmes conditions. Ce qui est important dans ce test, ce n’est pas le temps d’exécution mais la différence entre l’exécution en Java et celle utilisant Hadoop Streaming.
Pour conclure…
En conclusion, cet article a permis de montrer comment utiliser .NET Core pour implémenter un mapper et un reducer de façon à exécuter un job Hadoop MapReduce. Avec Hadoop Streaming, l’implémentation n’est pas forcément plus complexe même si l’interfaçage en utilisant la sortie et l’entrée standard nécessite une adaptation du code.
Le gros inconvénient de Hadoop Streaming est la pénalité imposée sur les performances puisque passer par l’entrée et la sortie standard engendre un lenteur plus importante qu’une implémentation avec un SDK.
Toutefois Hadoop Streaming permet d’exploiter d’autres fonctionnalités de Hadoop pour optimiser l’exécution des jobs comme l’utilisation d’un cache distribué ou d’un combiner. Ces fonctionnalités feront l’objet d’articles futurs.
- Yahoo! Hadoop Tutorial Module 4: MapReduce: https://developer.yahoo.com/hadoop/tutorial/module4.html
- Hadoop and .NET: A Match Made in Docker: https://blog.sixeyed.com/hadoop-and-net-core-a-match-made-in-docker/
- Writing an Hadoop MapReduce Program in Python: http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/
- How to Create MapReduce Jobs for Hadoop Using C#: http://www.codeguru.com/columns/experts/how-to-create-mapreduce-jobs-for-hadoop-using-c.htm
- Connecting to Hadoop/Hive from .NET: https://community.hortonworks.com/questions/345/connecting-to-hadoophive-from-net.html
- Hadoop Streaming: https://hadoop.apache.org/docs/r1.2.1/streaming.html
- Running VS Code on Linux: https://code.visualstudio.com/docs/setup/linux
- Working with C#: https://code.visualstudio.com/docs/languages/csharp
- Install .NET and build your first app on Debian: https://www.microsoft.com/net/core#linuxdebian
- Visual Studio Code Keyboard shortcuts for Linux: https://code.visualstudio.com/shortcuts/keyboard-shortcuts-linux.pdf