Pour augmenter l’efficacité d’un job MapReduce, en plus du cache distribué, on peut s’aider de combiners.
Brièvement, dans un job MapReduce:
- Lors de la phase Map, les mappers génèrent des paires de clé/valeur.
- Lors de la phase shuffle/sort, ces paires sont réparties et ordonnées sur un ou plusieurs nœuds en fonction de la valeur de la clé .
- Lors de la phase Reduce, un ou plusieurs reducers agrègent les paires de clé/valeur en fonction de la valeur de la clé.
Ces étapes sont expliquées plus en détail dans Hadoop MapReduce en 5 min.
Des paires de clé/valeur sont échangées lors de la phase shuffle/sort. Plus il y a des paires qui sont échangées entre des nœuds et moins le job sera exécuté de façon efficace. Utiliser des combiners peut aider à réduire les données échangées.
Explication du “combiner”
Le combiner est un composant logiciel qui va agréger les paires de clé/valeur à la sortie d’un mapper avant la phase shuffle/sort. Cette première agrégation permet de réduire le nombre de clé/valeur qui seront transmises à la phase shuffle/sort et par suite au reducer. Réduire le nombre de paires de clé/valeur transitant d’un nœud à l’autre permet d’optimiser l’exécution du job.
Concrètement, le combiner est placé juste après chaque mapper et est exécuté avant la phase shuffle/sort:
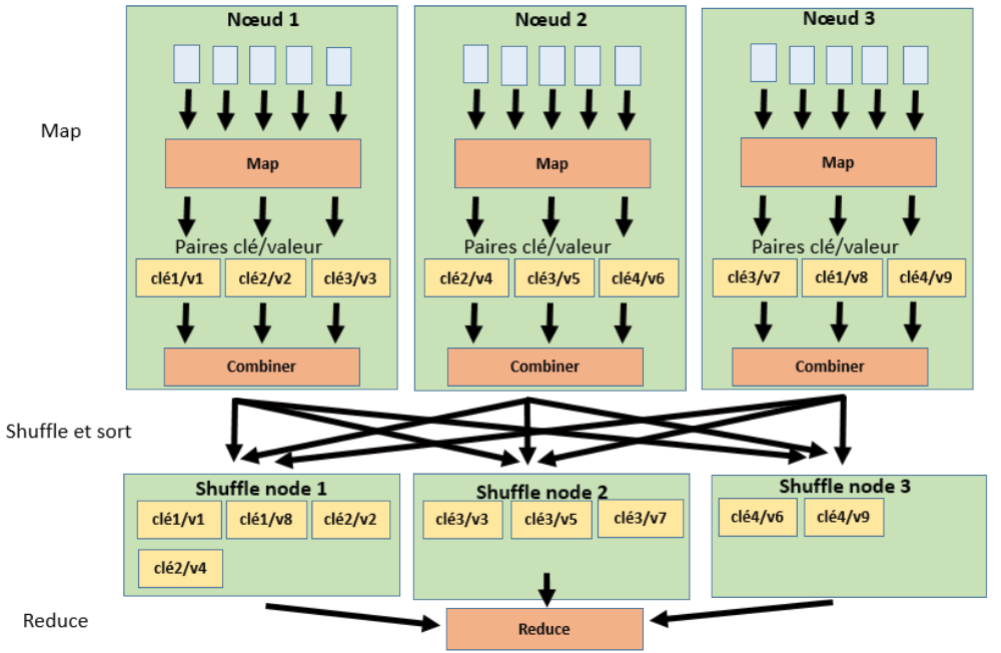
Exemple d’utilisation du “combiner”
En utilisant l’exemple du job Word count et en considérant le comptage des mots de la phase:
"Hadoop est un outil puissant toutefois cet outil a des limites qui le rendent moins puissant."
Dans le cas où le cluster est composé de 2 nœuds, le comptage de la phrase sera réparti sur 2 mappers. A la sortie des mappers, les paires de clé/valeur seront:
- Nœud 1 après exécution du mapper:
("Hadoop"/1), ("est"/1), ("un"/1), ("outil"/1), ("puissant"/1), ("toutefois"/1), ("cet"/1), ("outil"/1) - Nœud 2 après exécution du mapper:
("a"/1), ("des"/1), ("limites"/1), ("qui"/1), ("le"/1), ("rendent"/1), ("moins"/1), ("puissant"/1)
Après exécution des combiners qui se trouvent à la sortie des mappers:
- Nœud 1 après exécution du combiner:
("Hadoop"/1), ("est"/1), ("un"/1), ("outil"/2), ("puissant"/1), ("toutefois"/1), ("cet"/1) - Nœud 2 après exécution du combiner:
("a"/1), ("des"/1), ("limites"/1), ("qui"/1), ("le"/1), ("rendent"/1), ("moins"/1), ("puissant"/1)
On remarque que dans le cas du nœud 1, les paires avec la clé "outil" ont été agrégées.
Après la phase shuffle/sort:
- Nœud 1:
("a"/1), ("cet"/1), ("des"/1), ("est"/1), ("Hadoop"/1), ("le"/1), ("limites"/1), ("moins"/1). - Nœud 2:
("outil"/2), ("puissant"/1), ("puissant"/1), ("qui"/1), ("rendent"/1), ("toutefois"/1), ("un"/1).
Les paires clé/valeur sont triées et réparties sur les 2 nœuds.
Dans le cas d’un seul reducer, toutes les clés sont adressées au seul reducer pour être agrégées. On obtient après exécution du reducer:
("a"/1), ("cet"/1), ("des"/1), ("est"/1), ("Hadoop"/1), ("le"/1),
("limites"/1), ("moins"/1), ("outil"/2), ("puissant"/2), ("qui"/1), ("rendent"/1),
("toutefois"/1), ("un"/1).
Le reducer n’a effectué qu’une seule agrégation: les paires avec la clé "puissant". S’il n’y avait pas de combiners, le reducer aurait dû agréger les paires correspondant aux clés "outil" et "puissant".
Le combiner permet donc de:
- Réduire les données échangées entre nœud
- Réduire le nombre de traitements effectués par le reducer.
Implémentation du “combiner”
Si on prend l’exemple du texte:
http://www.gutenberg.org/files/2600/2600-0.txt
Dans le cadre du comptage de mots, l’implémentation du combiner est la même que celle du reducer (l’implémentation du reducer se trouve dans l’article Exécuter un job Hadoop MapReduce avec .NET Core:
using System;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
string currentWord = string.Empty;
int currentWordCount = 0;
string word = string.Empty;
string valueFromMapper = Console.ReadLine();
while (valueFromMapper != null)
{
var splitLine = valueFromMapper.Split('\t');
if (splitLine.Length == 2)
{
word = splitLine[0];
int count;
if (Int32.TryParse(splitLine[1], out count))
{
if (currentWord == word)
{
currentWordCount += count;
}
else
{
if (!string.IsNullOrWhiteSpace(currentWord))
{
Console.WriteLine($"{currentWord}\t{currentWordCount}");
}
currentWord = word;
currentWordCount = count;
}
}
}
valueFromMapper = Console.ReadLine();
}
if (currentWord == word && !string.IsNullOrWhiteSpace(currentWord))
{
Console.WriteLine($"{currentWord}\t{currentWordCount}");
}
}
}
}
Exécution du job MapReduce avec un “combiner”
Pour exécuter un job MapReduce avec Hadoop Streaming en fournissant un combiner, il faut, dans une premier temps, créer un projet console avec .Net Core:
% dotnet new console –n combiner
Après avoir modifié l’implémentation dans combiner/Program.cs:
% cd combiner
% dotnet build
% dotnet publish –c release
On copie ensuite les résultats de compilation dans le répertoire publish:
% cp bin/release/netcoreapp2.0/publish/* ../publish
On exécute ensuite le job MapReduce en fournissant l’argument correspondant au combiner:
% hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/tools/lib/hadoop-streaming-2.8.1.jar \
-files "publish" \
-mapper "dotnet publish/mapper.dll" \
-reducer "dotnet publish/reducer.dll" \
-combiner "dotnet publish/combiner.dll" \
-input /user/input/comparison/2600-0.txt \
-output /output_combiner
Le résumé de l’exécution est le suivant:
File System Counters
FILE: Number of bytes read=375438
FILE: Number of bytes written=1171439
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3363856
HDFS: Number of bytes written=227620
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=76630
Total time spent by all reduces in occupied slots (ms)=12702
Total time spent by all map tasks (ms)=38315
Total time spent by all reduce tasks (ms)=6351
Total vcore-milliseconds taken by all map tasks=38315
Total vcore-milliseconds taken by all reduce tasks=6351
Total megabyte-milliseconds taken by all map tasks=78469120
Total megabyte-milliseconds taken by all reduce tasks=13006848
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=4242981
Map output materialized bytes=375444
Input split bytes=210
Combine input records=566308
Combine output records=29157
Reduce input groups=20470
Reduce shuffle bytes=375444
Reduce input records=29157
Reduce output records=20470
Spilled Records=58314
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=323
CPU time spent (ms)=7770
Physical memory (bytes) snapshot=571236352
Virtual memory (bytes) snapshot=8277688320
Total committed heap usage (bytes)=398663680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3363646
File Output Format Counters
Bytes Written=227620
Comparaison entre l’exécution avec et sans “combiner”
Si on considère le résumé de l’exécution du job MapReduce word count sans combiner:
...
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=4242981
Map output materialized bytes=5375609
...
Sur la quantité de données échangées, on constate une diminution assez conséquente (l’unité utilisée est l’octet):
- Sans combiner:
Map output materialized bytes=5375609 - Avec combiner:
Map output materialized bytes=375444
Soit un gain de 93% ce qui est considérable.
Le temps d’exécution est le même avec ou sans combiner (50 sec).
Dans le cadre du job Word Count, on constate que la quantité de données échangées est considérablement réduite. Le temps d’exécution est, quant à lui, inchangé.
Le combiner est donc une option à prendre en compte lors de l’exécution d’une job MapReduce, en particulier si on cherche à limiter la quantité de données transitant d’un nœud à l’autre.