Lors de l’exécution d’un job MapReduce, il peut être nécessaire de consulter des données régulièrement de façon à les utiliser pour les traitements effectués par le mapper ou le reducer. Par exemple, on peut avoir la nécessité de mettre en place un dictionnaire et y accéder pendant l’exécution du mapper et du reducer.
Hadoop possède une fonctionnalité qui permet de répondre à ce besoin avec le cache distribué (i.e. distributed cache). Ce cache est accessible à partir du système de fichier distribué HDFS ce qui permet à tous les jobs qui s’exécutent de pouvoir y accéder. Il suffit de lire les fichiers sur HDFS.
Le gros intérêt du cache distribué est d’avoir des fichiers de travail consultables par les jobs:
- Pour réduire la quantité de traitements effectués par les jobs,
- Pour limiter la quantité de données transmises entre les mappers et le reducer,
- Pour éventuellement utiliser les résultats d’autres jobs.
Réduire la quantité de traitement ou limiter la quantité de données transitant dans le réseau sont des facteurs qui permettent de rendre l’exécution d’un job MapReduce plus efficace.
Cet article va montrer un exemple d’utilisation du cache distribué avec Hadoop Streaming et une implémentation du mapper et du reducer en C# avec .NET Core.
Explication du cache distribué
Comme indiqué plus haut, le cache distribué (i.e. distributed cache) sont des fichiers accessibles par les jobs sur HDFS. On y accède à partir du mapper ou du reducer en les lisant directement sur le système de fichiers HDFS. Par exemple si un fichier du cache se trouve sur HDFS avec le path suivant:
refdata/distributed_cache_file.txt
On peut y accéder dans l’implémentation du mapper et du reducer en exécutant simplement:
var cacheFileLines = System.IO.File.ReadAllLines("refdata/distributed_cache_file.txt")
Dans l’article Hadoop MapReduce en 5 min, on avait expliqué le fonctionnement d’un job MapReduce en indiquant que les données traitées par les mappers étaient envoyées au reducer. Plus il y a des données à transmettre et plus l’exécution du job sera lente puisque ces données transitent à travers le réseau. On peut donc utiliser le cache distribué pour réduire la quantité de données transitant dans le réseau entre les mappers et le reducer.
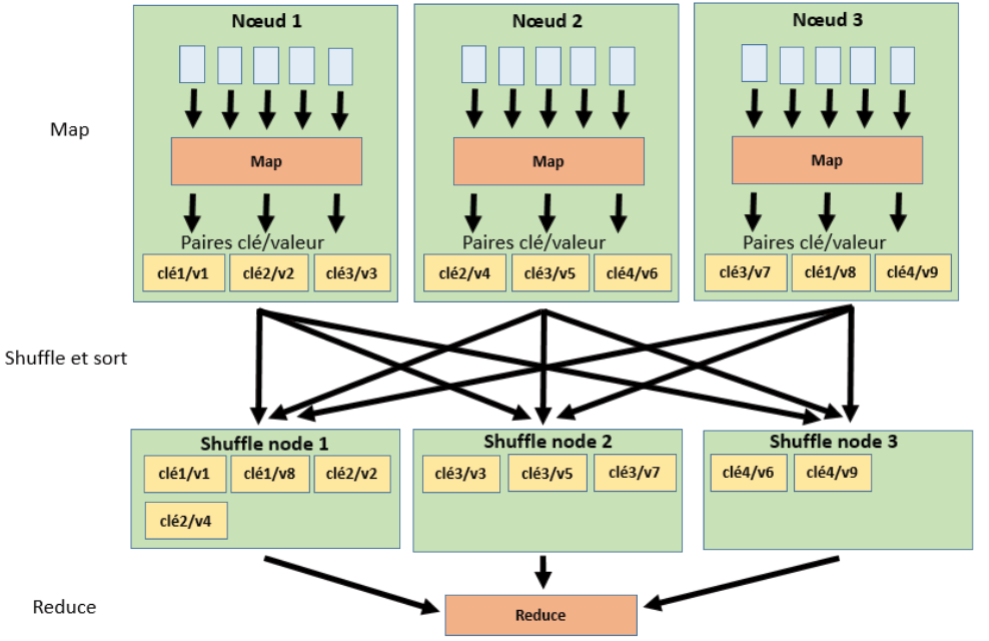
Dans le schéma précédent, les flèches noires indiquent la transmission des données à travers le réseau.
Exemple d’utilisation du cache distribué
On se propose d’illustrer l’utilisation du cache distribué avec le job Word count. Le but est de réduire la quantité de données entre les mappers et le reducer. Les données transmises entre les différents jobs correspondent aux mots. Ainsi si on réduit la taille des mots, on peut réduire la quantité de données transmises.
Une méthode pour réduire la taille des mots est de considérer un dictionnaire comportant pour chaque mot un code. Si la taille de ce code est inférieure à celle du mot, on peut réduire la taille du mot.
Par exemple, si on considère le comptage des mots de la phrase:
"Hadoop est un outil puissant toutefois cet outil a des limites
qui le rendent moins puissant"
Normalement, à la sortie du mapper, on obtient les paires clé/valeur suivantes:
("Hadoop"/1), ("est"/1), ("un"/1), ("outil"/1), ("puissant"/1), ("toutefois"/1),
("cet"/1), ("outil"/1), ("a"/1), ("des"/1), ("limites"/1), ("qui"/1), ("le"/1),
("rendent"/1), ("moins"/1), ("puissant"/1)
Si on affecte un code unique à chacun de ces mots:
hadoop 1
est 2
un 3
outil 4
puissant 5
toutefois 6
cet 7
a 8
des 9
limites A
qui B
le C
rendent D
moins E
On remarque que pour la plupart des mots, le code est plus court en nombre de lettres que le mot. Ainsi, en utilisant le code pour désigner le mot en tant que clé dans le job MapReduce, on économise des lettres lors de la transmission des paires clé/valeur entre les mappers et le reducer.
Dans cet exemple les paires de clé/valeur transmises au reducer seraient:
("1"/1), ("2"/1), ("3"/1), ("4"/1), ("5"/1), ("6"/1), ("7"/1), ("4"/1), ("8"/1),
("9"/1), ("A"/1), ("B"/1), ("C"/1), ("D"/1), ("E"/1), ("5"/1)
Si on prends l’exemple du texte:
http://www.gutenberg.org/files/2600/2600-0.txt
On peut créer un dictionnaire pour affecter à chaque mot un code dont la taille sera réduite par rapport à la taille du mot.
Le code doit être unique pour chaque mot.
Ainsi:
- Chaque mapper lit le dictionnaire et génère des paires clé/valeur avec
code/1au lieu demot/1. - Le reducer lit aussi le dictionnaire pour compter le nombre d’occurrences du code (qui est le même que celui du mot correspondant) et ensuite affecter pour chaque code le mot qui correspond.
La sortie du reducer est donc la même que si on n’utilise pas de dictionnaire. L’échange de données entre les mappers et le reducer ne comporte que des paires code/1 dont la taille est plus faible que les paires mot/1.
Génération du dictionnaire de mots
La 1ère étape consiste à générer des codes uniques pour chaque mot. On affecte à chaque mot un nombre décimal et on convertit ce nombre décimal vers un nombre hexadécimal pour en réduire la taille.
Dans l’exemple évoqué précédemment, on effectue ce traitement:
hadoop 1
est 2
un 3
outil 4
puissant 5
toutefois 6
cet 7
a 8
des 9
limites A
qui B
le C
rendent D
moins E
Si on va plus loin, et au lieu de convertir en hexadécimal, on utilise davantage la table de caractères ASCII en considérant les caractères du code 48 à 122:
- Les chiffres de 0 à 9 du code ASCII 48 à 57.
- Les lettres majuscules de A à Z du code ASCII 65 à 90.
- Les caractères “[“, “\”, “]”, “^”, “_” et “`” du code ASCII 91 à 96.
- Les lettres minuscules de a à z du code ASCII 97 à 122.
Avec ces caractères, le code comporte moins de lettres que les nombres en hexadécimal.
Pour convertir le nombre décimal du mot vers la suite de caractères qui sera le code, on propose donc l’algorithme suivant:
public static string ConvertIntToCode(int number)
{
if (number < 1) return "0";
int codeAsInt = number;
string code = string.Empty;
while (number > 0)
{
codeAsInt = number % 68;
if (codeAsInt < 10)
code = code.Insert(0, Convert.ToChar(codeAsInt + 48).ToString());
else
code = code.Insert(0, Convert.ToChar(codeAsInt + 55).ToString());
number /= 68;
}
return code;
}
Le nombre 68 dans l’algorithme est utilisé parce qu’on considère les caractères de la table ASCII du code 65 à 122.
Pour générer le dictionnaire, on utilise les mots provenant d’un précédent comptage de façon à avoir un exemple de listes de mots.
Par exemple si on considère une liste de mots provenant d’un précédent comptage:
...
perdere 1
peremptorily 3
peremptory 2
perfect 18
perfecting 2
perfection 10
perfectly 24
perform 16
performance 10
performances 2
performed 24
performer 1
performing 8
perfume 4
...
En exécutant l’algorithme suivant:
static void Main(string[] args)
{
string filePath = "part-00000";
string outputFilePath = "word_codes.txt";
int counter = 0;
using (StreamReader reader = new StreamReader(filePath))
{
using (StreamWriter writer = new StreamWriter(outputFilePath, false))
{
string line;
while ((line = reader.ReadLine()) != null)
{
string word = line.Split('\t', StringSplitOptions.RemoveEmptyEntries)
.FirstOrDefault();
if (string.IsNullOrEmpty(word) || word.Length < 3) continue;
writer.WriteLine($"{word}\t{ConvertIntToCode(counter)}");
counter++;
}
}
}
}
On obtient un dictionnaire avec un code unique pour chaque mot:
...
perdere 2mI
peremptorily 2mJ
peremptory 2mK
perfect 2mL
perfecting 2mM
perfection 2mN
perfectly 2mO
perform 2mP
performance 2mQ
performances 2mR
performed 2mS
performer 2mT
performing 2mU
perfume 2mV
...
Adaptation du “mapper” pour utiliser le dictionnaire
Comme indiqué plus haut, on modifie le mapper pour lire le dictionnaire et affecter un code à chaque mot trouvé. Le mapper génère des paires code/1 au lieu de génèrer des paires mot/1.
On modifie l’implémentation du mapper dans l’article: Exécuter un job Hadoop MapReduce avec .NET Core.
Après modification, le mapper devient:
using System;
using System.IO;
using System.Text;
using System.Collections.Generic;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
Dictionary<string, string> wordCounts = GetCachedWordCodes();
var fileLine = Console.ReadLine();
while (fileLine != null)
{
var words = fileLine.Split(' ');
foreach (var word in words)
{
if (string.IsNullOrWhiteSpace(word)) continue;
var wordToWrite = StripPunctuation(word.Trim().ToLower());
string wordCode;
if (wordCounts.TryGetValue(wordToWrite, out wordCode))
{
wordToWrite = wordCode;
}
Console.WriteLine($"{wordToWrite}\t1");
}
fileLine = Console.ReadLine();
}
}
// Permet de lire le dictionnaire se trouvant dans le cache distribué
public static Dictionary<string, string> GetCachedWordCodes()
{
Dictionary<string, string> wordCounts = new Dictionary<string, string>();
var lines = File.ReadAllLines("refdata/word_codes.txt");
foreach (var line in lines)
{
var splitLine = line.Split('\t', StringSplitOptions.RemoveEmptyEntries);
if (splitLine.Length < 2) continue;
string word = splitLine[0];
string wordCode = splitLine[1];
wordCounts[word] = wordCode;
}
return wordCounts;
}
// Supprime la ponctuation
public static string StripPunctuation(string inputString)
{
var outputString = new StringBuilder();
foreach (char character in inputString)
{
if (!char.IsPunctuation(character))
outputString.Append(character);
}
return outputString.ToString();
}
}
}
Dans cet algorithme, File.ReadAllLines("refdata/word_codes.txt") permet de lire le dictionnaire qui se trouve dans le cache distribué sur HDFS.
Exécution du job MapReduce sans adaptation du “reducer”
Si on exécute à cette étape le job MapReduce sur adapter le reducer, on obtiendra la liste de codes avec le nombre d’occurrences.
Il faut placer le dictionnaire word_codes.txt obtenu à l’étape précédente dans le répertoire refdata sur HDFS.
En compilant le mapper et en le plaçant dans le répertoire mapper_distributed_cache:
% dotnet new console –n mapper_distributed_cache
Après avoir modifié l’implémentation dans mapper_distributed_cache/Program.cs:
% cd mapper_distributed_cache
% dotnet build
% dotnet publish –c release
On copie ensuite les résultats de compilation dans le répertoire publish:
% cp bin/release/netcoreapp2.0/publish/* ../publish
On exécute ensuite le job MapReduce:
hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/tools/lib/hadoop-streaming-2.8.1.jar \
-files "publish,refdata" \
-mapper "dotnet publish/mapper_distributed_cache.dll" \
-reducer "dotnet publish/reducer.dll" \
-input /user/input/comparison/2600-0.txt \
-output /output_distributedcache_mapper
On obtient une liste de codes avec les occurrences des mots:
...
2mi 1
2mj 2
2mk 3
2ml 4
2mm 1
2mn 1
2mo 8
2mp 1
2mq 24
2mr 1
2ms 2
2mt 1
2mu 1
2mv 8
...
Le résumé de l’exécution est le suivant:
File System Counters
FILE: Number of bytes read=4311878
FILE: Number of bytes written=9044253
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3363856
HDFS: Number of bytes written=122053
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=78664
Total time spent by all reduces in occupied slots (ms)=15192
Total time spent by all map tasks (ms)=39332
Total time spent by all reduce tasks (ms)=7596
Total vcore-milliseconds taken by all map tasks=39332
Total vcore-milliseconds taken by all reduce tasks=7596
Total megabyte-milliseconds taken by all map tasks=80551936
Total megabyte-milliseconds taken by all reduce tasks=15556608
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=3179256
Map output materialized bytes=4311884
Input split bytes=210
Combine input records=0
Combine output records=0
Reduce input groups=20311
Reduce shuffle bytes=4311884
Reduce input records=566308
Reduce output records=20310
Spilled Records=1132616
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=328
CPU time spent (ms)=9270
Physical memory (bytes) snapshot=572051456
Virtual memory (bytes) snapshot=8277377024
Total committed heap usage (bytes)=398663680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3363646
File Output Format Counters
Bytes Written=122053
Adaptation du “reducer”
On adapte le reducer pour lire le dictionnaire, et affecter le mot correspondant à chaque code trouvé. L’implémentation de départ du reducer est celle se trouvant dans l’article Exécuter un job Hadoop MapReduce avec .NET Core.
Après adaptation, le reducer devient:
using System;
using System.Collections.Generic;
using System.IO;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
Dictionary<string, string> word_codes = GetCachedWordCodes();
string currentWord = string.Empty;
int currentWordCount = 0;
string word = string.Empty;
string valueFromMapper = Console.ReadLine();
while (valueFromMapper != null)
{
var splitLine = valueFromMapper.Split('\t');
if (splitLine.Length == 2)
{
word = splitLine[0];
int count;
if (Int32.TryParse(splitLine[1], out count))
{
if (currentWord == word)
{
currentWordCount += count;
}
else
{
if (!string.IsNullOrWhiteSpace(currentWord))
{
string wordToWrite = currentWord;
word_codes.TryGetValue(currentWord, out wordToWrite);
Console.WriteLine($"{wordToWrite}\t{currentWordCount}");
}
currentWord = word;
currentWordCount = count;
}
}
}
valueFromMapper = Console.ReadLine();
}
if (currentWord == word && !string.IsNullOrWhiteSpace(currentWord))
{
string wordToWrite = currentWord;
word_codes.TryGetValue(currentWord, out wordToWrite);
Console.WriteLine($"{wordToWrite}\t{currentWordCount}");
}
}
// Permet de lire le dictionnaire se trouvant dans le cache distribué
public static Dictionary<string, string> GetCachedWordCodes()
{
Dictionary<string, string> wordCounts = new Dictionary<string, string>();
var lines = File.ReadAllLines("refdata/word_codes.txt");
foreach (var line in lines)
{
var splitLine = line.Split('\t', StringSplitOptions.RemoveEmptyEntries);
if (splitLine.Length < 2) continue;
string word = splitLine[0];
string wordCode = splitLine[1];
wordCounts[wordCode] = word;
}
return wordCounts;
}
}
}
De la même façon que le mapper, File.ReadAllLines("refdata/word_codes.txt") permet de lire le dictionnaire qui se trouve dans le cache distribué sur HDFS.
Exécution du job MapReduce avec le “reducer” adapté
On compile le reducer et on le place dans le répertoire reducer_distributed_cache:
% dotnet new console –n reducer_distributed_cache
Après avoir modifié l’implémentation dans reducer_distributed_cache/Program.cs:
% cd reducer_distributed_cache
% dotnet build
% dotnet publish –c release
On copie les résultats de compilation dans le répertoire publish:
% cp bin/release/netcoreapp2.0/publish/* ../publish
On exécute ensuite le job MapReduce:
hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/tools/lib/hadoop-streaming-2.8.1.jar \
-files "publish,refdata" \
-mapper "dotnet publish/mapper_distributed_cache.dll" \
-reducer "dotnet publish/reducer_distributed_cache.dll" \
-input /user/input/comparison/2600-0.txt \
-output /output_distributedcache
On obtient une liste de mots avec leur occurrence comme si on n’avait pas utilisé de cache distribué:
...
perdere 1
peremptorily 3
peremptory 2
perfect 18
perfecting 2
perfection 10
perfectly 24
perform 16
performance 10
performances 2
performed 24
performer 1
performing 8
perfume 4
...
Le résumé de l’exécution est le suivant:
File System Counters
FILE: Number of bytes read=4311878
FILE: Number of bytes written=9044253
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3363856
HDFS: Number of bytes written=122053
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=78664
Total time spent by all reduces in occupied slots (ms)=15192
Total time spent by all map tasks (ms)=39332
Total time spent by all reduce tasks (ms)=7596
Total vcore-milliseconds taken by all map tasks=39332
Total vcore-milliseconds taken by all reduce tasks=7596
Total megabyte-milliseconds taken by all map tasks=80551936
Total megabyte-milliseconds taken by all reduce tasks=15556608
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=3179256
Map output materialized bytes=4311884
Input split bytes=210
Combine input records=0
Combine output records=0
Reduce input groups=20311
Reduce shuffle bytes=4311884
Reduce input records=566308
Reduce output records=20310
Spilled Records=1132616
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=328
CPU time spent (ms)=9270
Physical memory (bytes) snapshot=572051456
Virtual memory (bytes) snapshot=8277377024
Total committed heap usage (bytes)=398663680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3363646
File Output Format Counters
Bytes Written=122053
Comparaison entre l’exécution avec et sans cache distribué
L’intérêt de l’utilisation du cache distribué n’est pas dans le résultat obtenu puisqu’il est le même, mais dans le temps et la quantité de données échangées entre les mappers et le reducer.
Ainsi si on considère le résumé de l’exécution du job MapReduce word count sans cache distribué:
File System Counters
FILE: Number of bytes read=5375603
FILE: Number of bytes written=11170764
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3363856
HDFS: Number of bytes written=227620
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=68848
Total time spent by all reduces in occupied slots (ms)=15542
Total time spent by all map tasks (ms)=34424
Total time spent by all reduce tasks (ms)=7771
Total vcore-milliseconds taken by all map tasks=34424
Total vcore-milliseconds taken by all reduce tasks=7771
Total megabyte-milliseconds taken by all map tasks=70500352
Total megabyte-milliseconds taken by all reduce tasks=15915008
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=4242981
Map output materialized bytes=5375609
Input split bytes=210
Combine input records=0
Combine output records=0
Reduce input groups=20471
Reduce shuffle bytes=5375609
Reduce input records=566308
Reduce output records=20470
Spilled Records=1132616
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=327
CPU time spent (ms)=8530
Physical memory (bytes) snapshot=574074880
Virtual memory (bytes) snapshot=8277377024
Total committed heap usage (bytes)=398663680
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3363646
File Output Format Counters
Bytes Written=227620
Sur la quantité de données échangées, on constate une légère diminution:
- Sans cache distribué:
Map output materialized bytes=5375609 - Avec cache distribué:
Map output materialized bytes=4311884
Soit un gain de 20% par rapport à l’utilisation sans cache distribué.
Au niveau du temps d’exécution:
- Sans cache distribué: 49 sec
- Avec cache distribué: 53 sec
On constate une légère pénalité dans le temps d’exécution qui peut s’expliquer par les traitements supplémentaires effectués pour faire la conversion mot → code dans les mappers et code → mot dans le reducer.
Dans cet exemple, le temps d’exécution n’a pas été réduit toutefois, suivant la quantité de données transitant dans le réseau, on peut imaginer que dans certains cas, le cache distribué permet de limiter les échanges de données.
- Hadoop Streaming: https://hadoop.apache.org/docs/r1.2.1/streaming.html
- Yahoo! Hadoop Tutorial –
Module 5: Advanced MapReduce Features: https://developer.yahoo.com/hadoop/tutorial/module5.html#auxdata