Hadoop (i.e. High-availability distributed object-oriented platform) est une système distribué permettant de stocker et d’analyser des données. Le grand intérêt d’Hadoop est de proposer un framework pour effectuer des analyses de données de façon parallélisée sur plusieurs machines. D’autre part, Hadoop permet d’utiliser des machines normales et de les associer en groupe de façon à ce que les puissances de calcul soient additionnées. Ces groupes de machines sont appelés des clusters et chaque machine est appelée un nœud (ou node). En effet, pour effectuer de gros traitements il n’est pas nécessaire d’utiliser de gros serveurs de type “mainframe”, plusieurs PC individuels de puissance classique suffisent.
Les avantages principaux d’Hadoop sont:
- Permet une grande scalabilité pour stocker et traiter de grandes quantités de données.
- Est tolérant aux pannes.
- Est optimisé pour un type varié de données (comme le texte ou les images).
- Possède un écosystème riche et souvent gratuit composé de différents outils capables de résoudre une problématique précise.
Les traitements effectués par Hadoop sont appelés des jobs, ils sont exécutés suivant un paradigme unique appelé MapReduce. Ce paradigme a pour but de rendre l’implémentation d’un job moins complexe pour le développeur en l’affranchissant de toutes les problématiques liées au calcul distribué.
Ainsi un job MapReduce va effectuer plusieurs opérations:
- Séparer les données en entrée en plusieurs morceaux indépendants (appelés chunks) qui pourront être traités en parallèle. Les chunks en entrée sont traités par des tâches appelées “map tasks”.
- La sortie des tâches ou “map tasks” est ensuite triée.
- Les données d’entrée et de sortie d’un job MapReduce sont stockées sur un système de fichiers distribués appelé HDFS (i.e. Hadoop distributed file system).
- Le framework Hadoop permet de programmer l’exécution des tâches suivant la puissance de calcul, de monitorer l’exécution des tâches et de ré-exécuter les tâches dont l’exécution aurait échouée.
- Un job MapReduce peut être implémenté sans effectuer de développement relatif à la parallélisation des tâches, à la distribution du travail sur les différentes machines du système ou des opérations de récupération des données sur le système de fichiers distribués. Il n’y a pas non plus de changements de l’implémentation vis-à-vis de l’adaptation du cluster à la charge.
Le but de cet article est d’expliciter les grandes lignes de l’architecture d’Hadoop, des différents éléments qui composent ce système et d’expliquer brièvement comment implémenter un job MapReduce.
Cette article permet d’avoir quelques connaissances théoriques pour permettre d’exécuter des jobs Hadoop MapReduce. Il n’y a pas d’explications de code mais juste des explications du point de vue algorithmique. Le code permettant d’exécuter un job en .NET sera explicité, par la suite, dans un article futur.
L’écosystème Hadoop
HDFS
Name node
Secondary name node
Data node
YARN
Resource Manager
Node manager
Application master
Container
MapReduce
Architecture d’Hadoop
Explication générale d’un job MapReduce
Map
Reduce
Shuffle
Sort
Reduce
Exemples de jobs MapReduce
Word count
Moteur de recherche
Multiplication d’une matrice et d’un vecteur
L’écosystème Hadoop
Comme indiqué plus haut, l’écosystème Hadoop est très riche et est composé plusieurs outils qui peuvent être organisé en couches. Les composants dans une même couche ne communiquent pas entre eux, ils communiquent avec des composants sur les couches supérieures ou inférieures:
- Hadoop HDFS (i.e. Hadoop Distributed File System)
- Yarn (i.e. Yet Another Resource negotiator): gestion de ressources.
- MapReduce: modèle de programmation pour permettre d’appliquer un calcul (Map) et d’agréger les résultats (Reduce).
- Hive et Pig: modèle de programmation haut niveau au dessus de MapReduce pour apporter une abstraction: Hive permet d’effectuer des requètes SQL et Pig permet d’effectuer du scripting sur des flux de données.
- Giraph: permet d’analyser des graphes pour les réseaux sociaux.
- Storm, Spark, Flink: traitement en mémoire et en temps réel.
- HBase, Cassandra, MongoDB: base de données NoSQL permettant de gérer des collections de clé-valeurs ou de grandes tables séparées (i.e. “sparse tables”).
- Zookeeper: permet de centraliser la configuration, la synchronisation et la disponibilité de ces outils.
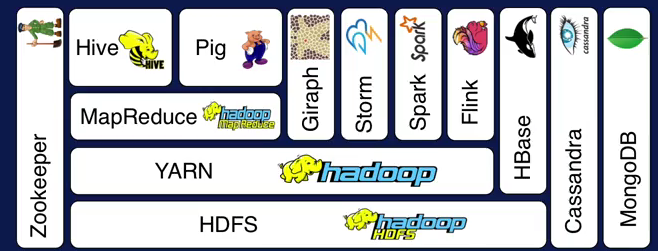
Dans l’installation de base d’Hadoop, seuls les composants HDFS, Yarn et MapReduce sont présents. Les autres composants doivent etre installés de façon séparée.
Tous ces outils sont libres et peuvent être utilisés ensemble.
Des solutions existent pour livrer l’ecosystème entier avec tous les outils sans considérer des installations séparées comme Cloudera, MapR ou Hortonworks.
Ces solutions doivent être installées sur un système hôte ou sur des machines virtuelles. Il est aussi possible d’utiliser un écosystème entier avec des solutions Cloud comme Amazon EC2, HDInsight de Microsoft Azure ou Cloud Dataproc de Google Cloud.
Pour effectuer des tests, on peut aussi facilement installer Hadoop sur une Debian GNU/Linux en utilisant une machine virtuelle.
HDFS
HDFS (i.e. Hadoop Distributed File System) est un système de fichiers dont la caractéristique principale est de permettre à Hadoop d’utiliser des fichiers en entrée pour l’exécution de ses jobs et d’écrire le résultat des jobs de façon distribuée. La manipulation des fichiers devient ainsi complètement transparente.
Hadoop est un système distribué et nécessite de pouvoir traiter des fichiers sur plusieurs nœuds d’un cluster. HDFS est capable de répondre aux exigences posées par Hadoop suivant plusieurs critères:
- HDFS peut répartir des fichiers sur plusieurs machines en additionnant la taille de chaque nœud de façon à ne former qu’un seul espace de stockage.
- HDFS répartit plusieurs fractions d’un fichier sur plusieurs nœuds ce qui permet de stocker des fichiers dont la taille dépasse la taille du disque d’un nœud. Les fractions de fichier ont des tailles fixes de 128 MO, ces fractions s’appellent des “chunks”.
- Pour éviter les pertes de données dans le cas de crash d’un disque, HDFS réplique ses fichiers sur plusieurs nœuds d’un cluster. Il existe aussi des paramètres pour que HDFS prenne en compte les racks dans lesquels sont rangés les serveurs. Ainsi dans la réplication, il peut isoler encore davantage les données.
- L’écriture et la manipulation des données par HDFS sont transparentes. Le système de fichiers apparaît comme un espace de stockage unique alors qu’il est composé de l’addition de plusieurs disques sur plusieurs nœuds du cluster.
Pour éviter un trop grand nombre d’échanges de données entre nœuds d’un cluster, Hadoop minimise les données qui doivent transiter d’un nœud à l’autre lors du traitement d’un job. Les traitements se font, en priorité, sur le nœud où se trouve les données. Le programme effectuant les traitements est déplacé sur le nœud où il sera exécuté car il est généralement beaucoup moins volumineux que les données qu’il manipule.
HDFS permet, en outre, de stocker de grandes quantités de données dans de larges datasets de façon scalable c’est-à-dire qu’il est possible d’augmenter l’espace disque en ajoutant des nœuds au cluster. HDFS distingue plusieurs types de nœuds: les name nodes et les data nodes.
Chaque fichier stocké dans HDFS possède des méta-données qui sont:
- Le nom du fichier,
- Les données de permission relatives à ce fichier: similaire aux permissions dans un système Unix.
- La localisation des blocs relatifs à ce fichier sur les data nodes.
La taille des blocs de fichiers étant assez grande (128 MO par défaut), ce qui permet de réduire le nombre de blocs utilisés pour stocker un ficher. Moins le nombre de blocs est important et moins nombreux seront les méta-données associés à chaque fichier. D’autre part, les blocs de grande taille permettent de favoriser la lecture en continu des données sur un disque. Plus les données seront lues de façon continue sur les disques et plus un job MapReduce sera exécuté de façon efficace et rapide. A l’opposé, la lecture de fichiers de taille faible implique des accés répétés et succints à des disques pouvant se trouver sur des nœuds différents. Ce qui tend à diminuer les performances.
La répartition des données est uniforme sur les nœuds du cluster. Un composant appelé le balancer s’exécute régulièrement pour répartir les données sur les nœuds de façon uniforme dès que la différence est trop importante. Si on ajoute un nœud au cluster, le balancer s’exécute aussi pour répartir les données sur le nouveau nœud lors d’une phase de réallocation de blocs. Supprimer un nœuds d’un cluster correspond aussi à une opération particulière.
Sur le schéma suivant, on peut voir qu’il existe un name node par cluster. Les clients ajoutent ou suppriment des fichiers de façon transparente directement sur les data nodes en passant par HDFS. Pour exécuter un job, les clients s’adressent au name node qui sollicite les data nodes. La réplication se fait directement entre data nodes, il n’y a pas d’échanges de données entre le name node et les data nodes.
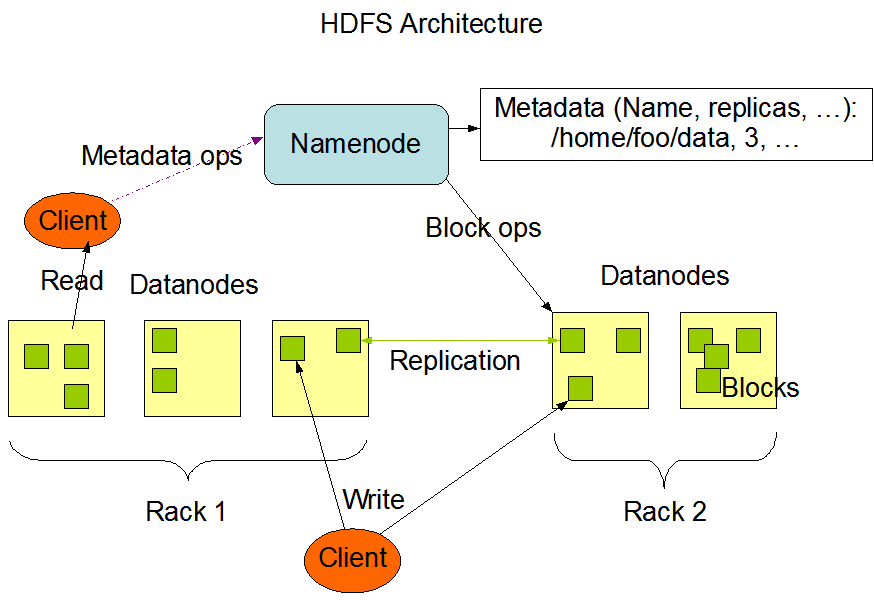
On peut facilement requêter HDFS à l’aide d’instructions à la ligne commandes.
Name node
Il s’agit d’un service central (appelé aussi master node). Il a pour but de:
- Gérer l’état du système de fichiers
- Maintient l’arborescence du système de fichiers d’Hadoop et les méta-données associées aux fichiers. Les méta-données permettent d’indiquer où le fichier se trouve physiquement.
- Le name node connaît les autres types de nœuds appelés data nodes où se trouvent les blocs permettant de stocker les fichiers.
- Quand le client intervient sur le système de fichiers, il le fait sur les data nodes. Le name node effectue ensuite les demandes aux data nodes pour répondre aux requêtes du client.
Les méta-données associées à chaque fichier sont stockées sur le disque auprès du name node dans des fichiers edits_xxx et fsimage_xxx (se trouvant dans le répertoire de données de HDFS: <répertoire de données>/hd-data/tmp/dfs/name/current).
Les positions des blocs de fichier dans les data nodes sont stockées en mémoire (de façon à permettre un accès rapide) et sont reconstruites à chaque démarrage du name node (pendant une phase appelée “safe mode”). Ainsi plus le nombre de fichiers stockée dans HDFS est important et plus il y aura de positions stockées dans la mémoire du name node. L’utilisation de fichiers de grande taille permet de minimiser la quantité de meta-données stockée dans la mémoire du name node. Enfin la mémoire du name node peut être une limite s’il y a trop de meta-données à stocker.
Secondary name node
Ce nœud copie les méta-données se trouvant auprès du name node et vérifie l’état de fonctionnement du name node. Dans le cas où ce dernier présente une défaillance, le secondary name node est capable de prendre le relais en prenant la place du name node principal.
Le passage du secondary name node au name node n’est pas automatique. Il nécessite une opération manuelle.
Data node
Les fichiers sont stockés sur les nœuds de ce type. Ils assurent une fonction de stockage et permettent au name node d’accéder aux données quand une tâche le nécessite.
Quand un fichier est ajouté à HDFS, il est séparé en plusieurs blocs de taille fixe lors d’une étape de “partitionning” et chaque bloc est ensuite répliqué sur plusieurs data nodes du cluster (1 cluster est lui-même composé de plusieurs data nodes). Par défaut, les blocs mémoire font 128 MO et le facteur de réplication de ces blocs est de 3, toutefois ces valeurs sont configurables.
Les data nodes répondent aux différentes demandes du name node et utilise les méta-données fournies par le name node pour:
- Créer des blocs
- Supprimer des blocs
- Répliquer des blocs
Le name node ne fait qu’indiquer des traitements à effectuer aux data nodes, il ne lit pas directement les données. Lors de copies de données, par exemple, les copies sont effectuées entre data nodes, elles ne transitent pas par le name node.
Le partitionning permet des accès parallèles aux blocs du fichier. La réplication réponds à plusieurs objectifs:
- Tolérance aux pannes: s’il y a un défaut d’un nœud ou une coupure réseau, les données ne sont pas perdues et sont facilement retrouvables.
- Performance: il est plus rapide d’exécuter un traitement sur des données si elles se trouvent déjà sur le nœud qui va effectuer le traitement.
L’inconvénient de la réplication est qu’elle nécessite plus d’espace de stockage.
YARN
YARN (i.e. Yet Another Resource Negotiator) est un composant qui se trouve au dessus de HDFS qui permet de gêrer l’exécution de jobs en parallèle. Il sert de base et est utilisé par d’autres applications comme MapReduce, Spark etc…
Comme pour HDFS, YARN est composé de plusieurs services ayant des fonctions spécifiques: le resource manager, le node manager, l’application master et le container.
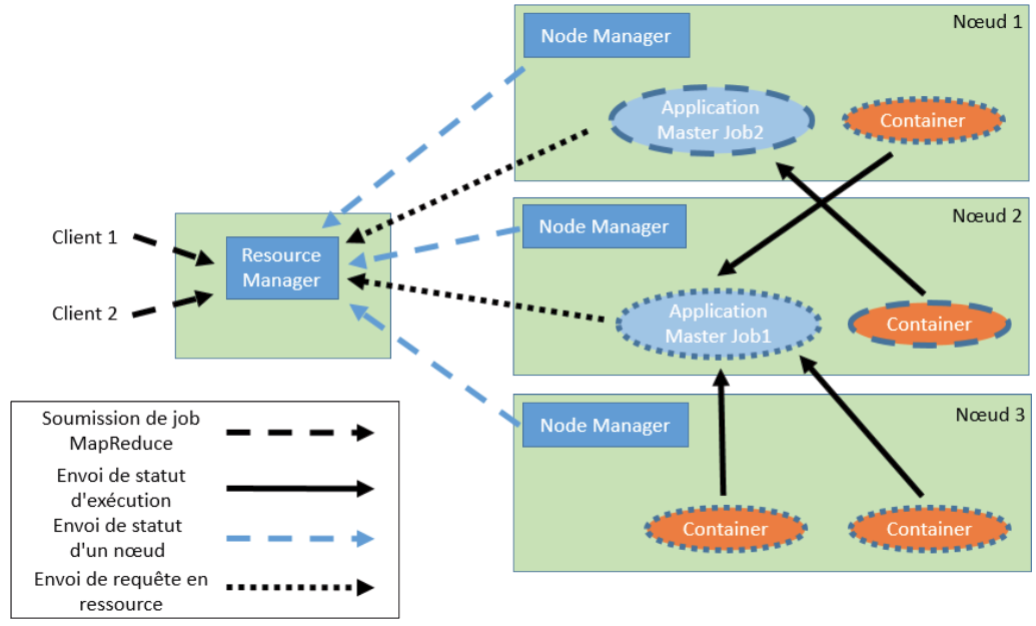
D’une façon générale, YARN organise l’exécution d’un job MapReduce dans un cluster en minimisant le déplacement des données et l’utilisation de ressources pour que les performances soient maximisées. Les données nécessaires à l’exécution d’un job ne se trouvent pas forcément dans le nœud où l’exécution sera effectuée. Ainsi, le traitement se fait en priorité où les données se trouvent pour augmenter la bande passante entre les clusters.
Resource Manager
Ce service permet d’ordonnancer et de dispatcher les tâches sur le cluster Hadoop. Quand YARN reçoit un job à exécuter, c’est le resource manager qui reçoit le job et qui le dispatche le plus rapidement possible sur les autres nœuds du cluster. Le cluster doit être exploité au maximum de ses capacités lors de l’exécution du job. Quand le resource manager reçoit le job sous forme de package MapReduce, il crée un application manager (on verra par la suite la fonction de ce composant) qu’il va transmettre à un nœud pour qu’il puisse exécuter le job.
Pour que le resource manager puisse assurer son rôle de coordination des ressources du cluster, il reçoit pendant l’exécution du job le statut des nœuds et l’application master lui transmet des requêtes pour obtenir de la ressource. C’est le resource manager qui va assigner à l’application master les ressources nécessaires à l’exécution du job.
Node manager
Chaque nœud ou machine du cluster dispose d’un service appelé node manager qui va organiser les resources de la machine. Le node manager envoie périodiquement le statut du nœud au resource manager pour que ce dernier puisse répartir la charge efficacement suivant les ressources.
Application master
Cette application est créée par le resource manager pour exécuter un job. En fonction des statuts que les node managers transmettent au resource manager, ce dernier va affecter l’exécution de l’application master auprès d’un nœud. Pendant l’exécution du job, le resource manager reçoit les informations de statut du job grâce au node manager.
L’application master a pour but de négocier les ressources auprès du resource manager. Quand le job est terminé, l’application master indique au resource manager la fin de son exécution. Le nœud est alors désalloué par le resource manager pour qu’il soit de nouveau disponible pour un nouveau job.
Container
Un container est une ressource abstraite correspondant à une machine: cette notion regroupe la mémoire, le réseau et d’autres ressources de la machine. Les containers envoient à l’application master, les statuts d’exécution d’un job MapReduce.
MapReduce
MapReduce est à la fois un paradigme de développement de jobs pour Hadoop et il est aussi un composant d’Hadoop. Le composant Hadoop MapReduce permet d’organiser et d’exécuter des jobs en parallèle sur un système de fichiers distribués HDFS.
Plusieurs autres outils de l’écosystème Hadoop utilisent Hadoop MapReduce comme par exemple:
- Hive qui propose une infrastructure de stockage et une syntaxe SQL pour la requêter.
- Pig qui est un langage de flux de données et un framework d’exécution de job en parallèle.
L’exécution de jobs en parallèle nécessite la maitrise de notions complexes comme les sémaphores, la mémoire partagée entre threads, de locks etc… Hadoop MapReduce permet d’éviter de prendre en compte toutes ces notions pour se focaliser davantage sur l’implémentation du job au sens fonctionnel à condition de respecter le concept de programmation MapReduce. Ce paradigme permet à Hadoop d’exécuter ses tâches de façon isolée pour optimiser la scalabilité d’un cluster.
A cause du paradigme de programmation MapReduce, tous les traitements ne sont pas forcément possibles. Ainsi pour utiliser MapReduce, il faut que:
- Les calculs soient parallélisables: si certaines opérations dépendent l’une de l’autre, il n’y aura pas d’intérêt à utiliser Hadoop et un job MapReduce.
- Traiter de grands volumes de données: la mise en place des tâches d’exécution de l’opération Map peuvent prendre à elles-seules 1 min. Donc pour que l’exécution d’un job MapReduce soit efficace, il faut que le traitement soit effectué sur un grand nombre de données.
- Le résultat final soit plus petit que l’ensemble de données de départ: dans le cas contraire, un job MapReduce n’est pas forcément pertinent. En effet un part du job consiste à agréger des valeurs donc s’il n’y a pas d’agrégation, une part de l’exécution de ce job est inutile.
- Etre capable de convertir les données en liste de paire clé/valeur: cette contrainte peut être difficile à mettre en place mais est primordiale pour l’exécution du job MapReduce car la clé est la seule façon d’avoir un élément permettant, d’abord de ségréger différentes valeurs pour permettre un traitement parallélisable (durant les étapes Map) et ensuite la clé est encore utilisée pour agréger les valeurs (durant la ou les étapes Reduce).
Architecture d’Hadoop
Avant d’expliquer l’exécution d’un job MapReduce et maintenant que certaines notions ont été définies, on peut expliquer l’architecture d’un cluster Hadoop.
Comme on a pu le voir plus haut, Hadoop s’occupe de récupérer les données pour effectuer les traitements distribués, de distribuer les tâches et de gérer les erreurs. Un cluster Hadoop nécessite plusieurs nœuds pour être complètement fonctionnel:
- Master nodes: il en faut 2, le premier en mode actif et l’autre en mode passif. Le 2e remplace le premier en cas de défaillance. Le master node contient les services suivants:
- Le name node HDFS
- Le resource manager YARN
- Worker nodes: il en faut 3 au minimum. Les données sont ainsi répliquées 3 fois sur les 3 nœuds. On peut rajouter d’autres nœuds, plus le nombre de nœuds est important et plus les tâches s’exécuteront rapidement. Comme indiqué plus haut, les données ne se trouvent pas forcément dans le nœud dans lequel les jobs vont s’exécuter. YARN effectue le transfert d’un worker node à l’autre en minimisant les transferts de données pour augmenter les performances. Chaque worker node contient les services:
- Le data node HDFS
- Le node manager YARN
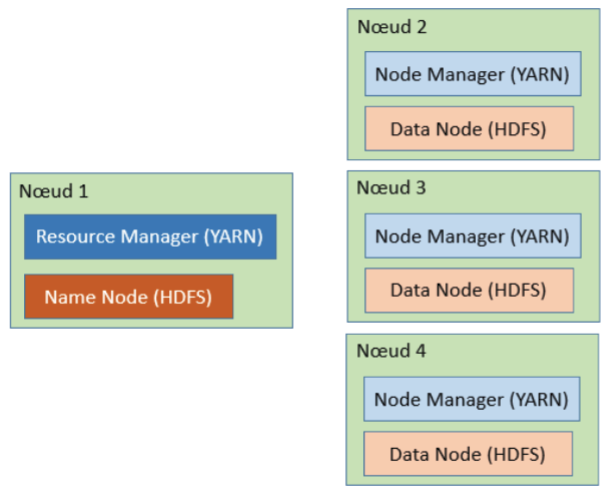
Le master node effectue la coordination et les worker nodes s’occupent du stockage et du traitement des données. Il n’est pas nécessaire d’avoir une configuration hardware particulière pour les worker nodes.
En cas d’échecs, plusieurs points de redondance sont assurés pour palier à une panne d’un master node ou d’un worker node:
- Si un worker node est en échec: les données sont répliquées 3 fois donc en cas d’échec d’un worker node, le cluster est encore fonctionnel et les données ne sont pas perdues. Un mécanisme de heartbeat permet à YARN de savoir si un worker node est hors-ligne ou non. Si un worker node devient absent ou si seulement un disque d’un nœud crashe, les données sont copiées sur un autre worker node pour être sûr d’avoir 3 réplications des données.
- Si le master node est en échec: on ne peut plus utiliser YARN donc le nœud doit être mis en mode passif et le 2e master node qui était en mode passif doit être mis en mode actif. Le mécanisme de passage du mode passif à actif n’est pas automatique, il doit se faire manuellement.
Explication générale d’un job MapReduce
MapReduce est basé sur des concepts de programmation fonctionnelle:
- Des opérations Map: permet de lire les données en entrée et d’appliquer des opérations à toutes les données lues.
- Une ou plusieurs opérations Reduce: qui agrège les résultats provenant des opérations Map et les écrit.
Map
Les opérations Map sont effectuées par un composant logiciel appelé le mapper. Concrètement il s’agit d’une classe dans laquelle il faut implémenter les fonctions qui effectueront le traitement suivant:
- Récupérer des données d’entrée fournies par Hadoop (les données d’entrée font partie des paramètres d’entrée du job Hadoop). Dans le cas d’un fichier texte, c’est Hadoop qui lit le fichier et non le mapper. Les données d’entrée du mapper sont directement les lignes du fichier sous forme de chaînes de caractères.
- Filtrer ces données si nécessaire,
- Ranger les données sous forme de paires clé/valeur et
- Renvoyer la liste de paires clé/valeur dans Hadoop.
Ainsi une instance du mapper s’exécute dans une tâche et sur un bloc de données. Différentes instances du mapper s’exécutent en parallèle. Le nombre de tâches Map dépend du nombre de données en entrée toutefois le bon niveau de parallélisme est atteint entre 10 et 100 tâches Map par nœud. A la fin de son exécution, le mapper produit des données intermédiaires qui ne sont pas le résultat final. Il renvoie ces données à Hadoop qui effectuera d’autres traitements.
C’est dans l’étape Map et dans l’implémentation du mapper qu’il faut choisir la granularité des données qui seront traitées par l’étape Map. Par exemple, dans le cas où on doit effectuer des opérations sur les lignes d’un fichier, c’est cette étape qui indiquera si on doit lire un mot à la fois, une ligne à la fois ou une lettre à la fois etc…
Si on décide de lire une ligne à la fois, une tâche consistant à effectuer un traitement sur une ligne ne doit pas avoir de liens avec la ligne précédente ou la ligne suivante. Sachant que les traitements sont faits en parallèle, ils ne peuvent pas dépendre l’un de l’autre.
Par défaut, les données d’entrée du mapper sont des lignes (TextInputFormat) mais il est possible de modifier ce format d’entrée en précisant un autre format d’entrée (KeyValueInputFormat, FileInputFormat ou SequenceFileInputFormat). Préciser un autre format d’entrée permet de changer un autre niveau de granularité des données. Par exemple à ce niveau, on pourrait traiter les fichiers un à un ou par paragraphe au lieu de les traiter par lignes.
Reduce
L’étape Reduce est composée de 3 sous-étapes: Shuffle, Sort et une étape Reduce à proprement parlé.
Shuffle
Cette étape est effectuée par Hadoop. Elle permet de récupérer les paires de clé/valeur obtenues à la suite de l’opération Map puis de les mixer et de les trier en les répartissant dans des shuffle nodes. Les shuffle nodes sont, en fait, les mêmes nœuds que ceux utilisés lors de l’étape Map toutefois lorsque les paires de clé/valeur sont obtenues, elles sont réaffectées à des nœuds pouvant être différents de ceux dont elles sont issues. L’étape de Shuffle effectue, ainsi, une réaffectation des paires clé/valeur en fonction des clés.
Les étapes de Shuffle commencent dès qu’une opération Map s’est terminée et elles s’exécutent en parallèle. Les étape Shuffle s’exécutent en même temps que les étapes Sort.
Sort
L’étape de Sort est aussi effectuée par Hadoop. Elle s’exécute de façon simultanée avec l’étape Shuffle. Elle consiste à trier les paires clé/valeur et à les répartir dans les shuffle nodes suivant leur clé. Ainsi les paires possédant la même clé seront rangées en priorité dans le même shuffle node.
Cette étape permet de préparer l’étape Reduce de façon à réduire sa charge de travail. Comme indiqué précédemment, l’étape de Sort est effectuée en même temps que l’étape Shuffle.
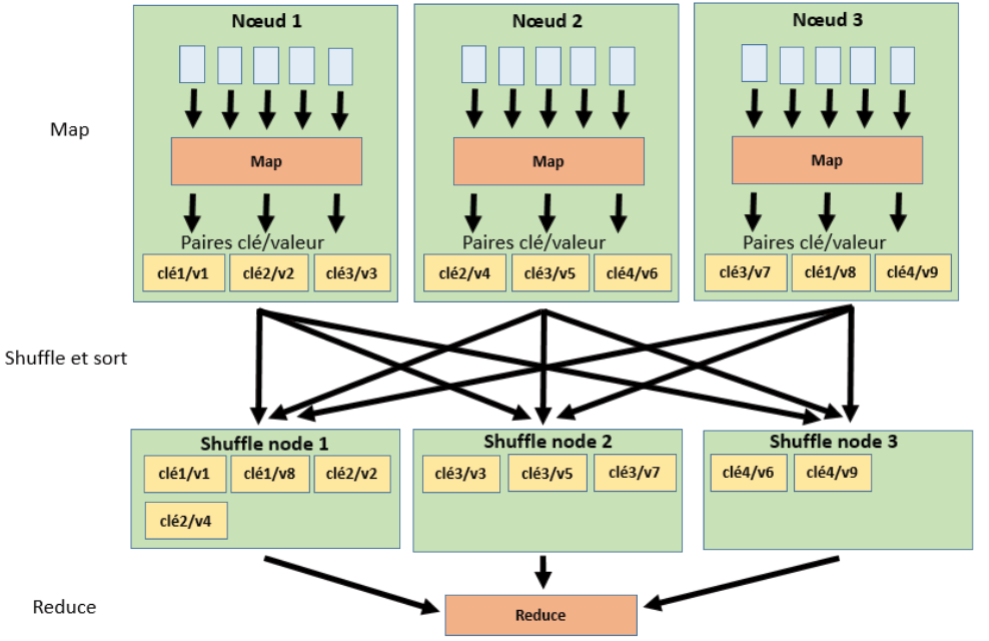
Reduce
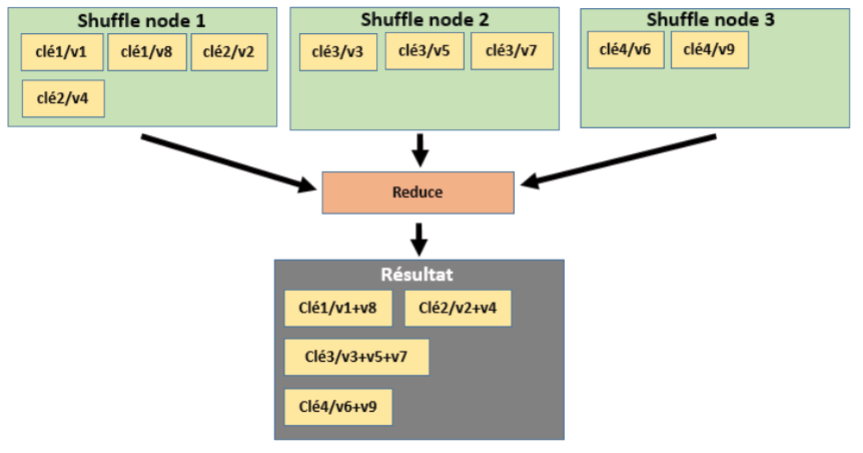
Cette étape est effectuée par un composant logiciel appelé reducer. De la même façon que pour le mapper, le reducer est une classe dans laquelle des fonctions effectuent un traitement fonctionnel pour traiter les paires de clé/valeur de façon à les agréger.
En effet, après l’étape Sort, les données d’entrée de l’étape Reduce sont des listes de paires clé/valeur regroupées par clé. Le reducer devra donc:
- Récupérer les paires de clé/valeur, ces paires sont fournies par Hadoop,
- Agréger les valeurs ayant la même clé
- Renvoyer la liste de paire clé/valeur réduite à Hadoop pour qu’il écrive sur le disque le résultat du job.
Sachant que l’étape de Reduce a consisté à agréger les valeurs ayant la même clé, le résultat comprendra moins de paires que le nombre de paires fournies en entrée. A l’issue de l’étape Reduce, on obtiendra une liste de paires avec la clé et des valeurs agrégées.
Par défaut, il n’y a qu’une seule étape Reduce pour le job même s’il y a plusieurs nœuds. Dans le cas d’une seule étape Reduce, il y aura un seul fichier résultat contenant toutes les valeurs agrégées.
Par configuration, il est possible d’indiquer que l’on souhaite plusieurs étapes Reduce. Dans ce cas, les opérations Reduce seront effectuées en parallèle et il y aura autant de fichier résultat que d’opération Reduce. Même s’il y aura plusieurs fichiers contenant les résultats, avoir plusieurs étapes Reduce permet de paralléliser cette étape de façon à réduire son temps d’exécution.
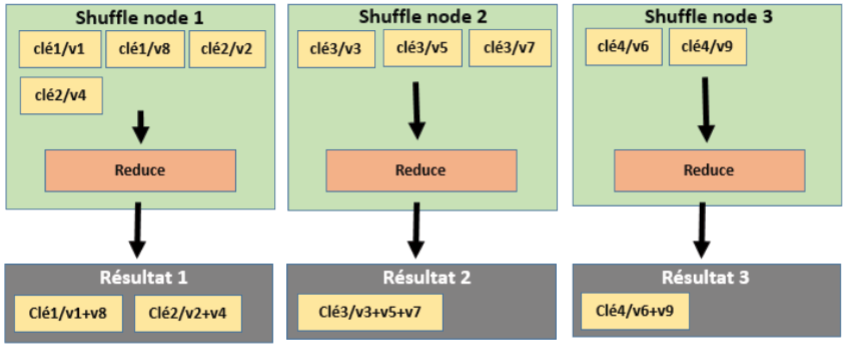
A l’opposé, on peut ne pas effectuer d’étape de Reduce. Si elle n’est pas effectuée, le fichier résultat contiendra une liste de paire clé/valeur sans agrégation des valeurs.
Exemples de jobs MapReduce
Word count
Le job “word count” est l’exemple classique utilisé pour illustrer un job MapReduce. Il consiste à compter le nombre de mots dans un texte. Ce job est facile à mettre en oeuvre car il ne nécessite qu’un fragment de texte sous forme de fichier texte en entrée. Il n’y a, par exemple, pas d’appels à une base de données ou à d’autres services tiers qui pourraient compliquer l’implémentation de ce traitement.
D’autre part, le job “word count” se prête bien à l’exécution d’un job MapReduce car si on considère chaque ligne comme étant un élément d’entrée, on peut facilement paralléliser le comptage.
En entrée, on a donc un texte sous forme de fichier. Ce texte comporte un certain nombre de lignes, elles-mêmes composées de plusieurs mots. Hadoop va découper chaque ligne en blocs séparés qui donneront des entrées différentes pour les tâches Map.
Les étapes du job MapReduce sont les suivantes:
- Map: chaque tâche Map reçoit une ligne. La fonction implémentant l’étape Map va considérer les mots comme étant des clés et elle va associer la valeur
"1"à chacun des mots. On obtient donc des paires de clé/valeur avec un clé pour chaque mot et"1"étant la valeur de chaque paire.Ainsi si on considère la ligne:
“Hadoop est un outil puissant toutefois cet outil a des limites qui le rendent moins puissant”A l’issue de l’étape Map, les paires clé/valeur obtenues sont:
("Hadoop"/1), ("est"/1), ("un"/1), ("outil"/1), ("puissant"/1), ("toutefois"/1), ("cet"/1), ("outil"/1), ("a"/1), ("des"/1), ("limites"/1), ("qui"/1), ("le"/1), ("rendent"/1), ("moins"/1), ("puissant"/1)On peut remarquer que les mots
"outil"et"puissant"sont répétés et chaque occurrence donne une paire différente.Lors de l’étape de Map, on peut filtrer les valeurs, par exemple, en ne gardant que les mots de plus de 3 caractères. Après avoir filtré et mis toutes les lettres en minuscule, la liste de paires devient:
("hadoop"/1), ("outil"/1), ("puissant"/1), ("toutefois"/1), ("outil"/1), ("limites"/1), ("rendent"/1), ("moins"/1), ("puissant"/1). - Shuffle et Sort: à l’issue de cette étape, les paires sont regroupées suivant leur clé et réparties sur les différents nœuds du cluster.
Par exemple, on peut avoir la répartition:- Node 1:
("hadoop"/1), ("limites"/1), ("moins"/1), ("outil"/1), ("outil"/1). - Node 2:
("puissant"/1), ("puissant"/1), ("rendent"/1), ("toutefois"/1).
- Node 1:
- Reduce: cette étape va agréger les valeurs suivant leur clé. Cette agrégation se fait en additionnant les valeurs ayant la même clé. On obtient donc après la phase Reduce:
("hadoop"/1), ("limites"/1), ("moins"/1), ("outil"/2), ("puissant"/2), ("rendent"/1), ("toutefois"/1).
Le fichier de sortie du job contient donc la liste des mots avec le nombre d’occurrences.
Moteur de recherche
Ce job est un version simplifiée des traitements effectuées par un moteur de recherche. Elle consiste à associer un mot à des adresses URL. Lorsqu’une page est analysée, il en ressort des mots clés associés à des URL. De manière à ce que chaque mot puisse diriger vers les pages où ils apparaissent, il faut effectuer un traitement pour associer un mot à une liste d’URL.
Comme on l’a dit, l’étape d’analyse consiste à détecter des mots clés dans une page. Le résultat de ce traitement est une liste de mots avec une URL correspondant à la page où ce mot apparait.
L’exécution d’un job MapReduce permettrait d’associer un mot à une liste d’URL de façon à exploiter cette liste de paires. Les étapes du job sont:
- Map: on considère les mots comme étant des clés d’une paire mot/url. L’étape Map va consister à extraire la liste de ces paires à partir d’une opération d’analyse des pages. Cette étape permet aussi de filtrer les mots non pertinents comme les conjonctions de coordination, les verbes trop usuels etc…
A la suite de cette étape, on a donc une liste de paires mot/url, par exemple:
(mot1/url1), (mot2/url2), (mot3/url3), (mot2/url1), (mot3/url4), (mot3/url5), (mot1/url6), (mot3/url1), (mot1/url1), (mot1/url6), (mot1/url7).On remarque que cette liste contient des doublons, que certains mots dirigent vers des URL différentes ou que des mots différents dirigent vers la même URL.
- Shuffle et Sort: cette étape va consister à regrouper les paires par mot clé et à les répartir suivant les nœuds du cluster. Par exemple, on peut obtenir la répartition suivante:
- Node 1: (mot1/url1), (mot1/url6), (mot1/url1), (mot1/url6), (mot1/url7)
- Node 2: (mot2/url2), (mot2/url1), (mot3/url3), (mot3/url4), (mot3/url5), (mot3/url1)
- Reduce: cette étape consiste à agréger chaque URL au mot auquel elle est associée. Pour chaque mot, on obtient une liste d’URL. Les doublons peuvent servir à associer une pertinence aux résultats de façon à les trier. A la suite de cette étape, on obtient pour chaque mot:
- mot1: url1 (pertinence 2), url6 (pertinence 2), url7 (pertinence 1).
- mot2: url2 (pert. 1), url1 (pert. 1).
- mot3: url3 (pert. 1), url4 (pert. 1), url5 (pert. 1), url1 (pert. 1).
Ainsi quand on écrit un mot, on peut voir l’ensemble des URL qui y sont associées classées par pertinence.
Multiplication d’une matrice et d’un vecteur
Cette exemple est légèrement plus complexe car il faut savoir comment multiplier une matrice à un vecteur.
Si on considère une matrice de taille 3×3:
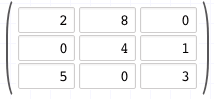
Et un vecteur de taille 3:
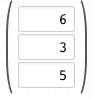
L’opération de multiplication d’une matrice et d’un vecteur consiste à additionner chaque ligne de la matrice aux valeurs du vecteur ce qui donne trois opérations. Dans notre cas:
- 1ère opération: 2*6 + 8*3 + 0*5 = 36
- 2è operation: 0*6 + 4*3 + 1*5 = 17
- 3e opération: 5*6 + 0*3 + 3*5 = 45
Le résultat de l’opération est le vecteur:

Pour effectuer ce calcul avec un job MapReduce, on va considérer un triplet (i, j, aij) avec i le numéro de ligne, j le numéro de colonne et aij la valeur. Si la valeur dans la matrice est 0, elle ne sera pas représentée.
Dans cet exemple, on effectue le calcul pour une matrice de petite taille toutefois, pour justifier l’utilisation d’un job MapReduce et pour que ce calcul soit pertinent, il faudrait une opération dont la matrice est de taille très grande qui nécessiterait plusieurs minutes de calcul.
Dans le cas de notre exemple, les opérations du job MapReduce sont:
- Map: dans un premier temps, on considère que les valeurs du vecteur sont représentables sous la forme (i, vi) et que les valeurs de la matrice sont aij (pour la valeur située à la i-ème ligne et j-ème colonne). L’opération Map consiste à extraire une paire (i, aij * vi) qui consiste à effectuer la multiplication de la valeur aij (située à la ligne i et à la colonne j de la matrice) avec la valeur du vecteur vi (située à la ligne i du vecteur).
Sachant que le résultat est un vecteur, on peut représenter le résultat de l’opération sous la forme de la paire indiquée précédemment avec i étant le numéro de ligne comme clé de la paire. La valeur étant le résultat de la multiplication aij * vi.
Il y a donc, autant de tâche Map que de multiplication à effectuer. Dans notre cas, les paires obtenues sont:
Pour la 1ère ligne (0 est l’indice de la 1ère ligne):- 1ère opération Map: (0, 2 * 6) soit (0,12)
- 2e opération Map: (0, 8 * 3) soit (0, 24)
- Il n’y a pas de 3è opération pour la 1ère ligne car la valeur du vecteur est 0.
Pour la 2e ligne (1 est l’indice de la 2e ligne):
- 3e opération Map: (1, 4 * 3) soit (1, 12). Comme précédemment à cause du 0, on passe directement au calcul de la 2è valeur de la ligne.
- 4e opération Map: (1, 1 * 5) soit (1, 5)
Pour la 3e ligne (2 est l’indice de la 2e ligne):
- 5e opération Map: (2, 5 * 6) soit (2, 30)
- 6e opération Map: (2, 3 * 5) soit (2, 15)
A l’issue de toutes les opérations Map, on obtient la liste de paires: (0,12), (0, 24), (1, 12), (1, 5), (2, 30) et (2, 15).
Cette liste est indiquée de façon ordonnée toutefois dans la réalité elle n’est pas ordonnée car les opérations Map se font de façon parallèle et les résultats ne sont pas forcément ordonnancés de cette façon. - Shuffle et Sort: cette étape va ordonner les paires suivant leur clé et répartir équitablement les paires sur les nœuds. On pourrait avoir une répartition de cette façon:
- Node 1: (0,12), (0, 24), (1, 12), (1, 5)
- Node 2: (2, 30) et (2, 15)
- Reduce: cette étape va permettre d’agréger toutes les valeurs suivant leur clé. On aura donc la liste de valeurs:
- (0, [12, 24])
- (1, [12, 5])
- (2, [30, 15])
En additionnant les valeurs agrégées, on obtient la liste: (0, 36), (1, 17) et (2, 45). Sachant que les clés correspondent à l’indice de ligne du vecteur, on a bien le résultat de la multiplication:
En conclusion
Le but de cet article était d’expliquer l’architecture d’Hadoop et le fonctionnement d’un job MapReduce. Il n’est pas rentré dans le détail de l’implémentation d’un mapper ou d’un reducer car ces composants feront l’objet d’un article futur sur le sujet. Cet article sert de base théorique de façon à aborder un job MapReduce de façon plus approfondie par la suite.
- Welcome to Apache Hadoop: http://hadoop.apache.org/
- HDFS Architecture Guide: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
- MapReduce Tutorial: http://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
- Stackoverflow: What is the purpose of shuffling and sorting phase in the reducer in Map Reduce Programming?: https://stackoverflow.com/questions/22141631/what-is-the-purpose-of-shuffling-and-sorting-phase-in-the-reducer-in-map-reduce
- Module 1: Tutorial Introduction: https://developer.yahoo.com/hadoop/tutorial/module1.html
- Module 2: The Hadoop Distributed File System:
- Module 4: MapReduce: https://developer.yahoo.com/hadoop/tutorial/module4.html
- MapReduce, premiers pas: http://b3d.bdpedia.fr/mapreduce.html
- Parcourez les principaux algorithmes MapReduce: https://openclassrooms.com/courses/realisez-des-calculs-distribues-sur-des-donnees-massives/parcourez-les-principaux-algorithmes-mapreduce
- Comprendre mapReduce: http://blog.soat.fr/2015/05/comprendre-mapreduce/
- Généralités sur HDFS et MapReduce: http://mbaron.developpez.com/tutoriels/bigdata/hadoop/introduction-hdfs-map-reduce/