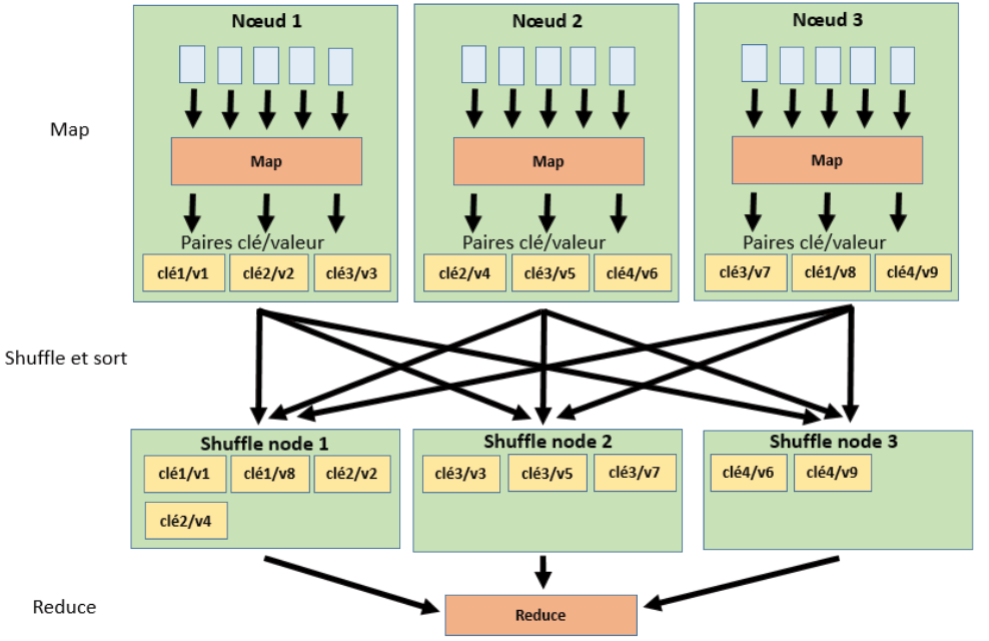
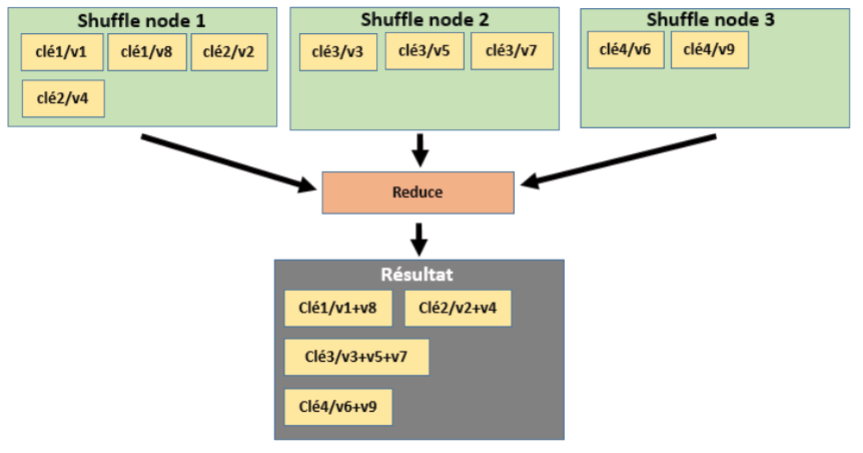
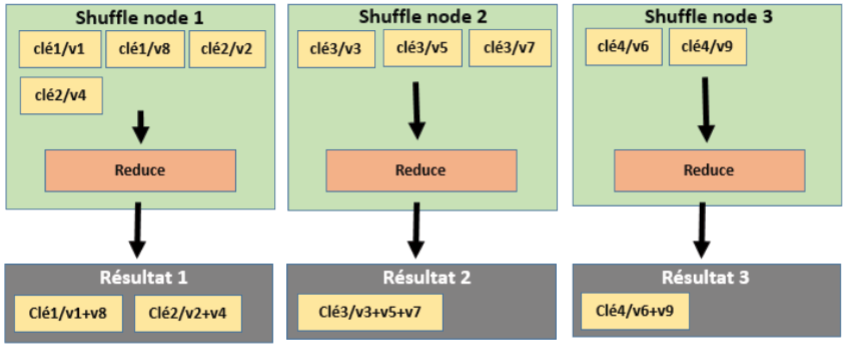
Cet article indique comment configurer un cluster Hadoop à partir d’une configuration en mode pseudo-distribué. Dans un article précédent, on avait expliqué comment installer Hadoop sur Debian GNU/Linux. A la suite de cette installation, le cluster Hadoop ne comportait qu’un seul nœud (i.e. single node cluster) et les jobs MapReduce s’exécutaient de façon pseudo distribuée. De façon à utiliser plus de fonctionnalités d’Hadoop, on va modifier la configuration pour permettre d’exécuter les jobs de façon distribuée.
Dans des articles précédents, on avait expliqué comment installer Debian sur une machine virtuelle VirtualBox pour exploiter la flexibilité des machines virtuelles (VM). On va donc, dans un premier temps, modifier la configuration du nœud qui s’exécutait en mode pseudo distribué pour qu’il soit le name node du cluster. Ensuite, on va dupliquer la machine virtuelle dans laquelle se trouve ce nœud pour créer d’autres nœuds qui seront les data nodes du cluster.
1. Dupliquer les machines virtuelles
2. Configurer le “name node”
Configurer l’alias réseau
Configurer core-site.xml
Configurer hdfs-site.xml
Configurer mapred-site.xml
Configurer yarn-site.xml
Configuration du “master” et des “slaves”
Formattage du système de fichiers HDFS
3. Configurer les “data nodes”
Configuration des alias réseau
Configuration SSH des “data nodes”
Copie de la configuration sur les “data nodes”
Suppression des répertoires de travail Hadoop sur les “data nodes”
Suppression de GNOME sur les “data nodes” (facultatif)
4. Exécuter Hadoop et YARN
Démarrage de Hadoop et YARN
Tester l’exécution
Stopper l’exécution de YARN et Hadoop
Erreur “container is running beyond physical memory limits”
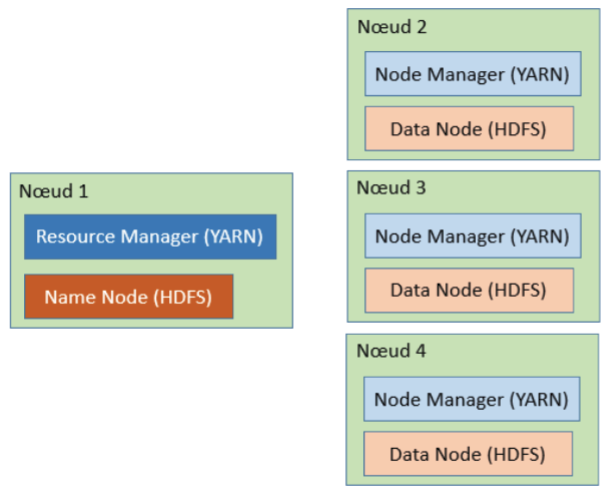
Pour qu’on puisse étudier le fonctionnement d’Hadoop et que le cluster s’exécute en distribuant l’exécution d’un job sur plusieurs nœuds, il faut au moins 2 data nodes (même si un data node suffit à l’exécution). Pour coordonner l’exécution du job, il faut aussi un name node. Il faudra, donc, exécuter simultanément 3 machines virtuelles:
- 1 machine virtuelle pour le name node
- 2 machines virtuelles pour les 2 data nodes.
La mise en place de cet environnement va donc consommer beaucoup de mémoire, il faut une machine avec au moins de 12 Go de RAM et quad-core pour permettre aux 3 instances Debian de fonctionner. Ensuite, pour que l’exécution du job soit distribuée à travers le réseau, il faut un routeur et que les machines virtuelles aient des adresses IP différentes pour que les nœuds du cluster puissent communiquer entre eux.
1. Dupliquer les machines virtuelles
La première étape consiste à dupliquer le nœud qu’on avait déjà configuré en mode pseudo-distribué. Mais avant d’effectuer la duplication, on va modifier la configuration pour que chaque machine virtuelle utilise moins de ressources et puisse avoir des adresses IP différentes.
Le système Debian qui se trouve sur la machine virtuelle, doit être arrété en exécutant, par exemple, halt à la ligne de commandes en tant qu’utilisateur root. On peut alors modifier la configuration de la machine virtuelle (VM) dans VirtualBox en faisant un clique droit sur la VM puis en cliquant sur “Configuration”:
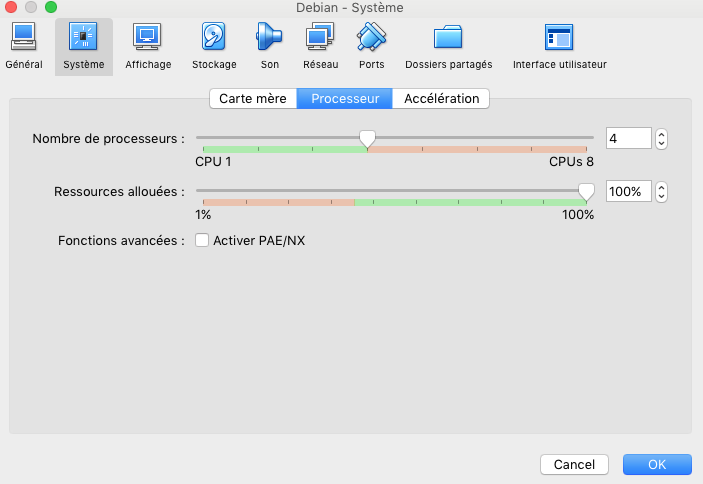
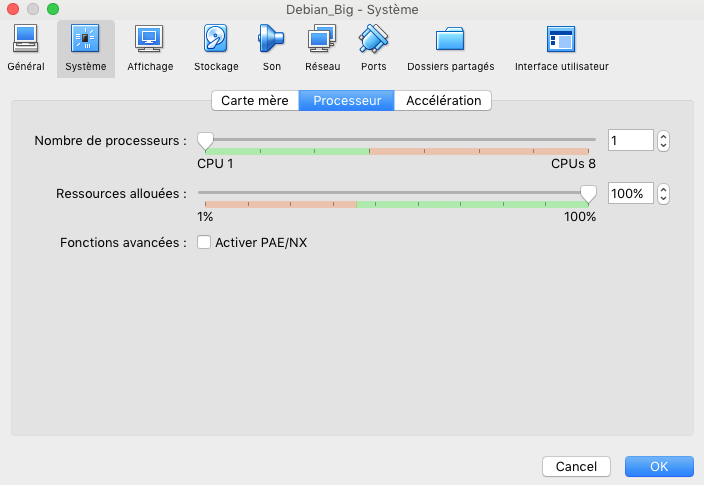
- On peut limiter à un 1 seul processeur en allant dans l’onglet “Système” puis “Processeur”:
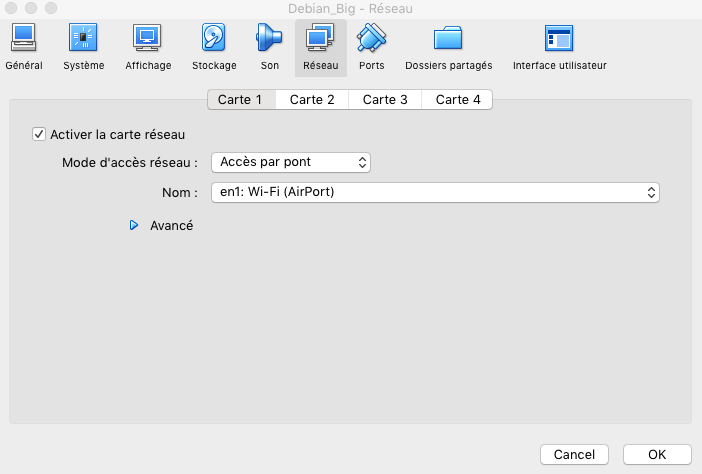
- Modifier la configuration réseau en allant dans l’onglet “Réseau”, en sélectionnant pour la configuration “Mode d’accès réseau” en “Accès par pont”. Ce paramétrage va permettre d’affecter une adresse IP différente pour chaque VM.
- On peut renommer cette machine “NameNode” en allant dans l’onglet “Général”.
La VM peut être dupliquée en faisant un clique droit puis en cliquant sur “Cloner”. Ensuite il faut cliquer sur “Mode expert” et sélectionner les paramètres suivants:
- Type de clone: “Clone intégral”
- Instantanés: “Etat actuel de la machine”
- Cocher “Réinitialiser l’adresse MAC de toutes les cartes réseau” pour affecter une adresse MAC différente.
- Nommer la VM, par exemple en “DataNode1”
- Cliquer ensuite sur “Cloner”.
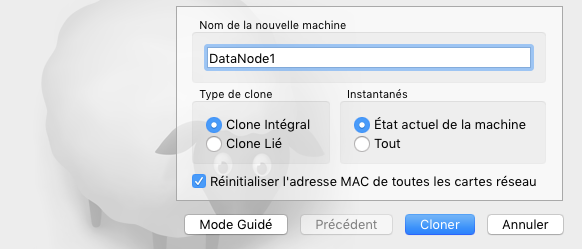
Il faut ensuite refaire l’opération pour le 2e nœud en nommant la VM “DataNode2”.
A ce stade, on a 3 machines virtuelles: “NameNode”, “DataNode1” et “DataNode2”.
2. Configurer le “name node”
On peut démarrer la VM nommée “NameNode” en cliquant sur “Démarrer”.
Sachant qu’on a commencé avec la VM utilisée après la configuration en mode pseudo distribué à la suite de l’article Installation d’Hadoop sur Debian, certaines étapes ont déjà été effectuées:
- Java et Hadoop sont installés. Hadoop se trouve dans le répertoire
/usr/hadoop/hadoop-2.8.1. - L’utilisateur qui peut exécuter Hadoop est “hduser”.
- Les variables d’environnement
JAVA_HOMEetHADOOP_HOMEsont paramétrées et le répertoire d’Hadoop se trouve dans la variablePATH(cf. Execution de jobs localement) - La configuration SSH est effectuée et la clé
/home/hduser/.ssh/id_rsa.pubest autorisée car elle a été copiée dans/home/hduser/authorized_keys(cf. Configuration SSH).
Configurer l’alias réseau
Il faut d’abord obtenir l’adresse de la VM en exécutant:
root@NameNode:~% ip addr show
Dans mon cas, l’adresse IP est 192.168.1.34.
On édite le fichier /etc/hostname en tant qu’utilisateur root (pour se connecter en tant qu’utilsateur root, il faut taper su sur un terminal):
root@NameNode:~% vi /etc/hostname
On remplace le nom avec le nom “NameNode” (appuyer sur [i] pour passer en mode édition et après avoir effectué le remplacement; pour enregistrer, appuyer sur [Echap] puis taper :wq).
Ensuite il faut éditer le fichier /etc/hosts en tant qu’utilisateur root:
root@NameNode:~% vi /etc/hosts
On doit commenter toutes les lignes présentes en les précédant du caractère “#” et ajouter la ligne suivante (en remplaçant l’adresse IP avec l’adresse trouvée précédemment):
192.168.1.34 NameNode
Dans mon cas, le fichier se présente de cette façon:
#127.0.0.1 localhost
192.168.1.34 NameNode
On peut redémarrer en exécutant:
root@NameNode:~% reboot
Configurer core-site.xml
Ce fichier doit être édité en tant qu’utilisateur “hduser”:
hduser@NameNode:~% vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/core-site.xml
Le fichier doit se présenter de cette façon:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://NameNode:8020</value>
<description>The name of the default file system.</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hduser/hadoop_data/hd-data/tmp</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/home/hduser/hadoop_data/hd-data/snn</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hduser/hadoop_data/hd-data/dn</value>
</property>
</configuration>
Dans sa configuration précédente, la valeur de fs.defaultFS était hdfs://localhost:9000. Cette valeur a été remplacée puisque l’alias réseau a été modifié.
Configurer hdfs-site.xml
On édite hdfs-site.xml en tant qu’utilisateur “hduser” de cette façon:
hduser@NameNode:~% vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/hdfs-site.xml
Le fichier doit se présenter de cette façon:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hduser/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hduser/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/home/hduser/hadoop_data/hdfs/namesecondary</value>
</property>
</configuration>
Par rapport à la configuration précédente, on a augmenté le paramètre dfs.replication à 2 car on veut configurer 2 data nodes (c’est le facteur de réplication de HDFS) et on a précisé des répertoires de données pour le name node.
Configurer mapred-site.xml
On configure mapred-site.xml en tant qu’utilisateur “hduser”:
hduser@NameNode:~% vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/mapred-site.xml
Le fichier doit se présenter de cette façon:
<configuration>
<property>
<value>yarn</value>
<name>mapreduce.framework.name</name>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>NameNode:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>NameNode:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user/app</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Djava.security.egd=file:/dev/../dev/urandom</value>
</property>
</configuration>
Par rapport à la configuration précédente, on a modifié la valeur du paramètre mapreduce.framework.name en la passant à yarn. Précédemment cette valeur était à local car on exécutait les jobs en mode pseudo-distribué sur un seul nœud. Maintenant YARN doit utiliser les autres nœuds pour l’exécution.
D’autres paramètres ont été rajoutés:
mapreduce.jobhistory.address: on indique l’adresse du serveur MapReduce JobHistory.mapreduce.jobhistory.webapp.address: on précise l’adresse web du serveur MapReduce JobHistory.mapred.child.java.opts: ce paramètre permet de rajouter une option au lancement du processus java. Cette option vise à éviter les retards de la JVM dus à la génération de nombres aléatoires. L’attente préalable permettant la génération de “bruit” avant de générer un nombre aléatoire peut bloquer l’exécution du serveur WebLogic SIP utilisé pour exécuter des processus scalables.
Configurer yarn-site.xml
On édite ce fichier en tapant:
hduser@NameNode:~% vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/yarn-site.xml
Ce fichier doit se présenter de cette façon:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>NameNode</value>
</property>
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:/home/hduser/hadoop_data/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:/home/hduser/hadoop_data/yarn/log</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>hdfs://NameNode:8020/var/log/hadoop-yarn/apps</value>
</property>
</configuration>
Le détail des éléments de configuration est:
yarn.nodemanager.aux-services: on indique le nom du service auxiliaire YARN.yarn.resourcemanager.hostname: on indique le nom réseau du resource manager de YARN.yarn.resourcemanager.bind-host: permet au resource manager d’écouter toutes les interfaces vers lesquelles le serveur RPC et le serveur webapp vont se connecter.yarn.nodemanager.bind-host: ce paramètre est similaire au précédent mais concerne le node manager.yarn.nodemanager.aux-services.mapreduce_shuffle.class: classe Java utilisée pour effectuer l’étape shuffle. Il s’agit de la valeur par défaut.yarn.log-aggregation-enable: on indique qu’on veut activer l’agrégation de logs. Les logs peuvent ainsi être agrégés de façon centrale dans HDFS et non sur le disque de tous les nœuds.yarn.nodemanager.local-dirsetyarn.nodemanager.log-dirs: permettent de préciser des répertoires pour stocker respectivement des données et de logs.yarn.nodemanager.remote-app-log-dir: répertoire dans lequel les logs des node managers seront agrégés. Ce répertoire se trouve dans HDFS.
Configuration du “master” et des “slaves”
On va ensuite indiquer le nom réseau des machines qui seront le name node et les data nodes. On n’a pas encore configuré le nom des alias des data nodes toutefois le nom sera “DataNode1” et “DataNode2”.
On précise l’alias du “NameNode” en éditant le fichier masters:
hduser@NameNode:~% vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/masters
On y ajoute seulement le nom du name node:
NameNode
Ensuite on édite le fichier slaves pour indiquer les alias des data nodes:
hduser@NameNode:~% vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/slaves
Le fichier doit contenir les 2 lignes suivantes:
DataNode1
DataNode2
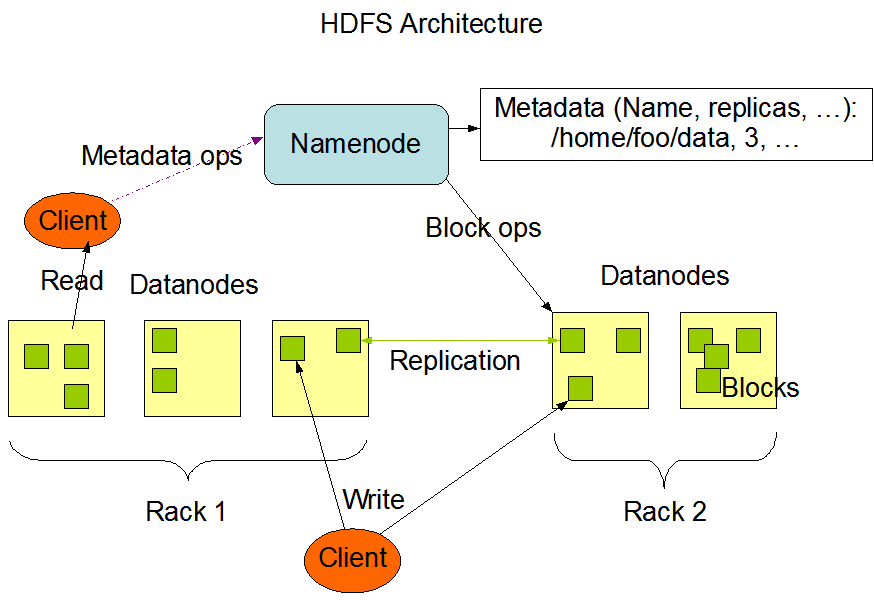
Formattage du système de fichiers HDFS
Sachant que le nœud a déjà servi pour des exécutions en mode pseuso-distribué et que la configuration a changé, il faut formatter le système de fichiers HDFS.
Au préalable, pour éviter les erreurs on peut supprimer le contenu des répertoires de travail de HDFS et de MapReduce en exécutant en tant qu’utilisateur “hduser”:
hduser@NameNode:~% rm –r /home/hduser/hadoop_data/hd-data
hduser@NameNode:~% rm –r /home/hduser/hadoop_data/hdfs
hduser@NameNode:~% rm –r /home/hduser/hadoop_data/yarn
On peut, ensuite, formatter en exécutant:
hduser@NameNode:~% /usr/hadoop/hadoop-2.8.1/bin/hdfs namenode -format
3. Configurer les “data nodes”
Les data nodes doivent, maintenant être configurés. Sachant que ces VM sont issues de duplication de la première VM, tous les éléments nécessaires sont déjà installés. De même, une bonne partie de la configuration a déjà été effectuée. Il y aura juste quelques éléments à modifier.
On peut maintenant démarrer les 2 VM correspondant aux data nodes: la VM “DataNode1” et la VM “DataNode2”.
Configuration des alias réseau
Avant tout, on récupére les adresses IP des 2 VM en exécutant sur les 2 machines la commande suivante:
hduser#DataNode1:% ip addr show
Et sur l’autre VM:
hduser@DataNode2:~% ip addr show
Dans mon cas, j’ai les adresses suivantes:
- DataNode1: 192.168.1.98
- DataNode2: 192.168.1.50
On indique ensuite le nom réseau pour chaque machine en éditant le fichier /etc/hostname en tant qu’utilisateur root:
root@DataNode1:~% vi /etc/hostname
Le fichier ne doit contenir que:
DataNode1
De même pour la VM DataNode2:
root@DataNode2:~% vi /etc/hostname
Le fichier doit contenir:
DataNode2
On édite ensuite le fichier /etc/hosts pour indiquer les adresses IP des autres nœuds:
root@DataNode1:~% vi /etc/hosts
Il faut commenter les autres lignes existantes, ce fichier doit contenir les lignes suivantes (il faut remplacer les adresses IP par celles obtenues précédemment):
192.168.1.34 NameNode
192.168.1.89 DataNode1
192.168.1.50 DataNode2
On effectue la même opération sur la VM DataNode2:
root@DataNode2:~% vi /etc/hosts
Il ne faut pas oublier de répercuter ces modifications aussi dans le name node. On édite donc aussi le fichier /etc/hosts sur la VM “NameNode”:
root@NameNode:~% vi /etc/hosts
Le fichier doit avoir le même contenu que les autres nœuds:
192.168.1.34 NameNode
192.168.1.89 DataNode1
192.168.1.50 DataNode2
Il faut redémarrer les VM après cette étape surtout les VM des data nodes “DataNode1” et “DataNode2”.
Configuration SSH des “data nodes”
Sachant que les VM des data nodes sont des clones du name node, la configuration SSH est déjà effectuée. Normalement, il n’y a rien à faire toutefois on précise quelle doit être cette configuration.
La configuration SSH consiste à autoriser le name node à se connecter aux data nodes par connexion SSH. Pour autoriser cette connexion, il faut copier la clé publique du name node dans la liste des clés autorisées dans les data nodes.
La clé publique du name node se trouve dans: /home/hduser/.ssh/id_rsa.pub. Si on regarde son contenu:
hduser@NameNode:~% cat /home/hduser/.ssh/id_rsa.pub
ssh-rsa AAAAA......p610nf hduser@debianvm
La clé doit être copiée dans le répertoire /home/hduser/.ssh/authorized_keys des 2 data nodes.
On édite ensuite la clé dans la VM “DataNode1” dans /home/hduser/.ssh/authorized_keys pour remplacer hduser@debianvm par hduser@NameNode. La clé doit se présenter de cette façon:
hduser@DataNode1:~% cat /home/hduser/.ssh/id_rsa.pub
ssh-rsa AAAAA......p610nf hduser@NameNode
Il faut faire la même modification dans la VM “DataNode2”:
hduser@DataNode2:~% cat /home/hduser/.ssh/id_rsa.pub
ssh-rsa AAAAA......p610nf hduser@NameNode
Maintenant l’utilisateur “hduser” du name node peut se connecter sur les 2 data nodes. On peut le vérifier en allant sur le name node et en se connectant sur un terminal en tant qu’utilisateur “hduser”. Si on tape:
hduser@NameNode:~% ssh DataNode1
On accède directement au DataNode1.
De même, on doit pouvoir se connecter directement sur le DataNode2 en exécutant:
hduser@NameNode:~% ssh DataNode2
Copie de la configuration sur les “data nodes”
A la suite de la configuration SSH, il faut copier toute la configuration d’Hadoop du name node dans les data nodes en s’aidant de scp.
On se connecte donc, en tant qu’utilisateur “hduser” dans le name node et on exécute les commandes suivantes:
hduser@NameNode:~% cd /usr/hadoop/hadoop-2.8.1/etc
hduser@NameNode:~% scp –r hadoop DataNode1:/usr/hadoop/hadoop-2.8.1/etc
hduser@NameNode:~% scp –r hadoop DataNode2:/usr/hadoop/hadoop-2.8.1/etc
Après cette étape la configuration est dupliquée dans les 2 data nodes.
Suppression des répertoires de travail Hadoop sur les “data nodes”
Sachant que les data nodes proviennent de duplications de machine virtuelle et pour éviter des erreurs, il est préférable de supprimer le contenu des répertoires de travail d’Hadoop en exécutant sur les 2 data nodes les commandes suivantes:
hduser@DataNode1:~% rm –r /home/hduser/hadoop_data/hd-data
hduser@DataNode1:~% rm –r /home/hduser/hadoop_data/hdfs
hduser@DataNode1:~% rm –r /home/hduser/hadoop_data/yarn
Puis sur l’autre data node:
hduser@DataNode2:~% rm –r /home/hduser/hadoop_data/hd-data
hduser@DataNode2:~% rm –r /home/hduser/hadoop_data/hdfs
hduser@DataNode2:~% rm –r /home/hduser/hadoop_data/yarn
Suppression de GNOME sur les “data nodes” (facultatif)
Cette étape vise seulement à diminuer la quantité de mémoire utilisée par la VM. Elle n’est pas indispensable.
Elle consiste à désinstaller GNOME sur les data nodes en exécutant en tant qu’utilisateur root sur chaque data node, la commande suivante:
root@DataNode1:~% apt-get purge gnome-shell
De même sur l’autre data node:
root@DataNode2:~% apt-get purge gnome-shell
Il faut redémarrer les 2 data nodes après cette étape.
4. Exécuter Hadoop et YARN
Démarrage de Hadoop et YARN
Après toutes ces étapes, Hadoop peut être démarré en exécutant sur le name node en tant qu’utilisateur “hduser”, les commandes suivantes:
hduser@NameNode:~% start-dfs.sh
Puis:
hduser@NameNode:~% start-yarn.sh
Si le démarrage s’effectue correctement, il n’y a pas d’erreurs dans les logs. On peut voir les logs du name node en exécutant la commande suivante:
hduser@NameNode:~% less /usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-namenode-NameNode.log
Les erreurs sont indiquées avec le niveau ERROR.
On peut aussi regarder les logs des data nodes:
hduser@DataNode1:~% less /usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-datanode-DataNode1.log
Et sur l’autre data node:
hduser@DataNode2:~% less /usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-datanode-DataNode2.log
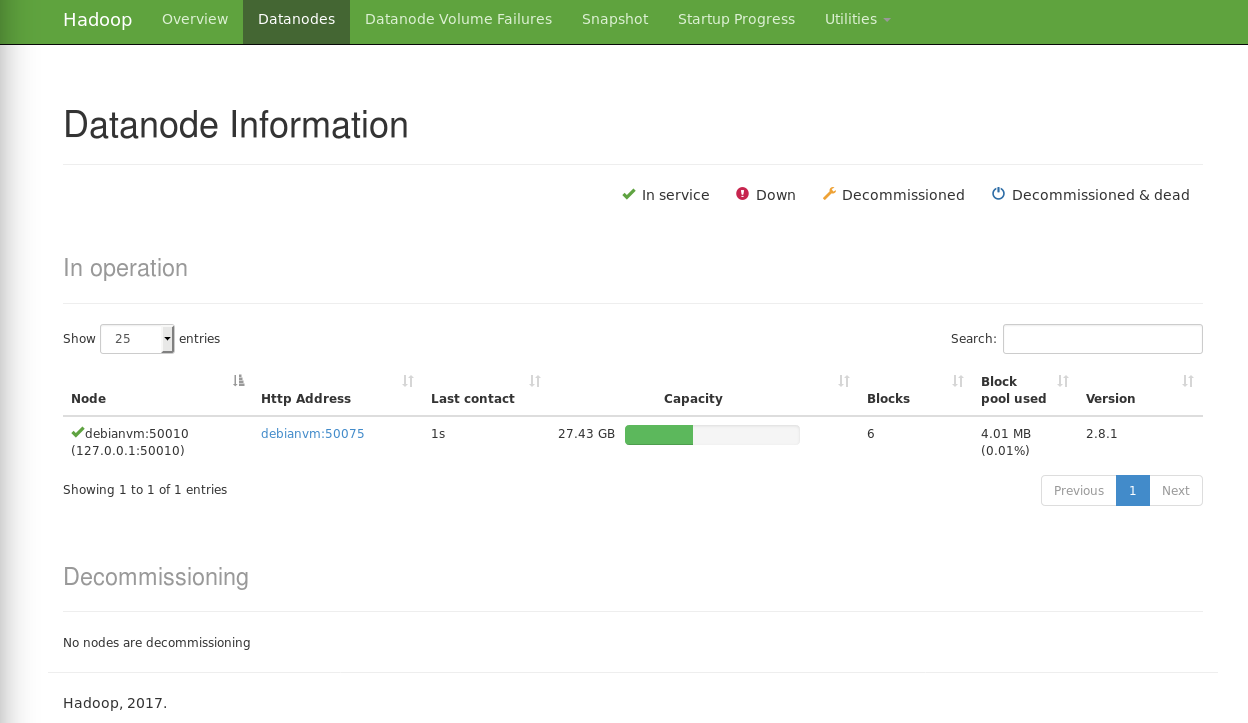
Pour vérifier si tout a démarré normalement, on peut taper sur le name node:
hduser@NameNode:~% hdfs dfsadmin –report
Normalement le résultat devrait indiquer la présence des 2 data nodes:
Live datanodes (2):
Name: 192.168.1.50:50010 (DataNode2)
Hostname: DataNode2
Decommission Status : Normal
Configured Capacity: 29455585280 (27.43 GB)
DFS Used: 114630656 (109.32 MB)
Non DFS Used: 12166201344 (11.33 GB)
DFS Remaining: 15654895616 (14.58 GB)
DFS Used%: 0.39%
DFS Remaining%: 53.15%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sat Oct 28 12:59:19 CEST 2017
Name: 192.168.1.98:50010 (DataNode1)
Hostname: DataNode1
Decommission Status : Normal
Configured Capacity: 29455585280 (27.43 GB)
DFS Used: 114630656 (109.32 MB)
Non DFS Used: 12171759616 (11.34 GB)
DFS Remaining: 15649337344 (14.57 GB)
DFS Used%: 0.39%
DFS Remaining%: 53.13%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sat Oct 28 12:59:19 CEST 2017
Tester l’exécution
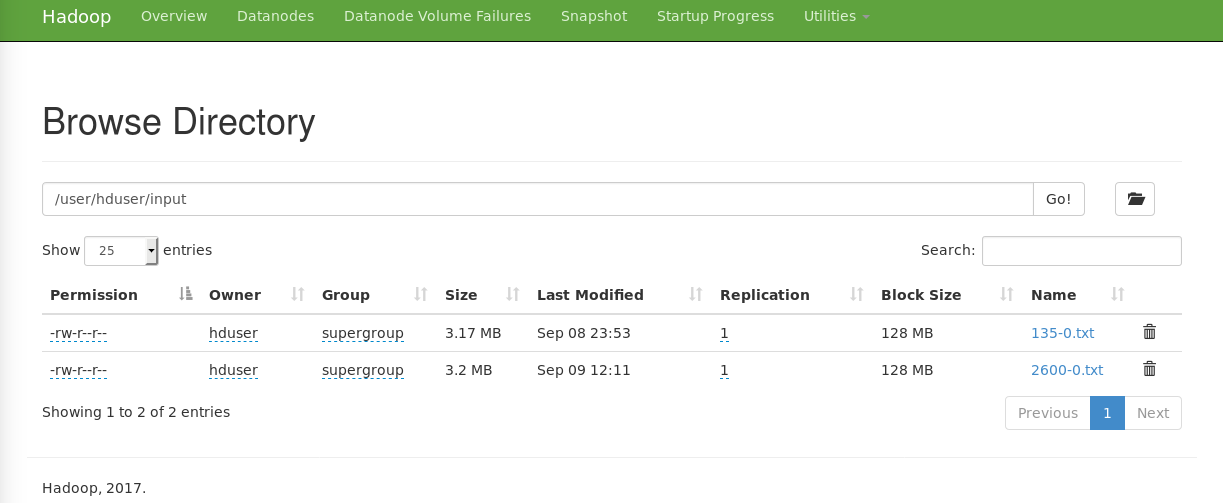
On peut tester l’exécution avec le job Wordcount, par exemple avec le fichier:
http://www.gutenberg.org/files/2600/2600-0.txt
Ce fichier doit être copié dans HDFS en écrivant:
hduser@NameNode:~% hdfs dfs -mkdir /user
hduser@NameNode:~% hdfs dfs -mkdir /user/hduser
hduser@NameNode:~% hdfs dfs -mkdir /user/hduser/input
hduser@NameNode:~% hdfs dfs -put 2600-0.txt /user/hduser/input
On peut lancer le job en écrivant:
hduser@NameNode:~% hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /user/hduser/input/2600-0.txt output
En cas de succès, le résultat devrait indiquer:
Job job_XXXX completed successfully
Stopper l’exécution de YARN et Hadoop
Pour stopper l’exécution, on exécute les commandes suivantes sur le name node:
hduser@NameNode:~% stop-dfs.sh
Puis:
hduser@NameNode:~% stop-yarn.sh
Erreur “container is running beyond physical memory limits”
Cette erreur peut se produire lors de l’exécution d’un job MapReduce en particulier avec la version 1.8 de Java.
Ainsi lors de l’exécution des jobs Map, une erreur survient avec le message:
"Container [pid=XXXX,containerID=XXXXX] is running beyond physical memory limits. Current usage: 1.0 GB of 1 GB physical memory used; 2.7 GB of 2.1 GB virtual memory used. Killing container."
Cette erreur empêche au job d’aboutir. La correction de ce problème consiste à limiter la mémoire utilisée par un job en ajoutant certains paramètres dans les fichiers de configuration.
Il faut stopper l’exécution de YARN et Hadoop avant d’éditer les fichiers.
En commançant par le name node:
hduser@NameNode:~% vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/mapred-site.xml
On ajoute les éléments de configuration suivants qui vont limiter la quantité de mémoire utilisée à 2 Go (la taille est indiquée en Mo):
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.map.java.opts.max.heap</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.java.opts.max.heap</name>
<value>2048</value>
</property>
Ensuite on édite le fichier yarn-site.xml en exécutant:
hduser@NameNode:~% vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/yarn-site.xml
On ajoute le paramètre suivant:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
Ces fichiers doivent être copiés sur les data nodes en exécutant les lignes suivantes:
hduser@NameNode:~% cd /usr/hadoop/hadoop-2.8.1/etc
hduser@NameNode:~% scp –r hadoop DataNode1:/usr/hadoop/hadoop-2.8.1/etc
hduser@NameNode:~% scp –r hadoop DataNode2:/usr/hadoop/hadoop-2.8.1/etc
On peut ensuite démarrer Hadoop et YARN et effectuer un nouveau test d’exécution.