Cet article explique l’installation de Hadoop sur Debian GNU/linux 9. La version d’Hadoop utilisée est celle téléchargeable directement du site d’Apache.
L’intérêt d’utiliser Debian est que beaucoup d’outils sont disponibles sur cette distribution et qu’elle est gratuite.
Dans cet article, on détaille l’installation d’Hadoop et de YARN ainsi que la configuration d’un cluster en single-node.
Une version de Debian installée sur une machine virtuelle est une configuration très flexible pour essayer Hadoop sans polluer son système d’exploitation hôte. L’installation de Debian sur VirtualBox est facile à réaliser (cf. Installation de Debian sur une machine virtuelle VirtualBox). Toutefois cette étape n’est pas obligatoire car il est possible d’installer Hadoop directement sur plusieurs types de système d’exploitation.
1. Installation JDK
3. Préparation de l’installation d’Hadoop
Installation SSH
Configuration SSH
4. Configuration d’Hadoop en single node cluster
Configuration d’Hadoop
Configuration du cluster en mode pseudo-distribué
Changement des droits sur le répertoire d’Hadoop
Execution de jobs localement
Erreur “Connection refused”
5. YARN
Configuration de YARN
Exécution de YARN
6. Execution d’un job MapReduce
7. Stopper l’exécution de YARN et Hadoop
1. Installation JDK
Avant d’installer Hadoop, il faut installer Java si ce n’est pas déjà fait.
On peut télécharger la JDK sur le site d’Oracle: http://www.oracle.com/technetwork/java/javase/downloads/index.html.
La version utilisée était la jdk1.8.0_144 pour linux en 64 bits.
On peut installer la JDK sur le disque en exécutant:
tar zxvf jdk-8u144-linux-x64.tar.gz
Cette commande permet d’extraire les fichiers contenus dans l’archive en listant tous les fichiers extraits.
En tant qu’utilisateur root, placer le répertoire résultant dans /usr/java. Pour passer en tant qu’utilisateur root, il faut taper:
su
Puis pour copier le répertoire:
mkdir /usr/java
mv <nom du répertoire> /usr/java
2. Télécharger Hadoop sur le site d’Apache
On peut télécharger Hadoop sur le site d’Apache: http://hadoop.apache.org/.
La version à installer est la dernière version stable sur http://hadoop.apache.org/releases.html.
Dans notre cas la version était la 2.8.1.
Il faut extraire l’archive et la placer dans /etc/hadoop:
tar zxvf hadoop-2.8.1.tar.gz
Et:
mkdir /etc/hadoop
mv <nom du répertoire> /usr/hadoop
3. Préparation de l’installation d’Hadoop
Création d’un groupe et d’un utilisateur Hadoop
Cette étape n’est pas indispensable mais permet de séparer les permissions. Cet utilisateur sera spécifique à Hadoop.
Pour créer le groupe “hadoop” et l’utilisateur “hduser”, il faut exécuter en tant qu’utilisateur root (taper su pour switcher vers l’utilisateur root):
addgroup hadoop
adduser --ingroup hadoop hduser
On peut ensuite se connecter avec cet utilisateur en écrivant:
su hduser
Installation SSH
Il faut installer SSH en tapant en tant qu’utilisateur root:
apt-get install ssh
Il faut aussi installer rsync qui permet des synchronisations de fichiers à distance en utilisant SSH. L’installation se fait en écrivant:
apt-get install rsync
Configuration SSH
L’utilisation d’Hadoop se fait par l’intermédiaire d’une connexion SSH même si Hadoop est exécuté localement. Il faut autoriser l’utilisateur “hduser” à se connecter en SSH sur la machine en créant une clé et en autorisant cette clé sur la machine.
La création de la clé se fait en exécutant les commandes suivantes. Il faut être connecté en tant qu’utilisateur “hduser”:
ssh-keygen -t rsa -P ""
L’option -t indique qu’on souhaite créer une clé de type rsa. L’option -P sert à indiquer une passphrase qui dans ce cas est vide.
La clé est rangée dans le répertoire /home/hduser/.ssh/id_rsa.pub.
Il faut ajouter cette clé aux clef autorisées pour les connexions SSH en exécutant:
cat /home/hduser/.ssh/id_rsa.pub >> /home/hduser/authorized_keys
Cette commande va rajouter le contenu de id_rsa.pub dans le fichier authorized_keys en le créant s’il n’existe pas.
On peut ensuite tester l’accès en SSH en écrivant:
ssh localhost
Il faut ensuite accepter la connexion en écrivant “yes”. L’accès doit se faire sans passphrase puisqu’on a indiqué une passphrase vide plus haut.
On peut sortir de la connexion SSH en écrivant:
exit
4. Configuration d’Hadoop en single-node cluster
L’installation peut se faire en suivant les instructions sur: Hadoop: Setting up a Single Node Cluster.
Cette installation permet de configurer Hadoop pour que le cluster ne soit former que d’un seul nœud.
Configuration d’Hadoop
Dans un premier temps, il faut configurer le chemin de la JDK dans le fichier de configuration d’Hadoop hadoop-env.sh. Ce fichier se trouve dans /usr/hadoop/hadoop-2.8.1/etc/hadoop/hadoop-env.sh. On peut l’éditer en tant qu’utilisateur root et en remplaçant:
export JAVA_HOME=${JAVA_HOME}
par:
export JAVA_HOME=/usr/java/jdk1.8.0_144/
On peut ensuite exécuter Hadoop en tapant:
/usr/hadoop/hadoop-2.8.1/bin/hadoop
L’exécution devrait afficher l’aide concernant Hadoop:
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
credential interact with credential providers
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.
Configuration du cluster en mode pseudo-distribué
Cette configuration correspond à la partie “Pseudo-Distributed operation”. Elle permet de configurer le cluster en mode pseudo-distribué (puisqu’il n’y a qu’une seule machine).
Il faut éditer le fichier core-site.xml dans le répertoire: /usr/hadoop/hadoop-2.8.1/etc/hadoop/core-site.xml en ajoutant:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Cette configuration permet d’indiquer que le nom du système de fichier est fs.defaultFS et que les répertoires et fichiers dans HDFS sont préfixés avec: hdfs://localhost:9000.
On édite ensuite le fichier qui se trouve dans: /usr/hadoop/hadoop-2.8.1/etc/hadoop/hdfs-site.xml et on ajoute les éléments suivants:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Cette configuration permet d’indiquer le nombre de réplication d’un bloc qui sera de 1 car il n’y a qu’un seul nœud dans le cluster.
Changement des droits sur le répertoire d’Hadoop
Pour permettre l’exécution d’Hadoop par l’utilisateur “hduser”, il faut changer les droits sur le répertoire d’Hadoop en tapant:
chown -R hduser:hadoop /usr/hadoop/hadoop-2.8.1
Execution de jobs localement
En se connectant en tant qu’utilisateur “hduser” (en tapant su hduser), on peut formater le système de fichiers de HDFS en tapant:
/usr/hadoop/hadoop-2.8.1/bin/hdfs namenode -format
On peut créer le répertoire qui va contenir les logs lors de l’exécution en écrivant:
mkdir /usr/hadoop/hadoop-2.8.1/logs
On peut paramétrer les variables d’environnement pour ajouter aux chemins le répertoire d’Hadoop. Il faut éditer le fichier /home/hduser/.bashrc en ajoutant:
export JAVA_HOME=/usr/java/jdk1.8.0_144/
export HADOOP_HOME=/usr/hadoop/hadoop-2.8.1/
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
Pour prendre en compte les modifications des variables d’environnement, on peut redémarrer sa session de terminal.
On peut démarrer ensuite le daemon du NameNode et du datanode en exécutant:
start-dfs.sh
Sachant que le répertoire contenant ce fichier a été rajouté dans la variable d’environnement PATH, on peut exécuter cette action de n’importe où. Toutefois si ce n’est pas le cas, ce fichier se trouve dans /usr/hadoop/hadoop-2.8.1/sbin/start-dfs.sh.
Les logs correspondant à cette action sont dans:
/usr/hadoop/hadoop-2.8.1/logs
L’exécution devrait indiquer:
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-namenode-debianvm.out
localhost: starting datanode, logging to /usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-datanode-debianvm.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-secondarynamenode-debianvm.out
On peut se connecter à l’interface web du NameNode à l’adresse:
http://localhost:50070/
On devrait voir une interface du type:
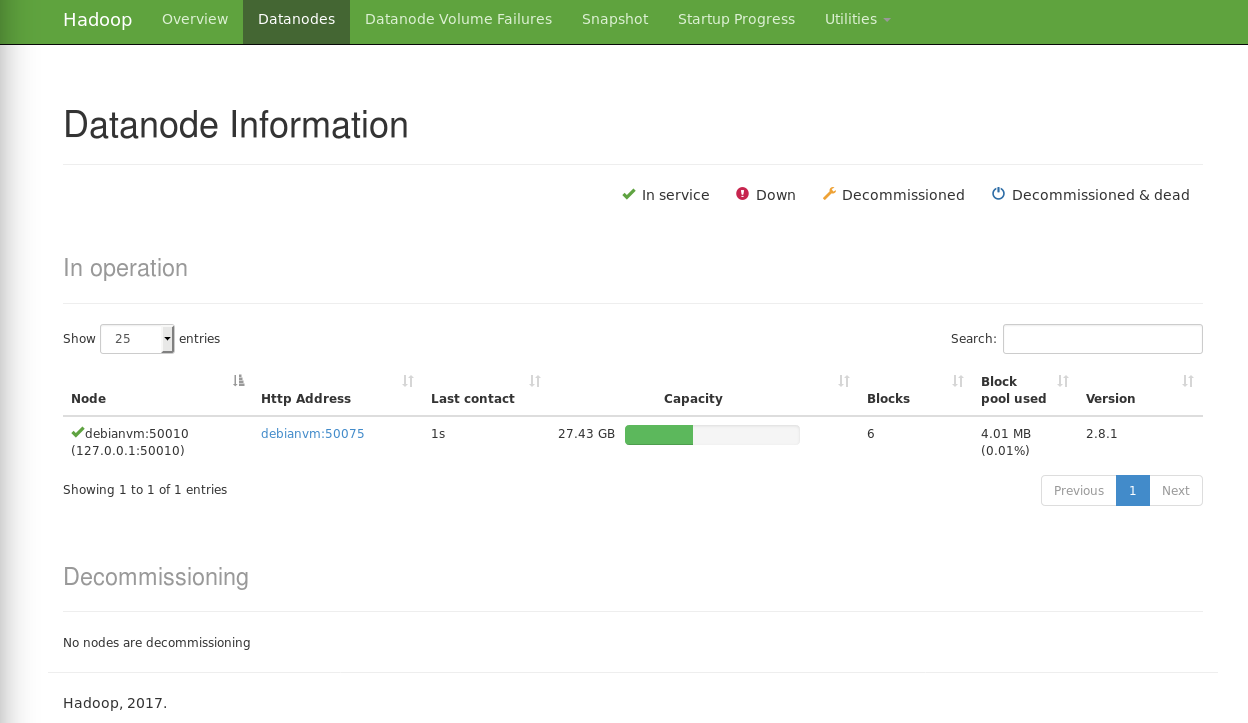
Erreur “Connection refused”
Une erreur “Connection refused” peut se produire quand on essaie de démarrer Hadoop avec start-dfs.sh. Cette erreur est assez déroutante puisqu’elle peut se produire sans raison particulière alors que le cluster a déjà fonctionné.
On peut s’apercevoir de cette erreur après exécution de start-dfs.sh et quand on essaie d’accéder à l’interface d’Hadoop en se connectant à l’adresse http://localhost:50070.
Pour savoir s’il s’agit bien de la même erreur, il suffit d’aller dans le répertoire des fichiers de logs:
vi /usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-datanode-<nom de la machine>.log
Hadoop refuse de démarrer et loggue une erreur du type:
2017-09-16 09:41:21,836 WARN org.apache.hadoop.ipc.Client: Failed to connect to server: localhost/127.0.0.1:9000: retries get failed due to exceeded maximum allowed retries number: 10
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:495)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:681)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:777)
at org.apache.hadoop.ipc.Client$Connection.access$3500(Client.java:409)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1542)
at org.apache.hadoop.ipc.Client.call(Client.java:1373)
at org.apache.hadoop.ipc.Client.call(Client.java:1337)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy15.versionRequest(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.versionRequest(DatanodeProtocolClientSideTranslatorPB.java:274)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.retrieveNamespaceInfo(BPServiceActor.java:215)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:261)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:746)
at java.lang.Thread.run(Thread.java:748)
Toutes les tentatives futures pour se connecter à l’adresse localhost/127.0.0.1:9000 ne fonctionnent pas:
017-09-16 09:43:22,011 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: localhost/127.0.0.1:9000
2017-09-16 09:43:28,013 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2017-09-16 09:43:29,013 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
etc...
L’erreur semble provenir du fait qu’Hadoop est sensible aux redirections DNS effectuées par Linux entre l’adresse localhost dirigée vers 127.0.0.1 et le nom réseau de la machine dirigée vers 127.0.1.1.
Tout d’abord avant de commencer à changer la configuration, il faut stopper l’exécution d’Hadoop et de YARN si ce n’est pas déjà fait (en tant qu’utilisateur “hduser”) en exécutant:
/usr/hadoop/hadoop-2.8.1/sbin/stop-yarn.sh
/usr/hadoop/hadoop-2.8.1/sbin/stop-dfs.sh
Ensuite, il faut connaître le nom réseau utilisé par Hadoop en exécutant:
hostname --fqdn
Le résultat est le nom réseau utilisé.
Pour corriger le problème, il faut éditer le fichier /etc/hosts en tant qu’utilisateur root:
su
vi /etc/hosts
Par défaut le fichier se présente de cette façon:
127.0.0.1 localhost
127.0.1.1 <nom réseau de la machine>
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
Il faut paramétrer la même adresse pour le nom réseau de la machine et commenter les lignes correspondant à IPv6:
127.0.0.1 localhost
127.0.0.1 <nom réseau de la machine>
# The following lines are desirable for IPv6 capable hosts
#::1 localhost ip6-localhost ip6-loopback
#ff02::1 ip6-allnodes
#ff02::2 ip6-allrouters
Il faut ensuite affiner la configuration pour que certains fichiers temporaires soient créés dans le répertoire de l’utilisateur “hduser”. Il faut éditer le fichier core-site.xml et ajouter quelques éléments de configuration:
vi /usr/hadoop/hadoop-2.8.1/etc/hadoop/core-site.xml
Après avoir ajouté les éléments, le fichier doit se présenter de cette façon:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<description>The name of the default file system.</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hduser/hadoop_data/hd-data/tmp</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/home/hduser/hadoop_data/hd-data/snn</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hduser/hadoop_data/hd-data/dn</value>
</property>;
</configuration>
Les parties en gras sont les parties nouvelles par rapport à la configuration précédente.
Il faut ensuite créer le répertoire hadoop_data dans le répertoire de l’utilisateur “hduser” (cette étape doit être effectuée en tant qu’utilisateur “hduser” pour qu’Hadoop puisse écrire dans le répertoire):
mkdir /home/hduser/hadoop_data
Il faut ensuite supprimer les fichiers temporaires d’Hadoop (en tant qu’utilisateur root):
rm -r /tmp/hadoop*
Enfin, il faut reformater HDFS en exécutant (en tant qu’utilisateur “hduser”):
/usr/hadoop/hadoop-2.8.1/hdfs namenode -format
On peut ensuite essayer de démarrer Hadoop avec:
/usr/hadoop/hadoop-2.8.1/sbin/start-dfs.sh
Le fichier log du NameNode devrait ne plus comporter l’erreur “Connection refused”. On peut consulter ce fichier de log et les autres fichiers pour le vérifier. Ces fichiers se trouvent dans:
/usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-datanode-<nom de la machine>.log
/usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-namenode-<nom de la machine>.log
/usr/hadoop/hadoop-2.8.1/logs/hadoop-hduser-secondarynamenode-<nom de la machine>.log
On peut tenter de se connecter à l’interface web d’Hadoop sur:
http://localhost:50070
5. YARN
Configuration de YARN
Cette étape permet de configurer le gestionnaire de cluster YARN (pour Yet Another Resource Negotiator) en nœud simple (ie. single-node). Il faut éditer le fichier /usr/hadoop/hadoop-2.8.1/etc/hadoop/mapred-site.xml (ou le créer s’il n’existe pas en copiant mapred-site.xml.template) et ajouter:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Cette configuration permet d’indiquer d’utiliser YARN en tant qu’implémentation de MapReduce.
Il faut ensuite éditer le fichier /usr/hadoop/hadoop-2.8.1/etc/hadoop/yarn-site.xml et ajouter:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Exécution de YARN
Après la configuration, on peut démarrer le daemon ResourceManager et NodeManager en tapant:
start-yarn.sh
Cette commande est dans un répertoire rajouté dans la variable d’environnement PATH donc elle doit être accessible de n’importe où. Ce fichier se trouve dans /usr/hadoop/hadoop-2.8.1/sbin/start-yarn.sh.
L’interface web du ResourceManager est accessible à l’adresse:
http://localhost:8088/
L’interface est du type:

6. Execution d’un job MapReduce
Le job le plus couramment exécuté pour illustrer l’exécution de jobs MapReduce est le Wordcount (i.e. comptage de mots). Il faut utiliser en entrée un texte et en sortie du job, on obtient une liste de mots avec le nombre d’occurences pour chaque mot.
Comme texte d’entrée, on peut utiliser le fichier correspondant au livre Guerre et Paix:
http://www.gutenberg.org/files/2600/2600-0.txt
Il faut copier ce fichier dans HDFS en écrivant:
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hduser
hdfs dfs -mkdir /user/hduser/input
hdfs dfs -put 2600-0.txt /user/hduser/input
A ce moment on peut voir le fichier dans HDFS si on va dans l’interface web de Hadoop à l’adresse http://localhost:50070 dans l’onglet Utilities ➔ Browse the file system:
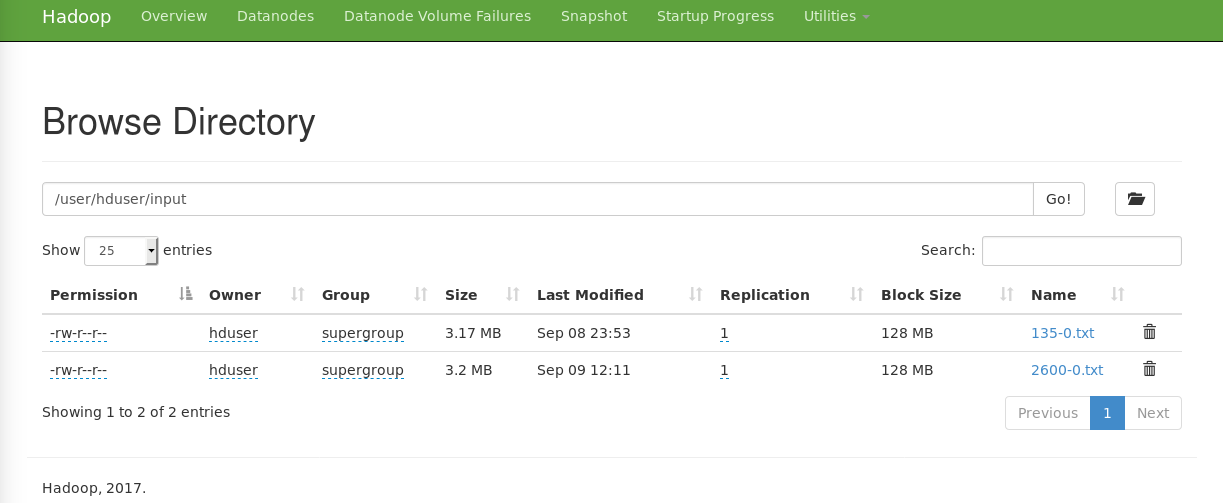
On peut lancer le job en écrivant:
hadoop jar /usr/hadoop/hadoop-2.8.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /user/hduser/input/2600-0.txt output
Cette ligne permet de lancer le job “wordcount” qui est implémenté dans le fichier JAR hadoop-examples-2.8.1.jar avec en entrée le fichier 2600-0.txt qui a été copié dans HDFS. Le résultat sera écrit dans le répertoire output dans HDFS.
L’exécution donnera en sortie:
17/09/09 12:16:44 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/09/09 12:16:45 INFO input.FileInputFormat: Total input files to process : 1
17/09/09 12:16:46 INFO mapreduce.JobSubmitter: number of splits:1
17/09/09 12:16:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1504949218149_0001
17/09/09 12:16:48 INFO impl.YarnClientImpl: Submitted application application_1504949218149_0001
17/09/09 12:16:48 INFO mapreduce.Job: The url to track the job: http://debianvm:8088/proxy/application_1504949218149_0001/
17/09/09 12:16:48 INFO mapreduce.Job: Running job: job_1504949218149_0001
17/09/09 12:17:09 INFO mapreduce.Job: Job job_1504949218149_0001 running in uber mode : false
17/09/09 12:17:09 INFO mapreduce.Job: map 0% reduce 0%
17/09/09 12:17:39 INFO mapreduce.Job: map 100% reduce 0%
17/09/09 12:17:53 INFO mapreduce.Job: map 100% reduce 100%
17/09/09 12:17:57 INFO mapreduce.Job: Job job_1504949218149_0001 completed successfully
17/09/09 12:17:57 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=649694
FILE: Number of bytes written=1571945
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3359665
HDFS: Number of bytes written=487290
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=27460
Total time spent by all reduces in occupied slots (ms)=10545
Total time spent by all map tasks (ms)=27460
Total time spent by all reduce tasks (ms)=10545
Total vcore-milliseconds taken by all map tasks=27460
Total vcore-milliseconds taken by all reduce tasks=10545
Total megabyte-milliseconds taken by all map tasks=28119040
Total megabyte-milliseconds taken by all reduce tasks=10798080
Map-Reduce Framework
Map input records=66055
Map output records=566308
Map output bytes=5541955
Map output materialized bytes=649694
Input split bytes=115
Combine input records=566308
Combine output records=41991
Reduce input groups=41991
Reduce shuffle bytes=649694
Reduce input records=41991
Reduce output records=41991
Spilled Records=83982
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=210
CPU time spent (ms)=6020
Physical memory (bytes) snapshot=412577792
Virtual memory (bytes) snapshot=3924443136
Total committed heap usage (bytes)=284688384
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3359550
File Output Format Counters
Bytes Written=487290
On peut voir le fichier contenant les résultats en écrivant:
hdfs dfs -ls /user/hduser/output
Les fichiers sur HDFS sont:
Found 2 items
-rw-r--r-- 1 hduser supergroup 0 2017-09-09 12:17 /user/hduser/output/_SUCCESS
-rw-r--r-- 1 hduser supergroup 487290 2017-09-09 12:17 /user/hduser/output/part-r-00000
On peut récupérer le fichier contenant les résultats en écrivant:
hdfs dfs -get /user/hduser/output/part-r-00000
On peut lire maintenant le fichier. Le contenu est une liste de mots avec le nombre d’occurences pour chaque mot.
Pour supprimer les fichiers se trouvant sur HDFS, il faut exécuter:
hdfs dfs -rm -R /user/hduser/output
hdfs dfs -rm -R /user/hduser/input
7. Stopper l’exécution de YARN et Hadoop
Il faut taper les commandes suivantes:
stop-yarn.sh
Si l’arrêt se passe bien, l’exécution est du type:
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
localhost: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop
stop-dfs.sh
Le résultat peut être du type:
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
- Hadoop: Setting up a Single Node Cluster: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
- Apache Hadoop: http://hadoop.apache.org/
- Setup newest Hadoop 2.x (2.2.0) on Ubuntu : http://codesfusion.blogspot.fr/2013/10/setup-hadoop-2x-220-on-ubuntu.html
- Installation et configuration d’un cluster simple nœud avec Cloudera CDH 5: http://mbaron.developpez.com/tutoriels/bigdata/hadoop/installation-configuration-cluster-singlenode-avec-cloudera-cdh5/
- Connection Refused: https://wiki.apache.org/hadoop/ConnectionRefused
- Stackoverflow: unable to check nodes on hadoop [Connection refused]: https://stackoverflow.com/questions/10918269/unable-to-check-nodes-on-hadoop-connection-refused
- Stackoverflow: hadoop connection refused on port 9000: https://stackoverflow.com/questions/18322102/hadoop-connection-refused-on-port-9000
- Stackoverflow: Failed to connect to server: localhost/127.0.0.1:9000: try once and fail. java.net.ConnectException: Connection refused: https://stackoverflow.com/questions/44273431/failed-to-connect-to-server-localhost-127-0-0-19000-try-once-and-fail-java-n
salut
super tuto.
> à priori 2 coquilles :
1) § 2 :mkdir /etc/hadoop > mkdir /usr/hadoop
2) § “exécution des jobs localement”:
export JAVA_HOME=/usr/java/jdk1.8.0_144/
export HADOOP_HOME=/usr/hadoop/hadoop-2.8.1/
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
avec ce paramétrage j’ai
/usr/hadoop/hadoop-2.8.1//sbin et /usr/hadoop/hadoop-2.8.1//bin
corrigé en modifiant :
export HADOOP_HOME=/usr/hadoop/hadoop-2.8.1/
en
export HADOOP_HOME=/usr/hadoop/hadoop-2.8.1
Par ailleurs: j’ai installé en utilisant des packages java 10 et hadoop 3.0.3
A noter que en hadoop V3 le port 50070 à changé pour 9870
j’ai passé l’étape 4. J’attaque la 5
cordialement
Merci beaucoup pour votre commentaire, je vais corriger les coquilles. J’espère que vous avez pu aboutir, toutefois, dans l’installation.
Bonjour,
Vous n’auriez pas quelque chose de clair pour installer Hue sur le cluster que vous venez de faire? En passant, c’est très clair et les instruction facile a suivre. Ça fait plus d’un mois que j’essaye avec les instructions de mon prof et il n’y a rien qui fonctionne alors qu’avec les autres, après 2h, tout est nickel.
Merci