Les contextes de chargement d’assemblies (i.e. assembly load contexts) correspondent à une proposition différente et plus aboutie que les domaines d’application (i.e. application domain) pour permettre d’assurer le même type de fonctionnalités:
- Permettre de charger des versions différentes d’une même assembly dans un même processus,
- Permettre de charger puis de décharger de façon modulaire des assemblies
L’avantage des contextes de chargement d’assemblies est qu’il n’y a pas de frontières entre les contextes comme pour les domaines d’application: des assemblies peuvent être partagées d’un contexte à l’autre. Pour assurer la possibilité de charger une même assembly avec une version différente, les contextes de chargement se concentrent sur l’aspect chargement de l’assembly plutôt que d’établir une frontière qui va perdurer pendant toute la durée de présence des 2 versions d’assemblies dans le processus.
Le but de cet article est de passer en revue les caractéristiques des assembly load contexts en les illustrant avec des exemples et de les comparer aux application domains.
Dans un 1er temps, on va expliquer le fonctionnement général des contextes de chargement d’assemblies, ensuite on va rentrer davantage dans les détails sur la façon dont les assemblies sont chargées dans le cas de plusieurs contextes. Enfin, on explicitera quelques fonctionnalités un peu plus avancées.
Fonctionnement des contextes de chargement
Il existe un contexte de chargement par défaut toujours présent lors de l’exécution d’un processus. Par la suite, on peut créer d’autres contextes pour des besoins particuliers de chargement d’assemblies. Dans un premier temps, on ne considère que le contexte de chargement par défaut.
Contexte de chargement par défaut
A l’issue de la compilation d’une application .NET, au moins 2 fichiers sont générés:
- Une assembly contenant le “main” de l’application avec le code fonctionnel et
- Un fichier exécutable qui est l’app host (i.e. application host) spécifique au système d’exploitation et à un runtime donné.
Au démarrage de l’application .NET, l’app host va charger quelques assemblies du framework comme par exemple:
hostfxr.dll: cette DLL va sélectionner le bon runtime permettant d’exécuter l’application .NET. Ce runtime dépend du runtime ciblé au moment de la compilation, du système d’exploitation et du runtime réellement installé.hostpolicy.dll: regroupe toutes les stratégies pour charger le runtime, appliquer la configuration, résoudre les dépendances de l’application et appeler le runtime pour exécuter l’application.coreclr.dll: c’est le CLR qui va exécuter le code .NET. Le comportement est ensuite similaire au framework .NET historique: le code .NET sous la forme de code IL est compilé au besoin par l’intermédiaire du compilateur JIT. Ce code est ensuite exécuté.
Lorsque le code fonctionnel se trouvant dans la fonction “main” est exécuté, suivant les types à exécuter, il peut être nécessaire de charger d’autres assemblies plus spécifiques au code à exécuter. Ces assemblies doivent être chargées avec leurs dépendances managées ou natives. Avant de charger ces assemblies, une recherche des fichiers est effectuée pour les localiser. Cette recherche est appelée assembly probing, elle consiste à parcourir plusieurs chemins précis pour trouver où se situe l’assembly et ses éventuelles dépendances.
Par défaut, les emplacements suivants sont parcourus:
TRUSTED_PLATFORM_ASSEMBLIES: liste des chemins des assemblies du framework (managées et natives).PLATFORM_RESOURCE_ROOTS: liste des chemins des répertoires qui seront parcourus pour chercher les assemblies satellites (assemblies de ressources).NATIVE_DLL_SEARCH_DIRECTORIES: liste des chemins des répertoires qui seront parcourus pour chercher les DLL natives.APP_PATHS et APP_NI_PATHS: chemin de l’application
Lorsque l’assembly est trouvée, elle est chargée avec ces dépendances. Il ne faut pas considérer que l’assembly est chargée dans le contexte par défaut mais grâce au contexte de chargement par défaut. La notion d’application domain avec des frontières n’existe plus, le contexte de chargement permet de fournir une logique pour trouver et charger une assembly.
Fonctionnement avec des contextes de chargement supplémentaires
Si on crée des contextes de chargement d’assemblies supplémentaires, la recherche et le chargement des assemblies peuvent être modifiés toutefois il n’y a pas d’isolation avec le contexte de chargement par défaut c’est la logique de recherche des assemblies qui est différente.
Ainsi si on souhaite accéder et exécuter un type particulier:
- Si le type a été chargé avec le contexte de chargement par défaut alors on y accède et on peut l’exécuter directement.
- Si le type a été chargé avec un contexte supplémentaire, son accès et son exécution ne seront possibles qu’en précisant le contexte supplémentaire explicitement lors de l’accès au type. Dans le cas contraire une exception sera lancée.
Si le chargement du type nécessite le chargement d’autres types dans d’autres assemblies alors:
- La recherche des dépendances se fera d’abord en utilisant le contexte de chargement supplémentaire.
- Si le contexte de chargement supplémentaire ne permet pas de trouver la dépendance alors la recherche se fera en utilisant le contexte de chargement par défaut.
Exemples d’utilisation des contextes de chargement
Au moyen de quelques exemples, on va essayer d’indiquer quelles sont les fonctionnalités principales des contextes de chargement des assemblies.
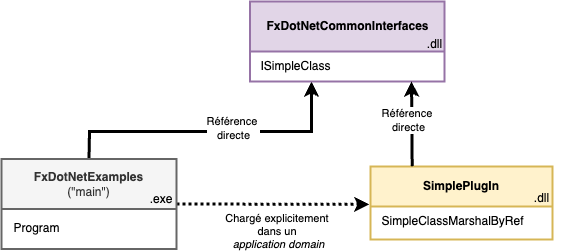
L’exemple utilisé est similaire à celui utilisé pour les application domains:
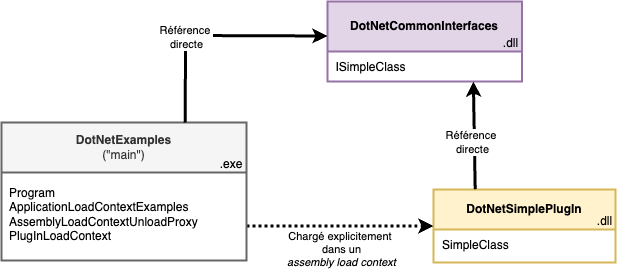
- Une assembly nommée
DotNetCommonInterfaces contenant une interface avec la signature de la fonction à exécuter:
public interface ISimpleClass
{
void HelloWorldExample();
}
- Une assembly nommée
DotNetSimplePlugIn contenant le code à exécuter qui doit être chargé dans un autre contexte de chargement d’assemblies. Dans cette assembly se trouve la classe SimpleClass qui satisfait ISimpleClass:
public class SimpleClass: ISimpleClass
{
public void HelloWorldExample()
{
Console.WriteLine($"{nameof(SimpleClass.HelloWorldExample)} executed");
}
}
- Un exécutable
DotNetExamples contenant le code de test pour manipuler les contextes de chargement des assemblies. Cet exécutable a une référence vers l’assembly DotNetCommonInterfaces. Dans DotNetExamples, il n’a pas de référence explicite vers DotNetSimplePlugIn.
Chargement d’une assembly dans un contexte de chargement
Comme indiqué plus haut, les contextes de chargement d’assemblies permettent d’apporter une solution pour personnaliser la façon dont les assemblies sont chargées en utilisant une logique différente de celle par défaut. En effet, par défaut, le mécanisme de recherche d’une assembly et de ses dépendances est celui d’assembly probing. L’assembly probing s’applique dans le cas du contexte de chargement d’assemblies par défaut AssemblyLoadContext.Default. L’intérêt de pouvoir ajouter d’autres contextes de chargement d’assemblies est de disposer de plusieurs logiques de chargement d’assemblies dans un même processus et de pouvoir les personnaliser.
Le code suivant permet de charger une assembly dans un contexte de chargement d’assemblies qui n’est pas le contexte par défaut:
const string assemblyLoadContextName = "PlugInLoadContext";
var plugInLoadContext = new AssemblyLoadContext(assemblyLoadContextName);
string plugInAssemblyPath = GetAssemblyPath("DotNetSimplePlugIn.dll");
Assembly a = plugInLoadContext.LoadFromAssemblyPath(plugInAssemblyPath); // ATTENTION: il faut utiliser le chemin absolu
La fonction GetAssemblyPath() permet de construire le chemin absolu de l’assembly à charger (le chemin relatif n’est pas suffisant):
private string GetAssemblyPath(string assemblyName)
{
string currentAssemblyLocation = Assembly.GetExecutingAssembly().Location;
string assemblyNameWithoutExtension = Path.GetFileNameWithoutExtension(assemblyName);
string relativePath = Path.Combine(Path.GetDirectoryName(currentAssemblyLocation),
$@"..\..\..\..\{assemblyNameWithoutExtension}\bin\Debug\net7.0", assemblyName);
return Path.GetFullPath(relativePath);
}
La méthode suivante permet de lister les assemblies dans un contexte de chargement donné:
private void DisplayAssembliesInLoadContext(AssemblyLoadContext loadContext)
{
Console.WriteLine("----------------------------------");
Console.WriteLine($"Assemblies loaded in: {loadContext.Name}:");
foreach (Assembly assembly in loadContext.Assemblies)
{
Console.WriteLine($"{assembly.FullName}");
}
Console.WriteLine("----------------------------------");
}
Si on vérifie les assemblies dans le contexte de chargement par défaut et dans le contexte supplémentaire créé en exécutant:
DisplayAssembliesInLoadContext(plugInLoadContext);
DisplayAssembliesInLoadContext(AssemblyLoadContext.Default);
On obtient:
----------------------------------
Assemblies loaded in: PlugInLoadContext:
DotNetSimplePlugIn, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
----------------------------------
----------------------------------
Assemblies loaded in: Default:
System.Private.CoreLib, Version=7.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e
DotNetExamples, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
System.Runtime, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
Microsoft.Extensions.DotNetDeltaApplier, Version=6.0.0.0, Culture=neutral, PublicKeyToken=adb9793829ddae60
System.IO.Pipes, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Linq, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Collections, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Console, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Threading, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Runtime.InteropServices, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Threading.Overlapped, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Security.AccessControl, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Security.Principal.Windows, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Security.Claims, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Runtime.Loader, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
System.Collections.Concurrent, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
DotNetCommonInterfaces, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
System.Text.Encoding.Extensions, Version=7.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a
----------------------------------
On peut voir que l’assembly DotNetSimplePlugIn est chargée seulement dans le contexte supplémentaire. Toutes les assemblies du framework sont chargées seulement dans le contexte par défaut.
Exécuter du code dans un contexte de chargement supplémentaire avec la reflection
Appeler du code dans le contexte de chargement d’assemblies supplémentaire ne nécessite pas d’utiliser du marshalling ou que les objets soient sérialisables. On peut directement utiliser la reflection pour instancier et utiliser le type contenant le code à appeler.
Par exemple, si on souhaite instancier un type se trouvant dans une assembly chargée dans un contexte de chargement particulier, on peut exécuter:
// il faut indiquer explicitement le contexte ayant permis de charger l'assembly
Assembly a = plugInLoadContext.LoadFromAssemblyPath(dependencyAssemblyPath);
const string simpleClassTypeName = "AssemblyLoadContextExamples.DotNetSimplePlugIn.SimpleClass";
Type pluginType = a.GetType(simpleClassTypeName);
ISimpleClass plugin = (ISimpleClass)Activator.CreateInstance(pluginType);
plugin.HelloWorldExample();
Dans cet exemple, on effectue un cast vers le type ISimpleClass pour faciliter l’appel de la méthode HelloWorldExample(). Ce cast n’est pas indispensable, on peut utiliser la reflection différemment pour appeler le constructeur et pour exécuter la méthode:
Type pluginType = a.GetType(simpleClassTypeName);
// Appel du constructeur pour instancier la classe SimpleClass
ConstructorInfo plugInConstructor = pluginType.GetConstructor(Array.Empty<Type>());
object plugInAsObject = plugInConstructor.Invoke(Array.Empty<object>());
// Exécution de la méthode HelloWorldExample()
MethodInfo helloWorldMethodInfo = pluginType.GetMethod("HelloWorldExample", BindingFlags.Instance | BindingFlags.Public);
helloWorldMethodInfo.Invoke(plugInAsObject, Array.Empty<object>());
Si on affiche les assemblies dans le contexte de chargement par défaut et dans le contexte créé après avoir exécuté la méthode SimpleClass.HelloWorldExample(), on obtient le même résultat que plus haut, l’assembly DotNetSimplePlugIn n’est pas dans le contexte par défaut.
On peut noter que si on exécute les autres surcharges de la méthode Activator.CreateInstance(), en précisant le nom de l’assembly DotNetSimplePlugIn.dll et de la classe SimpleClass:
var pluginObjectHandle = Activator.CreateInstance(a.FullName, pluginType.FullName);
dynamic pluginUntyped = pluginObjectHandle.Unwrap();
On obtient une erreur car la recherche ne se fait que dans le contexte de chargement par défaut:
System.IO.FileNotFoundException: 'Could not load file or assembly 'DotNetSimplePlugIn, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null'. The system cannot find the file specified.'
Il faut que l’assembly soit chargée dans le contexte par défaut pour que cette surcharge fonctionne:
Assembly b = AssemblyLoadContext.Default.LoadFromAssemblyPath(dependencyAssemblyPath);
var pluginObjectHandle = Activator.CreateInstance(b.FullName, pluginType.FullName);
dynamic pluginUntyped = pluginObjectHandle.Unwrap();
plugin.HelloWorldExample();
Chargement des dépendances
Une assembly peut avoir des dépendances spécifiques. Si du code dans une assembly nécessite le chargement de dépendances managées ou non managées, le CLR va chercher à charger les assemblies ou DLL correspondantes. Le comportement sera légèrement différent suivant le contexte de chargement utilisé pour charger l’assembly d’origine:
- Si l’assembly d’origine a été chargée avec le contexte de chargement par défaut, alors la dépendance sera localisée en utilisant l’algorithme de “default probing” évoqué précédemment. La dépendance sera ensuite chargée en utilisant le contexte de chargement par défaut ce qui implique qu’elle sera accessible à tous les autres contextes de chargement en tant qu’assembly partagée.
- Si l’assembly d’origine a été chargée avec un contexte supplémentaire (différent du contexte par défaut), alors:
- Dans un 1er temps, le CLR cherchera à charger la dépendance en utilisant le contexte de chargement supplémentaire (le comportement de ce contexte peut éventuellement être personnalisé).
- Si le contexte de chargement supplémentaire n’a pas permis de trouver la dépendance alors le CLR effectuera la recherche de la dépendance en utilisant le contexte de chargement par défaut.
Pour illustrer ce comportement, on reprend l’exemple précédent en ajoutant une dépendance à l’assembly DotNetSimplePlugIn sous la forme d’une assembly nommée DotNetCommonDependency:
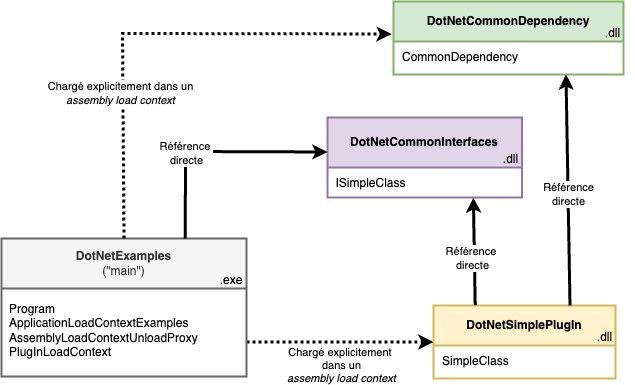
On modifie la classe SimpleClass en rajoutant la méthode suivante:
using AssemblyLoadContextExamples.DotNetCommonInterfaces;
using AssemblyLoadContextExamples.DotNetCommonDependency;
namespace AssemblyLoadContextExamples.DotNetSimplePlugIn;
public class SimpleClass: ISimpleClass
{
// ...
public void FunctionToExecute()
{
var commonDependency = new CommonDependency();
Console.WriteLine($"{nameof(SimpleClass.FunctionToExecute)} executed. From CommonDependency: {commonDependency.InnerStringValue}");
}
}
La classe CommonDependency se trouve dans une autre assembly nommée DotNetCommonDependency:
namespace AssemblyLoadContextExamples.DotNetCommonDependency;
public class CommonDependency
{
public string InnerStringValue => $"From {nameof(CommonDependency)}";
}
L’assembly DotNetSimplePlugIn référence directement l’assembly DotNetCommonDependency.
On exécute le code suivant permettant de charger l’assembly DotNetSimplePlugIn avec un contexte de chargement supplémentaire et d’exécuter la méthode SimpleClass.FunctionToExecute():
// Création contexte de chargement supplémentaire
var plugInLoadContext = new AssemblyLoadContext(assemblyLoadContextName);
// Chargement de l'assembly DotNetSimplePlugIn avec le contexte supplémentaire
string plugInAssemblyPath = GetAssemblyPath("DotNetSimplePlugIn.dll");
Assembly a = plugInLoadContext.LoadFromAssemblyPath(plugInAssemblyPath);
// Instanciation de la classe SimpleClass
Type pluginType = a.GetType(simpleClassTypeName);
ISimpleClass plugin = (ISimpleClass)Activator.CreateInstance(pluginType);
// On affiche les assemblies chargées grâce au contexte de chargement supplémentaire
DisplayAssembliesInLoadContext(plugInLoadContext);
plugin.FunctionToExecute(); // ⚠ ERREUR ⚠
A l’exécution du code précédent, on obtient une erreur lors de la l’exécution de la ligne plugin.FunctionToExecute() car il n’est pas possible de charger l’assembly DotNetCommonDependency:
- Le contexte de chargement supplémentaire n’a pas d’indications pour charger
DotNetCommonDependency (même si l’assembly DotNetCommonDependency se trouve dans le répertoire de sortie de l’assembly DotNetSimplePlugIn),
- Le contexte de chargement par défaut n’a pas non plus d’indication sur l’emplacement de
DotNetCommonDependency.
L’erreur est:
System.IO.FileNotFoundException: 'Could not load file or assembly 'DotNetCommonDependency, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null'. The system cannot find the file specified.'
A l’exécution, on peut voir que le contexte de chargement supplémentaire ne peut pas charger l’assembly DotNetCommonDependency:
----------------------------------
Assemblies loaded in: PlugInLoadContext:
DotNetSimplePlugIn, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
----------------------------------
Si on modifie le code exécuté pour permettre au contexte de chargement supplémentaire de charger l’assembly DotNetCommonDependency:
// Création contexte de chargement supplémentaire
var plugInLoadContext = new AssemblyLoadContext(assemblyLoadContextName);
// Chargement de l'assembly DotNetSimplePlugIn avec le contexte supplémentaire
string plugInAssemblyPath = GetAssemblyPath("DotNetSimplePlugIn.dll");
Assembly a = plugInLoadContext.LoadFromAssemblyPath(plugInAssemblyPath);
string dependencyAssemblyPath = GetAssemblyPath("DotNetCommonDependency.dll");
plugInLoadContext.LoadFromAssemblyPath(dependencyAssemblyPath);
// Instanciation de la classe SimpleClass
Type pluginType = a.GetType(simpleClassTypeName);
ISimpleClass plugin = (ISimpleClass)Activator.CreateInstance(pluginType);
// On affiche les assemblies chargées grâce au contexte de chargement supplémentaire
DisplayAssembliesInLoadContext(plugInLoadContext);
plugin.FunctionToExecute();
L’exécution ne produit pas d’erreur, la dépendance est correctement chargée grâce au contexte de chargement supplémentaire:
----------------------------------
Assemblies loaded in: PlugInLoadContext:
DotNetSimplePlugIn, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
DotNetCommonDependency, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
----------------------------------
FunctionToExecuteInVersion1 executed. From CommonDependency: From CommonDependency
On modifie de nouveau le code pour ne pas charger l’assembly DotNetCommonDependency avec le contexte de chargement supplémentaire mais avec le contexte par défaut:
// Création contexte de chargement supplémentaire
var plugInLoadContext = new AssemblyLoadContext(assemblyLoadContextName);
// Chargement de l'assembly DotNetSimplePlugIn avec le contexte supplémentaire
string plugInAssemblyPath = GetAssemblyPath("DotNetSimplePlugIn.dll");
Assembly a = plugInLoadContext.LoadFromAssemblyPath(plugInAssemblyPath);
string dependencyAssemblyPath = GetAssemblyPath("DotNetCommonDependency.dll");
AssemblyLoadContext.Default.LoadFromAssemblyPath(dependencyAssemblyPath);
// Instanciation de la classe SimpleClass
Type pluginType = a.GetType(simpleClassTypeName);
ISimpleClass plugin = (ISimpleClass)Activator.CreateInstance(pluginType);
// On affiche les assemblies chargées grâce au contexte de chargement supplémentaire
DisplayAssembliesInLoadContext(plugInLoadContext);
plugin.FunctionToExecute();
L’exécution ne produit pas d’erreur. Conformement au mécanisme de chargement expliqué plus haut, dans un 1er temps le CLR cherche à charger la dépendance DotNetCommonDependency avec le contexte de chargement supplémentaire ce qui échoue. Dans un 2e temps, le chargement de la dépendance se fait avec le contexte de chargement par défaut, ce qui réussit. Durant l’exécution, on peut voir que le contexte de chargement supplémentaire ne permet pas de charger l’assembly DotNetCommonDependency:
----------------------------------
Assemblies loaded in: PlugInLoadContext:
DotNetSimplePlugIn, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
----------------------------------
FunctionToExecuteInVersion1 executed. From CommonDependency: From CommonDependency
Assemblies partagées entre plusieurs contexte de chargement
Lors du chargement d’une assembly, quelque soit le cas de figure, le CLR va tenter d’utiliser le contexte de chargement par défaut pour localiser puis charger l’assembly soit directement, soit après avoir essayé d’utiliser un contexte de chargement supplémentaire (voir plus haut).
Ainsi si on charge une assembly avec le contexte de chargement par défaut (comme dans le cas de l’exemple précédent), il est possible de partager cette assembly entre tous les contextes de chargement.
Exemple de chargement d’un même type dans des contextes de chargement différents
Le but de cet exemple est de montrer comment il est possible de charger 2 versions d’une même assembly dans un même processus en utilisant les contextes de chargement. En pratique il suffit de charger les 2 versions dans 2 contextes de chargement différents. Dans cet exemple, on crée 2 contextes de chargement différents toutefois, on peut se contenter d’en créer un seul:
- Une 1ère version est chargée dans le contexte de chargement par défaut et
- Une 2e version dans un contexte supplémentaire.
Dans cet exemple, on considère 2 versions de l’assembly DotNetSimplePlugIn.dll avec les implémentations suivantes:
- Version 1 (dans le répertoire
\..\Version1\DotNetSimplePlugIn.dll):
public class SimpleClass: ISimpleClass
{
public void FunctionToExecuteInVersion1()
{
var commonDependency = new CommonDependency();
Console.WriteLine($"{nameof(SimpleClass.FunctionToExecuteInVersion1)} executed. From CommonDependency: {commonDependency.InnerStringValue}");
}
}
- Version 2 (dans le répertoire
\..\Version2\DotNetSimplePlugIn.dll):
public class SimpleClass: ISimpleClass
{
public void FunctionToExecuteInVersion2()
{
var commonDependency = new CommonDependency();
Console.WriteLine($"{nameof(SimpleClass.FunctionToExecuteInVersion2)} executed. From CommonDependency: {commonDependency.InnerStringValue}");
}
}
Comme on peut le voir, ces 2 versions dépendent d’une assembly commune nommée DotNetCommonDependency. Cette assembly sera chargée dans le contexte de chargement par défaut pour qu’elle soit partagée.
Dans un 1er temps, on va essayer de charger les 2 versions dans le même contexte de chargement:
// Création d'un seul contexte de chargement
var loadContextForV1 = new AssemblyLoadContext("loadContextV1Name");
//var loadContextForV2 = new AssemblyLoadContext("loadContextV2Name");
// On charge les 2 versions dans un même contexte de chargement
Assembly assemblyV1 = loadContextForV1.LoadFromAssemblyPath(
Path.GetFullPath("..\\..\\..\\..\\TEST\\Version1\\DotNetSimplePlugIn.dll"));
Assembly assemblyV2 = loadContextForV1.LoadFromAssemblyPath(
Path.GetFullPath("..\\..\\..\\..\\TEST\\Version2\\DotNetSimplePlugIn.dll")); // ⚠ ERREUR ⚠
// On charge la dépendance DotNetCommonDependency
string dependencyAssemblyPath = GetAssemblyPath("DotNetCommonDependency.dll");
Assembly commonDependency = AssemblyLoadContext.Default.LoadFromAssemblyPath(dependencyAssemblyPath);
// Instanciation des 2 versions de SimpleClass
Type typeV1 = assemblyV1.GetType(simpleClassTypeName);
Type typeV2 = assemblyV2.GetType(simpleClassTypeName);
dynamic simpleClassFromV1 = Activator.CreateInstance(typeV1);
dynamic simpleClassFromV2 = Activator.CreateInstance(typeV2);
// On exécute les méthodes correspondant aux bonnes versions
simpleClassFromV1.FunctionToExecuteInVersion1();
simpleClassFromV2.FunctionToExecuteInVersion2();
Sans surprise, quand on essaie de charger une 2e version de la même assembly dans le même contexte de chargement on obtient une erreur:
System.IO.FileLoadException: 'Assembly with same name is already loaded'
On place alors la 2e version dans un 2e contexte de chargement:
// Création de 2 contextes de chargement
var loadContextForV1 = new AssemblyLoadContext("loadContextV1Name");
var loadContextForV2 = new AssemblyLoadContext("loadContextV2Name");
// On charge les 2 versions dans un même contexte de chargement
Assembly assemblyV1 = loadContextForV1.LoadFromAssemblyPath(
Path.GetFullPath("..\\..\\..\\..\\TEST\\Version1\\DotNetSimplePlugIn.dll"));
Assembly assemblyV2 = loadContextForV2.LoadFromAssemblyPath(
Path.GetFullPath("..\\..\\..\\..\\TEST\\Version2\\DotNetSimplePlugIn.dll"));
// On charge la dépendance DotNetCommonDependency
string dependencyAssemblyPath = GetAssemblyPath("DotNetCommonDependency.dll");
Assembly commonDependency = AssemblyLoadContext.Default.LoadFromAssemblyPath(dependencyAssemblyPath);
// Instanciation des 2 versions de SimpleClass
Type typeV1 = assemblyV1.GetType(simpleClassTypeName);
Type typeV2 = assemblyV2.GetType(simpleClassTypeName);
dynamic simpleClassFromV1 = Activator.CreateInstance(typeV1);
dynamic simpleClassFromV2 = Activator.CreateInstance(typeV2);
// On exécute les méthodes correspondant aux bonnes versions
simpleClassFromV1.FunctionToExecuteInVersion1();
simpleClassFromV2.FunctionToExecuteInVersion2();
Pas d’erreur, l’exécution aboutit normalement:
FunctionToExecuteInVersion1 executed. From CommonDependency: From CommonDependency
FunctionToExecuteInVersion2 executed. From CommonDependency: From CommonDependency
Le point important dans cet exemple est que les 2 types sont bien distincts même s’il s’agit de 2 versions d’une même classe.
AssemblyLoadContext.EnterContextualReflection()
Si on ne précise pas le contexte de chargement à utiliser pour exécuter certaines fonctions statiques, c’est le contexte par défaut qui est utilisé. Ainsi si on a chargé des assemblies dans un contexte de chargement particulier et qu’on souhaite effectuer des opérations sur ces assemblies, on risque d’avoir une erreur car ces opérations pourront être exécutées dans le contexte par défaut.
Les fonctions pour lesquelles il peut être nécessaire de préciser le contexte sont:
Dans un des exemples présentés précédemment, nous avons expérimenté ce problème. Dans cet exemple, 2 assemblies sont en jeu:
DotNetExamples contenant le “main” qui permet de créer un contexte de chargement supplémentaire et de lancer le code de l’exemple,DotNetSimplePlugIn qui est le plug-in à charger dans un contexte de chargement différent,
Pour rappel, le code exécuté est le suivant:
// Création contexte de chargement supplémentaire
var plugInLoadContext = new AssemblyLoadContext(assemblyLoadContextName);
// Chargement de l'assembly DotNetSimplePlugIn avec le contexte supplémentaire
string plugInAssemblyPath = GetAssemblyPath("DotNetSimplePlugIn.dll");
Assembly a = plugInLoadContext.LoadFromAssemblyPath(plugInAssemblyPath);
// Instanciation de la classe SimpleClass
Type pluginType = a.GetType(simpleClassTypeName);
var pluginObjectHandle = Activator.CreateInstance(a.FullName, simpleClassTypeName); // ⚠ ERREUR ⚠
dynamic pluginUntyped = pluginObjectHandle.Unwrap();
// Exécution de la fonction dans le plug-in
pluginUntyped.HelloWorldExample();
L’erreur est:
System.IO.FileNotFoundException: 'Could not load file or assembly 'DotNetSimplePlugIn, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null'. The system cannot find the file specified.'
L’erreur se produit à l’exécution de la fonction statique Activator.CreateInstance() car le contexte dans lequel cette fonction est exécutée est celui du contexte de chargement par défaut. Etant donné que l’assembly DotNetSimplePlugIn n’a pas été chargée dans le contexte par défaut, elle ne peut être instanciée avec le contexte par défaut.
Pour remédier à ce problème, une solution est de préciser un contexte de chargement à appliquer avec la fonction AssemblyLoadContext.EnterContextualReflection(). Cette fonction permet à l’intérieur d’une clause using de préciser le contexte qui devrait être utilisé:
using (<instance contexte de chargement>.EnterContextualReflection())
{
// Le code sera exécuté dans un contexte de chargement spécifique
}
Une autre surcharge de cette fonction permet d’appliquer un contexte utilisé pour charger une assembly donnée:
using (AssemblyLoadContext.EnterContextualReflection(<assembly>))
{
// Le code sera exécuté dans un contexte de chargement spécifique
}
Dans le cas de l’exemple, si on modifie le code de cette façon:
// Création contexte de chargement supplémentaire
var plugInLoadContext = new AssemblyLoadContext(assemblyLoadContextName);
// Chargement de l'assembly DotNetSimplePlugIn avec le contexte supplémentaire
string plugInAssemblyPath = GetAssemblyPath("DotNetSimplePlugIn.dll");
Assembly a = plugInLoadContext.LoadFromAssemblyPath(plugInAssemblyPath);
// On précise le contexte à utiliser
using (plugInLoadContext.EnterContextualReflection())
{
// Instanciation de la classe SimpleClass
Type pluginType = a.GetType(simpleClassTypeName);
var pluginObjectHandle = Activator.CreateInstance(a.FullName, simpleClassTypeName); // OK
dynamic pluginUntyped = pluginObjectHandle.Unwrap();
// Exécution de la fonction dans le plug-in
pluginUntyped.HelloWorldExample();
}
Il n’y a pas d’erreur, la fonction statique Activator.CreateInstance() est exécutée dans le contexte de chargement plugInLoadContext. Ainsi la classe SimpleClass est correctement instanciée.
Déchargement d’un contexte de chargement
Il est possible de décharger un contexte de chargement ainsi que toutes les assemblies qu’il contient lorsque c’est possible. En réalité, le déchargement ne se fait que si le garbage collector ne constate pas de références qui justifieraient de maintenir chargé le contexte de chargement.
L’appel à la fonction AssemblyLoadContext.Unload() permet d’indiquer qu’on souhaite décharger le contexte de chargement. L’appel ne garantit pas le déchargement effectif du contexte. En effet, il ne sera pas effectué de façon synchrone lors de l’appel mais après exécution du garbage collector et dans le cas où il n’y a pas de dépendances nécessitant que les assemblies soient maintenues dans le contexte.
Si un appel à Unload() n’est pas effectué explicitement pour un contexte de chargement d’assemblies donné, il ne sera jamais déchargé. Enfin, pour décharger un contexte, il faut qu’il soit instancié avec l’option Collectible = true:
var newAppContext = new AssemblyLoadContext(dependencyAssemblyName, true);
Dans l’exemple suivant, pour éviter de maintenir une référence qui empêchera le déchargement, on entoure la référence du contexte de chargement avec une WeakReference:
// Création contexte de chargement supplémentaire
var plugInLoadContext = new AssemblyLoadContext(assemblyLoadContextName, true); // Pour permettre le déchargement Collectible = true
// Ajout d'une WeakReference
WeakReference plugInLoadContextWeakRef = new WeakReference(plugInLoadContext);
string plugInAssemblyPath = GetDependencyAssemblyPath(plugInAssemblyName);
Assembly a = plugInLoadContext.LoadFromAssemblyPath(plugInAssemblyPath);
Type pluginType = a.GetType(simpleClassTypeName);
ISimpleClass plugin = (ISimpleClass)Activator.CreateInstance(pluginType);
plugin.HelloWorldExample();
// Déchargement du contexte
plugInLoadContext.Unload();
// On retourne la WeakReference pour vérifier si le contexte a bien été déchargé
return plugInLoadContextWeakRef;
Après l’exécution de la méthode AssembleLoadContext.Unload(), on sollicite l’exécution du garbage collector puis on vérifie que le contexte a bien été déchargé:
var example = new ApplicationLoadContextExamples();
WeakReference plugInLoadContextWeakRef = example.LoadPlugInExecuteAndUnLoad();
for (int i = 0; plugInLoadContextWeakRef.IsAlive && (i < 10); i++)
{
GC.Collect();
GC.WaitForPendingFinalizers();
}
Contexte de chargement personnalisé
Il est possible d’implémenter un contexte de chargement de façon à personnaliser des comportements lors du chargement d’assemblies. Cette personnalisation se fait en créant une classe dérivant de System.Runtime.Load.AssemblyLoadContext. Appliquer un comportement particulier peut se faire en surchargeant les fonctions:
protected override Assembly? Load(AssemblyName assemblyName) qui permet d’indiquer une assembly en fonction de son nom. protected override IntPtr LoadUnmanagedDll(string unmanagedDllName) permettant d’indiquer l’adresse de base d’une DLL non managée chargée (i.e. HMODULE). Il est possible d’obtenir cette adresse à partir du chemin de la DLL en utilisant la fonction: IntPtr LoadUnmanagedDllFromPath(string unmanagedDllPath).
Des comportements particuliers peuvent être implémentés en s’abonnant aux évènements:
public event Func<AssemblyLoadContext, AssemblyName, Assembly?>? Resolving déclenché quand aucune assembly correspondant au nom fourni n’a pu être trouvée. Cet évènement donne une possibilité de fournir l’assembly quand les autres procédés ont échoué. public event Func<Assembly, string, IntPtr>? ResolvingUnmanagedDll qui est déclenché quand aucune DLL non managée n’a pu être fournie pour un nom donné. Dans les arguments de cet évènement, on peut trouver l’assembly pour laquelle le chargement de la DLL est nécessaire et son nom. Cet évènement est le dernier recours quand une DLL n’a pas été trouvée.
Par exemple, si on reprend l’exemple précédent où l’assembly DotNetSimplePlugIn.dll possède une dépendance vers l’assembly DotNetCommonDependency.dll. On charge l’assembly DotNetSimplePlugIn grâce à un contexte de chargement personnalisé de façon à préciser le chemin de la dépendance DotNetCommonDependency.dll.
Ainsi, dans un premier temps, on crée un contexte de chargement personnalisé:
internal class PlugInLoadContext: AssemblyLoadContext
{
private readonly string plugInPath;
private const string dependencyAssemblyName = "DotNetCommonDependency";
public PlugInLoadContext(string plugInPath)
{
this.plugInPath = plugInPath;
}
protected override Assembly? Load(AssemblyName assemblyName)
{
if (assemblyName.Name.Equals(dependencyAssemblyName))
{
string plugInAssemblyPath = GetAssemblyPath(dependencyAssemblyName);
return LoadFromAssemblyPath(plugInAssemblyPath);
}
else
return base.Load(assemblyName);
}
private string GetAssemblyPath(string assemblyName)
{
string currentAssemblyLocation = Assembly.GetExecutingAssembly().Location;
string assemblyNameWithoutExtension = Path.GetFileNameWithoutExtension(assemblyName);
string relativePath = Path.Combine(Path.GetDirectoryName(currentAssemblyLocation),
$@"..\..\..\..\{assemblyNameWithoutExtension}\bin\Debug\net7.0", assemblyName);
return Path.GetFullPath(relativePath);
}
}
Ensuite on charge l’assembly DotNetSimplePlugIn avec le contexte de chargement personnalisé:
// Création d'un contexte de chargement personnalisé
var plugInLoadContext = new PlugInLoadContext("...");
// Chargement de l'assembly DotNetSimplePlugIn avec le contexte supplémentaire
string plugInAssemblyPath = GetDependencyAssemblyPath("DotNetSimplePlugIn.dll");
Assembly a = plugInLoadContext.LoadFromAssemblyPath(plugInAssemblyPath);
// Instanciation de la classe SimpleClass
Type pluginType = a.GetType(simpleClassTypeName);
ISimpleClass plugin = (ISimpleClass)Activator.CreateInstance(pluginType);
// On affiche les assemblies chargées grâce au contexte de chargement supplémentaire
DisplayAssembliesInLoadContext(plugInLoadContext);
plugin.FunctionToExecute();
La dépendance est correctement chargée car le contexte de chargement personnalisé permet d’indiquer le chemin de l’assembly.
System.Runtime.Loader.AssemblyDependencyResolver
L’objet System.Runtime.Loader.AssemblyDependencyResolver permet de trouver le chemin complet d’une dépendance d’une assembly à partir de son nom. AssemblyDependencyResolver peut donc s’avérer utile dans le cas où on souhaite implémenter un contexte de chargement personnalisé.
Par exemple, si on considère l’assembly DotNetSimplePlugIn.dll qui possède une dépendance directe vers DotNetCommonDependency.dll (à la compilation l’assembly DotNetCommonDependency.dll sera donc rajoutée dans le répertoire de sortie du projet DotNetSimplePlugIn), on peut retrouver le chemin de l’assembly DotNetCommonDependency.dll à partir du nom de la référence DotNetCommonDependency de cette façon:
string plugInAssemblyPath = GetAssemblyPath(plugInAssemblyName);
var resolver = new AssemblyDependencyResolver(plugInAssemblyPath);
var dependencyAssemblyName = new AssemblyName("DotNetCommonDependency");
string? dependencyPath = resolver.ResolveAssemblyToPath(dependencyAssemblyName);
En conclusion…
Comme on a pu le voir, les contextes de chargement d’assemblies permettent d’assurer tous les cas d’utilisation assurés anciennement par les application domains (utilisables seulement avec le framework .NET): le chargement modulaire d’assemblies dans un processus, le déchargement d’assemblies ou le chargement de versions différentes d’une même assembly.
Outre l’aspect isofonctionnel, les contextes de chargement sont plus faciles à mettre en œuvre car ils ne nécessitent pas de marshalling ou de sérialisation des objets. En effet, il n’y a pas de frontières strictes entre les contextes de chargement, il est ainsi plus facile et moins gourmant en performance d’accéder à des objets d’un contexte à l’autre et des dépendances peuvent être facilement partagées entre plusieurs contextes.
Plutôt que d’avoir une isolation forte, le principe des contextes de chargement est de permettre des logiques de chargement d’assemblies différentes d’un contexte à l’autre. Les assemblies et leurs dépendances peuvent être chargées différemment et les possibilités de personnalisation sont bien plus grandes que les domaines d’application.