Cet article est un aide-mémoire concernant les fonctions principales de Swagger UI. La documentation complête se trouve sur le repository GitHub du package Swashbuckle.AspNetCore qui est le package NuGet permettant d’installer Swagger sur une application ASP.NET Core.
Swagger est un outil permettant de documenter un API Web en présentant les différentes fonctions sous forme d’une page web. On peut ainsi utiliser l’interface web pour requêter les différentes fonctions de l’API.
Dans cet article, on va présenter les éléments de paramétrages principaux pour paramétrer Swagger dans le cas d’une API Web ASP.NET Core.
En commençant “from scratch”, pour créer une API Web ASP.NET Core, on peut exécuter la commande suivante après avoir installé la CLI .NET Core:
user@debian:~/% dotnet new webapi --name <nom du projet>
Pour installer Swagger dans une application ASP.NET Core et requêter facilement une API Web, il faut ajouter le package NuGet Swashbuckle.AspNetCore en exécutant la commande suivante:
user@debian:~/% dotnet add <chemin du fichier .csproj> package swashbuckle.aspnetcore
Pour configurer Swashbuckle, il faut ajouter les lignes suivantes dans le fichier StartUp.cs:
public void ConfigureServices(IServiceCollection services)
{
// ...
services.AddSwaggerGen(c =>
{
c.SwaggerDoc("v1", new Info { Title = "Pizza API", Version = "v1"});
});
}
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
// ...
app.UseSwagger();
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("/swagger/v1/swagger.json", "Pizza API V1");
});
// ...
}
Dans l’extrait précédent:
services.AddSwaggerGen() permet de rajouter un service qui va analyser le code pour générer la description de l’API sous forme d’un document JSON (i.e. SwaggerDocument).
app.UseSwagger() va rajouter un middleware pour exposer le contenu du SwaggerDocument (contenant la description de l’API dans un document JSON). En pratique ce middleware va répondre quand une requête est faite à l’adresse http://localhost:5000/swagger/v1/swagger.json (adresse par défaut).
app.UseSwaggerUI() permet de rajouter un middleware pour présenter le SwaggerDocument sous forme d’une interface web. L’ajout de ce middleware est facultatif. On peut utiliser seulement le middleware Swagger, générer le SwaggerDocument et copier le code JSON dans https://editor.swagger.io/ pour l’utiliser.
Dans l’exemple, on peut lancer la compilation et l’exécution en exécutant successivement les lignes suivantes:
user@debian:~/% cd webapi_example
user@debian:~/webapi_example/% dotnet build
user@debian:~/webapi_example/% dotnet run
Par défaut:
La description JSON de l’API se trouve à l’adresse: http://localhost:5000/swagger/v1/swagger.json.
On peut accéder à l’interface de Swagger à l’adresse: http://localhost:5000/swagger/index.html.
Installation de .NET Core sur Linux
Pour installer .NET Core sur Debian, il faut suivre les étapes suivantes:
Quand on requête le description JSON à l’adresse http://localhost:5000/swagger/v1/swagger.json, le document est présenté de façon compacte. On peut améliorer la présentation du document en ajoutant la configuration suivante dans le fichier StartUp.cs:
Dans cet exemple, Swagger sera ainsi accessible à l’adresse: http://localhost:5000/pizza-api-docs.
Ajouter des informations globales
Les éléments de configuration suivants permettent d’ajouter des informations globales sur l’API.
Ajouter un titre HTML
Ce titre correspond au titre de la page HTML. Il apparaîtra dans l’onglet du browser. Pour l’ajouter, il faut rajouter la ligne suivante:
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
// ...
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("/swagger/v1/swagger.json", "Pizza API V1");
c.DocumentTitle = "Custom HTML title";
});
}
Sans préciser davantage d’éléments de configuration, les informations sont présentées de cette façon sur l’interface web de Swagger:
Enrichir les informations globales
On peut ajouter d’autres informations globales, par exemple:
public void ConfigureServices(IServiceCollection services)
{
services.AddSwaggerGen(c =>
{
c.SwaggerDoc("v1", new Info {
Title = "Pizza API",
Version = "v1",
Description = "API for pizza",
TermsOfService = "Terms of Service",
Contact = new Contact
{
Name = "Developer Name",
Email = "developer.name@example.com"
},
License = new License
{
Name = "Apache 2.0",
Url = "http://www.apache.org/licenses/LICENSE-2.0.html"
}
});
});
}
En rajoutant ces informations, on obtient l’affichage suivant:
Prendre en compte les commentaires XML du projet
Swagger peut afficher les commentaires XML du projet, à condition qu’ils soient générés. Avec ASP.NET Core, pour générer les commentaires XML, il faut éditer le fichier .csproj de l’application ASP.NET Core et ajouter la ligne suivante correspondant au nœud XML <DocumentationFile>:
<PropertyGroup>
<TargetFramework>netcoreapp2.2</TargetFramework>
<AspNetCoreHostingModel>InProcess</AspNetCoreHostingModel>
<DocumentationFile>bin\$(Configuration)\$(TargetFramework)\<nom du fichier>.xml</DocumentationFile>
</PropertyGroup>
Ensuite, il faut indiquer le chemin du fichier XML généré à Swagger dans le fichier StartUp.cs du projet:
public void ConfigureServices(IServiceCollection services)
{
// ...
services.AddSwaggerGen(c =>
{
// ...
var filePath = Path.Combine(System.AppContext.BaseDirectory, "<nom du fichier>.xml");
c.IncludeXmlComments(filePath);
});
}
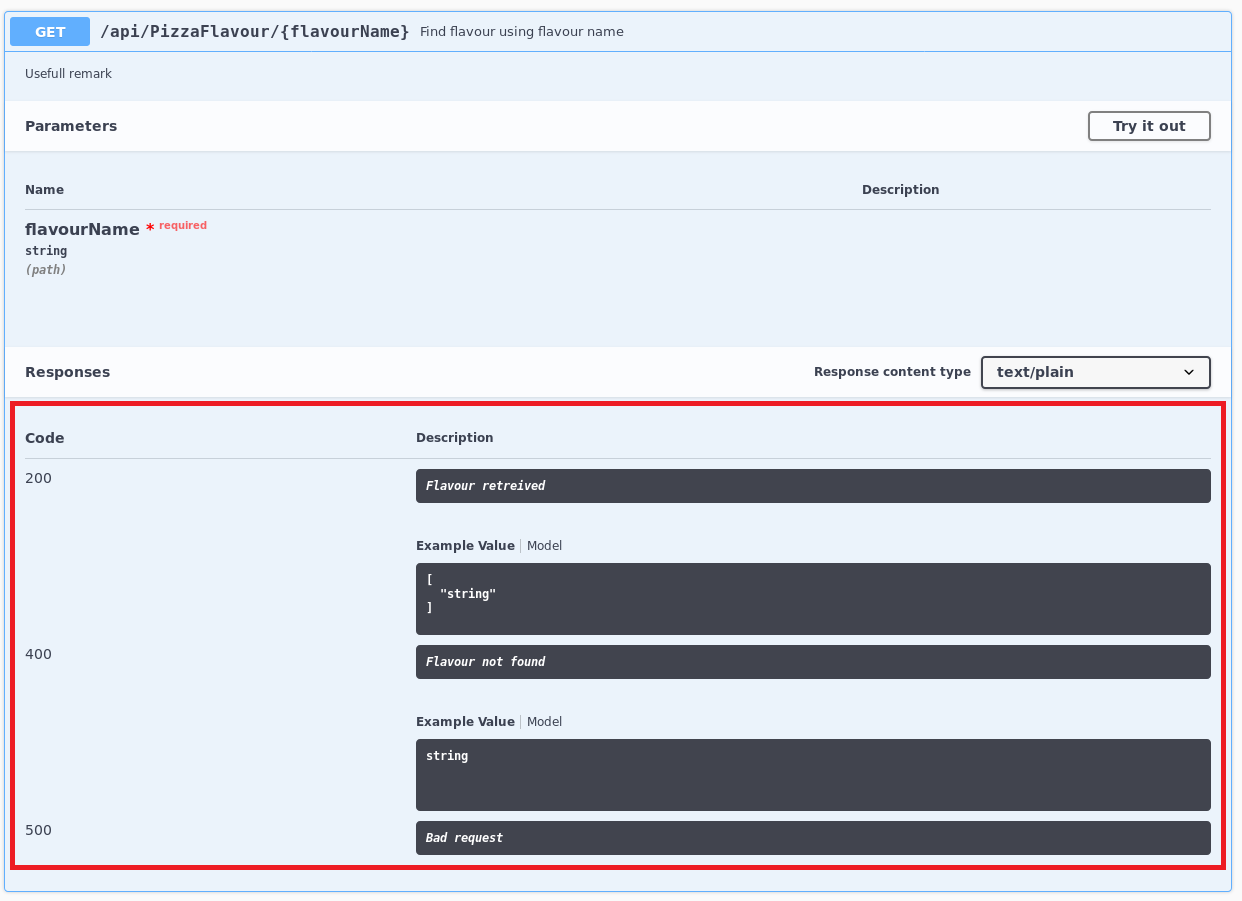
Ainsi, si on ajoute des informations dans les commentaires d’une action d’un controller, par exemple au niveau de l’action FindFlavour() du controllerPizzaFlavourController:
/// <summary>
/// Find flavour using flavour name
/// </summary>
/// <remarks>Usefull remark</remarks>
/// <response code="200">Flavour retreived</response>
/// <response code="400">Flavour not found</response>
/// <response code="500">Bad request</response>
[HttpGet("{flavourName}", Name = "FindFlavourByName")]
[ProducesResponseType(typeof(IEnumerable<string>), 200)]
[ProducesResponseType(typeof(string), 400)]
[ProducesResponseType(500)]
public ActionResult<IEnumerable<string>> FindFlavour(string flavourName)
{
// ...
}
On peut enrichir les informations relatives à la fonction de l’API:
Ajouter des informations sur les actions d’un controller
Sans davantage d’éléments de configuration, l’affichage indique les noms des actions:
En utilisant la propriété Name des attributs HttpGetAttribute, HttpPostAttribute, HttpPutAttribute et HttpDeleteAttribute, on peut préciser un nom particulier différent du nom de l’action.
Par exemple:
[HttpGet("{flavourName}", Name = "FindFlavourUsingFlavourName")]
public ActionResult<IEnumerable<string>> FindFlavour(string flavourName)
{
// ...
}
[HttpPost(Name = "AddPizzaFlavour")]
public ActionResult<int> Post([FromBody, BindRequired]AddPizzaFlavourRequest request)
{
// ...
}
[HttpGet]
public ActionResult<IEnumerable<string>> GetFlavourNames()
{
// ...
}
On obtient ainsi:
Liste des réponses possibles
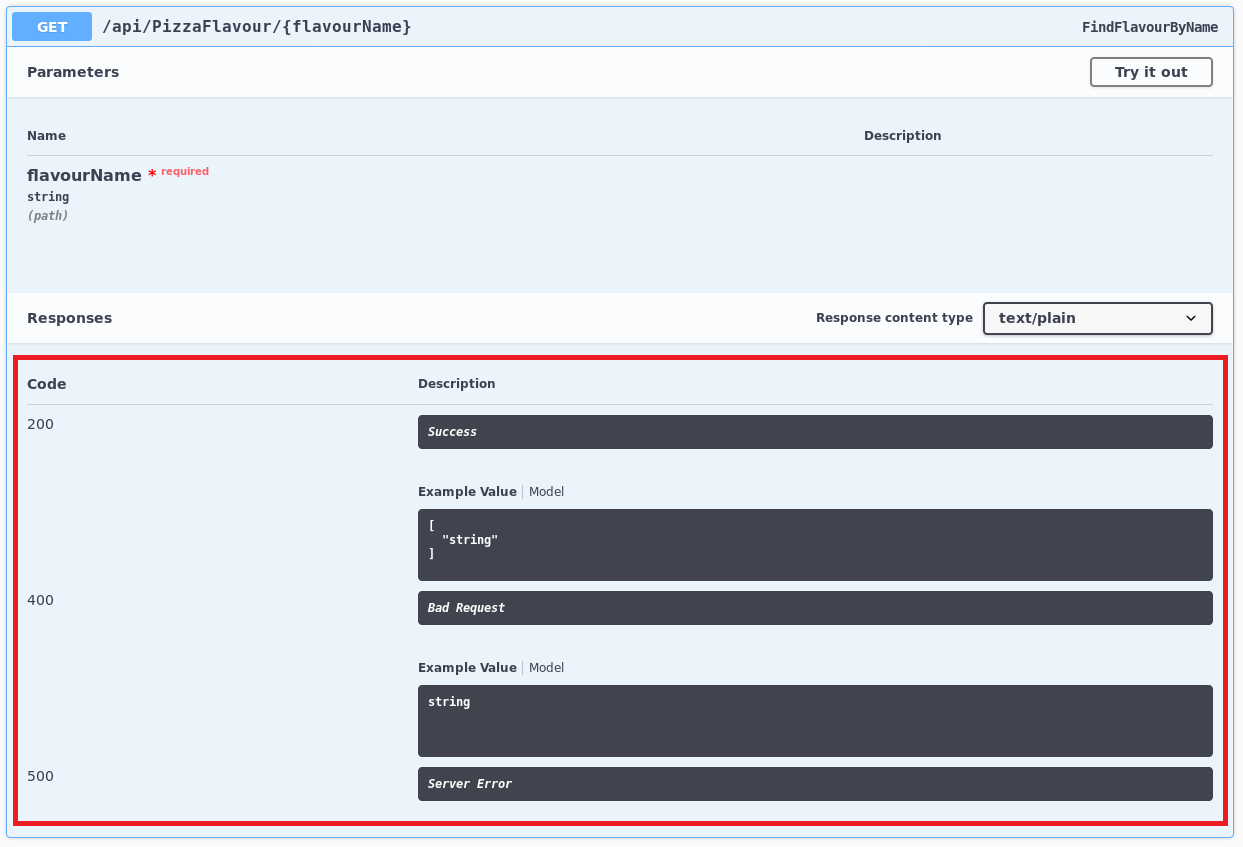
En utilisant l’attribut ProducesResponseTypeAttribute, on peut indiquer toutes les réponses possibles d’une action. Swagger peut prendre en compte ces réponses dans la description d’une action.
Par exemple en rajoutant cet attribut dans l’action suivante:
[HttpGet("{flavourName}", Name = "FindFlavourByName")]
[ProducesResponseType(typeof(IEnumerable<string>), 200)]
[ProducesResponseType(typeof(string), 400)]
[ProducesResponseType(500)]
public ActionResult<IEnumerable<string>> FindFlavour(string flavourName)
{
// ...
}
On obtient l’affichage suivant:
Attributs FromQueryAttribute et FromBodyAttribute
Les attributs FromQueryAttribute et FromBodyAttribute permettent d’indiquer explicitement si le paramètre d’une action doit se trouver dans l’URL de la requête ou dans le corps d’un message HTTP. Ces attributs sont pris en compte par Swagger dans sa description.
Par exemple, si on utilise ces paramètres de la façon suivante:
[HttpGet("{flavourName}", Name = "FindFlavourByName")]
public ActionResult<IEnumerable<string>> FindFlavour([FromQuery]string flavourName)
{
// ...
}
[HttpPost(Name = "AddPizzaFlavour")]
public ActionResult<int> Post([FromBody]AddPizzaFlavourRequest request)
{
// ...
}
On obtient l’affichage suivant dans Swagger:
Indiquer un paramètre obligatoire
On peut utiliser l’attribut BindRequiredAttribute sur le paramètre d’une action ou l’attribut RequiredAttribute sur les propriétés d’une DTO pour indiquer explicitement que le paramètre est obligatoire.
Par exemple en utilisant l’attribut BindRequiredAttribute pour les actions suivantes:
[HttpGet("{flavourName}", Name = "FindFlavourByName")]
public ActionResult<IEnumerable<string>> FindFlavour([FromQuery, BindRequired]string flavourName)
{
// ...
}
[HttpPost(Name = "AddPizzaFlavour")]
public ActionResult<int> Post([FromBody, BindRequired]AddPizzaFlavourRequest request)
{
// ...
}
On obtient l’affichage:
Indiquer des metadonnées avec des attributs Swagger
Avec les méthodes précédentes, on a précisé les métadonnées d’une API en utilisant:
Il est possible de préciser ces informations en utilisant des attributes spécifiques à Swagger. Les informations seront reconnues et utilisées pour enrichir les métadonnées de l’API de la même façon qu’avec la méthode précédente.
Les attributs spécifiques à Swagger utilisés par la suite suivants, se trouvent dans le namespaceSwashbuckle.AspNetCore.Annotations, il faut les utiliser en précisant dans l’entête du fichier .cs:
using Swashbuckle.AspNetCore.Annotations;
SwaggerOperationAttribute
Cet attribut est l’équivalent des commentaires XML pour préciser des informations concernant une action.
Par exemple, en utilisant SwaggerOperationAttribute dans le code suivant:
[HttpGet("{flavourName}", Name = "FindFlavourByName")]
[SwaggerOperation(
Summary = "Returns the ingredients from a flavour name",
Description = "Returns the ingredients",
OperationId = "FindFlavour")]
public ActionResult<IEnumerable<string>> FindFlavour([FromQuery, BindRequired]string flavourName)
{
// ...
}
Le résultat est le même que dans le cas des commentaires XML:
L’élément Tag permet d’indiquer dans quelle partie sera rangée l’action.
Par exemple, si on précise les tags "Flavour" et "Pizza", l’action sera rangée dans les parties "Flavour" et "Pizza"
[HttpGet("{flavourName}", Name = "FindFlavourByName")]
[SwaggerOperation(
Summary = "Returns the ingredients from a flavour name",
Description = "Returns the ingredients",
OperationId = "FindFlavour",
Tags = new[] { "Flavour", "Pizza" }
)]
public ActionResult<IEnumerable<string>> FindFlavour([FromQuery, BindRequired]string flavourName)
{
// ...
}
Le résultat sera:
Il est possible préciser d’autres éléments en utilisant SwaggerOperationAttribute comme:
Consumes pour préciser les types MIMES que l’action peut consumer.
Produces pour préciser les types MIMES que l’action peut générer.
Schemes pour indiquer les protocoles de transfert supportés par l’action.
SwaggerResponseAttribute
Cet attribut permet d’indiquer des informations sur les réponses possibles. Il est équivalent à l’attribut ProducesResponseTypeAttribute.
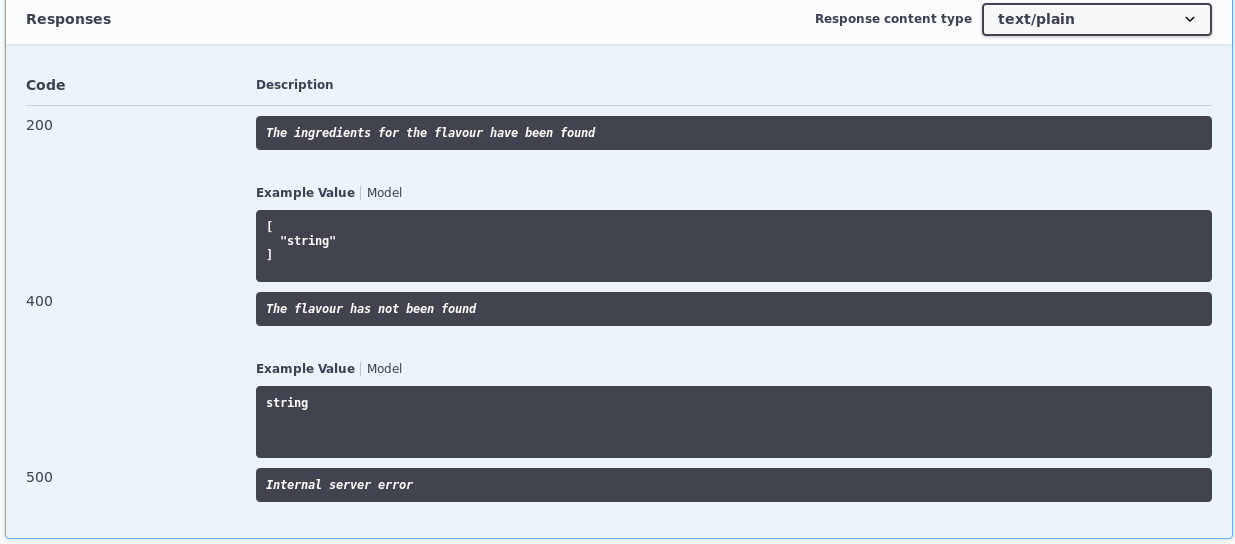
Par exemple en utilisant SwaggerResponseAttribute dans le code suivant:
[HttpGet("{flavourName}", Name = "FindFlavourByName")]
[SwaggerResponse(200, "The ingredients for the flavour have been found", typeof(IEnumerable<string>))]
[SwaggerResponse(400, "The flavour has not been found", typeof(string))]
[SwaggerResponse(500, "Internal server error")]
public ActionResult<IEnumerable<string>> FindFlavour([FromQuery, BindRequired]string flavourName)
{
// ...
}
Le résultat de cet exemple est du type:
SwaggerParameterAttribute
Cet attribut permet de fournir des informations sur les paramètres d’une action. Il est l’équivalent de l’attribut BindRequiredAttribute, toutefois il permet d’indiquer d’apporter une précision supplémentaire comme le nom du paramètre.
Par exemple si on utilise l’attribut SwaggerParameterAttribute dans le code suivant:
[HttpGet("{flavourName}", Name = "FindFlavourByName")]
public ActionResult<IEnumerable<string>> FindFlavour(
[FromQuery, SwaggerParameter("Flavour name", Required = true)]string flavourName)
{
// ...
}
Le résultat de cet exemple est du type:
SwaggerTagAttribute
Cet attribut permet de préciser des informations supplémentaires concernant le controller.
Par exemple, en utilisant l’attribut sur la classe du controller:
[Route("api/[controller]")]
[ApiController]
[SwaggerTag("Get or create new flavour for pizzas")]
public class PizzaFlavourController : ControllerBase
{
// ...
}
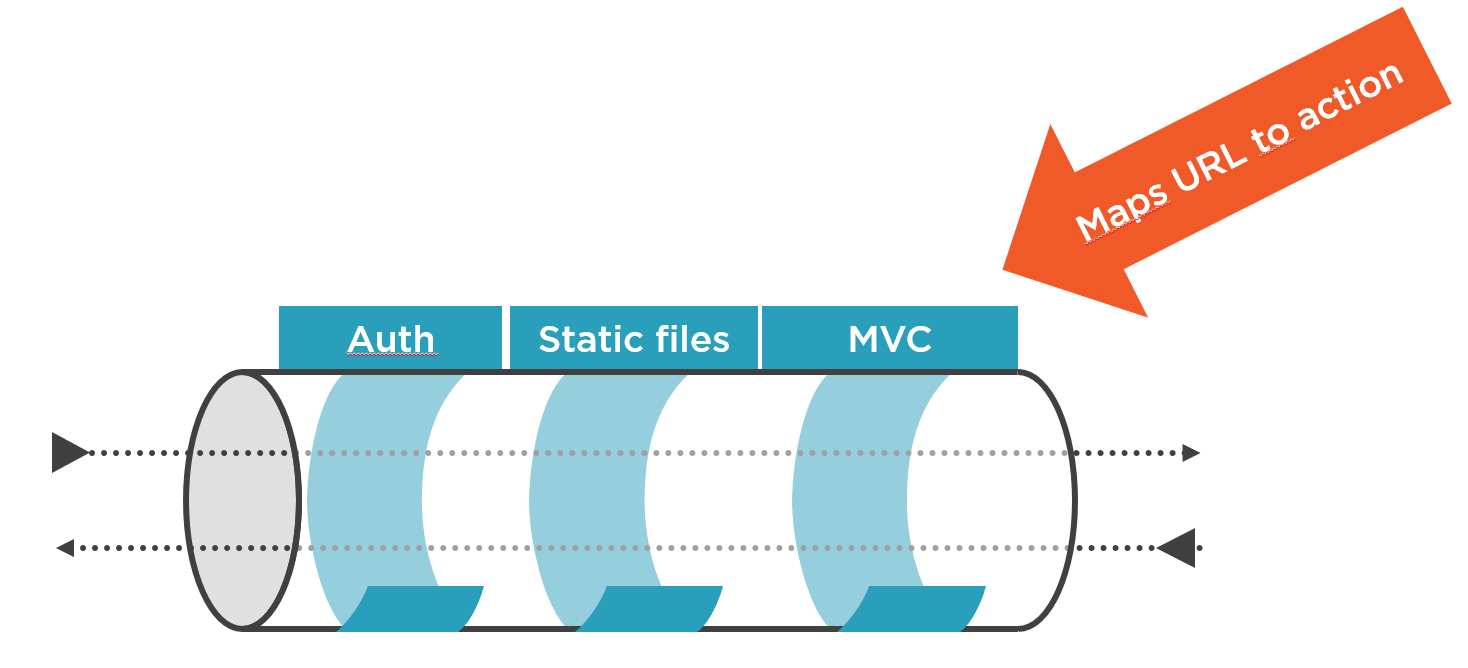
Quand on utilise la technologie ASP.NET Core pour implémenter une application web, il est possible d’utiliser le middleware et le pattern MVC (i.e. Model-View-Controler) pour organiser les classes qui répondront aux différentes requêtes HTTP. ASP.NET Core permet de router les requêtes vers les bonnes instances d’objets à condition que le “routage” soir configuré. Dans le cadre de MVC, cette fonctionnalité de “routage” (i.e. routing) va ainsi permettre de trouver le controller et l’action dans le controller qui sera évoquée en fonction de l’adresse web de la requête HTTP.
Le but de cet article n’est pas de paraphraser la documentation mais d’être un aide-mémoire sur les principales caractéristiques du routage. La documentation de Microsoft permet d’avoir des détails plus exhaustifs sur tous les aspects du routage.
Lorsqu’une requête HTTP est adressée à une application web ASP.NET Core, elle traverse différentes couches de l’application en utilisant le pipeline de middlewares. Ces middlewares sont évoqués successivement et permettent d’adresser différents points techniques liés à la requête comme par exemple la gestion d’erreurs, la gestion des cookies, l’authentification, la gestion de sessions etc… L’exécution successive des différents middlewares aboutira le cas échéant à créer une réponse à la requête. Le routage est l’un de ces middlewares.
Après avoir exécuté les middlewares précédents, la requête parvient au middleware routing (correspond aux classes dans le namespace Microsoft.AspNetCore.Routing) qui va effectuer les étapes suivantes:
Parser l’URL pour déterminer les différents paramètres de la requête.
En fonction des paramètres, trouver la route parmi les différentes routes configurées qui permettra de répondre à la requête.
Si une route est trouvée alors la requête est passée à une classe satisfaisant IRouteHandler (dans Microsoft.AspNetCore.Routing). Par défaut, la classe RouteHandler.
Si aucune route n’est trouvée, la requête est passée au middleware suivant.
Ainsi, le middleware routing est composé de différents objets:
Les routes (la classe correspondante est Route): elles définissent les différentes chemin de routage que pourrait emprunter la requête.
Par exemple, une route pourrait être définie en utilisant l’expression:
"{controller=Home}/{action=Index}/{id?}"
Une liste de routes (i.e. route collection): les routes sont testées successivement parmi cette liste pour déterminer qu’elle est la première qui convient. Si une route convient aux paramètres de la requête, les routes suivantes ne sont pas testées.
IRouter: la classe satisfaisant cette interface va être appelée pour déterminer quelle classe va traiter la requête pour en générer une partie de la réponse. Dans le cas d’une application ASP.NET Core MVC, le route handler, par défaut, est la classe MvcRouteHandler.
Cette classe va chercher le controller et l’action dans le controller à évoquer pour générer une réponse.
Ces différents objets doivent être configurés pour que le routage s’effectue correctement.
Configurer les routes
Routage basique
Pour configurer un routage par défaut, il faut d’abord ajouter les services MVC pour indiquer que l’application ASP.NET Core utilisera ce pattern dans la classe Startup servant à la configuration initiale:
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc().SetCompatibilityVersion(CompatibilityVersion.Version_2_2);
// ...
}
}
SetCompatibilityVersion(CompatibilityVersion.Version_2_2) permet d’indiquer qu’on utilise une logique de routage compatible avec celle d’ASP.NET Core 2.2.
On indique ensuite, qu’on souhaite utiliser le middleware de routage et on l’ajoute au pipeline de middleware avec la ligne:
public class Startup
{
public void Configure(IApplicationBuilder app)
{
app.UseMvc();
}
}
UseMvc() ajoute le middleware de routage mais ne configure aucune route. Pour configurer une route par défaut, il faut utiliser la méthode (on explicitera par la suite quelle est la route par défaut):
app.UseMvcWithDefaultRoute();
Les 2 ajouts sont nécessaires services.AddMvc() et app.UseMvc().
Template d’une route
Par défaut, dans le cadre de MVC, une route se définit en indiquant un template. Ce template contient des indications concernant:
Le controller qui implémente le code permettant de construire la réponse à la requête,
L’action c’est-à-dire la fonction dans le controller qui sera exécutée pour générer la réponse,
Eventuellement des arguments nécessaires à l’exécution de l’action.
De façon générique, une route se définit en indiquant les différents éléments successivement:
"{controller}/{action}/{id}"
L’utilisation de { } permet d’indiquer qu’un élément n’a pas une valeur fixe.
Par exemple, le template de la route définie précédemment sera utilisée si l’adresse appelée est du type:
pizzaOrder/get/23
Dans ce cas:
{controller} est égal à pizzaOrder,
{action} est égal à get et
{id} est égal à 23
Elément à valeur fixe
On peut indiquer qu’un élément de l’adresse a une valeur fixe. Par exemple, si le template de la route est:
admin/{controller}/{action}/{id}
admin est fixe et toutes les adresses devront commencer par admin pour être prise en compte par la route. Par exemple:
admin/pizzaOrder/get/23
Elément facultatif
On peut indiquer qu’un élément est facultatif en utilisant ?, par exemple:
"{controller}/{action}/{id?}"
Cette route correspond à des adresses du type:
pizzaOrder/list
pizzaOrder/list/12
Element par défaut
Si un élément n’est pas précisé, alors la valeur par défaut sera utilisée. Pour préciser la valeur par défaut, il faut utiliser le caractère =<valeur par défaut>, par exemple:
"{controller}/{action=index}/{id?}"
Dans ce cas, l’action par défaut sera index.
Si on utilise l’adresse:
pizzaOrder
L’adresse équivalente sera: pizzaOrder/index (l’élément id étant facultatif).
Mise à part controller, action d’autres mots clés peuvent désigner des éléments précis dans l’application ASP.NET Core comme area, handler et page.
Template par défaut
Si on utilise app.UseMvcWithDefaultRoute() dans StartUp.Configure(), le template par défaut utilisé est:
"{controller=Home}/{action=Index}/{id?}"
Ajouter une route
L’ajout explicite d’une route se fait en utilisant l’une des surcharges suivantes dans StartUp.Configure():
app.UseMvc(routes => {
routes.MapRoute("<nom unique de la route>", "<template de la route>");
});
Par exemple:
public class Startup
{
public void Configure(IApplicationBuilder app)
{
app.UseMvc(routes => {
routes.MapRoute("default", "{controller}/{action=index}");
});
}
}
Le template de la route est "{controller}/{action}" et les valeurs par défaut sont "Home" pour le controller et "Index" pour l’action.
Pour préciser des contraintes sur les éléments:
routes.MapRoute("Home", "{controller}/{action}",
defaults: new { Controller = "Home", Action = "Index" },
constraints: new { id = new IntRouteConstraint() });
La contrainte impose que l’élément id doit être un entier.
D’autres contraintes existent comme:
Pour imposer une contrainte sur le type: BoolRouteConstraint, DateTimeRouteConstraint, DecimalRouteConstraint, DoubleRouteConstraint, GuidRouteContraint, FloatRouteConstraint ou LongRouteConstraint.
Pour imposer une contrainte sur la longueur d’une chaîne de caractères: MinLengthRouteConstraint ou MaxLengthConstraint
Pour imposer une contrainte sur une valeur: MinRouteConstraint, MaxRouteConstraint ou RangeRouteConstraint.
Pour imposer une contrainte avec une regex: RegexInlineRouteConstraint.
Ordre d’ajout des routes
L’ordre d’ajout des routes est important puisque le parcours des routes dans la liste de routes se fera dans l’ordre d’ajout de celles-ci.
Contrainte sur un élément d’une route
Il est possible d’indiquer des contraintes concernant un élément dans le template d’une route. Par exemple, si on considère le template de route suivant:
"{controller}/{action}/{id}"
Si on souhaite ajouter des contraintes sur le paramètre id, il faut utiliser la syntaxe suivante:
Par exemple pour indiquer que le paramètre id doit être de type entier, on utilise la syntaxe:
"{controller}/{action}/{id:int}"
Contraintes de type
Pour contraindre le type d’un paramètre, on peut utiliser les syntaxes suivantes:
Entier
{id:int}
Alphabétique (caractères de A à Z et a à z seulement)
{id:alpha}
bool
{id:bool}
DateTime
{id:datetime}
decimal
{id:decimal}
double
{id:double}
GUID
{id:guid}
float
{id:float}
Contraintes de valeurs
Pour contraindre un paramètre à avoir des valeurs dans un intervalle spécifique:
Chaine de caractères d’une longueur minimum (par exemple 5 caractères)
{id:minlength(5)}
Chaine de caractères d’un longueur maximum (par exemple 10 caractères)
{id:maxlength(10)}
Chaine de caractères de longueur spécifique (par exemple 7 caractères)
{id:length(7)}
Chaine de caractères de longueur bornée (par exemple comprise entre 4 et 9 caractères)
{id:length(4, 9)}
Entier supérieur ou égal (par exemple 5)
{id:min(5)}
Entier inférieur ou égal (par exemple 14)
{id:max(14)}
Entier compris dans un interval borné (par exemple entre 3 et 9)
{id:range(3, 9)}
Contrainte avec une regex
Pour contraindre un paramètre à respecter une regex:
"{id:regex(<regex>)}"
Par exemple:
"{id:regex(^2019$)}"
Il faut utiliser des caractères d’échappement quand on utilise \,{, }, [ ou ]. Par exemple la regex^\d{5}$ doit s’écrire:
"{id:regex(^\\d{{5}}$)}"
Définition des routes avec des attributs
Il n’est pas obligatoire de préciser des routes en utilisant un template comme dans le paragraphe précédent. On peut utiliser des attributs placés sur:
un controller et/ou
une action d’un controller
Pour définir les routes par attributs, il faut utiliser la fonction suivante dans StartUp.Configure():
public class Startup
{
public void Configure(IApplicationBuilder app)
{
app.UseMvc();
}
}
RouteAttribute
Au niveau d’un controller
L’attribut RouteAttribute peut être utilisé au niveau d’un controller pour définir une route:
[Route("PizzaOrder")]
public class PizzaOrderController : Controller
{
// ...
}
Ce controller sera appelé dès que l’adresse commence par PizzaOrder.
Au niveau d’une action
RouteAttribute peut aussi être utilisé au niveau d’une action:
[Route("PizzaOrder")]
public class PizzaOrderController : Controller
{
[Route("Index")]
public IActionResult Index()
{
// ...
}
}
L’action sera appelée si l’adresse est: PizzaOrder/Index.
Utilisation de “tokens” de remplacement
On peut utiliser des tokens pour éviter d’avoir à préciser le nom du controller ou de l’action. Au lieu d’indiquer le nom du controller ou de l’action, on utilise:
[controller] pour désigner le nom du controller
[action] pour désigner le nom de l’action.
[area] pour indiquer le nom de la zone.
Par exemple:
[Route("[controller]")]
public class PizzaOrderController : Controller
{
[Route("[action]")]
public IActionResult Index()
{
// ...
}
}
On peut aussi tout préciser directement au niveau du controller:
[Route("[controller]/[action]")]
public class PizzaOrderController : Controller
{
public IActionResult Index()
{
// ...
}
}
La définition des routes se combinent
Les attributs utilisés au niveau d’un controller et d’une action se combinent toutefois il est aussi possible d’utiliser plusieurs attributs au même niveau. Par exemple si on indique:
[Route("PizzaOrder")]
public class PizzaOrderController : Controller
{
[Route("")]
[Route("Index")]
[Route("/")]
public IActionResult Index()
{
// ...
}
}
L’actionIndex() est appelée si pour les adresses:
PizzaOrder à cause de [Route("PizzaOrder")] et [Route("")]
PizzaOrder/Index à cause de [Route("PizzaOrder")] et [Route("Index")]
"" (ou rien) à cause de [Route("PizzaOrder")] et [Route("/")]
HttpGetAttribute, HttpPostAttribute, HttpPutAttribute et HttpDeleteAttribute
Pour configurer Swashbuckle, il faut ajouter les lignes suivantes dans StartUp.cs:
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddSwaggerGen(c =>
{
// Permet de préciser de la documentation
c.SwaggerDoc("v1", new Info { Title = "My API", Version = "v1" });
});
}
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
app.UseSwagger();
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("/swagger/v1/swagger.json", "My simple API V1");
});
}
}
On ajoute les controllers suivants dans le répertoire Controllers:
La route "secure" permet d’appeler toujours le controllerAdminController avec l’actionGetOrders. Pour l’invoquer il suffit d’effectuer une requête GET à l’adresse: http://localhost:5000/secure
La route "admin" permet de définir une route plus générale pour appeler le controllerAdminController. Par exemple pour appeler l’actionDeleteOrder, il faut effectuer une requête GET à l’adresse http://localhost:5000/admin/DeleteOrder/1
La route "default" définit une route plus générale pour appeler les controllersPizzaFlavourController et PizzaOrderController.
Par exemple pour appeler l’actionFindFlavour dans le controllerPizzaFlavourController, il faut effectuer une requête GET à l’adresse http://localhost:5000/PizzaFlavour/FindFlavour/Regina
Utiliser cURL ou postman
Dans cet exemple, pour illustrer l’utilisation des templates, on a supprimé les attributs dans les controllerAdminController et PizzaFlavourController. A cause de cette suppression, les fonctions ne sont plus visibles dans Swagger toutefois elles sont toujours fonctionnelles. Pour les invoquer, il faut utiliser:
cURL: par exemple exécutant à la ligne de commandes:
curl -X GET "http://localhost:5000/PizzaFlavour/FindFlavour/Regina" -H "accept: text/plain"
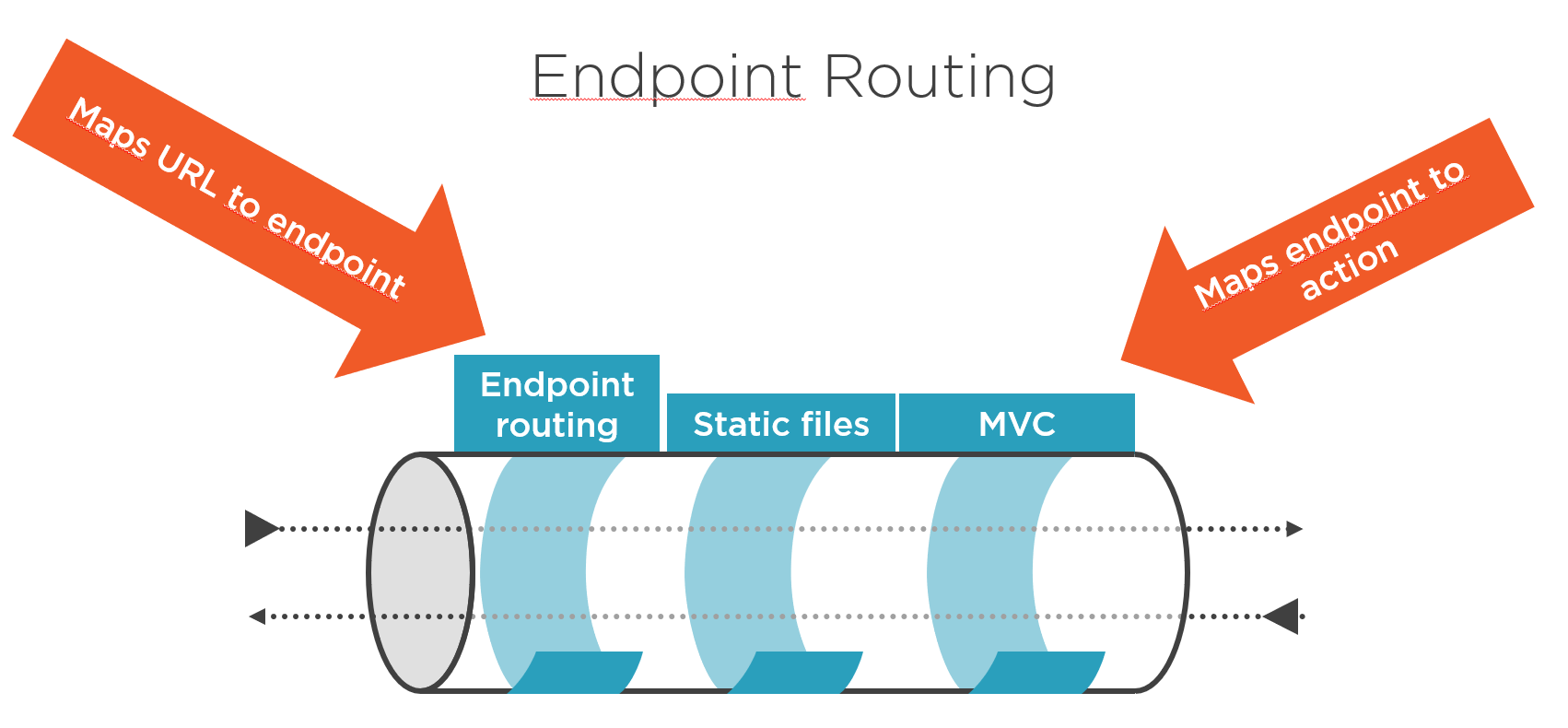
Le middleware permettant d’effectuer le routage n’est plus le même à partir d’ASP.NET Core 2.2. Jusqu’à ASP.NET Core 2.1, le routage de l’URL vers le controller et l’action était effectué au niveau du middleware MVC. A partir d’ASP.NET Core 2.2, le routage est fait plus en amont et avant l’exécution du middleware MVC dans le pipeline, il est effectué par un middleware spécial appelé “Endpoint Routing”.
Ainsi, à partir d’ASP.NET Core 2.2, il faut ensuite désactiver le routage par point de terminaison pour que le routage s’effectue avec IRouter avec la ligne suivante:
Le but de cet article est d’illustrer l’import de bibliothèques externes Javascript dans du code Typescript. Il fait suite à un article précédent qui expliquait comment on pouvait séparer le code Typescript en modules (cf. Les modules en Typescript en 5 min).
Le compilateur Typescript permet de générer du code Javascript exécutable sur tous les browsers. Un des gros intérêts d’implémenter en Typescript est d’abord d’avoir un typage fort et ensuite de permettre au compilateur d’effectuer une vérification syntaxique. Le code Javascript généré est ainsi plus robuste puisque une vérification des types a déjà été effectuée à la compilation.
L’écosystème Javascript est très riche en bibliothèques. Ces bibliothèques sont couramment utilisées pour enrichir une application Javascript. Toutefois la plupart d’entre elles ne sont pas implémentées en Typescript. Heureusement il existe quelques méthodes pour utiliser ces bibliothèques Javascript et continuer à tirer partie des avantages de la compilation Typescript. Dans cet article, on va présenter quelques méthodes les plus courantes.
Dans un premier temps, on va indiquer la solution utilisée pour permettre l’import de bibliothèques externes au niveau de la syntaxe Typescript. Dans un 2e temps, on indiquera les méthodes les plus courantes pour mettre en pratique cette solution.
Avant de rentrer dans les détails, on va expliquer comment il est possible d’importer du code Javascript dans du code Typescript.
Mot-clé “declare”
Comme on l’a indiqué plus haut, le compilateur Typescript effectue une vérification des types des objets. Le type de tous les objets ainsi que celui les dépendances sont vérifiés, il devient alors plus compliqué d’importer du code Javascript qui n’est pas obligatoirement fortement typé. Pour palier à ce problème, le mot-clé declare permet de déclarer des variables ne provenant pas de code Typescript. Il donne ainsi la possiblité d’introduire dans du code Typescript, des types provenant de code Javascript. Le compilateur n’ira pas effectuer des vérifications dans le code Javascript, toutefois il prendra en compte le type déclaré pour vérifier le code Typescript.
Par exemple si on écrit:
declare var externalLibrary;
On peut introduire une variable nommée externalLibrary de type any qui pourra être utilisée dans le code Typescript comme si on l’avait déclaré de cette façon:
var externalLibrary: any;
Le code Javascript généré est le même, toutefois utiliser declare permet d’indiquer qu’il s’agit de l’import d’un objet défini de façon externe.
Il faut avoir à l’esprit que declare permet seulement d’indiquer au compilateur le type d’une variable sans explicitement indiquer l’implémentation. Il part du principe que l’implémentation Javascript correspondante devra être fournie à l’exécution.
Ainsi en fonction des déclarations de types indiquées avec declare, le compilateur ne fera que vérifier la syntaxe Typescript, il ne “transpile” en Javascript que le code Typescript. Si l’implémentation Javascript correspondant aux types déclarés n’est pas présente, l’exécution provoquera des erreurs.
Le mot-clé declare permet de déclarer tous les types d’objets comme le ferait, par exemple, une interface par rapport à une classe.
Pour déclarer une variable de type any:
declare var variableName: any;
Pour déclarer la signature d’une fonction:
declare function DecodeValue(valueName: string): void;
Pour déclarer une classe:
declare class Person {
constructor(name: string, firstName: string);
showPersonName(): void;
}
Pour déclarer un module ou un namespace:
declare namespace ExternalDependency {
class Person {
constructor(name: string, firstName: string);
showPersonName(): void;
}
class Player {
constructor(person: Person);
showPlayerName(): void;
}
function CreatePlayer(name: string, firstName: string): Player;
}
module et namespace sont équivalents
Les mot-clés module et namespace sont équivalents (cf. Namespaces en Typescript), on peut aussi écrire:
declare module ExternalDependency {
...
}
On peut associer les mot-clé export et declare pour indiquer l’export d’un module et de tous les éléments qui s’y trouvent.
Ainsi:
export declare namespace ExternalDependency {
class Person {
constructor(name: string, firstName: string);
showPersonName(): void;
}
class Player {
constructor(person: Person);
showPlayerName(): void;
}
function CreatePlayer(name: string, firstName: string): Player;
}
Est équivalent à:
export namespace ExternalDependency {
export class Person {
constructor(name: string, firstName: string);
showPersonName(): void;
}
export class Player {
constructor(person: Person);
showPlayerName(): void;
}
export function CreatePlayer(name: string, firstName: string): Player;
}
Fichier de définition (declaration file)
Dans le cas d’une bibliothèque, tous les types Javascript peuvent être déclarés dans un seul fichier appelé “fichier de définition” (i.e. declaration file). Ces fichiers ont usuellement l’extension .d.ts toutefois rien n’oblige à utiliser cette extension. N’importe quelle déclaration peut être implémentée dans un fichier .ts.
Les fichiers de définition .d.ts peuvent être référencés avec une directive triple-slash (cf. Directive “triple-slash”) au même titre qu’un fichier .ts normal, par exemple:
/// <reference path="declarationFile.d.ts" />
Ainsi quand on doit utiliser une bibliothèque Javascript dans du code Typescript, on peut référencer les fichiers de définition correspondant à cette bibliothèque.
Générer un fichier de définition
Le compilateur Typescript permet de générer un fichier de définition à partir du code Typescript en écrivant:
tsc --declaration <chemin des fichiers .ts>
Ou
tsc –d <chemin des fichiers .ts>
On peut préciser un répertoire de sortie pour ces fichiers:
tsc --declaration <chemin des fichiers .ts> --declarationDir <répertoire de sortie>
Exemple d’utilisation de “declare”
On se propose d’illustrer l’import d’un fichier de définition avec un exemple. Le but de cet exemple est d’importer du code Javascript dans du code Typescript en utilisant un fichier de définition. Le code de la bibliothèque se trouve dans les fichiers dependency.ts ou dependency.js.
Code sur GitHub
Le code de cet article se trouve dans le repository GitHub suivant: github.com/msoft/external_typescript_modules.
Le code se trouve dans des branches différentes suivant la partie de l’article qu’il illustre:
Branche 1_initial: code initial permettant de compiler du code Typescript.
Ainsi on considère le code suivant permettant d’importer un module:
import { Person, Player, CreatePlayer } from "./dependency.js";
class Startup {
public static main(): number {
var player = new Player(new Person('Buffon', 'Gianluigi'));
player.showPlayerName();
return 0;
}
}
Startup.main();
Le module se trouve dans le fichier dependency.ts (la directive d’import utilise l’extension .js dans le code Typescript car le compilateur ne change pas les extensions à la compilation(1)(2)).
Le fichier dependency.ts contient le code suivant:
export class Person {
constructor(private name: string, private firstName: string) {
}
public showPersonName(): void {
console.log("Name: " + this.name + "; First Name: " + this.firstName);
}
}
export class Player {
constructor(private person: Person) {
}
public showPlayerName(): void {
this.person.showPersonName();
}
}
export function CreatePlayer(name: string, firstName: string): Player {
return new Player(new Person(name, firstName));
}
Le fichier public/index.html qui va permettre de lancer l’exécution (il ne fait que déclarer les fichiers Javascript contenant le code) est:
Pour afficher la console de développement dans un browser
Pour tous les exemples présentés dans cet article, pour voir les résultats d’exécution, il faut afficher la console de développement:
Sous Firefox: on peut utiliser la raccourci [Ctrl] + [Maj] + [J] (sous MacOS: [⌘] + [Maj] + [J], sous Linux: [Ctrl] + [Maj] + [K]) ou en allant dans le menu “Développement web” ⇒ “Console du navigateur”.
Sous Chrome: utiliser le raccourci [F12] (sous MacOS: [⌥] + [⌘] + [I], sous Linux: [Ctrl] + [Maj] + [I]) puis cliquer sur l’onglet “Console”. A partir du menu, il faut aller dans “Plus d’outils” ⇒ “Outils de développement”.
Sous EDGE: utiliser le raccourci [F12] puis naviguer jusqu’à l’onglet “Console”.
Le résultat de l’exécution est du type:
Name: Buffon; First Name: Gianluigi
On modifie le code de dependency.ts pour qu’il ne contienne que des déclarations de types (on supprime toutes les implémentations):
On modifie le code de cette façon:
declare namespace ExternalDependency {
class Person {
constructor(name: string, firstName: string);
showPersonName(): void;
}
class Player {
constructor(person: Person);
showPlayerName(): void;
}
function CreatePlayer(name: string, firstName: string): Player;
}
On déplace ensuite ce fichier dans le répertoire ExternalDependency/index.d.ts:
On importe ensuite ce fichier dans index.ts en utilisant une directive triple-slash et en supprimant la directive d’import de module:
/// <reference path="ExternalDependency/index.d.ts" />
class Startup {
public static main(): number {
var player = ExternalDependency.CreatePlayer('Buffon', 'Gianluigi');
player.showPlayerName();
return 0;
}
}
Startup.main();
Si on compile, on s’aperçoit qu’il n’y a pas d’erreurs de compilation. Il n’existe plus d’implémentation des classes Player et Person pourtant la compilation se passe correctement.
En revanche si on tente d’exécuter le code en rafraichissant le browser:
index.js:24 Uncaught ReferenceError: ExternalDependency is not defined
at Function.Startup.main (index.js:24)
at index.js:30
Ceci s’explique par le fait, qu’il n’y a pas de références vers le code Javascript correspondant aux classes Player et Person.
On modifie le code de dependency.ts pour encapsuler les classes Player et Person dans un module et on exporte seulement la fonction CreatePlayer():
module ExternalDependency {
class Person {
constructor(private name: string, private firstName: string) {
}
public showPersonName(): void {
console.log("Name: " + this.name + "; First Name: " + this.firstName);
}
}
class Player {
constructor(private person: Person) {
}
public showPlayerName(): void {
this.person.showPersonName();
}
}
export function CreatePlayer(name: string, firstName: string): Player {
return new Player(new Person(name, firstName));
}
}
On lance la compilation en exécutant:
npm run build
Pour rajouter une référence vers le code Javascript des classes Player et Person, on déplace au bon endroit le fichier Javascript dependency.js compilé précédemment:
On modifie ensuite le fichier public/index.html pour qu’il ne référence plus les fichiers Javascript sous forme de module ES6 (cf. Utilisation des modules ES2015):
Après avoir rafraîchi le browser, le résultat est le même que précédemment:
Name: Buffon; First Name: Gianluigi
Le but de cet exemple était d’illustrer l’utilisation d’un fichier de définition de façon à comprendre plus facilement leur utilisation par la suite.
Comment utiliser des fichiers de définition ?
Comme indiqué plus haut, ces fichiers servent à déclarer des types sans préciser l’implémentation. En effet l’implémentation de ces types est en Javascript et sera utilisable seulement pendant l’exécution. Les fichiers de définition contiennent le code Typescript permettant au compilateur de faire une vérification des types.
Ainsi la plupart des bibliothèques Javascript téléchargeables sous forme de modules avec npm possèdent des fichiers de définition. Il existe plusieurs façon d’obtenir ces fichiers. On va indiquer 2 méthodes pour télécharger ces fichiers.
Exemple avec jQuery et DataTables
Pour illustrer ces différentes méthodes, on se propose d’utiliser un exemple dans lequel on utilise jQuery et DataTables. L’exemple permet de remplir un tableau avec 2 lignes. En dessous du tableau se trouve un bouton. Si on clique sur ce bouton, le contenu de la cellule à la 2e ligne et 2e colonne est modifié.
Pour utiliser l’exemple:
On commence à partir d’un “squelette” vide ne contenant que webpack. Webpack est un outil permettant de compiler le code Typescript dans un seul fichier Javascript (appelé bundle). Webpack permet aussi d’exécuter le code en utilisant un serveur web de développement.
A ce stade, si on tente d’utiliser du code jQuery dans index.ts, le code ne compilera pas:
var data = [
[
"Tiger Nixon",
"System Architect",
"Edinburgh",
"5421",
"2011/04/25",
"$3,120"
],
[
"Garrett Winters",
"Director",
"Edinburgh",
"8422",
"2011/07/25",
"$5,300"
]
]
$(document).ready( function () {
var datatable = $('#table_id').DataTable({
data,
});
} );
Dans le code ci-dessus, jQuery est appelé avec l’instruction $(...) et le code de DataTables est appelé avec .DataTable(...).
Les instructions permettent de rajouter des données dans le tableau HTML nommé table_id se trouvant dans la page HTML index.html.
En lançant npm run build pour compiler, on obtient des erreurs de compilation:
ERROR in /home/user/external_typescript_modules/webpack_es6/index.ts
./index.ts
[tsl] ERROR in /home/user/external_typescript_modules/webpack_es6/index.ts(9,15)
TS2451: Cannot redeclare block-scoped variable '$'.
ℹ 「wdm」: Failed to compile.
Les méthodes suivantes permettent de corriger ces erreurs.
Utiliser “any”
Cette méthode est la plus simple toutefois elle est la plus risquée. Elle consiste à déclarer le type any pour l’objet de plus haut niveau dans la bibliothèque, par exemple en indiquant dans le fichier index.ts:
declare const $: any;
L’erreur de compilation disparaît, toutefois il faut avoir en tête qu’il n’y aucune vérification de syntaxe sur toutes les déclarations suivant $. On peut écrire n’importe quoi après $, il n’y aura pas d’erreurs de compilation. Cette solution est donc à utiliser pour tester rapidement une bibliothèque mais elle est à proscrire pour produire du code de production.
Installer les fichiers de définition avec npm
Le domaine types de la commande npm permet d’installer les fichiers de définition dans le répertoire node_modules/@types/<nom du package>. Pour installer ces fichiers, on peut exécuter la commande:
npm install @types/<nom du package> --save-dev
Cette commande va installer les fichiers de définition et indique ce package dans la partie devDependencies du fichier package.json.
Dans la plupart des cas pour télécharger les fichiers de définition pour un package donné, il suffit d’installer le package avec le nom @types/<nom du package>. Ce n’est pas toujours le cas, ainsi pour retrouver le package contenant les fichiers de définition pour un package donné, on peut utiliser TypeSearch.
Il faut privilégier l’installation de fichiers de définition avec npm
Cette méthode est actuellement la méthode la plus usuelle pour télécharger les fichiers de définition. Cette fonctionnalité n’est disponible qu’à partir de Typescript 2.0.
Les fichiers de définition dans le domaine @types de npm proviennent du repository GitHub DefinitelyTyped qui est un référentiel contenant les fichiers de définition pour les packages les plus courants.
Dans le cas de notre exemple, on peut installer les fichiers de définition de jQuery et DataTables en exécutant:
Pour des versions de Typescript antérieures à la version 2.0 ou pour obtenir des fichiers de définition pour des packages qui ne sont pas disponibles dans le domaine @types de npm, on peut passer par typings.
typings est un outil disponible avec la ligne de commandes qui possède de nombreuses fonctionnalités pour télécharger les fichiers de définition à partir de sources différentes.
Import sous forme de module externe
Par défaut typings considère que l’import des types de définition se fait sous forme de module externe Typescript. Typings encapsule, ensuite la définition des types dans un module avec des déclarations du type:
declare module '<nom du module>' {
// Définition du type
// ...
}
Pour consommer le type dans le code Typescript, on peut utiliser des alias en utilisation la syntaxe:
import * as <alias utilisé> from '<nom du module>'
Un des intérêts de cette méthode est de pouvoir utiliser des versions différentes de fichiers de définition correspondant à des versions différentes de package. On peut, ainsi, utiliser un alias par version.
Dépendances globales
Typings considère certaines définitions de types comme étant globales pour différentes raisons:
Soit parce-qu’il ajoute les types au scope global,
Soit il ajoute des éléments nécessaires pour effectuer les builds (comme webpack ou browserify)
Soit il ajoute des éléments nécessaires à l’exécution (par exemple comme Node.js).
Pour installer des définitions globales, il faut utiliser l’option --global. Typings indique si l’installation de types doit se faire obligatoirement de façon globale.
Utiliser typings
Pour installer typings, on utilise npm en exécutant la commande:
npm install typings --global
Cette commande ajoute l’utilitaire typings dans le répertoire global de façon à ce qu’elle soit disponible sur la ligne de commandes.
Quelques commandes courantes de typings
Une fois que typings est installé, on peut l’utiliser directement à la ligne de commandes:
Pour chercher des définitions correspondant à un package à partir de son nom, on peut taper:
typings search --name <nom du package>
Pour chercher en fonction d’un mot clé:
typings search <éléments recherchés>
Pour installer des définitions à partir du nom du package:
typings install <nom du package> --save
L’option --save permet d’enregistrer le nom du package pour lequel les définitions ont été téléchargées dans le fichier typings.json dans le nœud json:
"dependencies" pour les packages externes classiques
"globalDependencies" pour les packages installés de façon globale.
Pour installer les définitions de façon globale, il faut rajouter l’option --global:
typings install <nom du package> --save --global
Pour indiquer la source:
typings install <nom de la source>~<nom du package> --save
Ou
typings install <nom du package> --source <nom de la source> --save
Par défaut, la source de typings est npm.
D’autres sources sont possibles, par exemple:
github pour récupérer des dépendances directement de GitHub (par exemple: Duo, JSPM).
Sans aucune mention supplémentaire, les types sont reconnus dans le code Typescript. Si on regarde les fichiers de types dans le répertoire typings, on remarque que le fichier typings/index.d.ts contient les lignes suivantes:
L’import de bibliothèques Javascript externes dans du code Typescript est quasiment incontournable. La méthode la plus usuelle pour intégrer des bibliothèques courantes est d’importer des fichiers de définition avec npm. D’autres méthodes existent, toutefois elles sont réservées aux cas particuliers. Par exemple quand on souhaite utiliser une version non disponible avec npm ou quand simplement les fichiers de définition ne sont pas fournis.
Cet article a tenté d’illustrer le plus simplement, l’utilisation du mot-clé declare et l’import de fichiers de définition avec npm.
Dans cet article, on cherche à proposer une implémentation d’un Timer en utilisant TPL (i.e. Task Parallel Library). Il existe une classe qui permet d’effectuer un traitement de façon périodique: System.Threading.Timer. Cette classe n’est pas très moderne puisqu’elle existe depuis les premières versions du Framework. Elle permet d’effectuer correctement un traitement périodique toutefois elle souffre de quelques défauts:
Cette classe est difficilement testable: les traitements asynchrones peuvent être difficiles à tester. C’est encore plus vrai avec System.Threading.Timer puisqu’on ne maitrise pas les itérations, elles sont déclenchées par l’écoulement du temps. Si on veut tester une périodicité de 30 min, il faut attendre 30 min que l’itération s’exécute.
Elle ne permet pas de tirer partie des avantages de TPL: gestion des exceptions, gestion de l’annulation de l’exécution, continuation, options de création des Task etc…
Il existe d’autres implémentations d’une tâche périodique toutefois elles présentent les mêmes inconvénients que System.Threading.Timer:
System.Timers.Timer
System.Windows.Forms.Timer utilisable dans le cadre de Windows Forms.
System.Windows.Threading.DispatcherTimer en WPF.
Le code correspondant à cet article se trouve dans le repository GitHub msoft/PeriodicTask.
Exemple avec System.Threading.Timer
Comme indiqué plus haut, on souhaite utiliser la flexibilité de TPL pour apporter une implémentation d’une tâche périodique.
Avant de commencer, voici un exemple rapide de l’implémentation d’une tâche périodique avec System.Threading.Timer (cf. classe SimpleTimerUsage). Cet exemple sert de base pour l’implémentation avec TPL. Le code “métier” exécuté de façon périodique est dans ExecuteJob():
public class SimpleTimerUsage : IDisposable
{
private readonly ILogger logger;
private Timer timer;
public SimpleTimerUsage(ILogger logger, int periodicity)
{
this.logger = logger;
this.timer = new Timer(ExecuteJob, null, 0, periodicity);
}
#region IDisposable member
public void Dispose()
{
if (this.timer != null)
{
this.timer.Dispose();
this.timer = null;
}
GC.SuppressFinalize(this);
}
#endregion
private void ExecuteJob(object stateInfo)
{
this.logger.Info("Executing job...");
Thread.Sleep(100);
this.logger.Info("Job executed");
}
}
Cette classe permet de lancer un timer à l’instanciation pour exécuter le méthode ExecuteJob(). La classe est disposable pour permettre de stopper l’exécution du timer.
Pour lancer l’exécution, il suffit d’instancier la classe:
var logger = NLog.LogManager.GetCurrentClassLogger();
var timerUsage = new SimpleTimerUsage(logger, 3000);
Console.ReadLine();
Pour exécuter le code correspondant à cet exemple, il faut compiler le projet PeriodicTaskCore avec .NET Core après avoir cloné le repository GitHub:
user@debian:~% git clone https://github.com/msoft/PeriodicTask.git
user@debian:~% cd PeriodicTask
user@debian:~/PeriodicTask/% dotnet build
Pour exécuter le projet:
user@debian:~/PeriodicTask/% cd PeriodicTaskCore
user@debian:~/PeriodicTask/PeriodicTaskCore/% dotnet run
Ainsi la boucle infinie exécute ExecuteJobOnce() comme précédemment. A chaque itération on attends le temps correspondant à la périodicité avec Task.Delay() puis on exécute le traitement en lançant:
ExecuteJobOnce().
Pour lancer l’exécution, il suffit de créer la Task et de la lancer de cette façon:
On lance l’exécution du traitement à l’instanciation de la Task puis de façon périodique par la suite.
Gestion de l’annulation
En introduisant la possiblité d’annuler l’exécution en utilisant un CancellationToken, l’implémentation devient:
private readonly CancellationTokenSource cancellationTokenSource = new CancellationTokenSource();
public void LaunchJob()
{
var cancellationToken = this.cancellationTokenSource.Token;
if (!this.IsTimerRunning())
{
this.timer = Task.Run(() =>
{
this.ExecuteJobOnce(cancellationToken);
this.ExecuteJobPeriodically(cancellationToken);
}, cancellationToken, TaskCreationOptions.LongRunning);
}
}
private void ExecuteJobPeriodically(CancellationToken cancellationToken)
{
while (true)
{
Task.Delay(this.periodicity.Value, cancellationToken).Wait(cancellationToken);
cancellationToken.ThrowIfCancellationRequested();
this.ExecuteJobOnce(cancellationToken);
}
}
private void ExecuteJobOnce(CancellationToken cancellationToken)
{
if (cancellationToken.IsCancellationRequested) return;
this.ExecutePeriodicTask(cancellationToken);
}
Pour annuler l’exécution, il suffit d’exécuter:
cancellationTokenSource.Cancel();
Ajout d’un traitement en cas d’annulation et de d’exception
Si l’exécution de la Task provoque une erreur et si elle est annulée, on souhaite effectuer un traitement comme par exemple logguer un message. Ce type de traitement peut être effectué en utilisation des continuations:
protected void CreateAndLaunchTimer()
{
var cancellationToken = this.cancellationTokenSource.Token;
if (!this.IsTimerRunning())
{
this.timer = new Task(() =>
{
this.ExecuteJobOnce(cancellationToken);
this.ExecuteJobPeriodically(cancellationToken);
}, cancellationToken, TaskCreationOptions.LongRunning);
// Exécuté quand la Task provoque une exception
this.timer.ContinueWith(t =>
{
this.OnPeriodicTaskFaulted(t.Exception);
}, TaskContinuationOptions.OnlyOnFaulted);
// Exécuté quand la task est annulé
this.timer.ContinueWith(t =>
{
this.OnPeriodicTaskCanceled();
}, TaskContinuationOptions.OnlyOnCanceled);
// Exécuté quand la task s'arrête
this.timer.ContinueWith(t =>
{
this.OnPeriodiTaskCompleted();
}, TaskContinuationOptions.OnlyOnRanToCompletion);
this.timer.Start();
}
}
protected virtual void OnPeriodicTaskFaulted(AggregateException exception)
{
this.Logger.Error("Periodic task raised an exception: {0}", exception);
}
protected virtual void OnPeriodicTaskCanceled()
{
this.Logger.Info("Periodic task has been canceled.");
}
protected virtual void OnPeriodiTaskCompleted()
{
this.Logger.Info("Periodic task ended");
}
On peut arrêter l’exécution en exécutant la méthode suivante, on ne fait que vérifier que la tâche n’est pas déjà stoppée puis on la stoppe:
public void StopPeriodicTask()
{
if (this.IsTimerRunning() && !this.cancellationTokenSource.Token.IsCancellationRequested)
{
this.OnPeriodicTaskStopping();
this.cancellationTokenSource.Cancel();
bool completed = false;
try
{
completed = this.timer.Wait(TimeSpan.FromSeconds(5));
}
catch (AggregateException occuredException)
{
occuredException.Handle(ex =>
{
if (ex is TaskCanceledException || ex is OperationCanceledException)
{
completed = true;
return true;
}
return false;
});
}
}
}
On peut ensuite ajouter un lock pour empêcher le lancement de la tâche plusieurs fois si la méthode LaunchJob() est exécutée par des threads différents. On modifie ainsi la méthode LaunchJob():
public void LaunchJob()
{
var cancellationToken = this.cancellationTokenSource.Token;
lock(this.timerCreationLock)
{
if (!this.IsTimerRunning())
{
// ...
}
}
}
Avec:
private readonly object timerCreationLock = new object();
Si cette méthode est exécutée plusieurs fois ou par des threads différents, la Task sera créée et lancée de façon unique.
Encapsuler l’implémentation
Pour rendre l’implémentation plus réutilisable et permettre sa réalisation, on peut encapsuler le code dans une classe abstraite. Le code complet de cette classe est dans: PeriodicTask.cs.
Ainsi on peut utiliser la classe PeriodicTask en dérivant de cette classe et en implémentant le code “métier”, par exemple:
public class PeriodicTaskUsage : PeriodicTask
{
public PeriodicTaskUsage(ILogger logger, TimeSpan? periodicity) :
base(logger, periodicity)
{
// Lancement de la tâche périodique
this.LaunchJob();
}
protected override void ExecutePeriodicTask(CancellationToken cancellationToken)
{
this.Logger.Info("Executing job...");
Thread.Sleep(100);
this.Logger.Info("Job executed");
}
}
Pour lancer l’exécution, il suffit d’instancier la classe PeriodicTaskUsage:
var logger = NLog.LogManager.GetCurrentClassLogger();
var periodicTaskUsage = new PeriodicTaskUsage(logger,
TimeSpan.FromMilliseconds(3000));
Console.ReadLine();
Le résultat de l’exécution est le même que précédemment.
Tester l’exécution du code “métier”
Comme indiqué en introduction, la classe System.Threading.Timer est difficilement testable. On souhaite pouvoir tester le code “métier” ainsi que la plus grande quantité de code dans la classe PeriodicTask. Le projet de test est PeriodicTaskTests.
Le code “métier” dans l’exemple se trouve dans la méthode:
[TestMethod]
public void When_executing_PeriodicTask_Then_DomainCode_Shall_Be_Executed()
{
var loggerMock = new Mock<ILogger>();
var periodicTaskUsage = new PeriodicTaskForTest(loggerMock.Object);
// Exécution de la 1ere itération
Assert.IsTrue(periodicTaskUsage.ExecuteIteration().Wait(5000));
// On peut effectuer des vérifications
loggerMock.Verify(l => l.Info("Executing job..."), Times.Once);
loggerMock.Verify(l => l.Info("Job executed"), Times.Once);
// Exécution d'une 2e itération
Assert.IsTrue(periodicTaskUsage.ExecuteIteration().Wait(5000));
//etc...
}
Pour faciliter l’exécution des tests, on modifie la méthode PeriodicTask.ExecuteJobPeriodically() pour ne pas lancer la boucle infinie si une périodicité n’est pas précisée. On peut, ainsi, maitriser chaque itération à l’éxtérieur de la classe:
private void ExecuteJobPeriodically(CancellationToken cancellationToken)
{
if (!this.periodicity.HasValue) return;
while (true)
{
Task.Delay(this.periodicity.Value, cancellationToken).Wait(cancellationToken);
cancellationToken.ThrowIfCancellationRequested();
this.ExecuteJobOnce(cancellationToken);
}
}
Ainsi si on dérive de la classe PeriodicTaskUsage de cette façon (cf. classe PeriodicTaskForTest):
internal class PeriodicTaskForTest : PeriodicTaskUsage
{
public PeriodicTaskForTest(ILogger logger) :
base(logger, null)
{
}
public async Task ExecuteIteration()
{
this.CreateAndLaunchTimer();
await this.Timer;
}
}
Avec cette implémentation, on est capable de maitriser l’exécution de chaque itération dans le test avec les lignes:
L’implémentation de cet exemple se trouve dans le répository gitHub: msoft/PeriodicTask.
Pour l’exécuter, il faut aller dans le répertoire PeriodicTaskTests et lancer l’exécution des tests:
user@debian:~/PeriodicTask/% cd PeriodicTaskTests
user@debian:~/PeriodicTask/PeriodicTaskTests/% dotnet build
user@debian:~/PeriodicTask/PeriodicTaskTests/% dotnet test
Build started, please wait...
Build completed.
Test run for /home/user/PeriodicTask/PeriodicTaskTests/bin/Debug/netcoreapp2.0/PeriodicTaskTests.dll(.NETCoreApp,Version=v2.0)
Microsoft (R) Test Execution Command Line Tool Version 15.5.0
Copyright (c) Microsoft Corporation. All rights reserved.
Starting test execution, please wait...
Total tests: 1. Passed: 1. Failed: 0. Skipped: 0.
Test Run Successful.
Test execution time: 2.1726 Seconds
Pour conclure…
Cette implémentation n’a rien de très novatrice mais elle permet de facilement mettre en place l’exécution d’une tâche périodique et de la tester. Il existe de nombreuses autres implémentations pour effectuer ce type de traitement. J’espère toutefois que cette implémentation vous a plu. Dans le cas contraire, n’hésiter pas à laisser un commentaire en indiquant les raisons, ça pourrait être intéressant de l’améliorer.
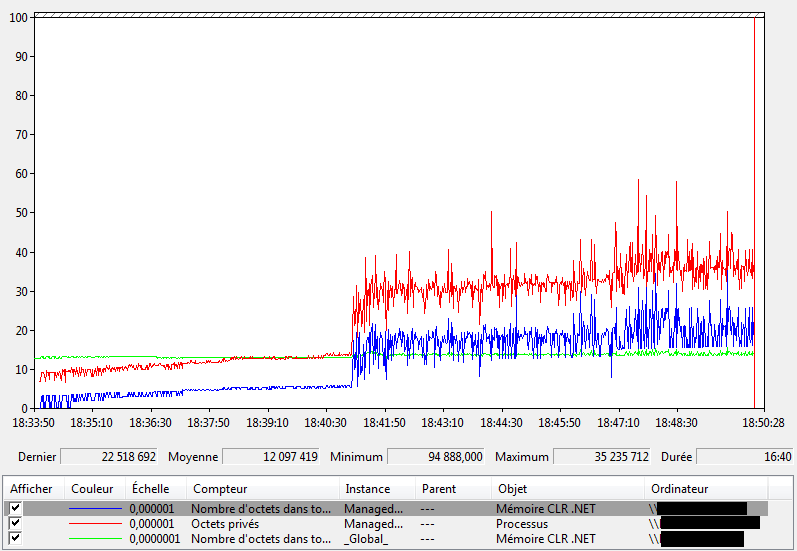
Performance Monitor (appelé aussi perfmon) est un outil de monitoring et d’alerte présent sur les plateformes Windows. Il permet de facilement observer des métriques concernant un processus spécifique ou les caractéristiques d’une machine. La plupart de temps, les développeurs oublient d’utiliser un outil comme celui-ci pour évaluer le comportement de leur application au cours du temps. Pourtant, observer l’évolution de métriques sur son application permet éventuellement de se rendre compte de mauvais comportements ou d’anomalies imprévues pouvant subvenir lors de l’exécution.
Le but de cet article est, dans un premier temps, de montrer les fonctionnalités principales de perfmon pour l’utiliser efficacement. Dans un 2e temps, on va expliciter les métriques utilisables qui permettent de faciliter le diagnostique de défauts d’une application. Enfin, on va montrer comment trouver les défauts les plus courants en combinant les différentes métriques.
Les screenshots dans cet article présente perfmon en français, toutefois les traductions anglaises sont indiquées dans le détail des éléments de configuration.
Les avantages les plus importants de perfmon sont:
Cet outil est déjà installé sur les systèmes Windows (desktop et server). Il n’est donc, pas nécessaire de l’installer.
Il permet de monitorer non seulement des processus classiques mais aussi de remonter des métriques plus spécifiques sur SqlServer ou IIS.
Il peut fonctionner en tant que service, sans qu’il soit nécessaire d’avoir une session ouverte. On peut donc laisser perfmon collecter ses métriques pendant plusieurs jours et ainsi, surveiller l’évolution de l’exécution d’une application ou de la machine qui l’exécute. Cette surveillance aide à anticiper les problèmes pouvant éventuellement subvenir comme, par exemple, le manque de resources CPU, le manque de mémoire ou une fuite mémoire dans un processus.
On peut exécuter perfmon pour qu’il collecte des données sur une machine à distance.
Le plus gros inconvénient de perfmon est qu’il n’est présent que sur les plateformes Windows. .NET Core étant exécutable sur d’autres plateformes que Windows, on ne peut que regretter qu’il n’y a pas d’équivalent de perfmon sur ces autres plateformes.
D’autre part, perfmon peut manquer de stabilité par moment et de nombreux bugs peuvent rendre son utilisation laborieuse.
Exécution de perfmon
Comme indiqué plus haut, perfmon est déjà installé sur Windows, il n’est pas nécessaire de l’installer. Cet outil se trouve à l’emplacement suivant:
C:\WINDOWS\system32\perfmon.msc
Lancer perfmon
On peut lancer perfmon de différentes façons:
En appuyant sur [WIN] + [R], en écrivant perfmon ou perfmon.msc puis en appuyant sur [Entrée].
A partir du menu Windows:
Cliquer sur “Panneau de configuration” (i.e. “Control Panel”).
Cliquer sur “Système et sécurité” (i.e. “System and Security”).
Cliquer sur “Outils d’administration” (i.e. “Administration tools”).
Cliquer sur “Analyseur de performance” (i.e. “Performance monitor”).
Collecter des compteurs en temps réel
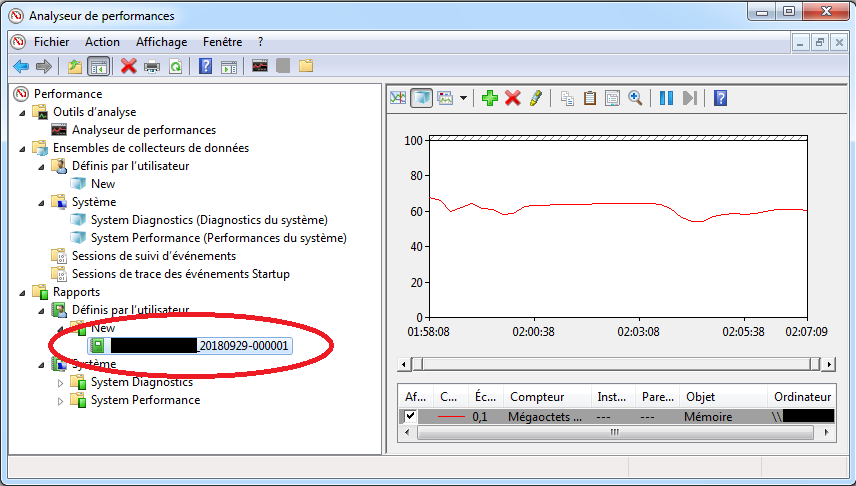
On peut collecter des métriques en temps réel dans la partie “Outils d’analyse” (i.e. “Monitoring Tools”) ⇒ Analyseur de performances (ou “Performance Monitor”).
Performance Monitor
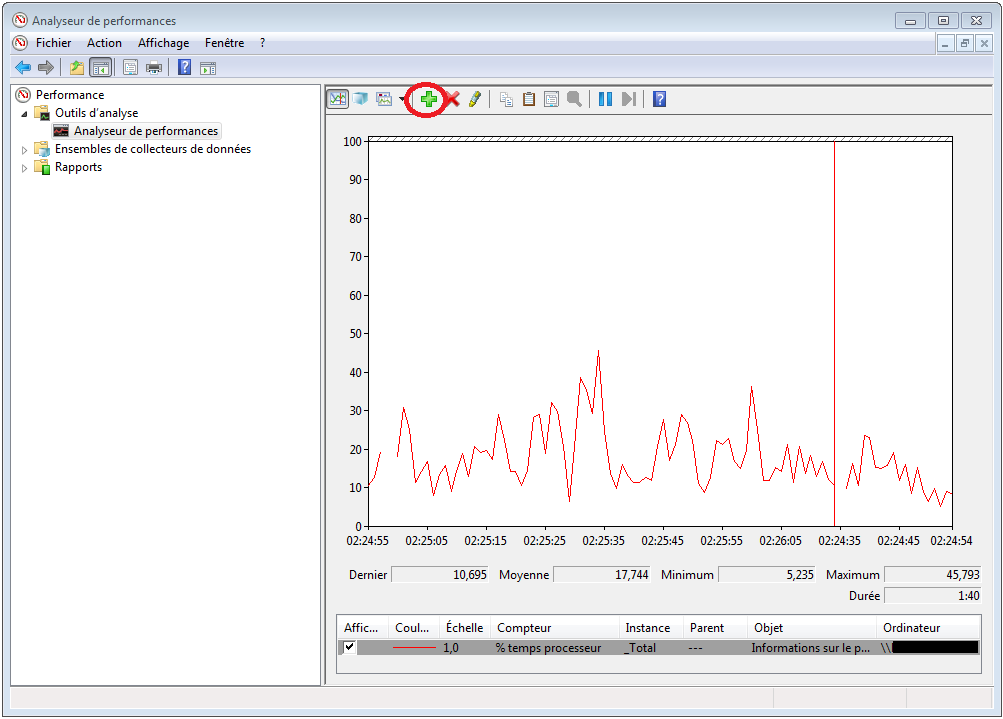
On peut ajouter des métriques (appelées compteur ou counter) en cliquant sur la croix verte:
Ajouter des métriques (1/2)
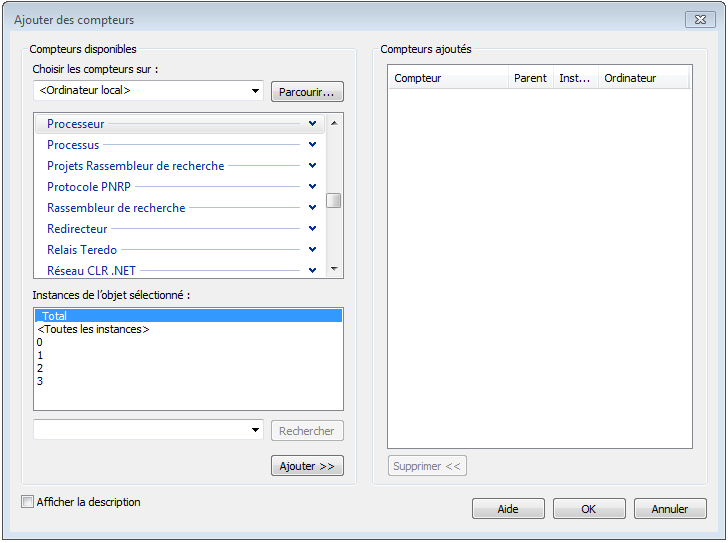
On peut aussi effectuer un clique droit sur le graphique puis cliquer sur “Propriétés” (i.e. “Properties”), dans l’onglet “Données” (i.e. “Data”) si on clique sur “Ajouter”, on accède à l’écran permettant de choisir le compteur à ajouter.
Ajouter des métriques (2/2)
Choisir la machine sur laquelle on effectue la collecte
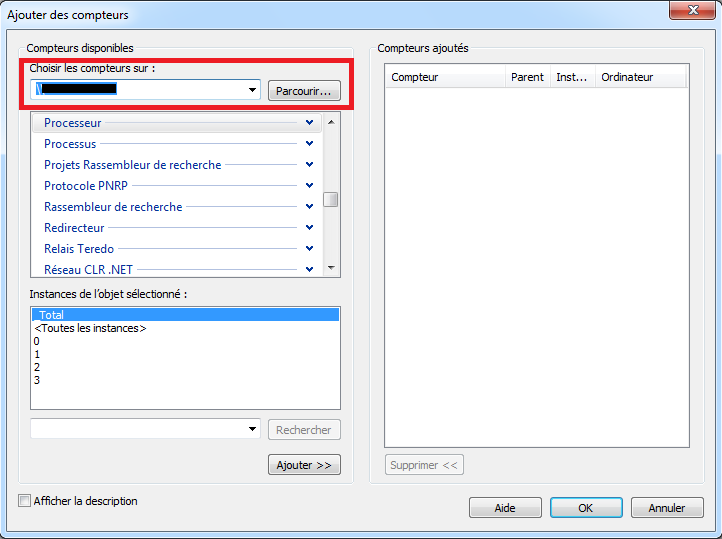
Un grand avantage de perfmon est de pouvoir monitorer des informations sur une machine se trouvant à distance. On peut ainsi renseigner l’adresse d’une machine distance et ainsi collecter les données la concernant.
Si on se connecte à une machine distante, il faut bien sélectionner la machine au moment d’ajouter des compteurs dans la partie “Choisir les compteurs sur” (i.e. “Select counters from computer”):
Ajuster l’échelle du graphique
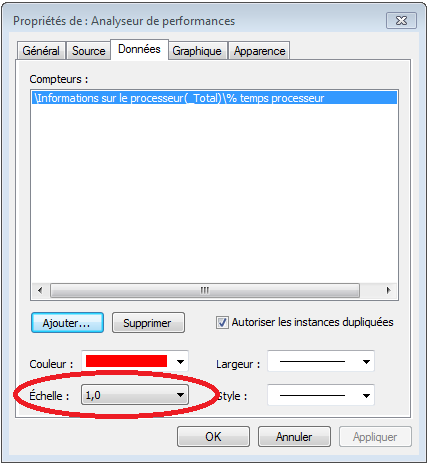
Dans l’écran de propriétés des graphiques, on peut ajuster manuellement l’échelle du graphique:
Ajuster l’échelle
L’ajustement de l’échelle peut se faire en appliquant un facteur d’échelle aux données pour que le graphique puisse être affichable.
Pour effectuer l’ajustement automatiquement, on peut aussi effectuer un clique droit sur le graphique puis cliquer sur “Mettre à l’échelle les compteurs sélectionnés” (i.e. “Scale selected counters”).
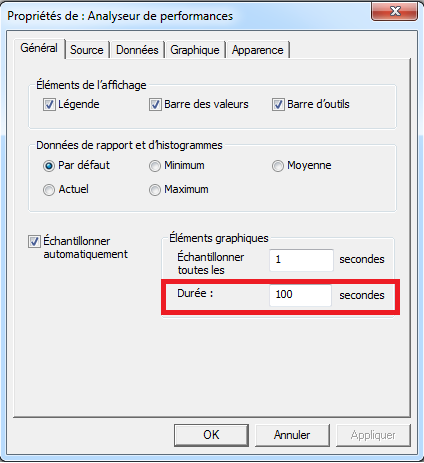
Par défaut, l’échelle de temps est sur 100 sec ce qui est parfois très court pour monitorer correctement un comportement. On peut augmenter cette échelle en allant dans l’onglet “Général” dans la partie “Eléments graphiques” (i.e. “Graph elements”):
Ajuster l’échelle verticale
Par exemple, on peut augmenter la valeur maximum à 1000 sec (le maximum est 1000) pour avoir un historique plus important.
La collecte des compteurs en temps-réel est plutôt limitée puisqu’elle ne permet pas de capturer plus longtemps que 1000 sec. D’autre part, les données ne sont pas sauvegardés sur le disque. Après avoir fermé perfmon, les données sont perdues.
Configurer des collectes automatiques de données
perfmon donne la possibilité de capturer des données sur plusieurs heures ou jours et de les sauvergarder sur le disque de façon à les consulter plus tard. Avec ce type de collecteur, même après fermeture de perfmon, les données continueront d’être collectées. Cette fonctionnalité apporte une grande flexibilité puisqu’on peut fermer la session et les données continueront d’être collectées et sauvegardées.
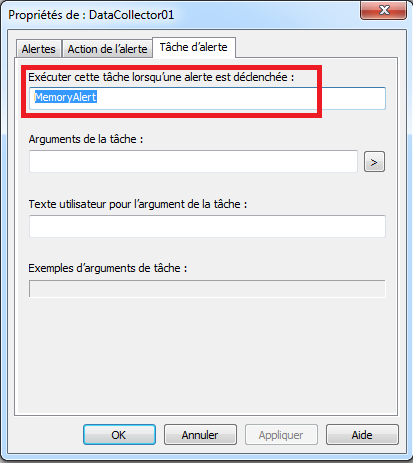
Configuration de compteurs par programmation
Cet article indique comment configurer des compteurs en utilisant perfmon toutefois il est possible de créer des compteurs de performance par programmation. Pour davantage de détails, voir PerformanceCounter en 5 min.
Configurer un collecteur de données
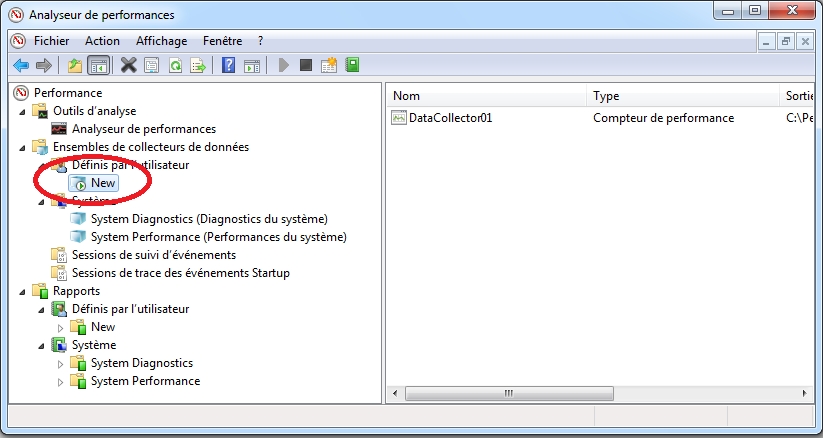
Pour effectuer des collectes automatiques, il faut:
Déplier la partie “Ensembles de collecteurs de données” (ou “Data Collector Sets”).
Déplier la partie “Définis par l’utilisateur” (ou “User Defined”).
On peut créer un ensemble de collecteurs de données en effectuant un clique droit sur “Définis par l’utilisateur” (ou “User Defined”) puis cliquer sur “Nouveau” et enfin “Ensemble de collecteurs de données” (ou “Data Collector Set”).
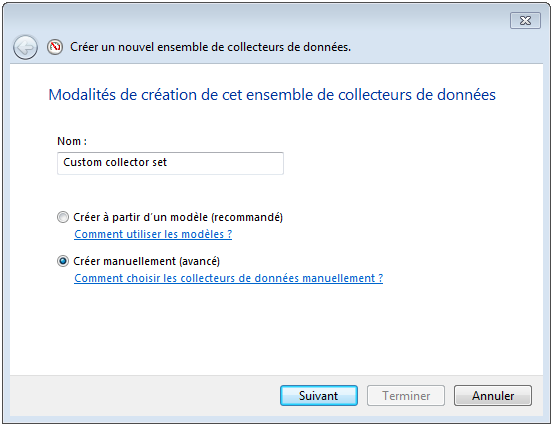
Préciser un nom pour l’ensemble de collecteurs.
Sélectionner “Créer manuellement (avancé)” (ou “Create manually (advanced)”) puis cliquer sur “Suivant”:
Les options affichées permettent d’ajouter des compteurs particuliers:
Compteur de performance (ou “performance counter”): cette option permet de créer des compteurs personnalisés avec lesquel on pourra préciser quelles sont les métriques à observer.
Données de suivi d’évènements (ou “Event trace data”): ce sont des évènements paramétrés.
Informations de la configuration système (ou “System configuration information”): ce paramétrage permet d’observer des valeurs de clé de registre.
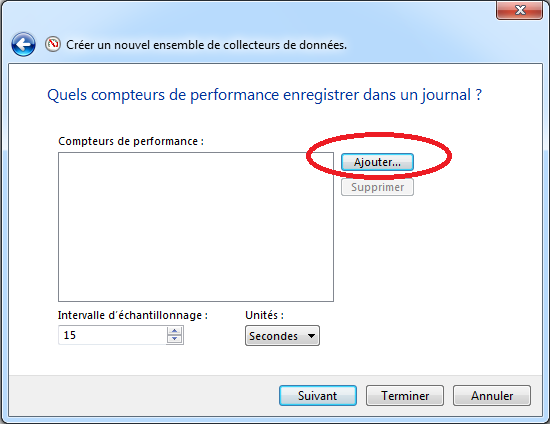
Pour effectuer une collecte automatique de métriques, il faut sélectionner “Compteur de performance” (ou “Performance Counter”) puis cliquer sur “Suivant”.
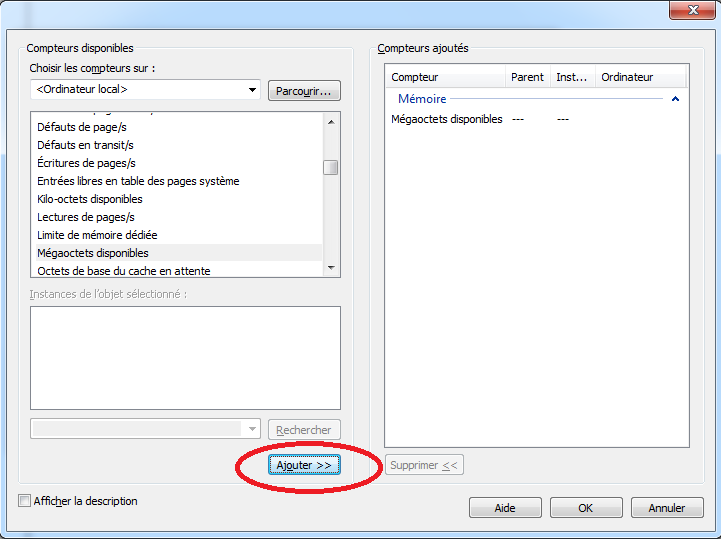
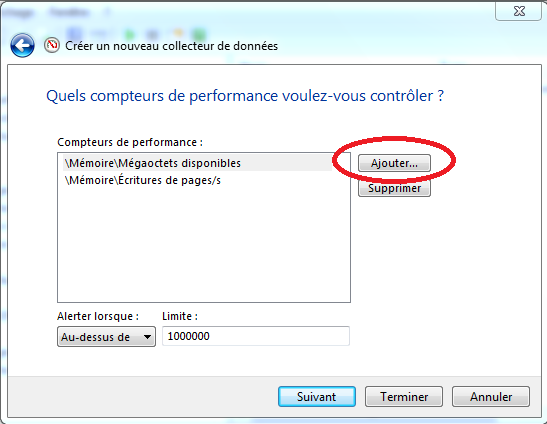
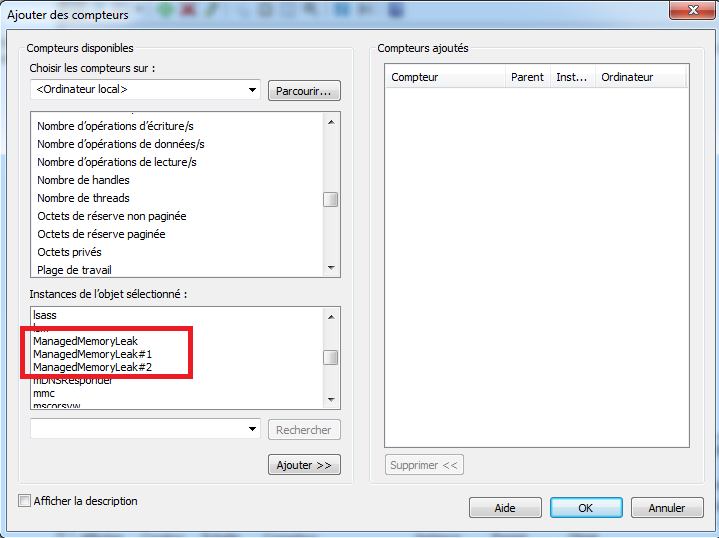
Dans l’écran, on peut sélectionner les métriques à observer en cliquant sur “Ajouter…”:
Dans le cadre de l’exemple, on peut choisir une métrique sur le système, par exemple dans la partie: “Mémoire” (i.e. “Memory”) ⇒ “Mégaoctets disponibles” (ou “Available Bytes”).
Cliquer sur “Ajouter” puis “OK”.
Cliquer ensuite sur “Terminer”.
Lorsque la configuration est ajoutée, on peut préciser quelques éléments de configuration supplémentaire:
Effectuer un clique droit sur le collecteur créé,
Cliquer sur “Propriétés”.
On peut personnaliser certains éléments:
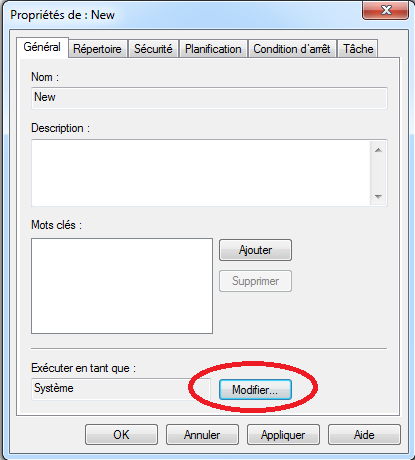
Utilisateur: l’utilisateur qui exécutera le compteur: ce paramétrage est particulièrement utile si on souhaite monitorer un processus lancé avec un utilisateur différent de celui qui effectue le paramétrage. Ce paramètre est disponible dans l’onglet “Général”:
Répertoire (ou “Directory”): le répertoire dans lequel les fichiers des compteurs seront créés: accessible dans l’onglet “Répertoire”.
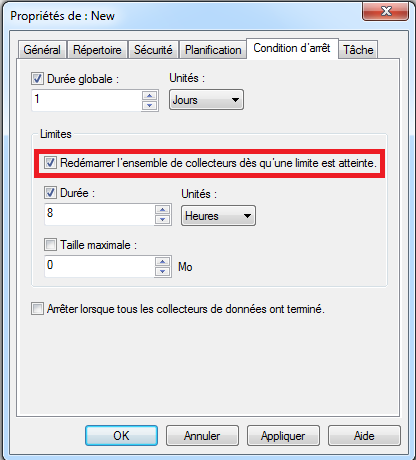
Condition d’arrêt (ou “Stop condition”): il peut être utile de paramétrer une condition d’arrêt pour éviter que la collecte s’effectue de façon permanente. Les paramètres les plus utiles sont:
Durée globale (ou “Overall duration”): indiquer une durée. Ne pas oublier de préciser l’unité.
Limites (ou “Limits”): cette partie est intéressante car elle va permettre d’indiquer une période de collecte qu’il est possible de redémarrer périodiquement. En effet, il n’est pas possible de consulter le résultat d’une collecte si elle est en cours d’exécution. Ainsi, si on redémarre une collecte de façon périodique, on pourra lire la collecte effectuée lors d’une période précédente.
Pour permettre de redémarrer périodiquement une collecte, il faut:
Indiquer une durée de collecte et cliquer sur “Durée”
Cliquer sur “Redémarrer l’ensemble de collecteurs dès qu’une limite est atteinte” (i.e. “Restart the data collection set at limits”) pour permettre de relancer une nouvelle période de collecte:
Paramétrer une condition d’arrêt
Il est vivement conseillé de paramétrer une condition d’arrêt pour plusieurs raisons:
Les compteurs peuvent consommer beaucoup de mémoire: cette quantité varie en fonction de la quantité de métriques paramétrées. Certaines métriques système consomment particulièrement de la mémoire.
On ne peut pas lire les résultats d’une collecte si celle-ci n’est pas arrêtée. Pour pouvoir lire les résultats, il faut:
soit arrêter la collecte
soit redémarrer la collecte de métriques de façon périodique. Lors d’une période de collecte, on ne peut pas lire la collecte en cours, toutefois on peut lire les périodes précédentes.
Enfin, en redémarrant une collecte périodiquement, les données de collecte sont écrites périodiquement sur le disque. Si perfmon crashe, on ne perds que la dernière période de collecte et non toute la collecte.
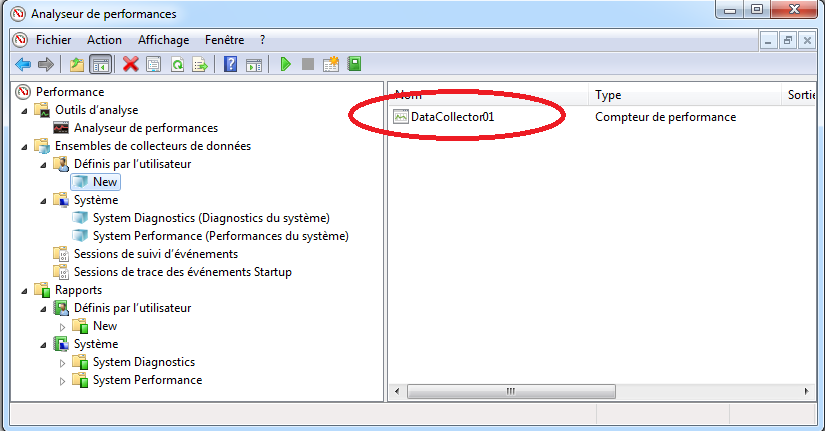
Modifier les propriétés du compteur de performance
Il est possible de modifier les métriques collectées en effectuant un clique droit sur le compteur de performance (sur la droite) puis en cliquant sur “Propriétés” (on peut aussi double cliquer sur le nom du compteur):
Accéder aux proprétés d’un compteur de performance
On peut aussi ajouter des collecteurs de données en effectuant un clique droit sur le panneau de gauche puis en cliquant sur “Nouveau”.
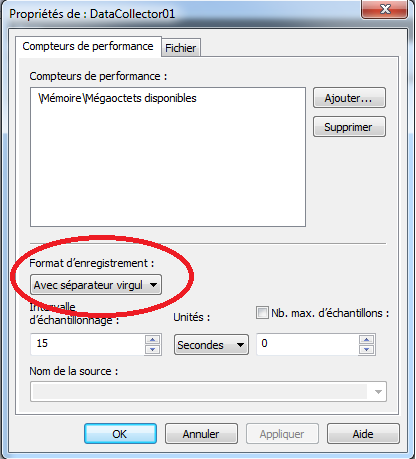
Modifier le format d’enregistrement des données collectées
Cette option peut s’avérer particulièrement utile pour sauvegarder les données dans un fichier CSV de façon à les ouvrir dans Excel par exemple:
Il faut accéder aux propriétés du compteur de performance en effectuant un clique droit sur le compteur (sur la droite) puis en cliquant sur “Propriétés” (on peut double cliquer sur le nom du compteur).
Dans la partie “Format d’enregistrement” (i.e. “Save Data As”), on peut sélectionner “Avec séparateur virgule” (i.e. “Test file (comma delimited)”) ou “Avec séparateur tabulation” (i.e. “Text file (tabulation delimited)”):
Les données collectées seront enregistrées dans un fichier .CSV consultable, par exemple, avec Excel.
Convertir un fichier de données binaires en CSV
On peut convertir les données collectées dans un fichier binaire au format .BLG vers un fichier texte de type .CSV en exécutant la commande suivante:
relog -f csv <chemin du fichier binaire .BLG> -o <chemin du fichier de sortie .CSV>
Démarrer un collecteur de données
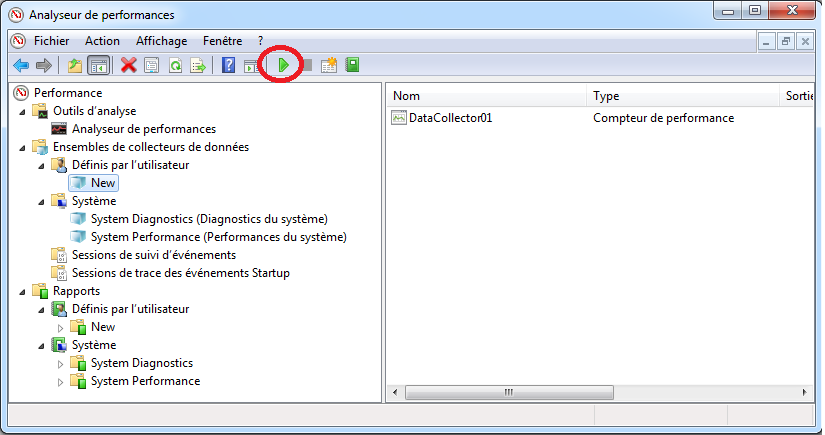
Démarrer manuellement une collecte
Après avoir configuré un collection de données, on peut la démarrer:
En le sélectionner puis en cliquant sur “Démarrer”:
On peut aussi démarrer en effectuant un clique droit sur le collecteur puis en cliquant sur “Démarrer”.
Après démarrage, l’icône du collecteur change:
Icône d’un collecteur de données démarré
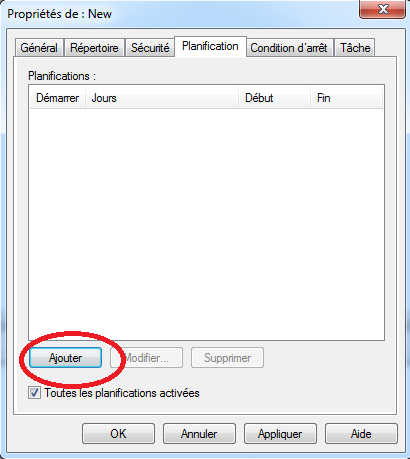
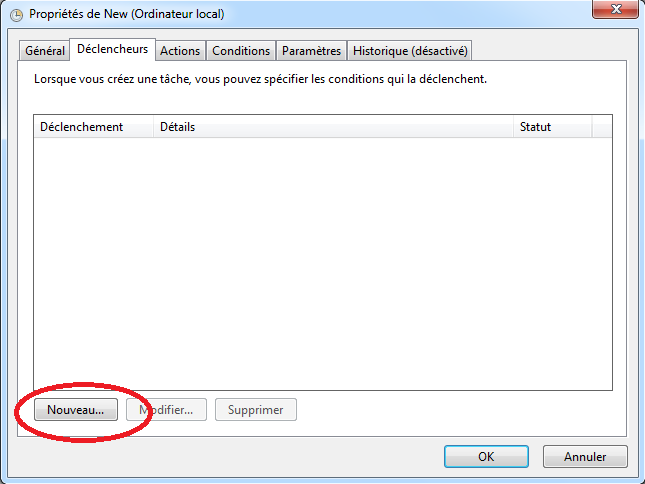
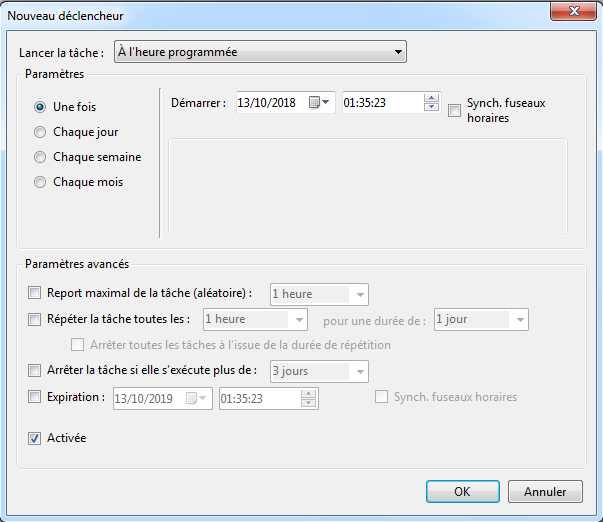
Programmer le démarrage d’une collecte
On peut programmer la collecte en consultant les propriétés d’un ensemble de collecteur de données (i.e. “Data collector sets”):
Accéder aux propriétés en effectuant un clique droit sur l’ensemble de collecteur de données ⇒ cliquer sur “Propriétés”.
Aller dans l’onglet Planification (i.e. “Schedule”).
Ajouter une condition de démarrage en cliquant sur “Ajouter”:
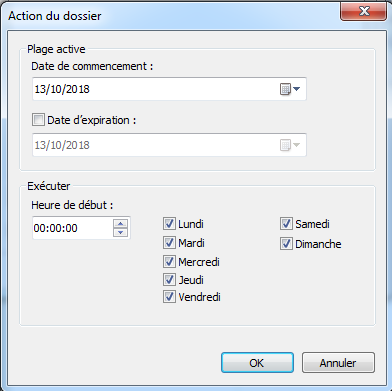
On peut préciser un certain nombre de critères pour planifier la collecte:
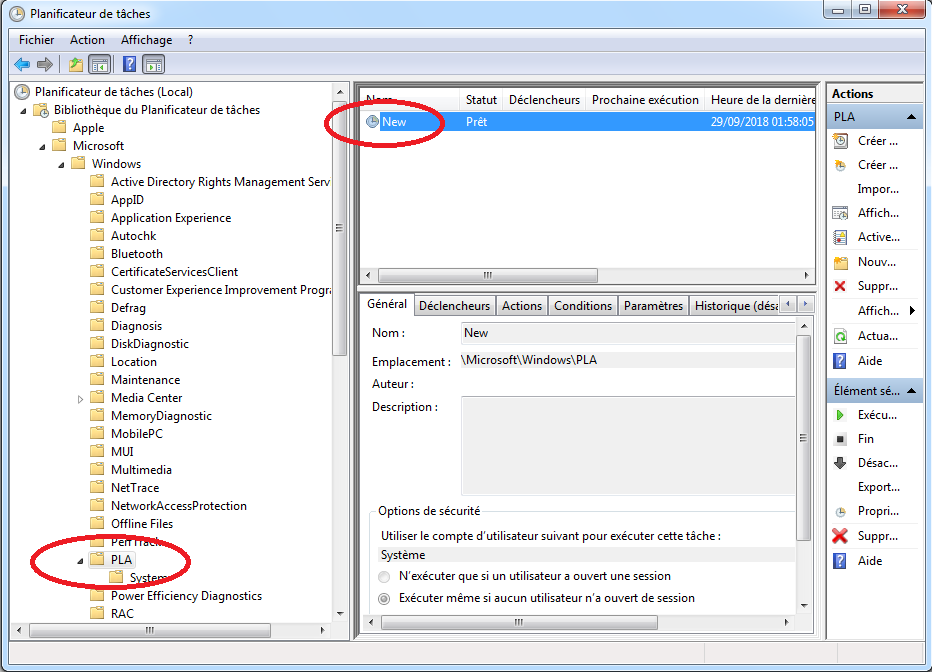
Une autre méthode permet de programmer le démarrage d’un ensemble de collecteur de données en passant par le Task Scheduler de Windows:
Il faut, d’abord, ouvrir le Task Scheduler ou Planificateur de tâches en allant dans “Panneau de configuration” (i.e. “Control Panel”) ⇒ “Système et sécurité”” (i.e. “System and Security”) ⇒ Dans la partie “Outils d’administration” (i.e. “Administration tools”), cliquer sur “Tâches planifiées” (i.e. “Task Scheduler”).
Une autre méthode consiste à exécuter la commande suivante en faisant [Win] + [R]:
taskschd.msc
On peut accéder aux ensembles de collecteur de données créés dans perfmon en allant dans la partie: “Bibliothèque de Planificateur de tâches” (i.e. “Task Scheduler Library”) ⇒ “Microsoft” ⇒ “Windows” ⇒ “PLA”:
On peut voir sur le panneau de droite, les ensembles de collecteur de données créés dans perfmon. Si on effectue un clique droit sur l’ensemble puis en cliquant sur “Propriétés” on peut accéder à un ensemble d’options permettant de planifier une exécution.
Dans l’onglet “Déclencheurs” (i.e. “Triggers”):
On peut indiquer des options dans les déclencheurs:
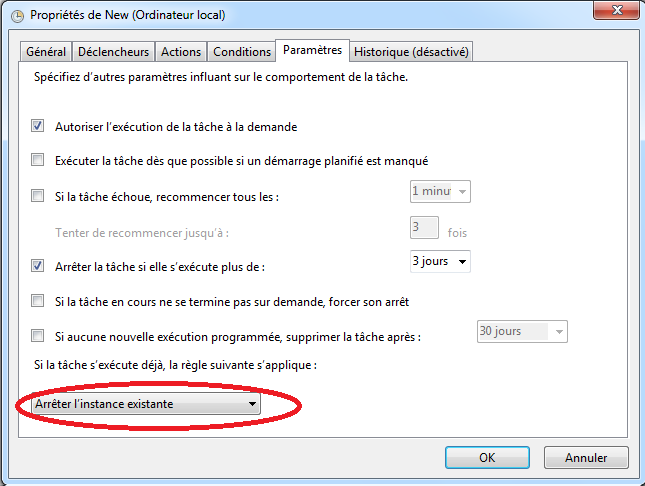
Dans l’onglet “Paramètres” (i.e. “Settings”), on peut indiquer de stopper l’exécution d’une collecte avant d’en commencer une autre en sélectionnant dans “Si la tâche s’exécute déjà, la règle suivante s’applique” (i.e. “If the task is already running, then the following rule applies”) l’option “Arrêter l’instance existante” (i.e. “Stop the existing instance”):
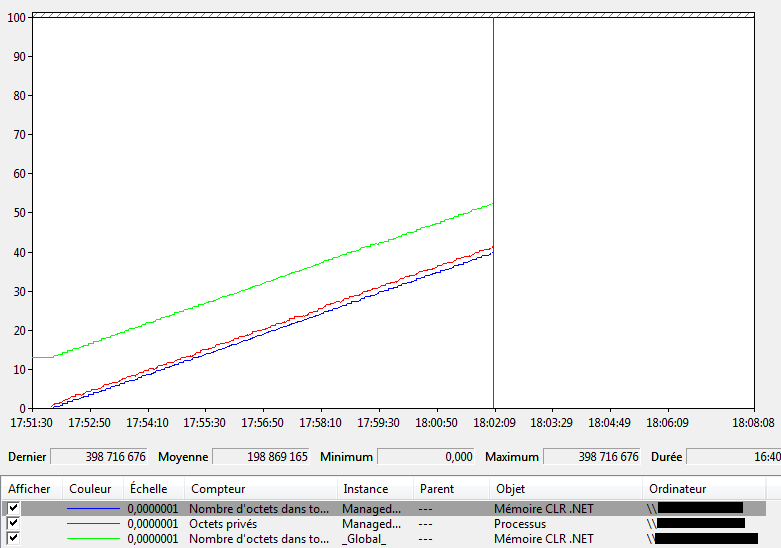
Lire les résultats d’une collecte
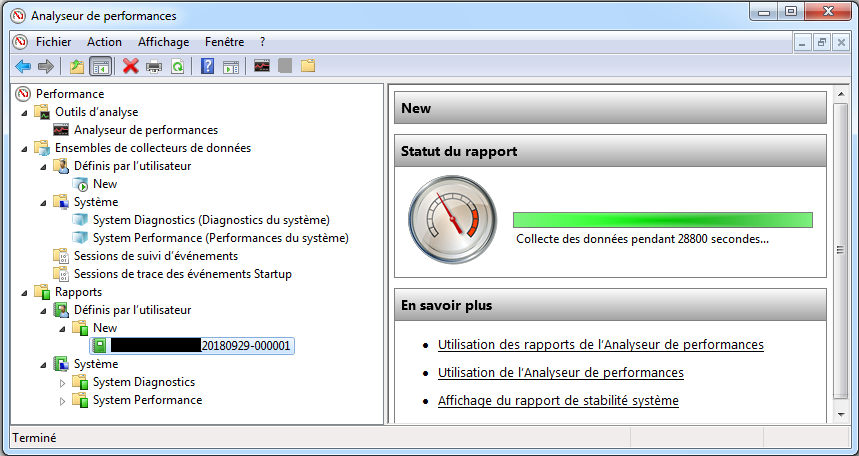
On ne peut pas voir les résultats d’une collecte de données tant que celle-ci est en cours d’exécution. Une astuce consiste à paramétrer une collecte périodique de façon à lire les résultats collectés lors d’une période précédente.
Si on tente de lire les résultats d’une collecte en cours:
Accéder à une collecte en cours
Pour lire les résultats, il faut:
Arrêter la collecte en effectuant un clique droit sur le collecteur puis en cliquant sur “Arrêter” ou
Les résultats se lisent dans la partie “Rapports” (i.e. “Reports”), il faut sélectionner le répertoire correspondant à la collecte:
Sélectionner un rapport
On peut choisir différent type d’informations en effectuant un clique droit sur le répertoire de la collecte ⇒ Cliquer sur “Affichage” ⇒ Différents éléments sont disponibles:
Rapport: regroupant des informations relatives à la collecte
Analyseurs de performances: présentant les courbes correspondant aux métriques collectées.
Dossier: c’est l’ensemble des fichiers permettant de stocker les informations collectées.
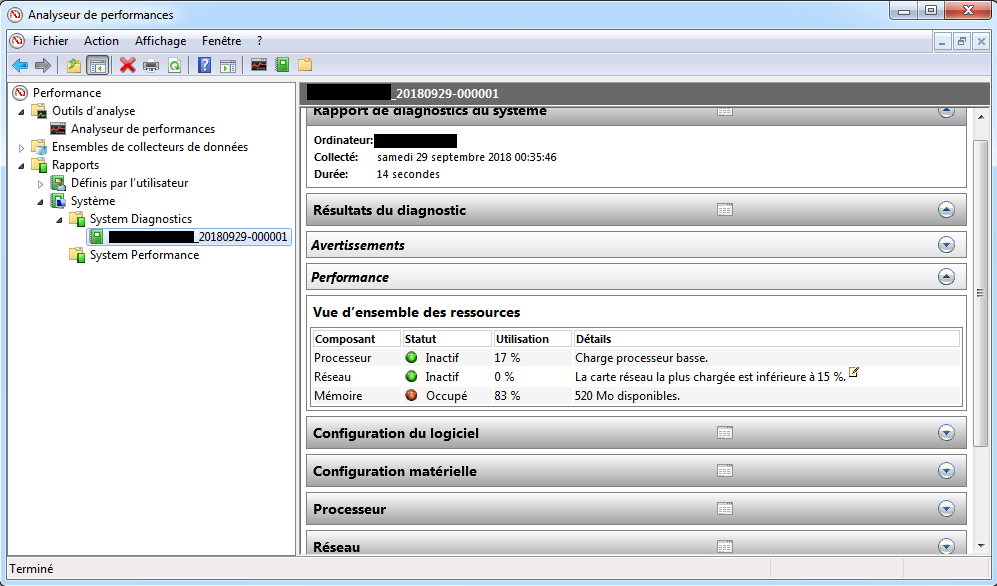
Si la collecte de données est terminée, en double cliquant sur le nom du rapport, on peut voir un résumé de la collecte (accessible aussi en effectuant un clique droit sur le nom du rapport ⇒ Affichage (i.e. “Display”) ⇒ Rapports (i.e. “Reports”):
Affichage d’un rapport
Il est possible de supprimer les répertoires regroupant les données collectées en effectuant un clique droit sur le répertoire ⇒ Cliquer sur “Supprimer”.
Créer des alertes
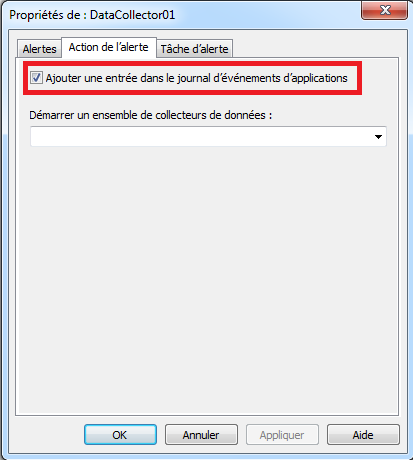
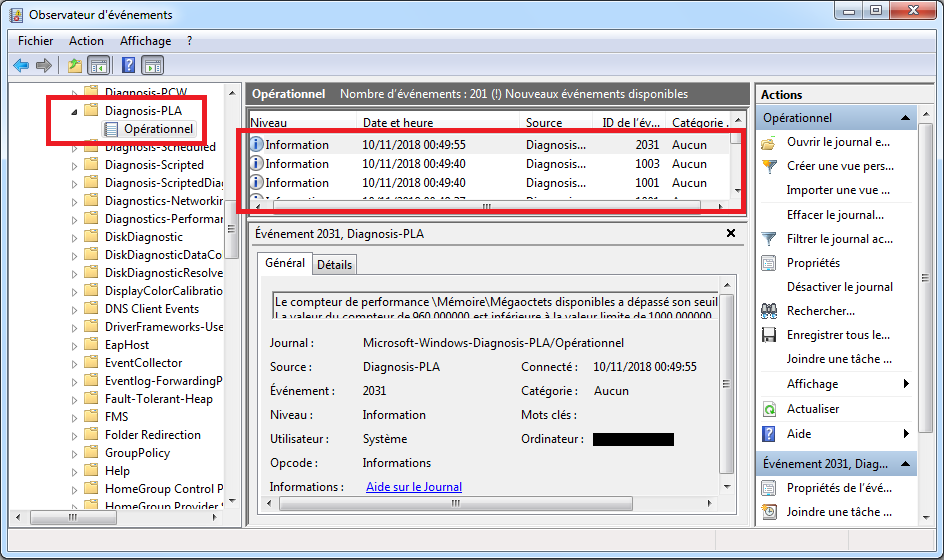
On peut configurer des alertes correspondant à des actions qui seront exécutées quand survient un évènement particulier. Les évènements sont configurés à partir de la comparaison d’une métrique avec une valeur seuil déterminée. Par exemple, on peut configurer l’exécution d’une action quand un seuil particulier est dépassé à la hausse ou à la baisse.
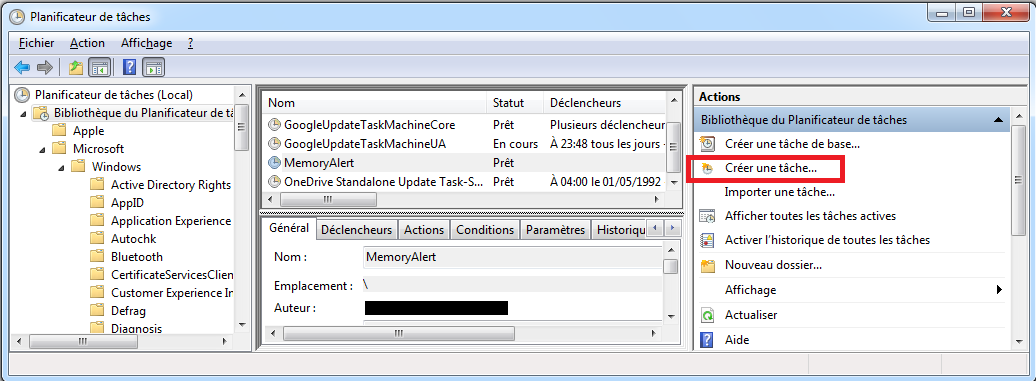
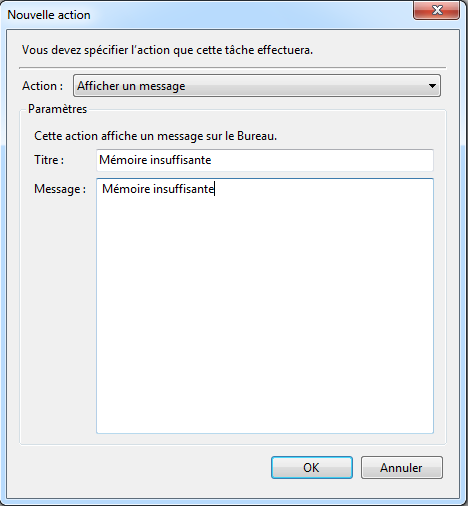
Pour configurer ce type d’alerte, il faut:
Déplier la partie “Ensembles de collecteurs de données” (ou “Data Collector Sets”).
Déplier la partie “Définis par l’utilisateur” (ou “User Defined”).
On peut créer un ensemble de collecteurs de données en effectuant un clique droit sur “Définis par l’utilisateur” (ou “User Defined”) puis cliquer sur “Nouveau” et enfin “Ensemble de collecteurs de données” (ou “Data Collector Set”).
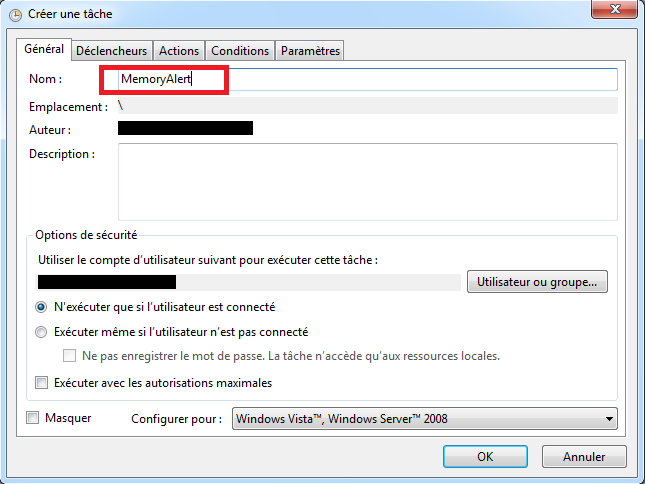
Préciser un nom pour l’ensemble de collecteurs.
Sélectionner “Créer manuellement (avancé)” (ou “Create manually (advanced)”) puis cliquer sur “Suivant”:
Sélectionner un collecteur de données de type “Alerte de compteur de performance” (i.e. Performance counter alert).
Ajouter des métriques qui seront comparées à différent seuil: cliquer sur “Ajouter” puis sélectionner une ou plusieurs métriques:
Indiquer pour chaque métrique des seuils utilisés à la hausse (quand “Au dessus de” ou “Above” est sélectionné) ou à la baisse (quand “Au dessous de” ou “Below” est sélectionné).
Cliquer sur “Terminer”.
Quand les seuils sont dépassés, on peut exécuter des actions en:
Effectuant un clique droit sur le collecteur de données (sur le panneau de droite) ⇒ cliquer sur “Propriétés”.
Dans l’onglet “Action de l’alerte” (i.e. “Alert action”), on peut indiquer l’ensemble de collecteurs à démarrer le cas échéant ou
Dans l’onglet “Tâche d’alerte” (i.e. “Alert task”), indiquer la tâche du Task Scheduler à lancer.
Avec ce type d’alerte, on peut exécuter plusieurs types de tâche comme envoyer un mail, afficher un message ou lancer un exécutable. On va expliciter la création d’une tâche pour afficher un message, la procédure étant facilement extensible aux autres cas.
Ainsi, si on veut afficher un message quand la mémoire disponible sur la machine est inférieure à une valeur limite, il faut effectuer les étapes suivantes:
Il faut créer une alerte de compteur de performance en utilisant la procédure décrite précédemment.
Il faut ensuite éditer quelques propriétés du collecteur de données:
Effectuer un clique droit sur le collecteur de données (sur le panneau de droite) ⇒ cliquer sur “Propriétés”.
Dans l’onglet “Action de l’alerte” (i.e. “Alert action”), cliquer sur “Ajouter une entrée dans le journal d’évènements d’applications” (i.e. Log entry in the application event log): cette action permet d’ajouter une entrée dans l’Event log Windows:
Cliquer sur “OK” pour valider.
On peut démarrer l’ensemble de collection de données en le sélectionnant puis en cliquant sur “Démarrer”.
Dans l’Event Viewer (ou l’observateur d’évènements), on peut voir l’ajout d’une entrée à chaque fois que l’alerte est déclenchée: dans notre cas, l’alerte sera déclenchée dès que la quantité de mémoire disponible sera inférieure à la valeur seuil.
Pour voir l’entrée dans Event Viewer:
Il faut l’ouvrir en appuyant sur les touches [Win] + [R] puis en écrivant eventvwr.msc.
Déplier les nœuds “Observateurs d’évènements” ⇒ “Journaux des applications et des services” ⇒ “Microsoft” ⇒ “Diagnosis-PLA” ⇒ “Opérationnel”, on peut voir les entrées ajoutées en cas de déclenchement de l’alerte:
Il faut ensuite créer une tâche permettant d’afficher un message dans le Task Scheduler:
On ouvre le Task Scheduler en appuyant sur les touches [Win] + [R], en écrivant taskschd.msc puis en appuyant sur [Entrée].
Dans le nœud “Planificateur de tâches” (i.e. “Task Scheduler”) ⇒ “Bibliothèque de Planificateur de tâches” (i.e. “Task Scheduler Library”), on peut créer une tâche en cliquant sur “Créer une tâche” (i.e. “Create a task”):
On indique le nom de la tâche, par exemple MemoryAlert:
Dans l’onglet “Actions”, en cliquant sur “Nouveau”, on peut créer une action à exécuter parmi les actions suivantes:
Démarrer un programme,
Envoyer un message électronique,
Afficher un message.
On sélectionne “Afficher un message” (i.e. “Display a message”) et on indique le message à afficher:
Cliquer sur “OK” pour terminer la création de la tâche.
On peut tester l’exécution de la tâche en sélectionnant la tâche et en cliquant sur “Exécuter”. Une popup devrait s’afficher avec le contenu suivant:
Il faut ensuite configurer la tâche nouvellement créée dans le collecteur de données:
Retourner dans perfmon
Sélectionner l’ensemble de collecteur de données puis effectuer un clique droit sur le collecteur de données (sur la partie droite) et cliquer sur “Propriétés”.
Dans l’onglet “Tâche d’alerte” (i.e. Alert task), dans la partie “Exécuter cette tâche lorsqu’une alerte est déclenchée” (i.e. “Run this task when an alert is triggered”), indiquer le nom de la tâche créée dans le Task Scheduler. Dans notre exemple, cette tâche s’appelle MemoryAlert:
A la suite de cette configuration si l’ensemble de collecteur de données est démarrer, un message d’alerte sous forme d’une popup devrait s’afficher à chaque fois que la mémoire disponible sur la machine descend en dessous de la valeur seuil configurée.
Principaux compteurs de perfmon
Les compteurs de perfmon sont des métriques permettant de mesurer plusieurs types d’information. Ils permettent d’observer des informations diverses allant des données concernant le système à des données concernant des processus spécifiques. Ces compteurs sont les plus importants puisque leur évolution permet de diagnostiquer l’état du système ou d’un processus.
La façon de traiter ces compteurs n’est pas la même:
Pour certains compteurs, une simple lecture de la valeur peut suffire à déduire une information pertinente, par exemple le pourcentage de temps processeur permet d’indiquer directement l’utilisation du processeur.
Pour d’autres compteurs, il faut comparer la valeur avec une autre valeur provenant éventuellement d’un autre compteur, par exemple pour la quantité de mémoire disponible. Pour en tirer une information pertinente, il faut comparer cette quantité avec la quantité de mémoire totale de la machine pour en déduire la quantité de mémoire occupée.
Pour certains compteurs, la lecture d’une valeur instantanée n’indiquera rien de pertinent, il faudra scruter la variation de la valeur du compteur en fonction du temps. Par exemple, la mémoire occupée par un processus peut apporter une information si on constate une augmentation au cours du temps. Plus l’augmentation sera brutale et plus l’évolution de ce compteur sera préoccupante.
Enfin, il faut distinguer les unités des compteurs: certains compteurs indiquent des valeurs instantanées, des valeurs moyennes, des pourcentages d’une valeur totale ou des valeurs moyennées par seconde. Il faut avoir en tête que des valeurs instantanées sont échantillonnées à une fréquence donnée. Ces échantillonnages peuvent avoir pour conséquence de déformer la réalité puisque la capture des valeurs est discontinue, seules les captures correspondant à la fréquence seront affichées et non pas toutes les valeurs de façon continue.
Utilisation du processeur
L’utilisation du processeur est une des informations qui peut être la plus utile à capturer. La plupart du temps, les machines comptent plusieurs cœurs logiques. Ainsi, l’utilisation peut être indiquée de façon totale ou pour chaque cœur logique.
Pourcentage du temps processeur
Processeur\% temps processeur Processor\% Processor Time
C’est une valeur instantanée qui permet d’avoir une idée de l’utilisation totale du processeur. Une valeur proche des 100% indique un processeur utilisé au maximum de sa capacité ce qui le plus souvent peut révéler une exécution anormale d’un processus. Généralement, il peut être utile d’analyser le temps processeur pour chaque cœur et non pour tout le processeur. En effet, le plus souvent un processus pourrait utiliser 100% d’un cœur mais plus rarement 100% du temps total du processeur.
Processus\% temps processeur Process\% Processor Time
Contrairement au compteur précédent, ce compteur ne concerne que le temps processeur pour un processus donné. Cette valeur peut s’avérer intéressante pour isoler le comportement anormal d’un processus en particulier. Plus simplement, dans un fonctionnement normal, ce compteur peut aussi servir à dimensionner une machine pour l’exécution d’un processus.
“Mode kernel” vs “mode utilisateur”
Brièvement, le processeur est exécuté soit en mode utilisateur (i.e. user mode), soit en mode kernel (i.e. kernel mode) suivant le code qu’il doit exécuter. Les applications sont exécutées en mode utilisateur, les systèmes d’exploitation et la plupart des drivers sont exécutés en mode kernel. Cette séparation permet d’isoler l’exécution d’un processus dans un espace d’adresse mémoire virtuelle qui lui est spécifique. Un processus peut appeler certaines fonctions du système d’exploitation qui seront exécutées en mode kernel comme par exemple effectuer des opérations sur un fichier sur le disque, allouer de la mémoire ou effectuer des entrées/sorties réseau.
Processeur\% temps privilégié Processor\% Privileged time
Ce compteur permet d’indiquer l’utilisation du processeur en mode kernel. Si l’utilisation du processeur en mode kernel est élevée (c’est-à-dire > 75%) peut révéler une machine sous-dimenssionnée pour l’ensemble des processus à exécuter.
Processeur\% temps utilisateur Processor\% User time
Ce compteur indique l’utilisation du processeur en mode utilisateur. Cette valeur est moins pertinente que le pourcentage de temps privilégié toutefois elle peut présenter un intérêt s’il est particulièrement élevé (> 90 %). Elle peut indiquer une machine sous-dimensionnée.
Système\Longueur de la file d’attente du processeur System\Processor Queue Length
Ce compteur donne une indication sur le nombre de threads en attente d’exécution. On considère que cette valeur est préoccupante si elle dépasse 5. Dans le cas d’une machine multi-cœur, il faut diviser la valeur par le nombre de cœurs et comparer le résultat avec 5. Si la valeur dépasse 5 de façon continue avec un processeur proche des 100% du temps d’exécution, il y a davantages de threads en attente d’exécution que la processeur n’est capable d’en traiter. Ce qui conduit à allonger la file d’attente et à rendre l’exécution des threads plus longue.
Système\Changement de contexte/s System\Context switches/sec
Ce compteur indique le nombre de fois moyens par seconde que le processeur passe du mode utilisateur vers le mode kernel pour effectuer des opérations où le mode kernel est nécessaire dans le cadre d’un thread exécuté en mode utilisateur. Cette valeur dépends de la charge à laquelle est soumise le processeur toutefois elle doit rester stable pour une même charge donnée. Si cette valeur augmente sans changement de charge du processeur, il pourrait s’agir d’un fonctionnement anormal d’un driver.
Une augmentation brutale peut provenir d’un processus qui effectue beaucoup d’opérations nécessitant une exécution en mode kernel. Dans ce cas, il faut observer la variation de cette valeur et la rapprocher à l’exécution du processus pour éventuellement surveiller une saturation qui pourrait dégrader l’exécution du processus.
D’une façon générale, une valeur inférieure à 5000 est considérée normale.
Processeur\Interruption/sec Processor\Interrupts/sec
Cette valeur indique le nombre de fois moyen par seconde que le processeur reçoit une interruption provenant d’un autre composant hardware. Si cette valeur est supérieure à 1000 de façon continue, il peut s’agir d’un défaut d’un composant matériel. Dans un fonctionnement normal, certains composants sollicitent des interruptions régulières du processeur comme l’horloge système, la souris, les drivers des disques, les cartes réseaux etc…
Identifier les processus
Dans perfmon, les processus sont reconnaissables par leur nom. Toutefois, il peut arriver qu’il existe plusieurs instances d’un même processus. Dans perfmon, tous ces processus seront représentés avec le même nom. Par exemple:
Différentes instances d’une même application
Pour identifier quel libellé correspond à quel processus, il faut se référer à l’ID du processus. On peut trouver cet ID dans le compteur Processus\ID de processus (ou Process\Process ID).
Identifier des threads
Dans le cas des threads, il n’est pas forcément facile d’identifier directement un thread qui consomme beaucoup de CPU avec perfmon. Le gros inconvénient est que dans la catégorie “Thread”, on ne peut pas choisir les threads correspondant à un processus, on est obligé d’ajouter tous les threads existants ce qui est, le plus souvent, inexploitable.
Par exemple pour identifier le thread responsable d’une grande consommation de ressource CPU, on peut aller dans la catégorie “Thread” et ajouter les compteurs:
Thread\% temps processeur (ou Thread\% Processor Time): ces compteurs permettent d’identifier le thread responsable ainsi que le processus parent.
Thread\N° du thread (ou Thread\ID thread): ces compteurs indiquent l’identifiant du thread en décimal. Il faut convertir cet identifiant en hexadécimal pour l’exploiter avec WinDbg par exemple.
Quand on sélectionne ces compteurs, un grand nombre de courbes sont rajoutées. La recherche est plutôt fastidieuse. Il ne faut pas confondre l’ID du thread et le numéro d’instance indiquée dans perfmon. Le numéro est spécifique à perfmon, il faut se référer à l’ID du thread correspondant au compteur concerné.
Par exemple, si on regarde les compteurs suivants:
Thread ID
L’instance permet de faire de rapprocher les 2 compteurs toutefois l’identifiant du thread est indiqué dans l’encadré rouge.
Utilisation de la mémoire
L’utilisation de la mémoire est le 2e point le plus important à monitorer car elle a un impact très direct sur l’exécution des processus. D’autre part, le fonctionnement anormal d’un processus qui pourrait occasionner une grande consommation de mémoire, peut avoir un impact sur tous les processus de la machine.
Mémoire\Mégaoctets disponibles Memory\Available MBytes
Ce compteur indique le nombre de mégaoctets disponibles en mémoire pour l’exécution des processus. Il s’agit d’une valeur instantanée. Si cette valeur est en dessous de 10% de la mémoire totale de la machine, la non disponibilité de mémoire libre pourrait occasionner une charge supplémentaire pour solliciter la mémoire virtuelle.
Page fault
Quand un processus est en cours d’exécution, il est exécuté dans un espace d’adresses mémoire virtuelle. Pour ses besoins, il sollicite le système d’exploitation pour que ce dernier lui alloue de la mémoire sous forme de page. Pendant le déroulement de l’exécution du processus, les pages allouées sont consultées pour écrire ou lire des objets. Le système d’exploitation traque les fréquences d’utilisation de ces pages pour savoir quelles sont les pages les plus fréquemment consultées par le processus. Les pages les plus fréquemment consultées seront mises en cache dans la mémoire RAM de façon à augmenter la vitesse d’exécution du processus. Les autres pages sont stockées dans la mémoire virtuelle sur le disque.
Si un processus souhaite accéder à une page mémoire qui ne se trouve pas dans la mémoire RAM, le système d’exploitation effectue un page fault (ou défaut de page) à la suite de laquelle, il va effectuer une copie de la page du disque vers la mémoire RAM. Le système d’exploitation suppose que la page sera éventuellement de nouveau consultée dans le futur. Le fait que la page soit dans la mémoire RAM rendra plus rapide l’exécution du processus.
Les page faults occasionnent donc beaucoup d’opérations par le système d’exploitation pour accéder à la page mémoire.
Processus\Plage de travail Process\Working set
Cette valeur indique la quantité de mémoire RAM en octets utilisée par un processus sans occasionner de page faults. Il s’agit d’une valeur instantanée. Cette valeur peut s’avérer intéressante si elle varie de façon significative au cours du temps.
Si la machine comporte beaucoup de mémoire, quand un processus libère de la mémoire, la page mémoire n’est pas forcément supprimée de la plage de travail (i.e. “working set”) du processus. La plage de travail d’un processus peut donc contenir des pages inutilisées.
Processus\Octets privés Process\Private bytes
Il s’agit de la quantité de mémoire totale en octets utilisée par un processus. Cette valeur est instantanée, de même que la valeur précédente c’est la variation au cours du temps qu’il faut observer. Si cette valeur augmente de façon plus ou moins rapide, il peut s’agir d’une fuite mémoire (i.e. memory leak).
Dans un contexte managé, cette valeur rassemble la quantité de mémoire managée et non managée.
Mémoire CLR .NET\Nombre d’octets dans tous les tas .NET CLR Memory\Bytes in all Heaps
Ce compteur indique la quantité de mémoire managée en octets dans tous les tas du processus. Ce compteur n’est utile que dans le contexte .NET. Elle permet de déduire la quantité de la mémoire non-managée en utilisant la formule: Processusoctets privés - Mémoire CLR .NETnombre octets dans tous les tas = Mémoirenon-managée
Mémoire\Octets du cache Memory\Cache Bytes
Ce compteur permet de connaître le nombre d’octets alloués en RAM pour des threads du kernel qui ne vont pas occasionnés un page fault. Il s’agit d’une valeur instantanée. Il faut comparer cette valeur à la quantité de mémoire RAM de la machine. Dans le cas d’une valeur élevée, il peut s’avérer que la machine manque de mémoire RAM.
Mémoire\Octets résidants dans le cache système Memory\Pool Nonpaged Bytes
Cette valeur correspond à la quantité de mémoire en octets allouées en RAM que le kernel ne peut pas déplacer dans la mémoire virtuelle sur le disque. C’est une valeur instantanée. Si cette valeur est trop grande (>75%), le système ne pourra plus allouer de la mémoire aux processus.
Mémoire\Pages/sec Memory\Pages/sec
Ce compteur indique la somme entre le nombre de pages lues et le nombre de pages écrites sur le disque pour résoudre le problème de page fault. Si cette valeur dépasse 50 de façon continue, il est fort probable que le système manque de mémoire.
Mémoire\Pages en entrée Memory Page Reads/sec
Il s’agit de la quantité moyenne de page mémoire virtuelle lue sur le disque par seconde. Cette valeur est à rapprocher de celles obtenues avec le compteur Mémoire\Pages/sec.
Mémoire\Pages en entrée Memory Page Reads/sec
Il s’agit de la quantité moyenne de page mémoire virtuelle écrite sur le disque par seconde. Cette valeur est à rapprocher de celles obtenues avec le compteur Mémoire\Pages/sec.
Fichier d’échange\Pourcentage d’utilisation Paging File\% Usage
Ce compteur permet d’indiquer la proportion du fichier contenant les pages de mémoire stockées en mémoire virtuelle sur le disque. Cette valeur permet de savoir si le fichier d’échange contenant la mémoire virtuelle est sous-dimensionnée.
Contexte managé
Dans un contexte managé, il est possible d’utiliser des compteurs supplémentaires qui pourront donner des indices supplémentaires sur un comportement d’un processus. Ces compteurs ne sont utilisables que pour des procesus .NET.
Verrous et threads CLR .NET\Taux de conflits/sec .NET CLR LocksAndThreads\Contention Rate/sec
Ce compteur indique le nombre de fois que le CLR tente d’acquérir un lock managé sans succès. Une valeur différente de 0 peut indiquer qu’une partie du code d’un processus provoque des erreurs.
Verrous et threads CLR .NET\Longueur de la file actuelle .NET CLR LocksAndThreads\Current Queue Length
Ce compteur permet de savoir quel est le nombre de threads attendant d’acquérir un lock managé dans un processus. Plus ce nombre est grand et plus il y a de la contention entre les threads ce qui peut révéler une mauvaise optimisation dans la synchronisation des threads d’un processus.
Verrous et threads CLR .NET\Nombre de threads actuels logiques .NET CLR LocksAndThreads\# of current logical threads
Cette valeur indique le nombre de threads managés de l’application. Les threads peuvent être stoppés ou en cours d’exécution. L’intérêt de ce compteur est de pouvoir surveiller une variation dans le nombre de threads d’un processus. Si cet indicateur augmente pendant l’exécution du processus, il peut s’agir d’un trop grand nombre de threads qui sont créés sans pouvoir être exécutés. Il s’agit d’une valeur instantanée.
Verrous et threads CLR .NET\Nombre de threads actuels physiques .NET CLR LocksAndThreads\# of current physical threads
Ce compteur indique le nombre de threads natifs du système d’exploitation appartenant au CLR effectuant des traitements pour des objets managés. Comme pour le compteur précédent, l’intérêt de ce compteur est de surveiller les variations dans le nombre de threads du processus. Une augmentation de cet indicateur peut révéler un trop grand nombre de threads créés par rapport à la capacité d’exécution du CLR.
Mémoire managée
Mémoire CLR.NET\Nombre d’octets dans tous les tas .NET CLR Memory\# Bytes in all heaps
Ce compteur est très utile pour suivre l’évolution de la mémoire managée d’un processus. Il correspond à la somme de la taille des tas de génération 1, 2 et des objets de grande taille.
Mémoire CLR.NET\Taille du tas de génération 0 (.NET CLR Memory\Gen 0 heap size) Mémoire CLR.NET\Taille du tas de génération 1 (.NET CLR Memory\Gen 1 heap size) Mémoire CLR.NET\Taille du tas de génération 2 (.NET CLR Memory\Gen 2 heap size) Mémoire CLR.NET\Taille du tas des objets volumineux (.NET CLR Memory\Large Object Heap Size)
Ces compteurs permettent d’évaluer l’évolution des compteurs des tas principaux d’un processus managé .NET. Ces compteurs peuvent être utiles pour monitorer le comportement du Garbage Collector pour un processus donné.
Détecter les anomalies
Dans cette partie, on va essayer de décrire quelques cas de figures les plus courants de façon à savoir comment utiliser perfmon pour faciliter un diagnostique concernant le comportement d’un processus.
Détecter une fuite mémoire dans un processus managé
Dans un contexte managé, on a tendance à penser qu’il n’est pas très important de détecter des fuites mémoire, le Gargage Collector est assez efficace pour ne jamais permettre la survenance de fuite mémoire. Ceci est vrai à condition de ne pas maintenir des liens vers des objets non utilisés. Dans le cas contraire si un lien est maintenu vers un objet qui n’est plus utilisé, le Garbage Collector sera incapable d’évaluer que cet objet doit être supprimé. Le plus souvent, c’est la source d’une fuite mémoire dans un contexte managé. Evaluer une fuite mémoire avec perfmon n’est pas forcément trivial, il faut avoir à l’esprit plusieurs choses:
Si un lien est maintenu vers un objet qui n’est plus utilisé, l’espace mémoire occupé par cet objet ne sera jamais libéré après exécution du Garbage Collector.
Le Garbage Collector ne s’exécute pas tout le temps. Il est amené à s’exécuter quand une demande importante en mémoire est requise. Ainsi, la quantité de mémoire managée d’un processus peut augmenter jusqu’à ce que le Garbage Collector s’exécute pour libérer de la mémoire. Ainsi l’augmentation constante de la mémoire utilisée par un processus au cours de son exécution n’est pas forcément synonyme de fuite mémoire.
Pour illustrer ces 2 points, on se propose d’exécuter un processus et d’afficher la mémoire managé de ce processus dans perfmon:
On implémente le code suivant:
internal class BigObject
{
private const string loremIpsum = "Lorem ipsum dolor ... laborum.";
private List<string> strings = new List<string>();
public void CreateObjects()
{
for (int i = 0; i < 100000; i++)
{
strings.Add(loremIpsum);
}
}
}
public class ManagedBigObjectGenerator
{
private List<BigObject> objects = new List<BigObject>();
public void CreateObjects()
{
for (int i = 0; i < 100000; i++)
{
this.objects.Add(new BigObject());
if (i % 10 == 0)
Thread.Sleep(100);
}
}
}
Ce code instancie un certain nombre d’objets sans jamais les libérer. Ces objets vont occuper un espace mémoire toujours plus important et ils ne seront jamais supprimé par le Garbage Collector car ils sont stockés dans une liste qui n’est jamais vidée.
On peut voir que la quantité de mémoire utilisée par le processus ne cesse d’augmenter.
Le graphique précédent présente les courbes suivantes:
En rouge: le nombre d’octets privés c’est-à-dire la mémoire totale occupée par le processus.
En bleu: le nombre d’octets dans tous les tas du processus, il s’agit de la quantité de mémoire managée.
En vert: le nombre d’octets dans tous les tas pour tous les processus managés de la machine.
Comme dans le cas d’une fuite mémoire réelle, la consommation de mémoire ne cesse de croître et ne se stabilise pas.
Cependant comme indiqué plus haut, dans certains cas, une augmentation continue de la mémoire ne signifie pas forcément une fuite mémoire:
Ainsi, si on implémente le code suivant:
public class ManagedBigObjectGeneratorWithWeakReferences
{
private List<WeakReference> objects = new List<WeakReference>();
public void CreateObjects()
{
for (int i = 0; i < 10000; i++)
{
this.objects.Add(new WeakReference(new BigObject()));
if (i % 10 == 0)
Thread.Sleep(100);
}
}
}
A la différence du code précédent, on utilise des objets de type WeakReference qui permettent de ne pas maintenir de liens avec les instances de BigObject qui sont créés. Ainsi le Garbage Collector peut supprimer les instances.
En affichant le compteur Mémoire CLR.NET\Nombre d'octets dans tous les tas dans perfmon, on constate dans un premier temps que la mémoire occupée augmente, toutefois après quelques minutes, cette quantité de mémoire se stabilise et cesse d’augmenter. La présence de l’objet WeakReference permet de ne pas maintenir un lien avec les objets et ils sont, ainsi, libérés par le Garbage Collector:
Ce graphique présente les mêmes courbes que précédemment:
En rouge: le nombre d’octets privés (mémoire totale occupée par le processus).
En bleu: le nombre d’octets dans tous les tas du processus (quantité de mémoire managée).
En vert: le nombre d’octets dans tous les tas pour tous les processus managés de la machine.
Détecter une fuite mémoire dans un processus non managé
Détecter une fuite dans un contexte non managée est plus rapide: dès qu’un objet est alloué sur le tas, s’il n’est pas libéré la mémoire ne peut pas être allouée à un autre objet. L’espace mémoire est ainsi perdu. Dans perfmon, il n’existe pas de compteur indiquant la quantité de mémoire non managée qui est utilisée. Pour détecter ce type de fuite mémoire, il faut utiliser 2 compteurs et déduire la mémoire non-managée à partir des compteurs:
Processus\Octets privés (ou Process\Private bytes): ce compteur permet d’indiquer la quantité de mémoire occupée le processus (mémoire managée + mémoire non managée).
La mémoire non managée peut être déduite en utilisant la formule: Processusoctets privés - Mémoire CLR .NETnombre octets dans tous les tas = Mémoirenon-managée
Ainsi si la quantité totale de mémoire du processus augmente sans que la mémoire managée augmente, cela signifie qu’il peut exister une fuite mémoire dans le code non managée. Si un processus présente une anomalie de ce type, l’évolution des compteurs pourrait ressembler à ces courbes:
Ce graphique présente les mêmes courbes que précédemment:
En rouge: le nombre d’octets privés (mémoire totale occupée par le processus).
En bleu: le nombre d’octets dans tous les tas du processus (quantité de mémoire managée).
En vert: le nombre d’octets dans tous les tas pour tous les processus managés de la machine.
Dans la courbe précédente, la quantité de mémoire managée (courbe bleue) reste à zéro car le code exécuté provient d’une assembly mixte contenant du code managé et du code natif (C++/CLI). Avec ce type d’assembly, perfmon ne détecte pas de code managé, c’est la raison pour laquelle cette courbe reste à zéro. Pour contourner ce problème, on affiche le nombre d’octets dans tous les tas pour tous les processus de la machine de façon à avoir une idée de l’évolution de la mémoire managée à l’échelle du processus.
Le but de cet article était d’indiquer les fonctionnalités principales de perfmon de façon à pouvoir l’utiliser rapidement. J’espère qu’il vous aura aider à configurer perfmon efficacement et surtout qu’il vous aura convaincu de l’utilité de perfmon pour monitorer une application ou une machine.
Il existe une fonctionnalité dans Visual Studio 2017 qui n’est pas évidente à repérer et qui consiste à avoir plusieurs frameworks cibles pour un projet donné. Traditionnellement dans Visual Studio, on crée un projet pour un framework donné, or depuis la multiplication récente des cibles de compilation (.NET Standard ou .NET Core), il peut être nécessaire de produire des assemblies destinées à des environnements différents à partir d’un même code.
On va, dans un premier temps, indiquer ce qui peut justifier l’utilisation de projets multi-target. Ensuite, on va indiquer la méthode pour générer des assemblies pour plusieurs frameworks cible. Enfin, on indiquera des directives à utiliser dans le code pour générer du code spécifique à une plateforme.
Les technologies Microsoft adressent un grand nombre d’environnements différents allant de systèmes d’exploitation comme Windows à des appareils mobiles comme les tablettes. D’autres parts, depuis quelques années, il est possible d’exécuter du code .NET sur d’autres plateformes que Windows. Cette ouverture a encore augmenté le nombre de plateformes sur lesquelles des technologies pouvaient s’exécuter: Linux, macOS, iOS, Android etc… Toutes ces plateformes ont des spécificités qui nécessitent, pour chacune d’entre elles, une implémentation particulière.
Pour Microsoft, un premier challenge a été de tenter d’uniformiser ses bibliothèques pour les rendre moins spécifiques à une plateforme. Ce premier travail a abouti à 3 grandes familles de technologies:
.NET Framework déployable sur des machines Windows,
.NET Core déployable sur Windows, Linux, macOS mais aussi sur des tablettes, smartphones et Xbox avec Universal Windows Platform (UWP).
Xamarin déployable sur Android et iOS.
Cette uniformisation ne permet pas, à elle-seule, d’utiliser un même code pour adresser plusieurs plateformes. Si on développe une bibliothèque, on est obligé d’avoir un projet spécifique pour chaque plateforme et il est nécessaire de compiler tout son code pour chacune des plateformes.
Pour permettre de compiler du code pour plusieurs plateformes et ainsi, encapsuler la complexité d’un déploiement sur plusieurs plateformes, une approche de Microsoft a été d’introduire une abstraction supplémentaire avec le .NET Standard.
.NET Standard
.NET Standard permet d’introduire une couche supplémentaire entre le code et les plateformes où seront déployées les bibliothèques:
Une bibliothèque .NET Standard définit un ensemble d’API qui sont communes à plusieurs plateformes.
Une bibliothèque .NET Standard n’est pas liée à une plateforme. Ainsi faire une bibliothèque se baser sur une version de .NET Standard permet d’éviter de la faire se baser sur une plateforme particulière. Il n’y a donc, plus de lien entre la bibliothèque et la plateforme sur laquelle elle sera déployée.
Cette caractéristique permet d’éviter d’écrire du code pour une plateforme spécifique. Le code de la bibliothèque est écrit pour une version du .NET Standard.
La couche supplémentaire qu’est .NET Standard rend plus facile la mise à jour éventuelle d’une plateforme. Au lieu de compiler une bibliothèque pour une version spécifique de la plateforme, on la compile pour une version du .NET Standard.
Si la nouvelle version d’une plateforme est compatible avec le .NET Standard sur lequel se base des bibliothèques, on peut mettre à jour la plateforme sans craindre une incompatibilité de ces bibliothèques. En effet c’est le .NET Standard qui va garantir la compatibilité.
Différences entre une bibliothèque et un exécutable
L’approche .NET Standard ne convient pas dans tous les cas. Elle permet de faciliter le déploiement de bibliothèques en ajoutant une abstraction de façon à éviter de baser ces bibliothèques directement sur des plateformes. Cette approche est possible car dans la majorité des cas, une bibliothèque de classes n’utilisent pas d’API spécifiques à une plateforme donnée.
En revanche, si une bibliothèque utilise des API trop spécifiques à une plateforme (comme par exemple, WPF qui nécessite un système Windows), elle ne pourra pas se baser sur .NET Standard (.NET Standard ne comporte pas de classes WPF).
De la même façon, un exécutable est spécifique à une plateforme. On ne pourra pas baser une exécutable sur un .NET Standard. Un exécutable est implémenté pour une plateforme précise.
Pour rendre l’approche .NET Standard la plus efficace possible, il faut donc placer un maximum de code dans des bibliothèques qui se basent sur .NET Standard. Le reste du code, étant plus spécifique, se basera sur une plateforme précise.
.NET Core
En plus de .NET Standard qui permet une certaine abstraction, la technologie .NET Core est capable de compiler du code pour des plateformes différentes. En effet .NET Core est une implémentation de Microsoft qui a pour but de rendre la technologie .NET disponible sur plusieurs plateformes. Contrairement à .NET Standard, .NET Core permet de produire des bibliothèques de classes et des exécutables. A la compilation, on précise le framework cible et l’environnement où ces assemblies seront exécutées (Windows, Linux, MacOS etc…).
Ces assemblies sont, ainsi, déployables et exécutables sur des environnements et des plateformes différents.
Fichiers projet .csproj simplifiés
.NET Core et .NET Standard ont introduit une grande flexiblité dans la technologie .NET puisqu’ils permettent de facilement générer des assemblies exécutables sur des plateformes différentes. De façon à rendre ces technologies plus facilement implémentables sur des plateformes différentes de Windows, Microsoft a fait un grand effort pour simplifier l’installation d’un environnement de développement en passant par la CLI .NET Core (CLI pour Command Line Interface) et éviter l’installation trop complexe de Visual Studio. Dans son effort de simplification, les fichiers projet .csproj ont aussi été considérablement simplifié pour ne conserver que le stricte minimum en élément de configuration de façon à ce qu’ils soient facilement éditables à la main.
Par exemple, le fichier .csproj d’un projet permettant de produire un exécutable .NET Core contient les éléments suivants:
Contrairement aux fichiers .csproj traditionels, par défaut le nouveau format n’indique pas explicitement les fichiers de code du projet. Tous les fichiers .cs font partie du projet, il n’est pas nécessaire de les spécifier un à un.
On peut toutefois spécifier les fichiers un à un ou avec une wildcard en désactivant le comportement par défaut avec l’élément de configuration EnableDefaultCompileItems et en utilisant l’option Compile:
On peut rajouter une référence d’un projet vers un autre en exécutant la commande CLI suivante:
dotnet add <chemin .csproj où ajouter la dépendance> reference
<chemin .csproj à rajouter>
PackageReference vs packages.config
L’élément de configuration PackageReference concerne les packages NuGet installés pour le projet. Par exemple, si on rajoute le package NuGetMicrosoft.AspNet.WepApi.Core au projet, le contenu du fichier projet .csproj devient:
On peut ajouter une référence vers un package NuGet en exécutant la commande CLI suivante:
dotnet add <chemin .csproj> package <nom du package NuGet>
Le fichier .csproj ne contient qu’une référence vers le package NuGet rajouté. Toutes les dépendances transitives du package ne sont pas indiquées dans le fichier. Les dépendances du packages NuGet ne sont pas rajoutées au fichier contrairement aux fichiers .csproj traditionnels.
Dans les projets Visual Studio traditionnels, les références vers les packages NuGet installés et les dépendances transitives sont ajoutés dans le fichier packages.config. D’autre part, le fichier projet .csproj contient des références vers les assemblies du package NuGet.
Configurer un projet multi-target
On peut facilement configurer le projet pour compiler le code pour plusieurs frameworks cibles en modifiant l’élément de configuration TargetFramework. Dorénavant, avec les nouveaux fichiers projet .csproj, il faut juste renommer l’élément TargetFramework en TargetFrameworks (avec un “s”):
Dans cet exemple, on produit des assemblies pour une application .NET Core 2.0 et une bibliothèque de classes pour .NET Standard 2.0. Les éléments netcoreapp2.0 et netstandard2.0 sont appelés TFM (pour Target Framework Moniker). Chaque code TFM correspond à un framework cible particulier, par exemple:
Utiliser des fichiers projet simplifiés dans Visual Studio
Le fichier projet .csproj traditionnel dans Visual Studio contient énormément de détails comme:
La liste des fichiers .cs de code du projet,
La liste des références d’assembly du projet qui peuvent être des assemblies tiers, des assemblies provenant d’un autre projet de la solution ou d’assemblies provenant de packages NuGet.
La liste des packages NuGet installés ainsi que les dépendances de chaque package est présente dans un fichier packages.config présent dans le projet.
Ces fichiers .csproj sont, malheureusement incontournables pour la plupart des projets générés dans Visual Studio en particulier les projets produisant des assemblies exécutables sur une plateforme Windows comme:
Les applications Winforms,
Les applications WPF,
Les projets ASP.NET,
Les applications Universal Windows (UWP).
En revanche il est possible d’utiliser des fichiers projet .csproj avec une syntaxe simplifiée pour les assemblies de type:
Bibliothèques de classes,
Applications console,
Applications ASP.NET Core,
Les applications .NET Core.
Configurer les packages NuGet en mode “PackageReference”
Cette configuration est valable pour tous les types de projet. Dans le mode par défaut, les dépendances NuGet sont indiquées dans un fichier packages.config présent dans le projet. Ce fichier contient plus précisement:
Les packages NuGet installés explicitement et
Les dépendances des packages NuGet installés.
Par exemple, si on installe dans un projet le package NuGetMicrosoft.AspNet.Mvc, ce package sera installé et ajouté dans le fichier packages.config. D’autre part, les dépendances transitives de ce package seront aussi installées à savoir:
Les assemblies contenues dans ces packages seront ajoutées au projet et visibles dans la partie “Références” (ou References) dans Visual Studio:
Pour configurer le mode “PackageReference” dans Visual Studio 2017:
Cliquer sur le menu “Outils” (ou “Tools”) ⇒ “Options”
Aller dans la partie “Gestionnaire de package Nuget” (ou “Nuget package manager”) ⇒ “Général”
Dans la partie “Gestion de packages” (ou “package management”), sélectionner le paramètre “Format de gestion de package par défaut”: “PackageReference” au lieu de “packages.config”:
Cliquer sur OK
Si avec cette configuration, on crée un nouveau projet (quel que soit le type) et si on ajoute un package NuGet, par exemple en exécutant dans la console du gestionnaire de package (i.e. Package Manager Console):
install-package Microsoft.AspNet.Mvc
La présentation du projet dans Visual Studio est un peu différente:
Il n’y a plus de fichier packages.config
On ne voit plus qu’une référence vers le package NuGet installé, les dépendances transitives du package NuGet ne sont plus visibles:
Dans le fichier .csproj, il y a une référence vers le package installé mais pas de liens vers les dépendances transitives du package:
De même, il n’y a pas de répertoire packages dans le répertoire du projet contenant les packages NuGet téléchargés. Les packages NuGet sont téléchargés dans le répertoire par défaut du cache c’est-à-dire:
%LocalAppData%\NuGet\Cache
L’utilisation du mode “PackageReference” présente plusieurs avantages:
Il simplifie considérablement le fichier projet .csproj puisqu’il n’y a plus les références d’assemblies. En effet, ces références changeaient à chaque mise à jour du package.
On ne voit plus les dépendances transitives des packages qui alourdissaient les fichiers projet .csproj.
En revanche, la résolution des conflits de versions dans les packages NuGet est plus complexe. Pour faciliter cette résolution, on peut:
On peut utiliser des wildcards pour indiquer la version de la dépendance:
<PackageReference Include ="Microsoft.AspNet.Mvc" version="5.2.*"/>
On peut aussi indiquer des contraintes de version:
1.0
1.0 ≤ x
Version 1.0 ou supérieure
(1.0,)
1.0 < x
Version strictement supérieure à 1.0
[1.0]
x == 1.0
Exactement la version 1.0
(,1.0]
x ≤ 1.0
Version 1.0 ou antérieure
(,1.0)
x < 1.0
Version strictement antérieure à 1.0
[1.0,2.0]
1.0 ≤ x ≤ 2.0
Version entre la 1.0 et 2.0
(1.0)
indication non valide
Par exemple:
<PackageReference Include ="Microsoft.AspNet.Mvc" version="[5.0.0,5.2)"/>
Forcer l’utilisation d’un répertoire “packages” avec le mode “PackageReference”
On peut toutefois forcer la présence du répertoire packages dans le répertoire du projet en éditant le fichier .csproj et en ajoutant l’élément de configuration RestorePackagePath:
Configurer un projet multi-target dans Visual Studio 2017
Comme indiqué plus haut, cette fonctionnalité est disponible pour les fichiers .csproj à la syntaxe simplifée. Cette syntaxe est possible seulement pour certains types de projet:
Bibliothèques de classes,
Applications console,
Applications ASP.NET Core,
Les applications .NET Core
Ainsi dans Visual Studio, si on crée un projet de type Console pour le framework.NET Core, les références du projet sont présentées de façon différente. Elles sont disponibles dans la partie “Dépendances” (i.e. Dependancies) du projet:
Traditionnellement dans les propriétés du projet, il est possible de modifier le framework cible. Pour accéder aux propriétés du projet, il faut:
Faire un clique droit sur le projet dans Visual Studio
Cliquer sur Propriétés
Dans l’onglet “Application”, on peut éditer le paramètre “framework cible”:
Pour configurer le projet pour cibler plusieurs frameworks, il faut:
Faire un clique droit sur le projet.
Cliquer sur “Modifier <nom du projet>” (i.e. “Edit <nom du projet>”).
Il est possible d’éditer le fichier .csproj directement dans Visual Studio (dans les versions actuelles, il n’existe pas d’éléments graphiques dans Visual Studio pour effectuer cette modification). Si “Modifier <nom du projet>” n’est pas présent, c’est que la syntaxe du fichier projet .csprojn’est pas une syntaxe simplifiée.
Il n’y a pas d’assistants pour passer d’une syntaxe traditionnelle à une syntaxe simplifiée.
Comme précédemment, il faut modifier le paramètre TargetFramework en ajoutant des TFM (i.e. Target Framework Moniker):
Après rechargement du fichier par Visual Studio, les dépendances contiennent plusieurs frameworks cible:
En allant dans les propriétés du projet, on ne peut plus éditer le paramètre “Framework cible”:
Pourquoi configurer plusieurs plateformes cible alors qu’on peut utiliser .NET Standard ?
On peut se poser la question de savoir quelle est la nécessité de paramétrer plusieurs plateformes cible alors qu’il suffit de paramétrer une plateforme cible .NET Standard. Comme .NET Standard est compatible avec plusieurs frameworks (on peut voir les compatibilités sur la page docs.microsoft.com/fr-fr/dotnet/standard/net-standard), en configurant la plateforme cible .NET Standard, on s’assure d’être compatible avec tous les frameworks prenant en charge par le standard. C’est vrai, toutefois:
Comme indiqué plus haut, .NET Standard permet de produire des assemblies seulement pour les bibliothèques de classes. On ne peut pas paramétrer une cible correspondant à .NET Standard pour un exécutable. Si on souhaite produire des exécutables différents pour un même code, il faut pouvoir paramétrer des frameworks cibles différents.
Certains packages NuGet comportent des assemblies spécifiques à une plateforme donnée. Ces plateformes peuvent être différentes d’une version de .NET Standard. En paramétrant des frameworks cible précis, si la compilation réussit, on peut être sûr que les dépendances NuGet seront assurées pour les cibles paramétrées.
Un des intérêts de cette fonctionnalité est de produire des assemblies pour plusieurs frameworks à partir d’un même code. Il est possible d’affiner la compilation en appliquant des directives de compilation pour des plateformes spécifiques. On s’assure, ainsi, à la compilation que le code compilé est compatible avec le framework auquel il est destiné. Ces directives de compilation seront indiquées par la suite.
NuGet est intégré à MSBuild
Pour permettre de simplifier les fichiers, NuGet a été intégré à MSBuild. Cette intégration a plusieurs avantages:
L’exécution de NuGet fait partie d’une tâche MsBuild qu’on peut lancer directement en exécutant MsBuild. Par exemple, pour générer un package NuGet, on peut lancer la tâche suivante:
msbuild.exe "<chemin du fichier projet .csproj>" /t:pack
On peut générer un package NuGet directement à la compilation du projet en allant dans les propriétés du projet dans Visual Studio, dans l’onglet “Package” et en cochant “Generate NuGet package on build”. On peut ainsi préciser des paramètres liés au package NuGet à générer, par exemple:
On peut effectuer le téléchargement des packages NuGet directement avec MsBuild dans une usine de build, on n’est plus obligé de configurer une étape supplémentaire pour exécuter nuget restore.
Possibilité d’avoir des symboles de préprocesseur dans le code.
On peut préciser des symboles de préprocesseur pour que des parties du code soient compilées pour une plateforme cible spécifique.
Par exemple:
public static class MultiTargetCode
{
public static string GetTargetFramework()
{
#if NETCOREAPP2_1
return ".NET Core";
#elif NETFULL
return ".NET Framework";
#else
throw new NotImplementedException();
#endif
}
}
Dans un article précédent, j’avais eu l’occasion d’évoquer les points les plus essentiels de la syntaxe Typescript (cf. L’essentiel de la syntaxe Typescript en 10 min). Volontairement, cet article ne traitait pas des modules, des exports et des imports d’objets de façon à parler de ces sujets dans un article à part entière. La raison principale qui a motivé un article séparé est que les modules correspondent à un sujet plus complexe que les différents éléments de syntaxe Typescript.
En effet, la définition des modules en Typescript hérite de la complexité des modules en Javascript. Comme on a pu l’indiquer dans un article consacré aux modules Javascript, il y a différentes méthodes pour définir des modules en Javascript. Etant donné que ce langage ne prévoyait pas de façon native les modules, ces différentes méthodes correspondent à autant de solutions pour tenter de les implémenter. A partir d’ECMAScript 2015 (i.e. ES6), l’implémentation de modules en Javascript peut se faire de façon native. Même si ES2015 a rendu obsolètes les solutions précédentes d’implémentation de modules, on ne peut pas complétement les ignorer car beaucoup de code existant les utilise encore.
Les modules Typescript sont moins complexes qu’ils y paraissent
De même que pour Javascript avant ES2015, Typescript a aussi, de son coté, dû trouver des éléments syntaxiques pour définir et implémenter des modules. Quand Javascript a implémenté ES2015, la syntaxe de Typescript s’est naturellement rapprochée de celle d’ES2015. La conséquence de cette évolution est que la notion de module peut être implémentée d’une part, avec des éléments syntaxiques spécifiques à Typescript et d’autre part, avec une syntaxe similaire à celle d’ES2015.
En préambule, cet article expliquera quelques éléments nécessaires à la compréhension des modules en Typescript. Dans un 2e temps, on indiquera quelques solutions pour implémenter des modules avant et après ES2015.
Avant de rentrer dans le détail des syntaxes Typescript permettant d’implémenter des modules, il faut savoir comment ces modules sont transpilés en code Javascript. Avant ES2015, la notion de module n’était pas native à Javascript, il a donc fallu trouver une façon d’implémenter des modules. La méthode a été d’utiliser le pattern module et des IIFE (i.e. Immediatly-Invoked Function Expression ou Expression de fonction invoquée immédiatement).
Pattern module
Sans rentrer dans les détails, le pattern module permet d’implémenter la notion de module en Javascript avant ES2015. Ce pattern utilise une IIFE (i.e. Immediatly-Invoked Function Expression ou Expression de fonction invoquée immédiatement) pour définir le contenu du module. Une IIFE est un bloc de code qui est exécuté tout de suite après avoir été parsé. Dans ce bloc de code, on peut ainsi définir ce qui sera le module.
Une IIFE s’écrit de cette façon:
var Module = (function() {
// Bloc de code à exécuter
})();
Pour utiliser une IIFE pour définir un module, on peut écrire par exemple:
var Module = (function() {
var self = {};
function privateFunc() {
// ...
};
self.publicFunc = function() {
privateFunc();
};
return self;
})();
Cette écriture permet de définir une variable appelée Module qui va contenir des membres et des fonctions, ce qui correspond à la notion de module:
privateFunc() est une fonction privée.
publicFunc() est une fonction publique.
Pour utiliser ce type de module, on peut l’instancier et l’appeler de cette façon:
var moduleInstance = new Module();
moduleInstance.publicFunc();
Pour être compatible avec ES5, les modules Typescript sont transpilés en utilisant le pattern module (pour plus de détails sur la syntaxe Javascript du pattern module, voir Les modules en Javascript en 5 min).
Directive “Triple-slash”
Cette directive dans l’en-tête d’un fichier Typescript permet d’indiquer au compilateur une référence vers un autre fichier en indiquant son emplacement physique. Le chemin est relatif par rapport au fichier contenant la référence. Cette directive doit être placée dans l’en-tête du fichier pour être valable, elle est de type:
/// <reference path="fichier.ts" />
Ce type de directive est essentiellement utilisé pour référencer des fichiers Typescript externes à un projet. La plupart du temps, avec les fichiers de configuration tsconfig.json, elle n’est plus nécessaire puisqu’il est possible d’indiquer dans ce fichier les emplacements des fichiers à compiler.
Par exemple, pour ne pas utiliser de directives triple-slash, on peut utilser les éléments de configuration "files" ou "include" dans un fichier tsconfig.json:
Pour afficher la console de développement dans un browser
Pour tous les exemples présentés dans cet article, pour voir les résultats d’exécution, il faut afficher la console de développement:
Sous Firefox: on peut utiliser la raccourci [Ctrl] + [Maj] + [J] (sous MacOS: [⌘] + [Maj] + [J], sous Linux: [Ctrl] + [Maj] + [K]) ou en allant dans le menu “Développement web” ⇒ “Console du navigateur”.
Sous Chrome: utiliser le raccourci [F12] (sous MacOS: [⌥] + [⌘] + [I], sous Linux: [Ctrl] + [Maj] + [I]) puis cliquer sur l’onglet “Console”. A partir du menu, il faut aller dans “Plus d’outils” ⇒ “Outils de développement”.
Sous EDGE: utiliser le raccourci [F12] puis naviguer jusqu’à l’onglet “Console”.
Le résultat de la compilation est de type:
Executed from module1.privateFunc()
Executed from module2.privateFunc()
Executed from module2.publicFunc()
Executed from module3.privateFunc()
Executed from module3.publicFunc()
Executed from module1.publicFunc()
Suppression du cache du browser
Sachant que tous les exemples présentés dans cet article utilisent la même URL http://localhost:8080, il peut subvenir certaines erreurs pendant leur exécution. Ces erreurs peuvent être dues au cache utilisé dans les browsers, en particulier pour les fichiers Javascript. Pour éviter que d’anciennes versions du fichiers restées dans le cache ne soient exécutées à la place de nouveaux fichiers:
On peut forcer le rechargement de la page avec le raccourci [Ctrl] + [Maj] + R
On peut aussi supprimer les fichiers se trouvant dans le cache en exécutant le raccourci [Ctrl] + [Maj] + [Supp]
Implémenter des modules en Typescript
Il existe plusieurs méthodes pour implémenter des modules en Typescript:
Utiliser des namespaces: ils se rapprochent de la notion de namespace en C#. Ils sont transpilés en modules en Javascript.
Avant ES2015/ES6: il faut utiliser des formats pour étendre la syntaxe Javascript pour permettre l’implémentation de modules. Ces formats peuvent CommonJS, AMD (i.e. Asynchronous Module Definition) ou UMD (i.e. Universal Module Definition). Ces formats doivent être associés à des loaders qui permettent de charger les modules transpilés en Javascript au runtime.
Utiliser la syntaxe ES2015/ES6: à partir d’ES2015, Javascript prévoit des éléments de syntaxe pour implémenter nativement des modules. En Typescript, la syntaxe permettant d’implémenter ce type de module est très proche de celle en Javascript.
Namespaces
Les namespaces correspondent à une notion spécifique à Typescript pour implémenter des modules en Javascript. Les namespaces en Typescript sont très semblables aux namespaces en C#: il s’agit d’un découpage du code en bloc correspondant à des modules logiques.
Comme pour les namespaces en C#, les namespaces Typescript:
Ont des noms qui se définissent avec une hiérarchie du type <namespace1>.<namespace2>.<namespace3>, par exemple:
mainNs.intermediateNs.innerNs
Les blocs de code sont inclus dans les namespaces, par exemple:
namespace nsName {
// Bloc de code
}
Sont indépendants des fichiers Typescript: on peut utiliser un même namespace dans des fichiers différents. Les éléments dans le namespace seront, ainsi, regroupés.
Les namespaces sont une approche permettant d’implémenter des modules en Javascript mais elle n’est pas la seule. D’autres approches permettent d’implémenter cette notion.
Avant Typescript 1.5, les namespaces Typescript étaient appelés “internal modules“. Ce terme prête particulièrement à confusion puisqu’il facilite la confusion entre la notion de module Typescript et les modules à proprement parlé en Javascript. Il est important d’avoir en tête que cette notion de namespace n’est pas tout à fait semblable aux modules en Javascript.
Mot clé namespace et module sont strictement équivalents
Au niveau de la syntaxe Typescript, le mot clé namespace peut être remplacé par le mot clé module. Dans ce contexte, les 2 mots clé sont équivalents.
Cet exemple permet d’illuster des appels d’un module à l’autre. Les différents modules sont définis dans des namespaces différents.
Par exemple, le namespacemodule1Namespace qui se trouve dans le fichier module1.ts:
namespace module1Namespace {
function privateFunc() {
console.log("Executed from module1.privateFunc()");
}
export function publicFunc() {
privateFunc();
console.log("Executed from module1.publicFunc()");
namespaceForModule2.publicFunc();
}
}
Dans ce fichier, on importe le namespacemodule2Namespace se trouvant dans le fichier module2.ts de cette façon:
import namespaceForModule2 = module2Namespace;
On peut ensuite appeler une fonction se trouvant dans le namespacemodule2Namespace en écrivant:
namespaceForModule2.publicFunc();
L’utilisation de la directive import est complétement facultative et sert uniquement à définir l’alias namespaceForModule2, on peut se contenter d’appeler directement:
module2Namespace.publicFunc();
De même que précédemment, pour compiler cet exemple:
Il faut exécuter les instructions suivantes pour, respectivement, installer les packages npm, compiler et démarrer le serveur de développement:
user@debian:~/typescript_modules/typescript_namespace% npm install && npm run build && npm start
Ouvrir la page http://localhost:8080 dans un browser.
On peut remarquer que le résultat de la compilation produit un module au sens Javascript en utilisant le pattern module. Par exemple, si on regarde le résultat de la compilation du contenu du fichier module1.ts dans le fichier public/module1.js:
var namespaceForModule2 = module2Namespace;
var module1Namespace;
(function (module1Namespace) {
function privateFunc() {
console.log("Executed from module1.privateFunc()");
}
function publicFunc() {
privateFunc();
console.log("Executed from module1.publicFunc()");
namespaceForModule2.publicFunc();
}
module1Namespace.publicFunc = publicFunc;
})(module1Namespace || (module1Namespace = {}));
Les namespaces peuvent être mergés
Les namespaces peuvent être mergés. Ainsi on peut définir des objets dans un même namespace réparti sur plusieurs fichiers Typescript à condition de ne pas avoir de collision dans le nommage des objets exportés.
Par exemple, on définit le namespacemodule2Namespace dans le fichier module2.ts:
namespace module2Namespace {
function privateFunc() {
console.log("Executed from module2.privateFunc()");
}
export function publicFunc() {
privateFunc();
console.log("Executed from module2.publicFunc()");
otherPublicFunc();
}
}
Et dans le fichier module3.ts:
namespace module2Namespace {
function privateFunc() {
console.log("Executed from privateFunc() in module3.ts");
}
export function otherPublicFunc() {
privateFunc();
console.log("Executed from otherPublicFunc() in module3.ts");
}
}
A condition d’exporter des éléments avec le mot clé export, on peut utiliser plusieurs fichiers pour définir un namespace. Les fichiers module2.ts et module3.ts seront transpilés en 2 fichiers Javascript qui définissent un seul module Javascript.
Pour compiler, il faut exécuter:
user@debian:~/typescript_modules/typescript_merging_namespace% npm install && npm run build
Parmi les fichiers générés, on obtient module2.js:
var module2Namespace;
(function (module2Namespace) {
function privateFunc() {
console.log("Executed from module2.privateFunc()");
}
function publicFunc() {
privateFunc();
console.log("Executed from module2.publicFunc()");
module2Namespace.otherPublicFunc();
}
module2Namespace.publicFunc = publicFunc;
})(module2Namespace || (module2Namespace = {}));
Et module3.js:
var module2Namespace;
(function (module2Namespace) {
function privateFunc() {
console.log("Executed from privateFunc() in module3.ts");
}
function otherPublicFunc() {
privateFunc();
console.log("Executed from otherPublicFunc() in module3.ts");
}
module2Namespace.otherPublicFunc = otherPublicFunc;
})(module2Namespace || (module2Namespace = {}));
On remarque que ces fichiers permettent de définir un même module nommé module2Namespace.
Il faut ensuite ouvrir un browser à l’adresse http://localhost:8080 et afficher la console de développement.
Implémenter des modules avant ES2015
Les namespaces Typescript ne correspondent pas tout à fait aux modules Javascript. Ils correspondent à un découpage logique du code qui peut être séparé en plusieurs fichiers. A l’opposé les modules Javascript sont découpés par fichier: un fichier correspond à un module le plus souvent.
Avant Typescript 1.5, namespace et module s’appelaient différemment:
Les namespaces s’appelaient “internal modules” et
Les modules s’appelaient “external modules“.
Même si les notions de namespace Typescript et de module sont différentes, après compilation du code, les namespaces Typescript sont transpilés en module Javascript en utilisant le pattern module. En effet, avant ES2015, Javascript ne gérait pas de façon native la notion de module. Le pattern module est un moyen de contournement pour définir des modules. Pour implémenter ces modules, on peut s’aider de formats qui vont apporter des mot-clés pour enrichir le langage Javascript et permettre une implémentation plus facile des modules sans écrire explicitement le pattern module.
En Typescript, on bénéficie de ces formats et on peut, comme en Javascript, les utiliser pour implémenter des modules Javascript avant ES2015. Au runtime, pour charger les modules en utilisant le format, il faut s’aider de loaders. Les formats les plus connus sont CommonJS, AMD (i.e. Asynchronous Module Definition) et UMD (i.e. Universal Module Definition). Les loaders les plus connus sont RequireJS (utlisant le format AMD), SystemJS (qui permet de gérer plusieurs formats).
CommonJS + SystemJS
CommonJS et SystemJS sont respectivement un format et un loader permettant d’implémenter les modules avant ES2015. Il existe d’autres formats comme AMD ou UMD. Un exemple d’implémentation de module en utilisant CommonJS se trouve dans le dépôt Github suivant: typescript_modules/typescript_commonjs. Cet exemple permet d’illustrer des appels entre modules.
Comme en Javascript, CommonJS permet de définir un format pour enrichir le langage avec une fonction qui va permettre d’effectuer des références vers un autre module. La fonction utilisée pour inclure des modules provenant d’un autre fichier est require.
Par exemple, si on écrit:
var moduleInFile = require('./file.js');
On définit une variable locale contenant le module se trouvant dans le fichier file.js. On peut directement utiliser les éléments se trouvant dans le module en les préfixant avec moduleInFile.
CommonJS sert de format pour la compilation. Pour l’exécution du code, il est nécessaire d’utiliser un loader qui va interpréter la syntaxe définie par le format CommonJS et charger les modules Javascript. SystemJS est un loader qui permet d’interpréter le format CommonJS.
Dans le cas de notre exemple, si on regarde le code du module se trouvant dans le fichier module1.ts:
import importedModule2 = require('./module2');
function privateFunc() {
console.log("Executed from module1.privateFunc()");
importedModule2.publicFunc();
}
export function publicFunc() {
privateFunc();
console.log("Executed from module1.publicFunc()");
}
On importe le module2 en utilisant la fonction require du format CommonJS:
import importedModule2 = require('./module2');
Puis on utilise l’alias défini pour appeler une fonction se trouvant dans le module2:
importedModule2.publicFunc();
Pour compiler, il faut exécuter:
user@debian:~/typescript_modules/typescript_commonjs% npm install && npm run build
Après compilation, la syntaxe produit des modules compatibles avec le format CommonJS:
"use strict";
Object.defineProperty(exports, "__esModule", { value: true });
var importedModule2 = require("./module2");
function privateFunc() {
console.log("Executed from module1.privateFunc()");
importedModule2.publicFunc();
}
function publicFunc() {
privateFunc();
console.log("Executed from module1.publicFunc()");
}
exports.publicFunc = publicFunc;
Pour exécuter ce code, il faut effectuer quelques ajouts dans la page HTML principale en important systemJS puis en le configurant:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Test module Typescript with /// (triple-slash)</title>
<script src="node_modules/systemjs/dist/system.js"></script>
<script>
// Le code suivant correspond à de la configuration
SystemJS.config({
meta:{
format: 'cjs' // cjs correspond à la configuration pour le format commonjs
},
packages: {
"/public": { defaultExtension: "js" } // pour charger par défaut les fichiers avec l'extension JS
}
});
SystemJS.import('public/index.js');
</script>
</head>
<body>
</body>
</html>
Pour exécuter cet exemple, il faut exécuter la commande:
Il est possible d’utiliser la syntaxe ES2015 dans le code Typescript pour définir des modules Javascript. Les modules Javascript ainsi compilés ont les mêmes caractéristiques que des modules ES2015 classiques. Ils sont supportés nativement par Node.js et par les browsers à partir d’une certaine version:
Chrome à partir de la version 63.
Firefox à partir de la version 60,
Edge à partir de la version 16,
Safari à partir de la version 11,
Node.js à partir de la version 10.
Pour plus d’informations sur les compatibilités des browsers:
Le code Javascript comportant des modules ES2015 s’exécute de plusieurs façons:
Exécuter le code Javascript sur un serveur Node.js: à partir de la version 10, Node.js gère nativement le chargement de modules au format ES2015.
Il est aussi possible d’associer un loader comme RequireJS ou SystemJS qui va charger lui-même les modules.
Les propriétés les plus importantes à avoir en tête avec les modules ES2015 sont les suivantes:
Par défaut, tous les modules ES2015 sont privés.
Un fichier Javascript correspond à un module.
Pour exposer des éléments comme des variables, des fonctions ou des classes à l’extérieur d’un module, il faut utiliser le mot-clé export.
Exporter un module
La syntaxe Typescript utilisant des modules est semblable à celle en Javascript. Il faut exporter explicitement les éléments pour les utiliser à l’extérieur d’un module.
Pour exporter, on utilise le mot-clé export.
Par exemple:
export function func1() {
// ...
}
Dans cet exemple, on exporte une fonction à l’extérieur du module.
D’autres formes de syntaxe sont possibles pour exporter plusieurs éléments du module en une fois:
function func1() {
// ...
}
function func2() {
// ...
}
export { func1, func2 };
On peut aussi indiquer l’instruction export avant la déclaration des éléments à exporter:
export { func1, func2 };
function func1() {
// ...
}
function func2() {
// ...
}
On peut indiquer un alias lors de l’export:
export { func1 as exporterFunc1 };
function func1() {
// ...
}
Importer un module
L’import d’un module correspond à importer les éléments exportés par ce module dans un autre.
Pour importer tous les éléments exportés d’un module dans une variable, on peut utiliser la syntaxe:
import * as moduleInFile from './file';
Dans ce cas, la variable est moduleInFile, on peut l’utiliser directement pour accéder aux éléments du module, par exemple:
moduleInFile.func1();
On peut importer un élément spécifique et non pas tous les éléments exportés du module en précisant les éléments à importer à partir de leur nom, par exemple:
import { func1 as funcFromOuterModule, func2 } from './file';
func1 as funcFromOuterModule permet de renommer le nom de l’élément importé. Cette déclaration est facultative, ainsi elle n’est pas utilisée pour func2.
Dans ce cas, on peut appeler directement les fonctions:
func2();
funcFromOuterModule();
Export par défaut
L’export d’un élément par défaut permet d’indiquer l’élément qui sera importé dans un module si ce dernier ne précise pas ce qui doit être importé. Ainsi, au moment d’importer l’élément d’un module, il ne sera pas nécessaire de préciser le nom de l’élément à importer, l’élément par défaut sera le seul élément importé même si le fichier comporte d’autres éléments.
Par exemple:
function func1() {
// ...
}
function func2() {
// ...
}
export default func1;
Au moment d’importer, le seul élément importé sera l’élément exporté par défaut:
import func1 from "file";
L’import ne comporte pas d’accolades. C’est l’élément par défaut qui est importé.
L’élément importé par défaut peut être utilisable directement:
func1();
Export nommé
On peut nommer un export de façon à modifier le nom de l’élément qui est exporté.
Par exemple, dans un premier temps on exporte un élément en le renommant:
function func1() {
// ...
}
function func2() {
// ...
}
export default func1;
export var finalFunc = func2;
En plus de l’élément par défaut, on décide de renommer un élément exporté.
A l’import, il faut indiquer le nouveau nom de l’élément:
import { finalFunc } from "./file";
On peut directement utilisé le nouveau nom de l’élément:
finalFunc();
Dans cet exemple, si on souhaite importer l’élément par défaut, on peut écrire:
import func1, { finalFunc } from "./file";
Configuration du compilateur
Il existe une option de compilation qui permet d’indiquer la syntaxe à utiliser pour les modules dans le code Javascript et pour générer du code Javascript avec une syntaxe différente. L’option module permet d’indiquer le format à utiliser pour la génération des modules:
{
"compilerOptions": {
"module": "es6"
}
}
Les valeurs possibles sont "CommonJS", "AMD", "UMD", "ES6", "ES2015", "ESNEXT" ou "None". Si on utilise "None", on ne peut pas déclarer des modules dans le code Typescript. Il ne faut pas confondre ce paramètre avec target qui indique la version d’ECMAScript cible de compilation. La configuration module ne concerne que le format utilisé pour les modules.
Ainsi, si on utilise l’option:
"es6" ou "es2015": il faut préciser l’extension ".js" dans les déclarations import dans les fichiers Typescript, par exemple:
import { finalFunc } from "./file.js";
Cette déclaration sera transpilée tel quel dans le fichier Javascript. Au runtime, pour que le browser ou Node.js puisse trouver le fichier à importer, il faut qu’il comporte l’extension du fichier Javascript.
"CommonJS": le format généré sera CommonJS. Au runtime, il faut associer ce format à un loader comme par exemple SystemJS.
"AMD": le format généré sera AMD. De même au runtime, il faut associer ce format à un loader comme par exemple RequireJS.
"UMD": le format généré sera UMD (i.e. Universal Module Definition). Ce format permet de générer compatible avec plusieurs formats comme AMD et CommonJS.
On peut aussi préciser le format au moment d’exécuter le compilateur:
tsc --module <nom du format>
Par exemple:
tsc --module es6
Exemple avec la syntaxe ES2015/ES6
Un exemple d’implémentation de modules en utilisant la syntaxe ES2015/ES6 se trouvent dans le dépôt Github suivant: typescript_modules/typescript_es6. Cet exemple permet d’illustrer des appels d’un module à l’autre en utilisant la syntaxe ES6.
Pour exécuter cet exemple:
Il faut exécuter les instructions suivantes pour, respectivement, installer les packages npm, compiler et démarrer le serveur de développement:
user@debian:~/typescript_modules/typescript_es6% npm install && npm run build && npm start
Ouvrir la page http://localhost:8080 dans un browser.
Un exemple d’implémentation de modules générés au format AMD se trouve dans le dépôt Github suivant: typescript_modules/typescript_es6_amd. Cet exemple permet d’illustrer la génération des modules au format AMD.
Pour exécuter cet exemple, il faut installer les packages en exécutant les commandes:
Il faut exécuter les instructions suivantes pour, respectivement, installer les packages npm, compiler et démarrer le serveur de développement:
user@debian:~/typescript_modules/typescript_es6_amd% npm install && npm run build && npm start
Ouvrir la page http://localhost:8080 dans un browser.
Le format AMD ajoute une fonction qui n’existe pas dans la syntaxe Javascript: define. Cette fonction comporte 2 paramètres:
Une tableau de dépendances: ce sont les fichiers nécessaires à l’exécution de la fonction.
Une fonction: cette fonction est le module à définir.
On peut voir un exemple d’utilisation de la fonction define en regardant le résultat de la compilation, par exemple dans le répertoire typescript_es6_amd/build/index.js:
L’attribut data-main="app" correspond au point d’entrée de l’application qui est à un fichier Javascript app.js contenant la configuration de requireJS.
Comme on a pu le voir pour l’exemple utilisant le format AMD, on a utilisé dans le code Typescript une syntaxe ES2015. Pourtant les modules ont été générés au format AMD qui compatible avec ES5. Il en est de même si on génère les modules en utilisant le format CommonJS.
Utilisation de “bundlers”
Les solutions présentées jusqu’içi ont un gros inconvénient: elles nécessitent d’inclure tous les fichiers Javascript générés dans le fichier HTML principal. Dans les exemples, on déclare les scripts Javascript correspondant aux différents modules de cette façon:
Ce type de déclaration peut être difficile à maintenir à l’échelle d’un grand projet.
Une solution pour palier à ce problème peut être d’utiliser des bundlers qui vont générer un fichier Javascript unique en incluant toutes les dépendances au moment de la compilation. Le code produit sera compatible ES5 et utilisable sur tous les browsers supportant ES5. Le gros inconvénient des bundlers est qu’ils vont générer un seul fichier contenant tout le code Javascript. Dans le cas d’une grosse application et si l’application comporte beaucoup de code Javascript, le temps de chargement du fichier bundle peut prendre du temps et ralentir le chargement de la page principale.
Exemple d’utilisation de webpack avec la syntaxe ES2015
Un exemple d’implémentation de modules en utilisant le bundler webpack se trouve dans le dépôt Github suivant: typescript_modules/webpack_es6. Cet exemple permet d’illustrer la génération d’un bundle contenant des modules implémentés au format ES2015.
Pour utiliser le bundler webpack, on a installé les packages webpack et ts-loader. Le packagets-loader permet à webpack de s’interfacer avec le compilateur Typescript. Pour exécuter webpack avec un serveur de développement, on a installé le packagewebpack-dev-server. Pour effectuer ces installations, on a exécuté la commande suivante:
Le fichier de configuration de webpack qui se trouve dans typescript_modules/webpack_es6/webpack.config.js permet d’indiquer qu’on souhaite utiliser le loaderts-loader et que le résultat de la compilation se fasse dans le fichier public/app.js. Le contenu de ce fichier est:
Exemple d’utilisation de webpack avec la syntaxe “namespace”
Les différentes syntaxes d’implémentation de modules sont possibles avec webpack. On a montré précédemment un exemple avec le format ES2015. Il est facile de transposer cet exemple en utilisant le format namespace spécifique à Typescript.
Un exemple d’implémentation avec la syntaxe des namespaces se trouve dans le dépôt Github suivant: typescript_modules/webpack_es6_namespace. L’exemple est le même que précédemment, à la différence de l’utilisation de namespaces pour déclarer des modules (la syntaxe générale des namespaces a été explicitée plus haut).
Comment le compilateur parcourt les modules ?
Pour trouver les modules suivant les références faites avec la directive triple-slash ou avec import, le compilateur effectue une étape de résolution. Cette résolution des modules se fait en partie en fonction de la configuration. De nombreux éléments de configuration peuvent avoir un impact sur la façon de réaliser cette résolution.
D’une façon générale, le compilateur Typescript tsc inclue dans son étape de compilation tous les fichiers qui se trouvent dans le répertoire du fichier de configuration tsconfig.json.
Avant de compiler ces fichiers, le compilateur va résoudre les dépendances de modules en fonction des directives import et triple-slash.
Paramètres de compilation “files”, “include” et “exclude”
Le comportement du compilateur lors de la résolution de modules peut être modifié par l’utilisation de certains paramètres dans le fichier tsconfig.json:
"files": ce paramètre permet d’indiquer les chemins absolus ou relatifs des fichiers à compiler:
Quand ce paramètre est présent, le compilateur ne va pas parcourir tous les fichiers .ts/.tsx/.d.ts présents dans le répertoire du fichier de configuration tsconfig.json mais seulement les fichiers précisés et leur références.
"include": permet d’indiquer des fichiers en utilisant des wildcards:
Les wildcards indiquées plus haut sont aussi utilisables avec le paramètre "exclude".
Import relatif et non-relatif
Il faut distinguer 2 types d’import:
Les imports relatifs: ces imports se font de façon relatives au fichier dans lequel on veut effectuer l’import. Ainsi si on écrit dans le fichier fileA.ts:
import * from './fileB.ts';
La recherche de la dépendance se fera dans le même répertoire que le fichier fileA.ts
Les imports non-relatifs: ces imports ne se font pas en fonction de l’emplacement du fichier dans lequel on effectue l’import. Il se fait dans des répertoires définis suivant une stratégie de recherche. Cette stratégie dépend de la configuration.
Pour ce type d’import, on indique directement le nom du module (sans indication de répertoire ou d’extension de fichier).
Par exemple:
import * from 'moduleName';
Stratégies de résolution des modules
Il existe 2 stratégies de résolution des modules:
"Classic": correspond à un parcours du répertoire de compilation et des répertoires parents.
"Node": cette stratégie imite la stratégie de résolution de Node.js avec les fichiers Javascript. Elle permet de parcourir le répertoire où se trouve le fichier .ts d’où se fait l’import ou le répertoire "node_modules".
On peut préciser la stratégie de résolution en ajoutant l’option --moduleResolution au lancement du compilateur:
tsc --moduleResolution "Node"
Par défaut, la stratégie est classique si le type de module choisi dans tsconfig.json est "AMD", "System" ou "ES6". Si un autre type de module est choisi, la stratégie est "Node".
Stratégie classique: “Classic”
La stratégie classique consiste à parcourir le répertoire de compilation du fichier d’où se fait l’import en cherchant les fichiers avec une extension .ts ou .d.ts:
Dans le cas d’un import relatif: la recherche se fait seulement dans le répertoire cible de l’import. Par exemple si le fichier dans /folder/file1.ts effectue un import:
import { module2 } from '../folder2/moduleName';
Alors le parcours se fera en cherchant successivement les fichiers /folder2/moduleName.ts et /folder2/moduleName.d.ts.
Dans le cas d’un import non-relatif: la recherche se fait dans le répertoire du fichier d’où se fait l’import et dans les répertoires parents.
Par exemple si le fichier dans /folder/file1.ts effectue un import:
import { module2 } from 'moduleName';
Alors le parcours se fera en cherchant successivement les fichiers: /folder/moduleName.ts, /folder/moduleName.d.ts, /folder/moduleName.ts et /folder/moduleName.d.ts.
Stratégie “Node”
Cette stratégie imite celle de Node.js pour la résolution des imports des fichiers Javascript:
Dans le cas d’un import relatif: le parcours se fait dans le répertoire du fichier d’où se fait l’import. Par exemple si le fichier dans /folder/file1.ts effectue un import:
import { module2 } from '../folder2/moduleName';
Alors le parcours se fera successivement en cherchant les fichiers:
/folder2/moduleName.ts, /folder2/moduleName.tsx ou /folder2/moduleName.d.ts
/folder2/moduleName/package.json (en utilisant la propriété "types" dans ce fichier)
/folder2/moduleName/index.ts, /folder2/moduleName/index.tsx ou /folder2/moduleName/index.d.ts.
Par exemple si le fichier dans /folder/file1.ts effectue un import:
import { module2 } from 'moduleName';
Alors le parcours se fera dans le répertoire node_modules se trouvant dans le répertoire du fichier en cherchant un fichier correspondant aux chemins suivants:
/folder/node_modules/moduleName.ts, /folder/node_modules/moduleName.tsx ou /folder/node_modules/moduleName.d.ts,
/folder/node_modules/moduleName/package.json,
/folder/node_modules/moduleName.index.ts, /folder/node_modules/moduleName.index.tsx ou /folder/node_modules/moduleName.index.d.ts.
Le parcours se fera, ensuite, dans le répertoire node_modules se trouvant dans un répertoire parent:
/node_modules/moduleName.ts, /node_modules/moduleName.tsx ou /node_modules/moduleName.d.ts,
/node_modules/moduleName/package.json,
/node_modules/moduleName.index.ts, /node_modules/moduleName.index.tsx ou /node_modules/moduleName.index.d.ts.
Paramètres de compilation “baseUrl”, “paths” et “rootDirs”
Ces paramètres peuvent modifier les chemins utilisés lors de l’application de la stratégie de recherche des modules à importer.
“baseUrl”
Il permet d’indiquer un préfixe que le compilateur appliquera systématiquement aux imports non-relatifs. Ce paramètre peut être précisé à l’exécution du compilateur:
tsc --baseUrl "../moduleFolder/"
Il peut aussi être précisé dans le fichier tsconfig.json:
“paths”
Ce paramètre permet de préciser un mapping entre des noms de module et leur chemin effectif. La valeur du paramètre "baseUrl" est rajouté aux chemins des mappings précisés dans "paths".
L’import sera fait en cherchant dans les répertoires: ../moduleFolder/otherModuleFolder1/moduleName et ../moduleFolder/otherModuleFolder2/moduleName.
Il est aussi possible d’utiliser le caractère "*" pour introduire plus de flexiblité au moment de l’import. Par exemple si le fichier de configuration est:
L’import sera fait en cherchant dans les répertoires: ../moduleFolder/otherModuleFolder1/folder/moduleName et ../moduleFolder/otherModuleFolder2/folder/moduleName.
“rootDirs”
Ce paramètre permet d’indiquer au compilateur des répertoires virtuels qui doivent être mergés après le déploiement de l’application.
Par exemple, s’il existe plusieurs répertoires indiqués dans le paramètre "rootDirs": "folder1", "folder2" et "folder3". A chaque fois qu’un import relatif est effectué à partir de l’un de ces répertoires, le compilateur va effectuer une recherche des modules dans tous les répertoires comme si leur contenu était mergé.
Le compilateur va effectuer la recherche dans les répertoires otherModuleFolder1/moduleName et otherModuleFolder2/moduleName.
Débugger la résolution de modules
En rajoutant l’option suivante au compilateur, on peut avoir des messages de logs lors de la résolution des modules:
tsc --traceResolution
Pour conclure…
Comme en Javascript, les modules en Typescript peuvent être implémentés de façon très différente. Il est possible de passer par les namespaces qui correspondent à une séparation logique du code et qui sont spécifiques à Typescript. On peut aussi utiliser des syntaxes plus proches du Javascript avec des formats comme CommonJS, AMD ou ES2015. L’intérêt d’utiliser une syntaxe plus proche de celle en Javascript permet de coller davantage à la notion des modules Javascript séparant le code en fichiers.
D’une façon générale, il est conseillé de privilégier la notion des modules Javascript par rapport aux namespaces. En effet, les namespaces ajoutent une couche hiérarchique aux objets dans le but d’éviter les collisions de nom. A l’opposé les modules Javascript, du fait de leur séparation en fichiers, évitent les collisions de nom sans ajouter de couche hiérarchique.
Comme on a pu le voir, la définition de modules en Typescript hérite de la syntaxe Javascript et ajoute la notion de namespace. En revanche la notion d’import de modules externes n’a pas été abordé dans cet article. Ce point fera l’objet d’un article ultérieur.
Le plus souvent, les fichiers d’installation des composants .NET impliquent d’être connecté à internet au moment de l’installation. Par exemple, c’est le cas pour Visual Studio Community ou les Build tools. Parfois, on peut ne pas disposer d’une connexion au moment de l’installation, en particulier si on effectue l’installation sur un serveur qui se trouve sur un réseau fermé.
Ces fichiers d’installation peuvent être exécutés hors-ligne toutefois ils nécessitent une manipulation au préalable.
Préparation du fichier d’installation
Pour utiliser les fichiers d’installation hors-ligne, il faut, d’abord, télécharger toutes les dépendances du fichier en exécutant la ligne:
<fichier d'installation> --layout <répertoire de sortie> --lang <code langue>
Par exemple, dans le cadre des Build Tools, pour télécharger tous les fichiers d’installation, il faut exécuter la ligne suivante:
Le gros inconvénient de cette méthode est qu’elle entraîne le téléchargement de toutes les dépendances. Ce qui représente 12GB de fichiers d’installation dans le cas des Build Tools.
Pour éviter de tout télécharger, il est possible d’indiquer les composants à télécharger en les indiquant en utilisant l’option --add <nom du composant>.
On peut ensuite ajouter des options pour télécharger certaines dépendances des composants comme:
--includeRecommended pour télécharger les composants conseillés
--includeOptional pour télécharger les composants optionels.
Téléchargement interrompu
Si jamais le téléchargement s’interrompt, il suffit de ré-exécuter la commande avec les mêmes arguments. Le téléchargement reprendra où il s’est interrompu. Les fichiers déjà téléchargés ne seront, alors, pas re-téléchargés.
Exécuter l’installateur hors-ligne
Après avoir copié les fichiers d’installation sur la machine cible, il faut d’abord installer les certificats:
Aller dans le répertoire téléchargé: <répertoire des fichiers d'installation>\certificates
Double-cliquer sur chaque fichier de certificat (fichiers avec une extension .p12).
Dans le cas où l’assistant demande un mot de passe, il faut le laisser vide.
Ensuite, on peut exécuter l’installateur qui se trouve dans le répertoire téléchargé.
Dans le cas des Build Tools, le fichier est vs_buildtools.exe.
Si tous les composants ont été correctement téléchargés, une connexion internet n’est pas requise.
Dans le cas où on souhaite modifier, réparer, mettre à jour ou désinstaller une installation existante, on peut exécuter l’exécutable dans le répertoire téléchargé en double-cliquant dessus ou exécuter à la ligne de commandes une instruction du type:
<répertoire des fichiers d'installation>\<fichier d'installation> <commande>
Par exemple, pour les Build Tools:
vs_buildtools.exe <commande>
Les commandes possibles sont:
modify pour modifier une installation existante.
update pour mettre à jour une composant déjà installé
repair pour réparer une installation existante
uninstall pour désinstaller.
Erreur quand on modifie une installation existante
Si un erreur survient au cours de l’exécution d’une commande, il faut essayer de désinstaller complétement le composant en allant dans le panneau de configuration. Puis le réinstaller sans utiliser de commande particulière.