Performance Monitor (appelé aussi perfmon) est un outil de monitoring et d’alerte présent sur les plateformes Windows. Il permet de facilement observer des métriques concernant un processus spécifique ou les caractéristiques d’une machine. La plupart de temps, les développeurs oublient d’utiliser un outil comme celui-ci pour évaluer le comportement de leur application au cours du temps. Pourtant, observer l’évolution de métriques sur son application permet éventuellement de se rendre compte de mauvais comportements ou d’anomalies imprévues pouvant subvenir lors de l’exécution.
Le but de cet article est, dans un premier temps, de montrer les fonctionnalités principales de perfmon pour l’utiliser efficacement. Dans un 2e temps, on va expliciter les métriques utilisables qui permettent de faciliter le diagnostique de défauts d’une application. Enfin, on va montrer comment trouver les défauts les plus courants en combinant les différentes métriques.
Exécution de perfmon
Lancer perfmon
Collecter des compteurs en temps réel
Ajuster l’échelle du graphique
Configurer des collectes automatiques de données
Configurer un collecteur de données
Modifier les propriétés du compteur de performance
Modifier le format d’enregistrement des données collectées
Convertir un fichier de données binaires en CSV
Démarrer un collecteur de données
Démarrer manuellement une collecte
Programmer le démarrage d’une collecte
Lire les résultats d’une collecte
Principaux compteurs de perfmon
Utilisation du processeur
Pourcentage du temps processeur
Identifier les processus
Identifier des threads
Utilisation de la mémoire
Contexte managé
Mémoire managée
Détecter les anomalies
Détecter une fuite mémoire dans un processus managé
Détecter une fuite mémoire dans un processus non managé
Les screenshots dans cet article présente perfmon en français, toutefois les traductions anglaises sont indiquées dans le détail des éléments de configuration.
Les avantages les plus importants de perfmon sont:
- Cet outil est déjà installé sur les systèmes Windows (desktop et server). Il n’est donc, pas nécessaire de l’installer.
- Il permet de monitorer non seulement des processus classiques mais aussi de remonter des métriques plus spécifiques sur SqlServer ou IIS.
- Il peut fonctionner en tant que service, sans qu’il soit nécessaire d’avoir une session ouverte. On peut donc laisser perfmon collecter ses métriques pendant plusieurs jours et ainsi, surveiller l’évolution de l’exécution d’une application ou de la machine qui l’exécute. Cette surveillance aide à anticiper les problèmes pouvant éventuellement subvenir comme, par exemple, le manque de resources CPU, le manque de mémoire ou une fuite mémoire dans un processus.
- On peut exécuter perfmon pour qu’il collecte des données sur une machine à distance.
Le plus gros inconvénient de perfmon est qu’il n’est présent que sur les plateformes Windows. .NET Core étant exécutable sur d’autres plateformes que Windows, on ne peut que regretter qu’il n’y a pas d’équivalent de perfmon sur ces autres plateformes.
D’autre part, perfmon peut manquer de stabilité par moment et de nombreux bugs peuvent rendre son utilisation laborieuse.
Exécution de perfmon
Comme indiqué plus haut, perfmon est déjà installé sur Windows, il n’est pas nécessaire de l’installer. Cet outil se trouve à l’emplacement suivant:
C:\WINDOWS\system32\perfmon.msc
Lancer perfmon
On peut lancer perfmon de différentes façons:
- En appuyant sur [WIN] + [R], en écrivant perfmon ou
perfmon.mscpuis en appuyant sur [Entrée]. - A partir du menu Windows:
- Cliquer sur “Panneau de configuration” (i.e. “Control Panel”).
- Cliquer sur “Système et sécurité” (i.e. “System and Security”).
- Cliquer sur “Outils d’administration” (i.e. “Administration tools”).
- Cliquer sur “Analyseur de performance” (i.e. “Performance monitor”).
Collecter des compteurs en temps réel
On peut collecter des métriques en temps réel dans la partie “Outils d’analyse” (i.e. “Monitoring Tools”) ⇒ Analyseur de performances (ou “Performance Monitor”).
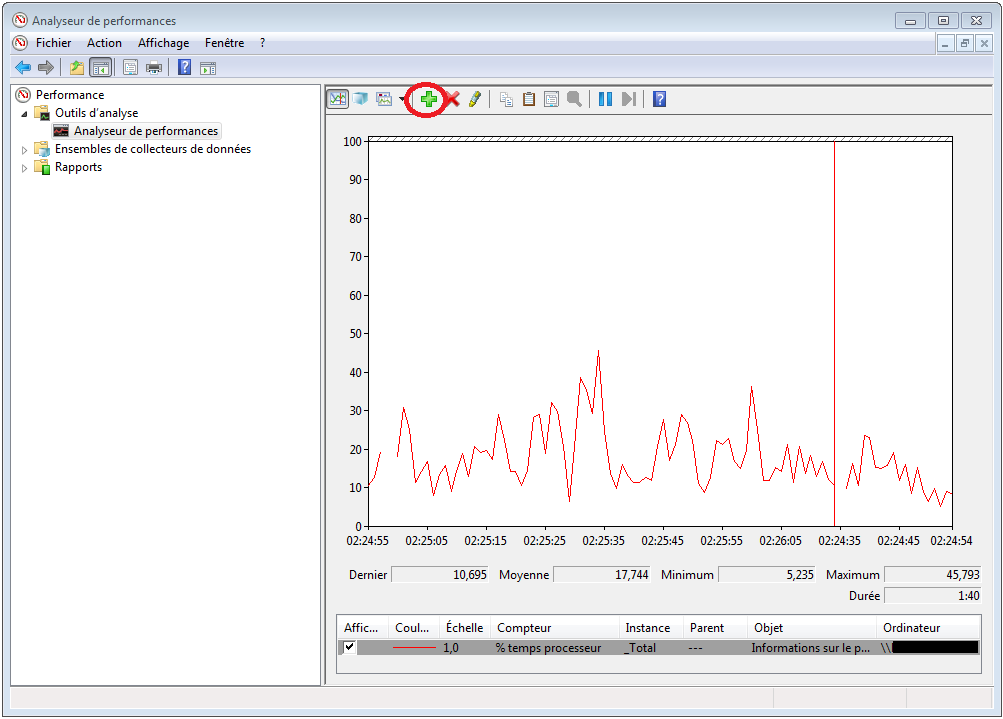
On peut ajouter des métriques (appelées compteur ou counter) en cliquant sur la croix verte:
On peut aussi effectuer un clique droit sur le graphique puis cliquer sur “Propriétés” (i.e. “Properties”), dans l’onglet “Données” (i.e. “Data”) si on clique sur “Ajouter”, on accède à l’écran permettant de choisir le compteur à ajouter.
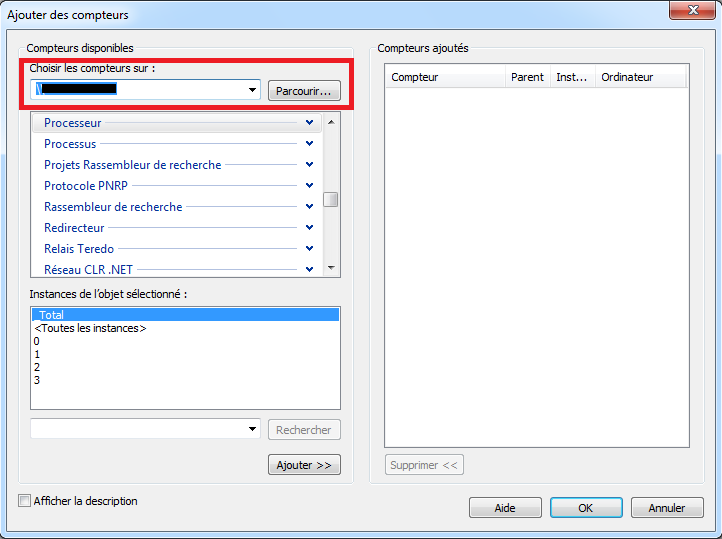
Un grand avantage de perfmon est de pouvoir monitorer des informations sur une machine se trouvant à distance. On peut ainsi renseigner l’adresse d’une machine distance et ainsi collecter les données la concernant.
Si on se connecte à une machine distante, il faut bien sélectionner la machine au moment d’ajouter des compteurs dans la partie “Choisir les compteurs sur” (i.e. “Select counters from computer”):
Ajuster l’échelle du graphique
Dans l’écran de propriétés des graphiques, on peut ajuster manuellement l’échelle du graphique:
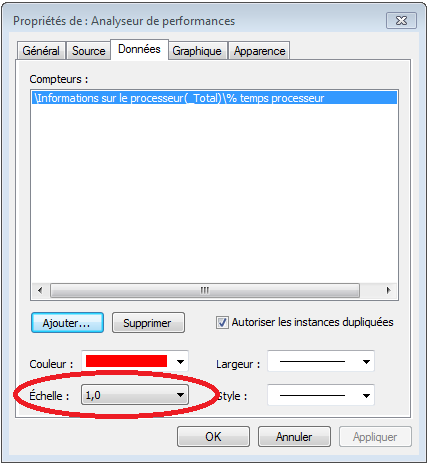
L’ajustement de l’échelle peut se faire en appliquant un facteur d’échelle aux données pour que le graphique puisse être affichable.
Pour effectuer l’ajustement automatiquement, on peut aussi effectuer un clique droit sur le graphique puis cliquer sur “Mettre à l’échelle les compteurs sélectionnés” (i.e. “Scale selected counters”).
Par défaut, l’échelle de temps est sur 100 sec ce qui est parfois très court pour monitorer correctement un comportement. On peut augmenter cette échelle en allant dans l’onglet “Général” dans la partie “Eléments graphiques” (i.e. “Graph elements”):
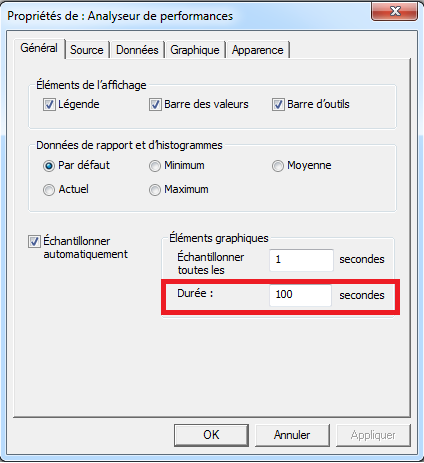
Par exemple, on peut augmenter la valeur maximum à 1000 sec (le maximum est 1000) pour avoir un historique plus important.
La collecte des compteurs en temps-réel est plutôt limitée puisqu’elle ne permet pas de capturer plus longtemps que 1000 sec. D’autre part, les données ne sont pas sauvegardés sur le disque. Après avoir fermé perfmon, les données sont perdues.
Configurer des collectes automatiques de données
perfmon donne la possibilité de capturer des données sur plusieurs heures ou jours et de les sauvergarder sur le disque de façon à les consulter plus tard. Avec ce type de collecteur, même après fermeture de perfmon, les données continueront d’être collectées. Cette fonctionnalité apporte une grande flexibilité puisqu’on peut fermer la session et les données continueront d’être collectées et sauvegardées.
Cet article indique comment configurer des compteurs en utilisant perfmon toutefois il est possible de créer des compteurs de performance par programmation. Pour davantage de détails, voir PerformanceCounter en 5 min.
Configurer un collecteur de données
Pour effectuer des collectes automatiques, il faut:
- Déplier la partie “Ensembles de collecteurs de données” (ou “Data Collector Sets”).
- Déplier la partie “Définis par l’utilisateur” (ou “User Defined”).
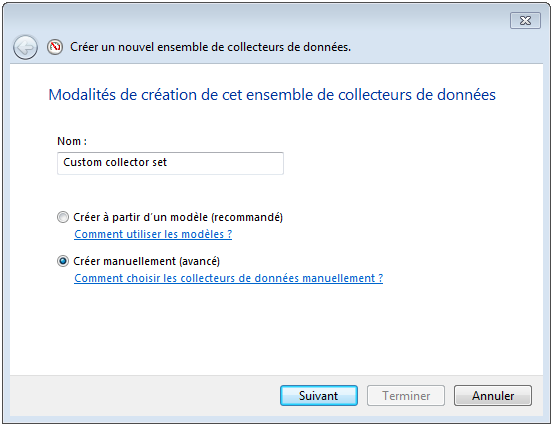
- On peut créer un ensemble de collecteurs de données en effectuant un clique droit sur “Définis par l’utilisateur” (ou “User Defined”) puis cliquer sur “Nouveau” et enfin “Ensemble de collecteurs de données” (ou “Data Collector Set”).
- Préciser un nom pour l’ensemble de collecteurs.
- Sélectionner “Créer manuellement (avancé)” (ou “Create manually (advanced)”) puis cliquer sur “Suivant”:
- Les options affichées permettent d’ajouter des compteurs particuliers:
- Compteur de performance (ou “performance counter”): cette option permet de créer des compteurs personnalisés avec lesquel on pourra préciser quelles sont les métriques à observer.
- Données de suivi d’évènements (ou “Event trace data”): ce sont des évènements paramétrés.
- Informations de la configuration système (ou “System configuration information”): ce paramétrage permet d’observer des valeurs de clé de registre.
Pour effectuer une collecte automatique de métriques, il faut sélectionner “Compteur de performance” (ou “Performance Counter”) puis cliquer sur “Suivant”.
- Dans l’écran, on peut sélectionner les métriques à observer en cliquant sur “Ajouter…”:
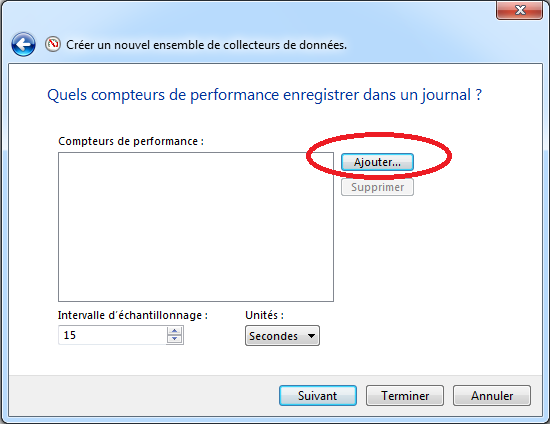
On peut choisir parmi les mêmes métriques que pour la collecte en temps réel. On détaillera par la suite certaines de ces métriques.
- Dans le cadre de l’exemple, on peut choisir une métrique sur le système, par exemple dans la partie: “Mémoire” (i.e. “Memory”) ⇒ “Mégaoctets disponibles” (ou “Available Bytes”).
Cliquer sur “Ajouter” puis “OK”.
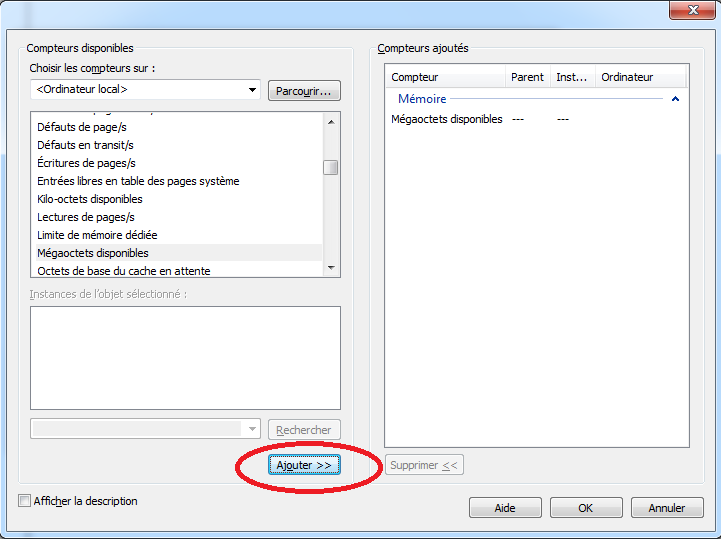
- Cliquer ensuite sur “Terminer”.
Lorsque la configuration est ajoutée, on peut préciser quelques éléments de configuration supplémentaire:
- Effectuer un clique droit sur le collecteur créé,
- Cliquer sur “Propriétés”.
On peut personnaliser certains éléments:
- Utilisateur: l’utilisateur qui exécutera le compteur: ce paramétrage est particulièrement utile si on souhaite monitorer un processus lancé avec un utilisateur différent de celui qui effectue le paramétrage. Ce paramètre est disponible dans l’onglet “Général”:
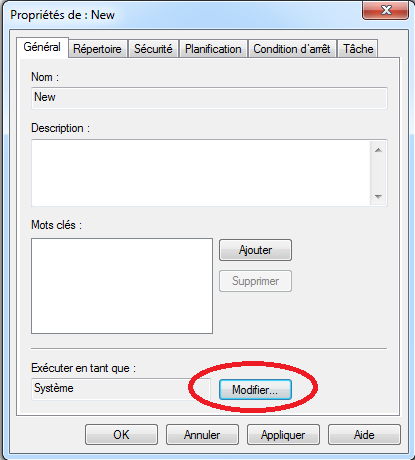
- Répertoire (ou “Directory”): le répertoire dans lequel les fichiers des compteurs seront créés: accessible dans l’onglet “Répertoire”.
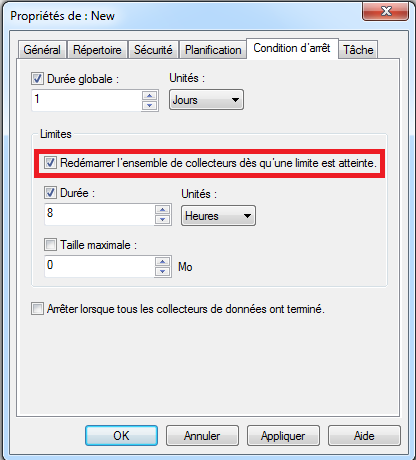
- Condition d’arrêt (ou “Stop condition”): il peut être utile de paramétrer une condition d’arrêt pour éviter que la collecte s’effectue de façon permanente. Les paramètres les plus utiles sont:
- Durée globale (ou “Overall duration”): indiquer une durée. Ne pas oublier de préciser l’unité.
- Limites (ou “Limits”): cette partie est intéressante car elle va permettre d’indiquer une période de collecte qu’il est possible de redémarrer périodiquement. En effet, il n’est pas possible de consulter le résultat d’une collecte si elle est en cours d’exécution. Ainsi, si on redémarre une collecte de façon périodique, on pourra lire la collecte effectuée lors d’une période précédente.
Pour permettre de redémarrer périodiquement une collecte, il faut:- Indiquer une durée de collecte et cliquer sur “Durée”
- Cliquer sur “Redémarrer l’ensemble de collecteurs dès qu’une limite est atteinte” (i.e. “Restart the data collection set at limits”) pour permettre de relancer une nouvelle période de collecte:
Il est vivement conseillé de paramétrer une condition d’arrêt pour plusieurs raisons:
- Les compteurs peuvent consommer beaucoup de mémoire: cette quantité varie en fonction de la quantité de métriques paramétrées. Certaines métriques système consomment particulièrement de la mémoire.
- On ne peut pas lire les résultats d’une collecte si celle-ci n’est pas arrêtée. Pour pouvoir lire les résultats, il faut:
- soit arrêter la collecte
- soit redémarrer la collecte de métriques de façon périodique. Lors d’une période de collecte, on ne peut pas lire la collecte en cours, toutefois on peut lire les périodes précédentes.
- Enfin, en redémarrant une collecte périodiquement, les données de collecte sont écrites périodiquement sur le disque. Si perfmon crashe, on ne perds que la dernière période de collecte et non toute la collecte.
Modifier les propriétés du compteur de performance
Il est possible de modifier les métriques collectées en effectuant un clique droit sur le compteur de performance (sur la droite) puis en cliquant sur “Propriétés” (on peut aussi double cliquer sur le nom du compteur):
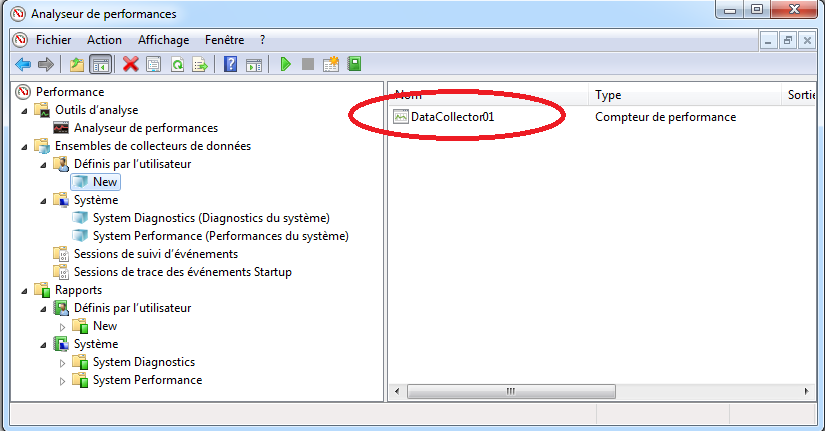
On peut aussi ajouter des collecteurs de données en effectuant un clique droit sur le panneau de gauche puis en cliquant sur “Nouveau”.
Modifier le format d’enregistrement des données collectées
Cette option peut s’avérer particulièrement utile pour sauvegarder les données dans un fichier CSV de façon à les ouvrir dans Excel par exemple:
- Il faut accéder aux propriétés du compteur de performance en effectuant un clique droit sur le compteur (sur la droite) puis en cliquant sur “Propriétés” (on peut double cliquer sur le nom du compteur).
- Dans la partie “Format d’enregistrement” (i.e. “Save Data As”), on peut sélectionner “Avec séparateur virgule” (i.e. “Test file (comma delimited)”) ou “Avec séparateur tabulation” (i.e. “Text file (tabulation delimited)”):
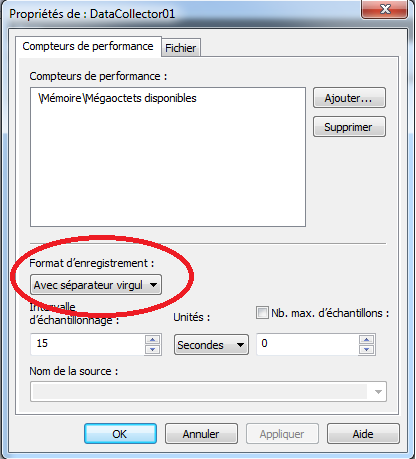
Les données collectées seront enregistrées dans un fichier .CSV consultable, par exemple, avec Excel.
Convertir un fichier de données binaires en CSV
On peut convertir les données collectées dans un fichier binaire au format .BLG vers un fichier texte de type .CSV en exécutant la commande suivante:
relog -f csv <chemin du fichier binaire .BLG> -o <chemin du fichier de sortie .CSV>
Démarrer un collecteur de données
Démarrer manuellement une collecte
Après avoir configuré un collection de données, on peut la démarrer:
- En le sélectionner puis en cliquant sur “Démarrer”:
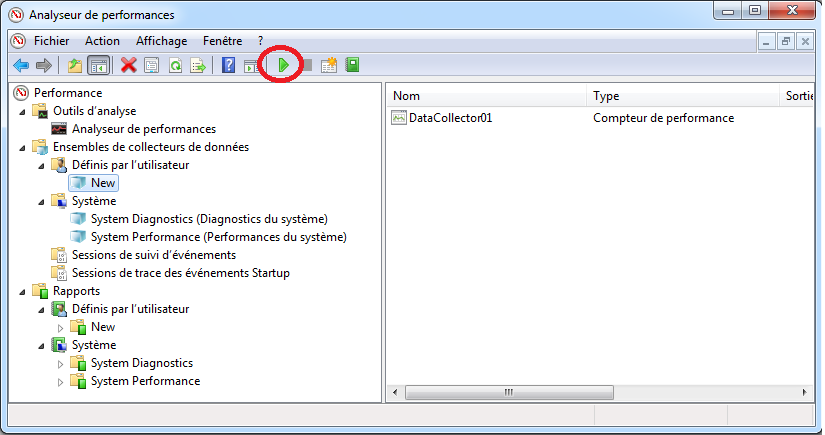
- On peut aussi démarrer en effectuant un clique droit sur le collecteur puis en cliquant sur “Démarrer”.
Après démarrage, l’icône du collecteur change:
Programmer le démarrage d’une collecte
On peut programmer la collecte en consultant les propriétés d’un ensemble de collecteur de données (i.e. “Data collector sets”):
- Accéder aux propriétés en effectuant un clique droit sur l’ensemble de collecteur de données ⇒ cliquer sur “Propriétés”.
- Aller dans l’onglet Planification (i.e. “Schedule”).
- Ajouter une condition de démarrage en cliquant sur “Ajouter”:
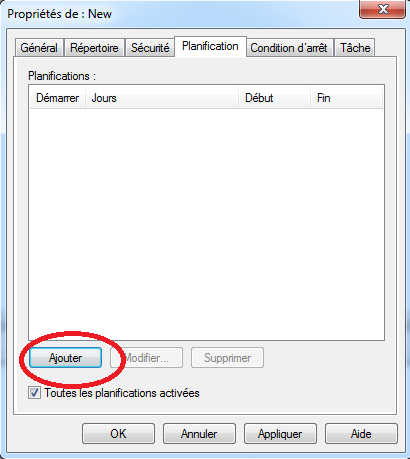
- On peut préciser un certain nombre de critères pour planifier la collecte:
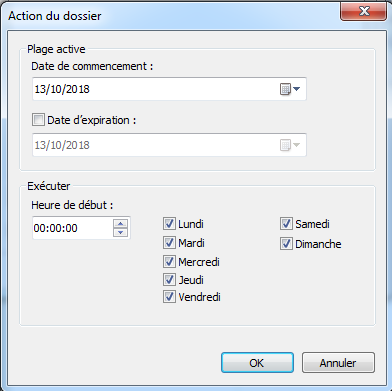
Une autre méthode permet de programmer le démarrage d’un ensemble de collecteur de données en passant par le Task Scheduler de Windows:
- Il faut, d’abord, ouvrir le Task Scheduler ou Planificateur de tâches en allant dans “Panneau de configuration” (i.e. “Control Panel”) ⇒ “Système et sécurité”” (i.e. “System and Security”) ⇒ Dans la partie “Outils d’administration” (i.e. “Administration tools”), cliquer sur “Tâches planifiées” (i.e. “Task Scheduler”).
Une autre méthode consiste à exécuter la commande suivante en faisant [Win] + [R]:taskschd.msc - On peut accéder aux ensembles de collecteur de données créés dans perfmon en allant dans la partie: “Bibliothèque de Planificateur de tâches” (i.e. “Task Scheduler Library”) ⇒ “Microsoft” ⇒ “Windows” ⇒ “PLA”:
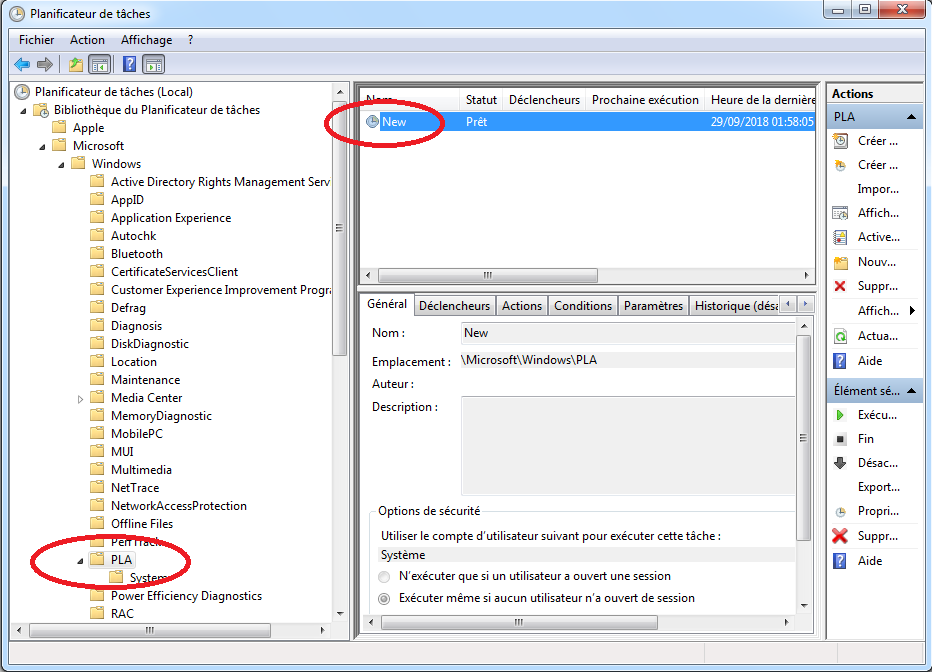
- On peut voir sur le panneau de droite, les ensembles de collecteur de données créés dans perfmon. Si on effectue un clique droit sur l’ensemble puis en cliquant sur “Propriétés” on peut accéder à un ensemble d’options permettant de planifier une exécution.
- Dans l’onglet “Déclencheurs” (i.e. “Triggers”):
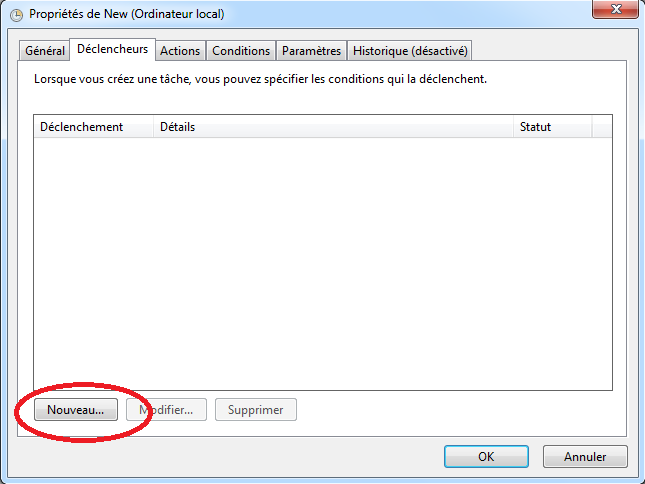
- On peut indiquer des options dans les déclencheurs:
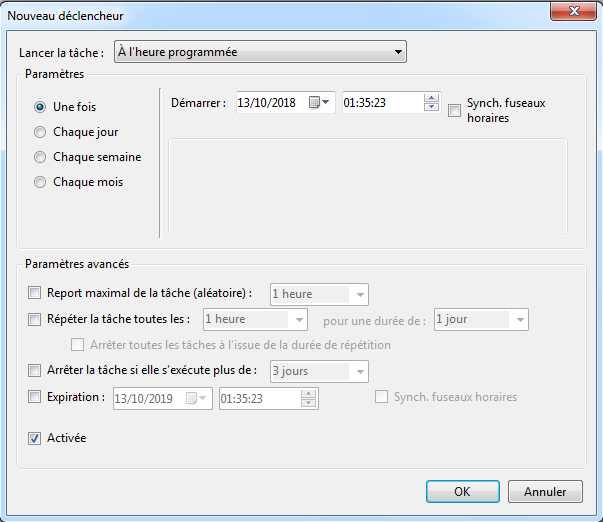
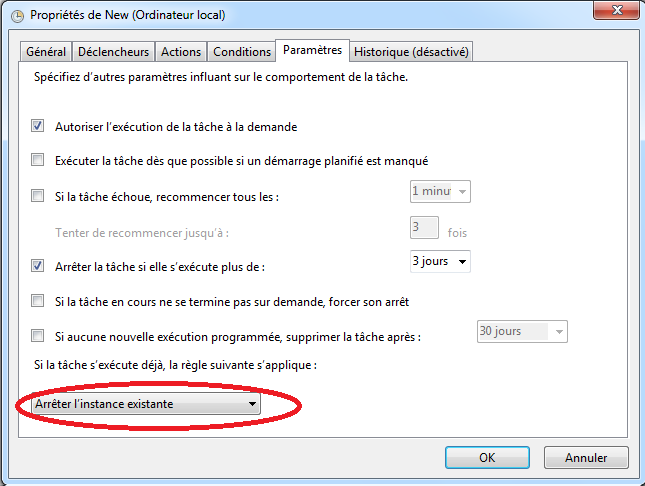
- Dans l’onglet “Paramètres” (i.e. “Settings”), on peut indiquer de stopper l’exécution d’une collecte avant d’en commencer une autre en sélectionnant dans “Si la tâche s’exécute déjà, la règle suivante s’applique” (i.e. “If the task is already running, then the following rule applies”) l’option “Arrêter l’instance existante” (i.e. “Stop the existing instance”):
Lire les résultats d’une collecte
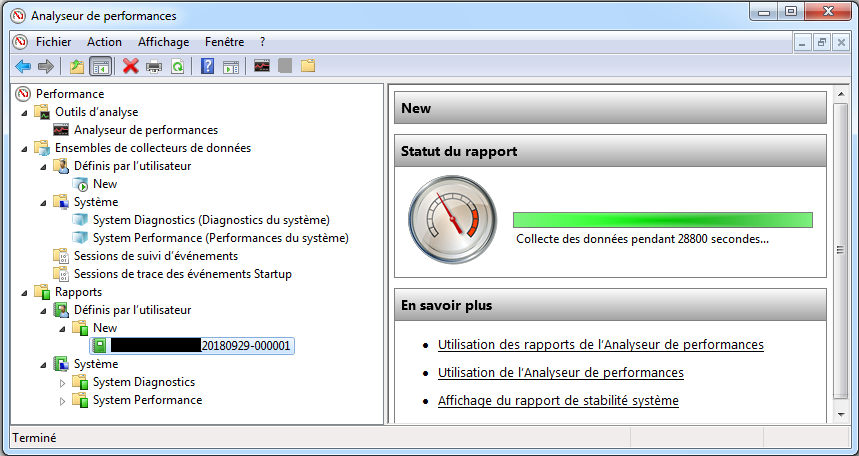
On ne peut pas voir les résultats d’une collecte de données tant que celle-ci est en cours d’exécution. Une astuce consiste à paramétrer une collecte périodique de façon à lire les résultats collectés lors d’une période précédente.
Si on tente de lire les résultats d’une collecte en cours:
Pour lire les résultats, il faut:
- Arrêter la collecte en effectuant un clique droit sur le collecteur puis en cliquant sur “Arrêter” ou
- Attendre qu’une période de collecte se termine (si elle a été configurée).
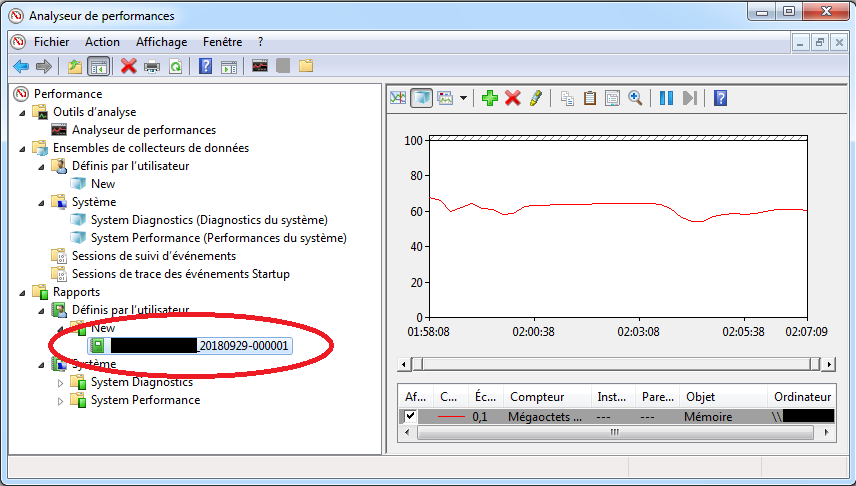
Les résultats se lisent dans la partie “Rapports” (i.e. “Reports”), il faut sélectionner le répertoire correspondant à la collecte:
On peut choisir différent type d’informations en effectuant un clique droit sur le répertoire de la collecte ⇒ Cliquer sur “Affichage” ⇒ Différents éléments sont disponibles:
- Rapport: regroupant des informations relatives à la collecte
- Analyseurs de performances: présentant les courbes correspondant aux métriques collectées.
- Dossier: c’est l’ensemble des fichiers permettant de stocker les informations collectées.
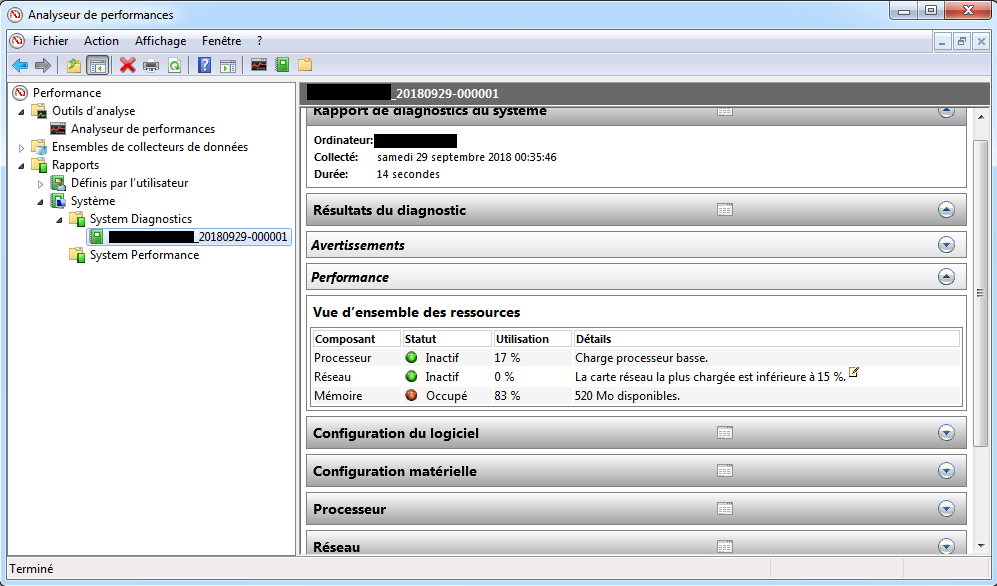
Si la collecte de données est terminée, en double cliquant sur le nom du rapport, on peut voir un résumé de la collecte (accessible aussi en effectuant un clique droit sur le nom du rapport ⇒ Affichage (i.e. “Display”) ⇒ Rapports (i.e. “Reports”):
Il est possible de supprimer les répertoires regroupant les données collectées en effectuant un clique droit sur le répertoire ⇒ Cliquer sur “Supprimer”.
Créer des alertes
On peut configurer des alertes correspondant à des actions qui seront exécutées quand survient un évènement particulier. Les évènements sont configurés à partir de la comparaison d’une métrique avec une valeur seuil déterminée. Par exemple, on peut configurer l’exécution d’une action quand un seuil particulier est dépassé à la hausse ou à la baisse.
Pour configurer ce type d’alerte, il faut:
- Déplier la partie “Ensembles de collecteurs de données” (ou “Data Collector Sets”).
- Déplier la partie “Définis par l’utilisateur” (ou “User Defined”).
- On peut créer un ensemble de collecteurs de données en effectuant un clique droit sur “Définis par l’utilisateur” (ou “User Defined”) puis cliquer sur “Nouveau” et enfin “Ensemble de collecteurs de données” (ou “Data Collector Set”).
- Préciser un nom pour l’ensemble de collecteurs.
- Sélectionner “Créer manuellement (avancé)” (ou “Create manually (advanced)”) puis cliquer sur “Suivant”:
- Sélectionner un collecteur de données de type “Alerte de compteur de performance” (i.e. Performance counter alert).
- Ajouter des métriques qui seront comparées à différent seuil: cliquer sur “Ajouter” puis sélectionner une ou plusieurs métriques:
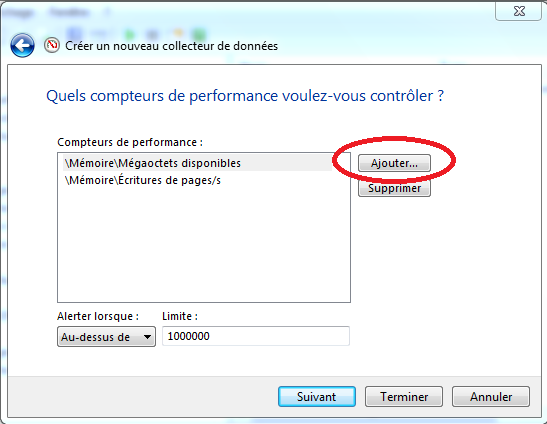
- Indiquer pour chaque métrique des seuils utilisés à la hausse (quand “Au dessus de” ou “Above” est sélectionné) ou à la baisse (quand “Au dessous de” ou “Below” est sélectionné).
- Cliquer sur “Terminer”.
- Quand les seuils sont dépassés, on peut exécuter des actions en:
- Effectuant un clique droit sur le collecteur de données (sur le panneau de droite) ⇒ cliquer sur “Propriétés”.
- Dans l’onglet “Action de l’alerte” (i.e. “Alert action”), on peut indiquer l’ensemble de collecteurs à démarrer le cas échéant ou
- Dans l’onglet “Tâche d’alerte” (i.e. “Alert task”), indiquer la tâche du Task Scheduler à lancer.
Avec ce type d’alerte, on peut exécuter plusieurs types de tâche comme envoyer un mail, afficher un message ou lancer un exécutable. On va expliciter la création d’une tâche pour afficher un message, la procédure étant facilement extensible aux autres cas.
Ainsi, si on veut afficher un message quand la mémoire disponible sur la machine est inférieure à une valeur limite, il faut effectuer les étapes suivantes:
- Il faut créer une alerte de compteur de performance en utilisant la procédure décrite précédemment.
Il faut ensuite éditer quelques propriétés du collecteur de données:- Effectuer un clique droit sur le collecteur de données (sur le panneau de droite) ⇒ cliquer sur “Propriétés”.
- Dans l’onglet “Action de l’alerte” (i.e. “Alert action”), cliquer sur “Ajouter une entrée dans le journal d’évènements d’applications” (i.e. Log entry in the application event log): cette action permet d’ajouter une entrée dans l’Event log Windows:
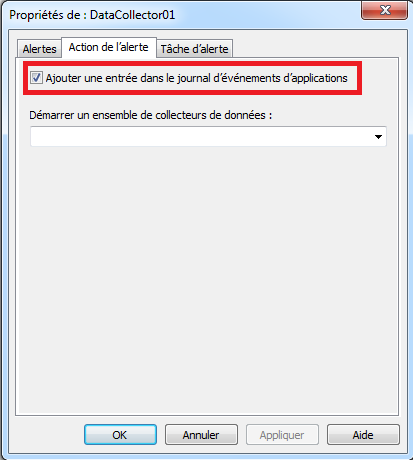
- Cliquer sur “OK” pour valider.
- On peut démarrer l’ensemble de collection de données en le sélectionnant puis en cliquant sur “Démarrer”.
- Dans l’Event Viewer (ou l’observateur d’évènements), on peut voir l’ajout d’une entrée à chaque fois que l’alerte est déclenchée: dans notre cas, l’alerte sera déclenchée dès que la quantité de mémoire disponible sera inférieure à la valeur seuil.
Pour voir l’entrée dans Event Viewer:- Il faut l’ouvrir en appuyant sur les touches [Win] + [R] puis en écrivant
eventvwr.msc. - Déplier les nœuds “Observateurs d’évènements” ⇒ “Journaux des applications et des services” ⇒ “Microsoft” ⇒ “Diagnosis-PLA” ⇒ “Opérationnel”, on peut voir les entrées ajoutées en cas de déclenchement de l’alerte:
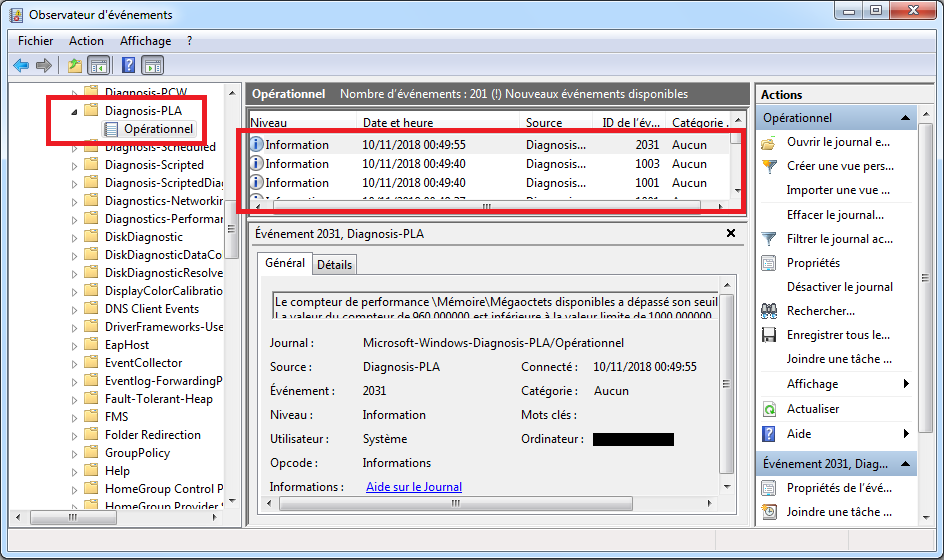
- Il faut l’ouvrir en appuyant sur les touches [Win] + [R] puis en écrivant
- Il faut ensuite créer une tâche permettant d’afficher un message dans le Task Scheduler:
- On ouvre le Task Scheduler en appuyant sur les touches [Win] + [R], en écrivant
taskschd.mscpuis en appuyant sur [Entrée]. - Dans le nœud “Planificateur de tâches” (i.e. “Task Scheduler”) ⇒ “Bibliothèque de Planificateur de tâches” (i.e. “Task Scheduler Library”), on peut créer une tâche en cliquant sur “Créer une tâche” (i.e. “Create a task”):
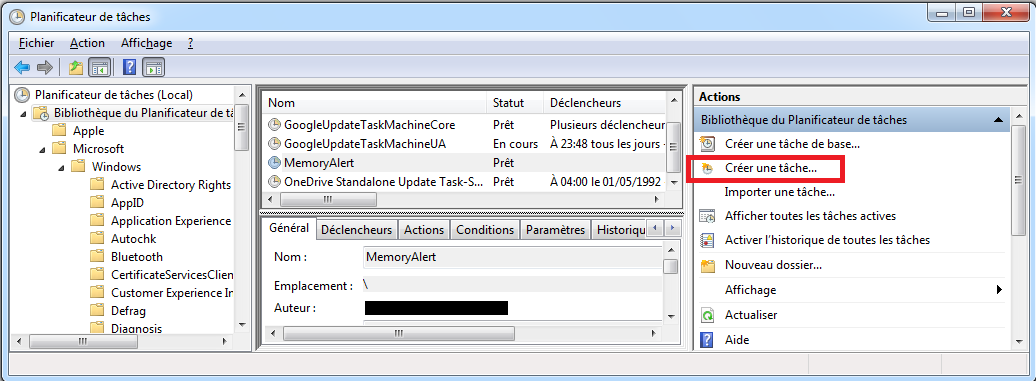
- On indique le nom de la tâche, par exemple
MemoryAlert:
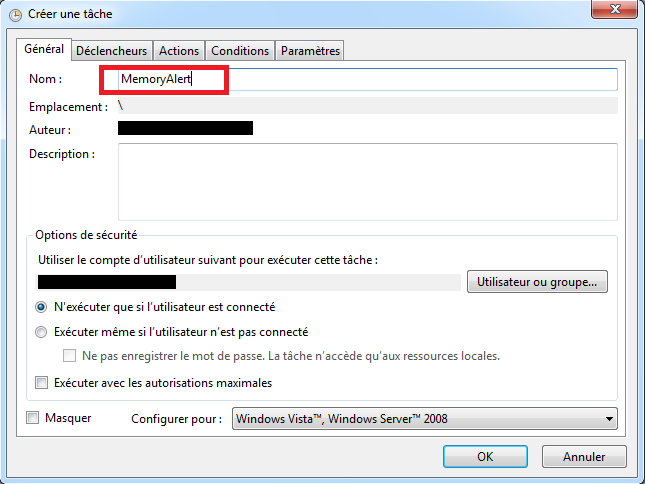
- Dans l’onglet “Actions”, en cliquant sur “Nouveau”, on peut créer une action à exécuter parmi les actions suivantes:
- Démarrer un programme,
- Envoyer un message électronique,
- Afficher un message.
On sélectionne “Afficher un message” (i.e. “Display a message”) et on indique le message à afficher:
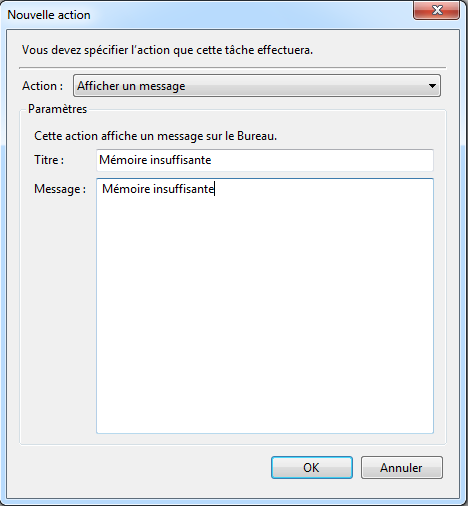
- Cliquer sur “OK” pour terminer la création de la tâche.
- On peut tester l’exécution de la tâche en sélectionnant la tâche et en cliquant sur “Exécuter”. Une popup devrait s’afficher avec le contenu suivant:
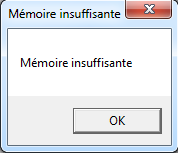
- On ouvre le Task Scheduler en appuyant sur les touches [Win] + [R], en écrivant
- Il faut ensuite configurer la tâche nouvellement créée dans le collecteur de données:
- Retourner dans perfmon
- Sélectionner l’ensemble de collecteur de données puis effectuer un clique droit sur le collecteur de données (sur la partie droite) et cliquer sur “Propriétés”.
- Dans l’onglet “Tâche d’alerte” (i.e. Alert task), dans la partie “Exécuter cette tâche lorsqu’une alerte est déclenchée” (i.e. “Run this task when an alert is triggered”), indiquer le nom de la tâche créée dans le Task Scheduler. Dans notre exemple, cette tâche s’appelle
MemoryAlert:
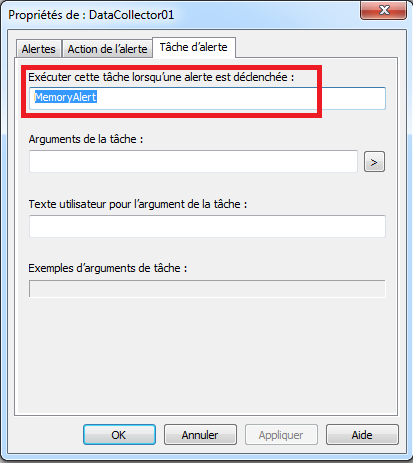
A la suite de cette configuration si l’ensemble de collecteur de données est démarrer, un message d’alerte sous forme d’une popup devrait s’afficher à chaque fois que la mémoire disponible sur la machine descend en dessous de la valeur seuil configurée.
Principaux compteurs de perfmon
Les compteurs de perfmon sont des métriques permettant de mesurer plusieurs types d’information. Ils permettent d’observer des informations diverses allant des données concernant le système à des données concernant des processus spécifiques. Ces compteurs sont les plus importants puisque leur évolution permet de diagnostiquer l’état du système ou d’un processus.
La façon de traiter ces compteurs n’est pas la même:
- Pour certains compteurs, une simple lecture de la valeur peut suffire à déduire une information pertinente, par exemple le pourcentage de temps processeur permet d’indiquer directement l’utilisation du processeur.
- Pour d’autres compteurs, il faut comparer la valeur avec une autre valeur provenant éventuellement d’un autre compteur, par exemple pour la quantité de mémoire disponible. Pour en tirer une information pertinente, il faut comparer cette quantité avec la quantité de mémoire totale de la machine pour en déduire la quantité de mémoire occupée.
- Pour certains compteurs, la lecture d’une valeur instantanée n’indiquera rien de pertinent, il faudra scruter la variation de la valeur du compteur en fonction du temps. Par exemple, la mémoire occupée par un processus peut apporter une information si on constate une augmentation au cours du temps. Plus l’augmentation sera brutale et plus l’évolution de ce compteur sera préoccupante.
- Enfin, il faut distinguer les unités des compteurs: certains compteurs indiquent des valeurs instantanées, des valeurs moyennes, des pourcentages d’une valeur totale ou des valeurs moyennées par seconde. Il faut avoir en tête que des valeurs instantanées sont échantillonnées à une fréquence donnée. Ces échantillonnages peuvent avoir pour conséquence de déformer la réalité puisque la capture des valeurs est discontinue, seules les captures correspondant à la fréquence seront affichées et non pas toutes les valeurs de façon continue.
Utilisation du processeur
L’utilisation du processeur est une des informations qui peut être la plus utile à capturer. La plupart du temps, les machines comptent plusieurs cœurs logiques. Ainsi, l’utilisation peut être indiquée de façon totale ou pour chaque cœur logique.
Pourcentage du temps processeur
- Processeur\% temps processeur
Processor\% Processor Time
C’est une valeur instantanée qui permet d’avoir une idée de l’utilisation totale du processeur. Une valeur proche des 100% indique un processeur utilisé au maximum de sa capacité ce qui le plus souvent peut révéler une exécution anormale d’un processus. Généralement, il peut être utile d’analyser le temps processeur pour chaque cœur et non pour tout le processeur. En effet, le plus souvent un processus pourrait utiliser 100% d’un cœur mais plus rarement 100% du temps total du processeur. - Processus\% temps processeur
Process\% Processor Time
Contrairement au compteur précédent, ce compteur ne concerne que le temps processeur pour un processus donné. Cette valeur peut s’avérer intéressante pour isoler le comportement anormal d’un processus en particulier. Plus simplement, dans un fonctionnement normal, ce compteur peut aussi servir à dimensionner une machine pour l’exécution d’un processus.
Brièvement, le processeur est exécuté soit en mode utilisateur (i.e. user mode), soit en mode kernel (i.e. kernel mode) suivant le code qu’il doit exécuter. Les applications sont exécutées en mode utilisateur, les systèmes d’exploitation et la plupart des drivers sont exécutés en mode kernel. Cette séparation permet d’isoler l’exécution d’un processus dans un espace d’adresse mémoire virtuelle qui lui est spécifique. Un processus peut appeler certaines fonctions du système d’exploitation qui seront exécutées en mode kernel comme par exemple effectuer des opérations sur un fichier sur le disque, allouer de la mémoire ou effectuer des entrées/sorties réseau.
- Processeur\% temps privilégié
Processor\% Privileged time
Ce compteur permet d’indiquer l’utilisation du processeur en mode kernel. Si l’utilisation du processeur en mode kernel est élevée (c’est-à-dire > 75%) peut révéler une machine sous-dimenssionnée pour l’ensemble des processus à exécuter. - Processeur\% temps utilisateur
Processor\% User time
Ce compteur indique l’utilisation du processeur en mode utilisateur. Cette valeur est moins pertinente que le pourcentage de temps privilégié toutefois elle peut présenter un intérêt s’il est particulièrement élevé (> 90 %). Elle peut indiquer une machine sous-dimensionnée. - Système\Longueur de la file d’attente du processeur
System\Processor Queue Length
Ce compteur donne une indication sur le nombre de threads en attente d’exécution. On considère que cette valeur est préoccupante si elle dépasse 5. Dans le cas d’une machine multi-cœur, il faut diviser la valeur par le nombre de cœurs et comparer le résultat avec 5. Si la valeur dépasse 5 de façon continue avec un processeur proche des 100% du temps d’exécution, il y a davantages de threads en attente d’exécution que la processeur n’est capable d’en traiter. Ce qui conduit à allonger la file d’attente et à rendre l’exécution des threads plus longue. - Système\Changement de contexte/s
System\Context switches/sec
Ce compteur indique le nombre de fois moyens par seconde que le processeur passe du mode utilisateur vers le mode kernel pour effectuer des opérations où le mode kernel est nécessaire dans le cadre d’un thread exécuté en mode utilisateur. Cette valeur dépends de la charge à laquelle est soumise le processeur toutefois elle doit rester stable pour une même charge donnée. Si cette valeur augmente sans changement de charge du processeur, il pourrait s’agir d’un fonctionnement anormal d’un driver.
Une augmentation brutale peut provenir d’un processus qui effectue beaucoup d’opérations nécessitant une exécution en mode kernel. Dans ce cas, il faut observer la variation de cette valeur et la rapprocher à l’exécution du processus pour éventuellement surveiller une saturation qui pourrait dégrader l’exécution du processus.
D’une façon générale, une valeur inférieure à 5000 est considérée normale. - Processeur\Interruption/sec
Processor\Interrupts/sec
Cette valeur indique le nombre de fois moyen par seconde que le processeur reçoit une interruption provenant d’un autre composant hardware. Si cette valeur est supérieure à 1000 de façon continue, il peut s’agir d’un défaut d’un composant matériel. Dans un fonctionnement normal, certains composants sollicitent des interruptions régulières du processeur comme l’horloge système, la souris, les drivers des disques, les cartes réseaux etc…
Identifier les processus
Dans perfmon, les processus sont reconnaissables par leur nom. Toutefois, il peut arriver qu’il existe plusieurs instances d’un même processus. Dans perfmon, tous ces processus seront représentés avec le même nom. Par exemple:
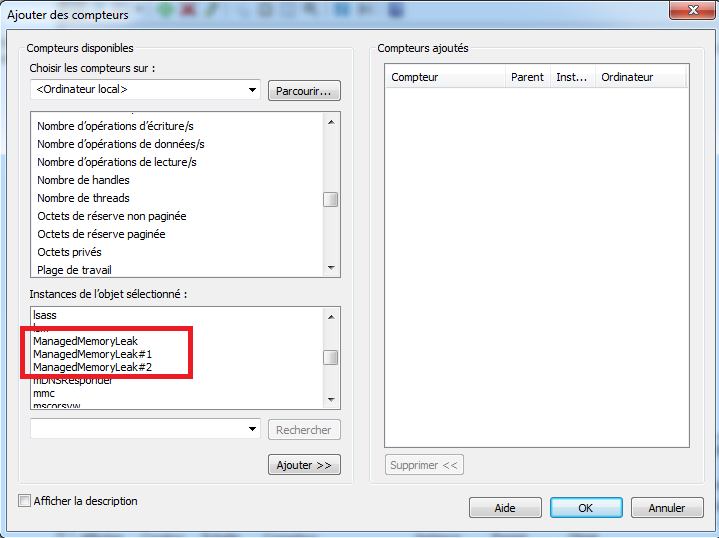
Pour identifier quel libellé correspond à quel processus, il faut se référer à l’ID du processus. On peut trouver cet ID dans le compteur Processus\ID de processus (ou Process\Process ID).
Identifier des threads
Dans le cas des threads, il n’est pas forcément facile d’identifier directement un thread qui consomme beaucoup de CPU avec perfmon. Le gros inconvénient est que dans la catégorie “Thread”, on ne peut pas choisir les threads correspondant à un processus, on est obligé d’ajouter tous les threads existants ce qui est, le plus souvent, inexploitable.
Par exemple pour identifier le thread responsable d’une grande consommation de ressource CPU, on peut aller dans la catégorie “Thread” et ajouter les compteurs:
Thread\% temps processeur(ouThread\% Processor Time): ces compteurs permettent d’identifier le thread responsable ainsi que le processus parent.Thread\N° du thread(ouThread\ID thread): ces compteurs indiquent l’identifiant du thread en décimal. Il faut convertir cet identifiant en hexadécimal pour l’exploiter avec WinDbg par exemple.
Quand on sélectionne ces compteurs, un grand nombre de courbes sont rajoutées. La recherche est plutôt fastidieuse. Il ne faut pas confondre l’ID du thread et le numéro d’instance indiquée dans perfmon. Le numéro est spécifique à perfmon, il faut se référer à l’ID du thread correspondant au compteur concerné.
Par exemple, si on regarde les compteurs suivants:

L’instance permet de faire de rapprocher les 2 compteurs toutefois l’identifiant du thread est indiqué dans l’encadré rouge.
Utilisation de la mémoire
L’utilisation de la mémoire est le 2e point le plus important à monitorer car elle a un impact très direct sur l’exécution des processus. D’autre part, le fonctionnement anormal d’un processus qui pourrait occasionner une grande consommation de mémoire, peut avoir un impact sur tous les processus de la machine.
- Mémoire\Mégaoctets disponibles
Memory\Available MBytes
Ce compteur indique le nombre de mégaoctets disponibles en mémoire pour l’exécution des processus. Il s’agit d’une valeur instantanée. Si cette valeur est en dessous de 10% de la mémoire totale de la machine, la non disponibilité de mémoire libre pourrait occasionner une charge supplémentaire pour solliciter la mémoire virtuelle.
Quand un processus est en cours d’exécution, il est exécuté dans un espace d’adresses mémoire virtuelle. Pour ses besoins, il sollicite le système d’exploitation pour que ce dernier lui alloue de la mémoire sous forme de page. Pendant le déroulement de l’exécution du processus, les pages allouées sont consultées pour écrire ou lire des objets. Le système d’exploitation traque les fréquences d’utilisation de ces pages pour savoir quelles sont les pages les plus fréquemment consultées par le processus. Les pages les plus fréquemment consultées seront mises en cache dans la mémoire RAM de façon à augmenter la vitesse d’exécution du processus. Les autres pages sont stockées dans la mémoire virtuelle sur le disque.
Si un processus souhaite accéder à une page mémoire qui ne se trouve pas dans la mémoire RAM, le système d’exploitation effectue un page fault (ou défaut de page) à la suite de laquelle, il va effectuer une copie de la page du disque vers la mémoire RAM. Le système d’exploitation suppose que la page sera éventuellement de nouveau consultée dans le futur. Le fait que la page soit dans la mémoire RAM rendra plus rapide l’exécution du processus.
Les page faults occasionnent donc beaucoup d’opérations par le système d’exploitation pour accéder à la page mémoire.
- Processus\Plage de travail
Process\Working set
Cette valeur indique la quantité de mémoire RAM en octets utilisée par un processus sans occasionner de page faults. Il s’agit d’une valeur instantanée. Cette valeur peut s’avérer intéressante si elle varie de façon significative au cours du temps.
Si la machine comporte beaucoup de mémoire, quand un processus libère de la mémoire, la page mémoire n’est pas forcément supprimée de la plage de travail (i.e. “working set”) du processus. La plage de travail d’un processus peut donc contenir des pages inutilisées. - Processus\Octets privés
Process\Private bytes
Il s’agit de la quantité de mémoire totale en octets utilisée par un processus. Cette valeur est instantanée, de même que la valeur précédente c’est la variation au cours du temps qu’il faut observer. Si cette valeur augmente de façon plus ou moins rapide, il peut s’agir d’une fuite mémoire (i.e. memory leak).
Dans un contexte managé, cette valeur rassemble la quantité de mémoire managée et non managée. - Mémoire CLR .NET\Nombre d’octets dans tous les tas
.NET CLR Memory\Bytes in all Heaps
Ce compteur indique la quantité de mémoire managée en octets dans tous les tas du processus. Ce compteur n’est utile que dans le contexte .NET. Elle permet de déduire la quantité de la mémoire non-managée en utilisant la formule:
Processusoctets privés - Mémoire CLR .NETnombre octets dans tous les tas = Mémoirenon-managée - Mémoire\Octets du cache
Memory\Cache Bytes
Ce compteur permet de connaître le nombre d’octets alloués en RAM pour des threads du kernel qui ne vont pas occasionnés un page fault. Il s’agit d’une valeur instantanée. Il faut comparer cette valeur à la quantité de mémoire RAM de la machine. Dans le cas d’une valeur élevée, il peut s’avérer que la machine manque de mémoire RAM. - Mémoire\Octets résidants dans le cache système
Memory\Pool Nonpaged Bytes
Cette valeur correspond à la quantité de mémoire en octets allouées en RAM que le kernel ne peut pas déplacer dans la mémoire virtuelle sur le disque. C’est une valeur instantanée. Si cette valeur est trop grande (>75%), le système ne pourra plus allouer de la mémoire aux processus. - Mémoire\Pages/sec
Memory\Pages/sec
Ce compteur indique la somme entre le nombre de pages lues et le nombre de pages écrites sur le disque pour résoudre le problème de page fault. Si cette valeur dépasse 50 de façon continue, il est fort probable que le système manque de mémoire. - Mémoire\Pages en entrée
Memory Page Reads/sec
Il s’agit de la quantité moyenne de page mémoire virtuelle lue sur le disque par seconde. Cette valeur est à rapprocher de celles obtenues avec le compteur Mémoire\Pages/sec. - Mémoire\Pages en entrée
Memory Page Reads/sec
Il s’agit de la quantité moyenne de page mémoire virtuelle écrite sur le disque par seconde. Cette valeur est à rapprocher de celles obtenues avec le compteur Mémoire\Pages/sec. - Fichier d’échange\Pourcentage d’utilisation
Paging File\% Usage
Ce compteur permet d’indiquer la proportion du fichier contenant les pages de mémoire stockées en mémoire virtuelle sur le disque. Cette valeur permet de savoir si le fichier d’échange contenant la mémoire virtuelle est sous-dimensionnée.
Contexte managé
Dans un contexte managé, il est possible d’utiliser des compteurs supplémentaires qui pourront donner des indices supplémentaires sur un comportement d’un processus. Ces compteurs ne sont utilisables que pour des procesus .NET.
- Verrous et threads CLR .NET\Taux de conflits/sec
.NET CLR LocksAndThreads\Contention Rate/sec
Ce compteur indique le nombre de fois que le CLR tente d’acquérir un lock managé sans succès. Une valeur différente de 0 peut indiquer qu’une partie du code d’un processus provoque des erreurs. - Verrous et threads CLR .NET\Longueur de la file actuelle
.NET CLR LocksAndThreads\Current Queue Length
Ce compteur permet de savoir quel est le nombre de threads attendant d’acquérir un lock managé dans un processus. Plus ce nombre est grand et plus il y a de la contention entre les threads ce qui peut révéler une mauvaise optimisation dans la synchronisation des threads d’un processus. - Verrous et threads CLR .NET\Nombre de threads actuels logiques
.NET CLR LocksAndThreads\# of current logical threads
Cette valeur indique le nombre de threads managés de l’application. Les threads peuvent être stoppés ou en cours d’exécution. L’intérêt de ce compteur est de pouvoir surveiller une variation dans le nombre de threads d’un processus. Si cet indicateur augmente pendant l’exécution du processus, il peut s’agir d’un trop grand nombre de threads qui sont créés sans pouvoir être exécutés. Il s’agit d’une valeur instantanée. - Verrous et threads CLR .NET\Nombre de threads actuels physiques
.NET CLR LocksAndThreads\# of current physical threads
Ce compteur indique le nombre de threads natifs du système d’exploitation appartenant au CLR effectuant des traitements pour des objets managés. Comme pour le compteur précédent, l’intérêt de ce compteur est de surveiller les variations dans le nombre de threads du processus. Une augmentation de cet indicateur peut révéler un trop grand nombre de threads créés par rapport à la capacité d’exécution du CLR.
Mémoire managée
- Mémoire CLR.NET\Nombre d’octets dans tous les tas
.NET CLR Memory\# Bytes in all heaps
Ce compteur est très utile pour suivre l’évolution de la mémoire managée d’un processus. Il correspond à la somme de la taille des tas de génération 1, 2 et des objets de grande taille. - Mémoire CLR.NET\Taille du tas de génération 0 (.NET CLR Memory\Gen 0 heap size)
Mémoire CLR.NET\Taille du tas de génération 1 (.NET CLR Memory\Gen 1 heap size)
Mémoire CLR.NET\Taille du tas de génération 2 (.NET CLR Memory\Gen 2 heap size)
Mémoire CLR.NET\Taille du tas des objets volumineux (.NET CLR Memory\Large Object Heap Size)
Ces compteurs permettent d’évaluer l’évolution des compteurs des tas principaux d’un processus managé .NET. Ces compteurs peuvent être utiles pour monitorer le comportement du Garbage Collector pour un processus donné.
Détecter les anomalies
Dans cette partie, on va essayer de décrire quelques cas de figures les plus courants de façon à savoir comment utiliser perfmon pour faciliter un diagnostique concernant le comportement d’un processus.
Le code correspondant à cette partie se trouve dans le repository GitHub:
github.com/msoft/memory_leak.
Détecter une fuite mémoire dans un processus managé
Dans un contexte managé, on a tendance à penser qu’il n’est pas très important de détecter des fuites mémoire, le Gargage Collector est assez efficace pour ne jamais permettre la survenance de fuite mémoire. Ceci est vrai à condition de ne pas maintenir des liens vers des objets non utilisés. Dans le cas contraire si un lien est maintenu vers un objet qui n’est plus utilisé, le Garbage Collector sera incapable d’évaluer que cet objet doit être supprimé. Le plus souvent, c’est la source d’une fuite mémoire dans un contexte managé. Evaluer une fuite mémoire avec perfmon n’est pas forcément trivial, il faut avoir à l’esprit plusieurs choses:
- Si un lien est maintenu vers un objet qui n’est plus utilisé, l’espace mémoire occupé par cet objet ne sera jamais libéré après exécution du Garbage Collector.
- Le Garbage Collector ne s’exécute pas tout le temps. Il est amené à s’exécuter quand une demande importante en mémoire est requise. Ainsi, la quantité de mémoire managée d’un processus peut augmenter jusqu’à ce que le Garbage Collector s’exécute pour libérer de la mémoire. Ainsi l’augmentation constante de la mémoire utilisée par un processus au cours de son exécution n’est pas forcément synonyme de fuite mémoire.
Pour illustrer ces 2 points, on se propose d’exécuter un processus et d’afficher la mémoire managé de ce processus dans perfmon:
- On implémente le code suivant:
internal class BigObject { private const string loremIpsum = "Lorem ipsum dolor ... laborum."; private List<string> strings = new List<string>(); public void CreateObjects() { for (int i = 0; i < 100000; i++) { strings.Add(loremIpsum); } } } public class ManagedBigObjectGenerator { private List<BigObject> objects = new List<BigObject>(); public void CreateObjects() { for (int i = 0; i < 100000; i++) { this.objects.Add(new BigObject()); if (i % 10 == 0) Thread.Sleep(100); } } }Ce code instancie un certain nombre d’objets sans jamais les libérer. Ces objets vont occuper un espace mémoire toujours plus important et ils ne seront jamais supprimé par le Garbage Collector car ils sont stockés dans une liste qui n’est jamais vidée.
- On exécute ce code et on affiche le compteur
Mémoire CLR.NET\Nombre d'octets dans tous les tasdans perfmon. - On peut voir que la quantité de mémoire utilisée par le processus ne cesse d’augmenter.
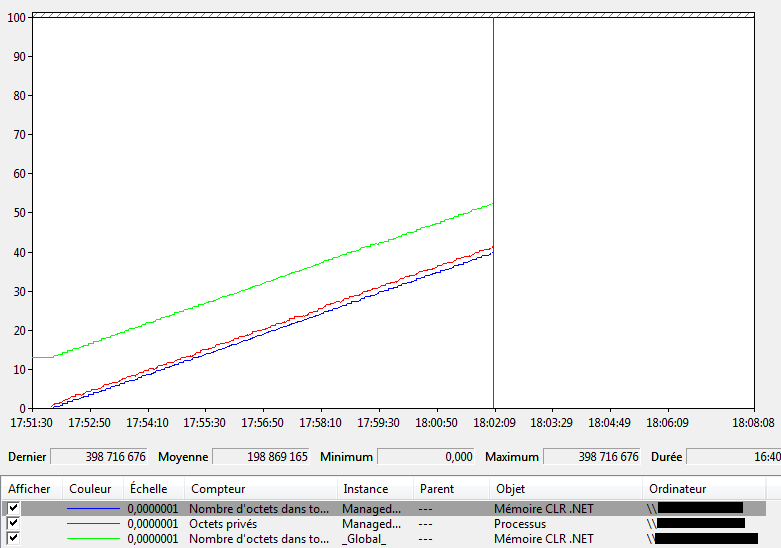
Le graphique précédent présente les courbes suivantes:- En rouge: le nombre d’octets privés c’est-à-dire la mémoire totale occupée par le processus.
- En bleu: le nombre d’octets dans tous les tas du processus, il s’agit de la quantité de mémoire managée.
- En vert: le nombre d’octets dans tous les tas pour tous les processus managés de la machine.
Comme dans le cas d’une fuite mémoire réelle, la consommation de mémoire ne cesse de croître et ne se stabilise pas.
Cependant comme indiqué plus haut, dans certains cas, une augmentation continue de la mémoire ne signifie pas forcément une fuite mémoire:
- Ainsi, si on implémente le code suivant:
public class ManagedBigObjectGeneratorWithWeakReferences { private List<WeakReference> objects = new List<WeakReference>(); public void CreateObjects() { for (int i = 0; i < 10000; i++) { this.objects.Add(new WeakReference(new BigObject())); if (i % 10 == 0) Thread.Sleep(100); } } }A la différence du code précédent, on utilise des objets de type
WeakReferencequi permettent de ne pas maintenir de liens avec les instances deBigObjectqui sont créés. Ainsi le Garbage Collector peut supprimer les instances. - En affichant le compteur
Mémoire CLR.NET\Nombre d'octets dans tous les tasdans perfmon, on constate dans un premier temps que la mémoire occupée augmente, toutefois après quelques minutes, cette quantité de mémoire se stabilise et cesse d’augmenter. La présence de l’objetWeakReferencepermet de ne pas maintenir un lien avec les objets et ils sont, ainsi, libérés par le Garbage Collector:
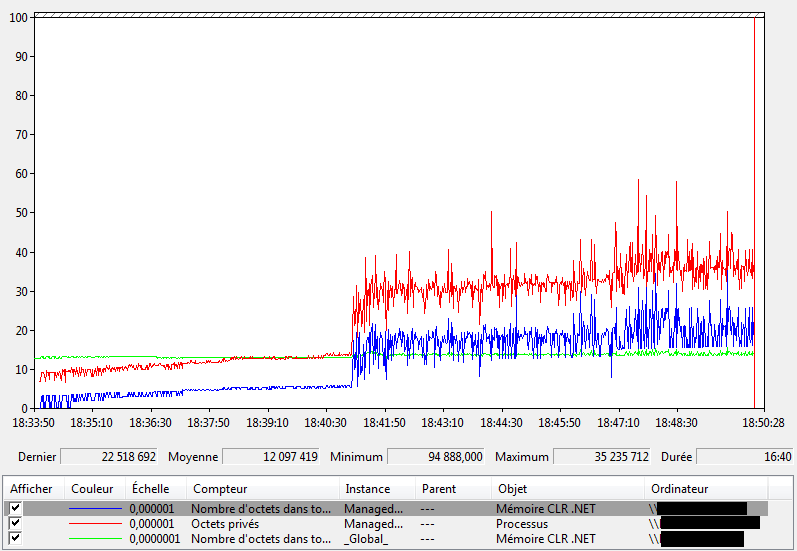
Ce graphique présente les mêmes courbes que précédemment:- En rouge: le nombre d’octets privés (mémoire totale occupée par le processus).
- En bleu: le nombre d’octets dans tous les tas du processus (quantité de mémoire managée).
- En vert: le nombre d’octets dans tous les tas pour tous les processus managés de la machine.
Détecter une fuite mémoire dans un processus non managé
Détecter une fuite dans un contexte non managée est plus rapide: dès qu’un objet est alloué sur le tas, s’il n’est pas libéré la mémoire ne peut pas être allouée à un autre objet. L’espace mémoire est ainsi perdu. Dans perfmon, il n’existe pas de compteur indiquant la quantité de mémoire non managée qui est utilisée. Pour détecter ce type de fuite mémoire, il faut utiliser 2 compteurs et déduire la mémoire non-managée à partir des compteurs:
Mémoire CLR.NET\Nombre d'octets dans tous les tas: il permet d’indiquer la quantité de mémoire managée.Processus\Octets privés(ouProcess\Private bytes): ce compteur permet d’indiquer la quantité de mémoire occupée le processus (mémoire managée + mémoire non managée).
La mémoire non managée peut être déduite en utilisant la formule:
Processusoctets privés - Mémoire CLR .NETnombre octets dans tous les tas = Mémoirenon-managée
Ainsi si la quantité totale de mémoire du processus augmente sans que la mémoire managée augmente, cela signifie qu’il peut exister une fuite mémoire dans le code non managée. Si un processus présente une anomalie de ce type, l’évolution des compteurs pourrait ressembler à ces courbes:
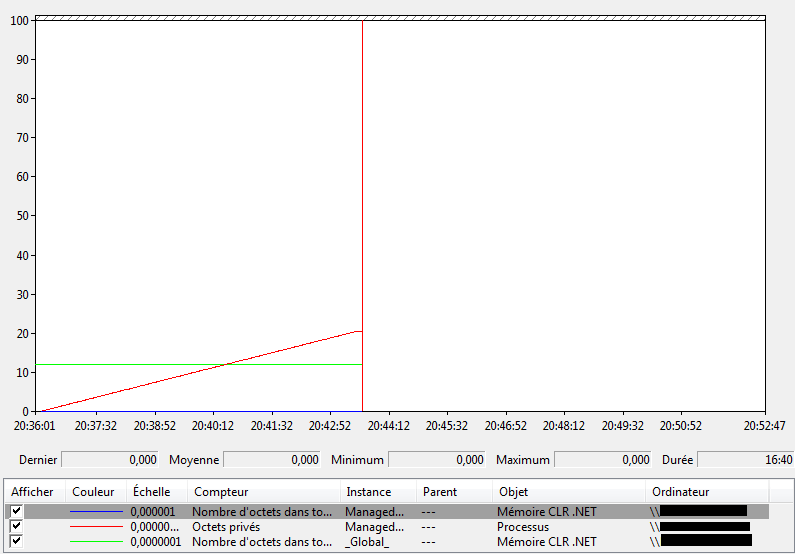
Ce graphique présente les mêmes courbes que précédemment:
- En rouge: le nombre d’octets privés (mémoire totale occupée par le processus).
- En bleu: le nombre d’octets dans tous les tas du processus (quantité de mémoire managée).
- En vert: le nombre d’octets dans tous les tas pour tous les processus managés de la machine.
Dans la courbe précédente, la quantité de mémoire managée (courbe bleue) reste à zéro car le code exécuté provient d’une assembly mixte contenant du code managé et du code natif (C++/CLI). Avec ce type d’assembly, perfmon ne détecte pas de code managé, c’est la raison pour laquelle cette courbe reste à zéro. Pour contourner ce problème, on affiche le nombre d’octets dans tous les tas pour tous les processus de la machine de façon à avoir une idée de l’évolution de la mémoire managée à l’échelle du processus.
Le code correspondant à cette partie se trouve dans le projet suivant:
github.com/msoft/memory_leak/tree/master/UnamanagedMemoryLeak.
Conclusion
Le but de cet article était d’indiquer les fonctionnalités principales de perfmon de façon à pouvoir l’utiliser rapidement. J’espère qu’il vous aura aider à configurer perfmon efficacement et surtout qu’il vous aura convaincu de l’utilité de perfmon pour monitorer une application ou une machine.
Documentation générale:
- Process Explorer v16.21: https://docs.microsoft.com/en-us/sysinternals/downloads/process-explorer
- Getting thread CPU usage using PerfMon: https://developer.voxtron.com/?p=32
- Key Performance Monitor Counters: http://techgenix.com/key-performance-monitor-counters/
- Monitoring CPU Performance Counters:
https://www.itprotoday.com/cloud-computing/monitoring-cpu-performance-counters - How to setup Performance Counters to assist with CPU / Memory related issues: http://micc.mitel.com/kb/TroubleshooterGuide50563.aspx
- Windows Performance Counters Explained: http://www.appadmintools.com/documents/windows-performance-counters-explained/
- How to save Perfmon data using Windows 7 performance monitor: https://searchitchannel.techtarget.com/feature/Using-Windows-7-performance-monitor-to-view-data
- Taming Perfmon: Data Collector Sets: https://blogs.technet.microsoft.com/askpfeplat/2012/02/27/taming-perfmon-data-collector-sets/
- How to use Performance Monitor on Windows 10: https://www.windowscentral.com/how-use-performance-monitor-windows-10
- Using Performance Monitor (PerfMon) to monitor SCADA systems: https://www.schneider-electric.com/resources/sites/SCHNEIDER_ELECTRIC/content/live/FAQS/325000/FA325349/en_US/PerformanceMonitorv2.pdf
Documentation sur les compteurs:
- Compteurs de performance dans le .NET Framework: https://docs.microsoft.com/fr-fr/dotnet/framework/debug-trace-profile/performance-counters
- Lock and Thread Performance Counters: https://docs.microsoft.com/en-us/previous-versions/dotnet/netframework-1.1/zf749bat(v=vs.71)
- What is private bytes, virtual bytes, working set?: https://stackoverflow.com/questions/1984186/what-is-private-bytes-virtual-bytes-working-set
- GC Performance Counters: https://blogs.msdn.microsoft.com/maoni/2004/06/03/gc-performance-counters/
- Memory Performance Counters: https://msdn.microsoft.com/en-us/library/x2tyfybc%28v=vs.110%29.aspx
Exécuter perfmon à distance:
- Powershell Performance Monitor on multiple remote computers: https://www.microsoftpro.nl/2013/11/21/powershell-performance-monitor-on-multiple-remote-computers/
- Setting a remote perfmon in a Windows client or Windows Server.: https://blogs.technet.microsoft.com/yongrhee/2015/05/16/setting-a-remote-perfmon-in-a-windows-client-or-windows-server/
- Setting a remote perfmon Windows Server 2012 style…: https://blogs.technet.microsoft.com/yongrhee/2013/09/06/setting-a-remote-perfmon-windows-server-2012-style/
- How often should Perfmon Sample?: https://blogs.technet.microsoft.com/yongrhee/2011/11/13/how-often-should-perfmon-sample/
- logman: https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/logman
Autre:
- Best Practices No. 5: Detecting .NET application memory leaks: https://www.codeproject.com/Articles/42721/Best-Practices-No-Detecting-NET-application-memo
- Working with Performance Counters in PowerShell: https://mcpmag.com/articles/2018/02/07/performance-counters-in-powershell.aspx
- Send email alert from Performance Monitor using PowerShell script: https://stackoverflow.com/questions/18475519/send-email-alert-from-performance-monitor-using-powershell-script
- What permissions are required to allow attaching a remote performance monitor?: https://superuser.com/questions/599636/what-permissions-are-required-to-allow-attaching-a-remote-performance-monitor
- How to repair Windows Performance Monitor: https://borncity.com/win/2016/04/03/how-to-repair-windows-performance-monitor/
Bonjour,
Vos articles sont extremement bien écrits, bien organisés en vue de leur lecture, Félicitations.
Cdlt