L’intérêt de l’injection de dépendances est de permettre:
– une meilleure maintenabilité,
– de mettre en place plus facilement une méthode TDD (Test Driven Development),
– d’être plus flexible (plus facile de s’adapter à une nouvelle implémentation),
– d’être plus extensible (ajout plus facile de nouvelles fonctionnalités),
– supporter le "late binding" (inclure des modules sans recompiler),
– le développement paralllèle,
– faible couplage en réduisant le nombre de dépendances.
Il existe plusieurs bibliothèques disponibles en .NET permettant l’injection de dépendances:
– Castle Windsor disponible sur GitHub. Une documentation est aussi disponible sur GitHub.
– Spring.NET.
– StructureMap présent sur GitHub très bien documenté.
– Autofac
– Unity: le code est disponible sur GitHub. La documentation se trouve sur MSDN.
– Ninject
– S2Container.NET
– PicoContainer.NET disponible sur GitHub.
Quelques approches pour déléguer la gestion d’objets
Plusieurs approches permettent de déléguer l’instanciation et la gestion de la durée de vie d’objets à d’autres classes différentes de celles qui les consomment. Les patterns "Factory" et le pattern "Service Locator" sont quelques unes de ces approches.
Patterns "Factory"
Il existe 3 implémentations du pattern factory: "factory method", fabrique abstraite et factory simple.
Method factory
Dans une classe consommatrice, on implémente une méthode virtuelle qui sera chargée de créer l’objet. Cette méthode peut, par exemple, être appelée dans le constructeur de la classe consommatrice. De plus elle peut être surchargée dans une classe qui hérite de la classe consommatrice.
Inconvénients:
– Si plusieurs classes consommatrices doivent utiliser le même objet, elles devront toute implémenter une fonction pour créer l’objet. De plus, cette fonction peut nécessiter d’autres objets pour créer l’objet, ce qui complexifie le modèle.
– Les tests à effectuer sur la classe consommatrice, ne sont pas évident à implémenter puisqu’il faut prévoir un mécanisme pour simuler la création de l’objet.
Factory simple
Ce pattern introduit une "factory" pour déléguer la création de l’objet. La classe consommatrice crée donc la "factory" et crée l’objet consommé au moyen de cette "factory".
Inconvénients
– La complexité de ce modèle peut augmenter rapidement si la classe consommatrice doit créer beaucoup d’objets.
– Si on doit créer des objets de type différent, il faudra créer les "factory" correspondantes. La logique de choix des "factory" reste dans la classe consommatrice. L’utilisation de plusieurs "factory" correspond au pattern "fabrique abstraite".
Exemple:
public class ManagementController : Controller
{
private readonly ITenantStore tenantStore;
public ManagementController()
{
var tenantStoreFactory = new TenantStoreFactory();
this.tenantStore = tenantStoreFactory.CreateTenantStore();
}
public ActionResult Index()
{
var model = new TenantPageViewData<IEnumerable>(this.tenantStore.GetTenantNames())
{
Title = "Subscribers"
};
return this.View(model);
}
...
}
Pattern "Service Locator"
Le "Service Locator" se comporte comme un registre à qui on demande des objets. C’est le "Service Locator" qui va créer et enregistrer l’objet. Pour obtenir l’instance, la classe consommatrice doit fournir le nom de l’objet et le type voulu en retour. En utilisant ce pattern, le "Service Locator" devient le responsable de la durée de vie de l’objet.
Inconvénients:
La seule contrainte de ce pattern est de maintenir une référence vers le "Service Locator" dans la classe consommatrice de façon y faire appel pour créer les objets.
Injection de dépendances
Dans la classe consommatrice, l’injection de l’objet se fait par le constructeur. Ainsi on ne garde pas une référence vers un "service locator" ou vers une "factory". De plus la gestion de la durée de vie de l’objet n’est pas effectuée par la classe consommatrice. On a une inversion de contrôle puisque l’objet est poussé vers la classe consommatrice sans demande explicite.
Un autre intérêt est que la classe consommatrice n’a pas de connaissance sur l’objet à créer puisque l’objet n’est manupulé qu’au moyen de son interface.
Exemple:
public class ManagementController : Controller
{
private readonly ITenantStore tenantStore;
public ManagementController(ITenantStore tenantStore)
{
this.tenantStore = tenantStore;
}
public ActionResult Index()
{
var model = new TenantPageViewData<IEnumerable>(this.tenantStore.GetTenantNames())
{
Title = "Subscribers"
};
return this.View(model);
}
...
}
L’injection de dépendances permet de minimiser les dépendances puisque dans le cas d’une "factory", la classe consommatrice possède une dépendance vers la "factory" et vers l’interface de l’objet à utiliser.
Dans le cas de l’injection de dépendance, sachant que l’objet à utiliser est injecté directement dans la classe consommatrice, il n’y a plus de dépendances vers une "factory" ou une autre classe qui fournit l’objet.
Instanciation des objets
L’injection de dépendances nécessite de devoir instancier tous les objets dans l’application. Cette instanciation doit se faire très tôt dans le cycle de vie de l’application pour être correctement utliisé par la suite (i.e. dans le Main() d’une application "Console", dans le "Global.asax" d’une application web etc…).
Durée de vie des objets
Certaines problématiques concernent la durée de vie des objets:
– Un objet doit-il être partagé entre plusieurs classes ou chaque classe doit-elle utiliser une seule instance.
– Quelle est la durée de vie de l’objet ? Sa durée de vie doit être lié à celle de la classe consommatrice et à celle de l’application.
Type d’injection
Plusieurs types d’injection:
– Injection par le constructeur: comme dans l’exemple précédent.
– Injection en utilisant un accesseur: à utiliser dans le cas où la dépendances est optionnelle sinon privilégier l’injection par le constructeur.
– Injection par appel à une méthode: cete méthode peut êter utile quand il est nécessaire d’avoir un paramètre supplémentaire qui ne peut être passé dans le constructeur.
Exemple:
public class MessageQueue : ...
{
public MessageQueue(StorageAccount account)
: this(account, typeof(T).Name.ToLowerInvariant())
{
}
public MessageQueue(StorageAccount account,
string queueName)
{
...
}
public void Initialize(TimeSpan visibilityTimeout, IRetryPolicyFactory retryPolicyFactory)
{
...
}
...
}
Quand ne pas utiliser l’injection de dépendances
– Petites applications,
– Dans une application existante qui n’est pas conçue à l’origine pour l’inversion de contrôle.
– L’enregistrement des types et la recherche d’instances introduisent un temps d’exécution plus long. Ce temps est très négligeable pour la recherche d’instances mais est plus pénalisant pour l’enregistrement (même s’il n’est effectué qu’une seule fois).
Injection de dépendances avec Unity
Dans le cycle de vie d’un objet manipulé par l’injection de dépendances, il y a 3 étapes:
– L’enregistrement: elle se fait auprès d’un conteneur d’objets appelé "container":
var container = new UnityContainer();
container.RegisterType();
– La résolution: qui permet d’instancier à la fois la classe consommatrice et les objets à injecter dans la classe consommatrice:
var controller = container.Resolve();
– La suppression par le garbage collector.
Exemples d’enregistrement
Enregistrement d’instances
L’instance est enregistrée directement. L’instance peut ensuite être retrouvée par son type:
StorageAccount account = ApplicationConfiguration.GetStorageAccount("DataConnectionString");
container.RegisterInstance(account);
Enregistrement d’un type simple
On enregistre un type qui sera reconnue par son interface:
container.RegisterType();
La résolution permet d’instancier l’objet à partir de l’interface:
var surveyStore = container.Resolve();
Enregistrement d’un type par nommage
En nommant l’enregistrement, il est possible d’en utliser plusieurs instances:
container
.RegisterType<IMessageQueue, MessageQueue>(
"Standard", new InjectionConstructor(storageAccountType, retryPolicyFactoryType,
Constants.StandardAnswerQueueName))
.RegisterType<IMessageQueue, MessageQueue>(
"Premium", new InjectionConstructor(storageAccountType, retryPolicyFactoryType,
Constants.PremiumAnswerQueueName));
La résolution peut se faire aussi en utilisant les noms:
container.Resolve<IMessageQueue>("Standard"),
container.Resolve<IMessageQueue>("Premium"),
Injection avec le constructeur
On peut injecter des classes enregistrées avec des paramètres:
public DataTable(StorageAccount account, IRetryPolicyFactory retryPolicyFactory,
string tableName)
{
...
}
Au préalable, les types auront été enregistrés avec:
container
.RegisterType<IDataTable, DataTable>(
new InjectionConstructor(storageAccountType,
retryPolicyFactoryType, Constants.SurveysTableName))
.RegisterType<IDataTable, DataTable>(
new InjectionConstructor(storageAccountType,
retryPolicyFactoryType, Constants.QuestionsTableName));
Enregistrer des génériques
Pour enregistrer une classe qui utlise des génériques, la syntaxe est un peu différente:
container.RegisterType(typeof(IMessageQueue), typeof(MessageQueue),
new InjectionConstructor(storageAccountType, retryPolicyFactoryType, typeof(string)));
La résolution du type se fait en faisant:
container.Resolve<IMessageQueue>(...)
Surcharge des paramètres
Si on doit préciser un paramètre dans le constructeur et que la valeur n’est pas connu au moment de l’enregistrement, on peut préciser le type de ce paramètre. Ainsi au moment de la résolution, il sera possible d’indiquer la valeur du paramètre et exécuter le bonne surcharge du constructeur.
Par exemple:
container.RegisterType(typeof(IMessageQueue), typeof(MessageQueue),
new InjectionConstructor(storageAccountType, retryPolicyFactoryType, typeof(string)));
...
container.RegisterType<IBlobContainer, EntitiesBlobContainer>(
new InjectionConstructor(storageAccountType, retryPolicyFactoryType, typeof(string)));
Exemple de résolution de types
Résolution simple
container.Resolve().Initialize();
Gestion de la durée de vie
| Lifetime manager |
Application |
Dépendances de référence |
Exemple |
| ContainerControlledLifetimeManager |
Singleton |
Container |
container.RegisterType(
new ContainerControlledLifetimeManager()); |
| HierarchicalLifetimeManager |
Singleton |
ChildContainer |
IUnityContainer container = new UnityContainer();
container.RegisterType(
new HierarchicalLifetimeManager());
IUnityContainer child1 = container.CreateChildContainer();
IUnityContainer child2 = container.CreateChildContainer();
var tenant1 = child1.Resolve();
var tenant2 = child2.Resolve();
var tenant3 = container.Resolve(); |
| TransientLifetimeManager |
Instance |
Une instance différente par appel à Resolve(). |
| PerResolveLifetimeManager |
Instance |
Une seule instance par appel à Resolve(). |
| ExternallyControlledLifetimeManager |
Singleton |
Aucune ("weak reference") |
| PerRequestLifetimeManager |
Instance |
Une instance par appel à Resolve() et par requête HTTP. |
Il est possible de définir une "LifetimeManager" spécialisé.
Interception
Ce parttern permet d’incorporer des fonctionnalités à une classe: logging, gestion d’exception, authentification, gestion de cache etc…
L’ajout de fonctionnalités doit toutefois satisfaire certains critères de qualité:
– Cohérence,
– Maintenabilité du code,
– Eviter la duplication du code.
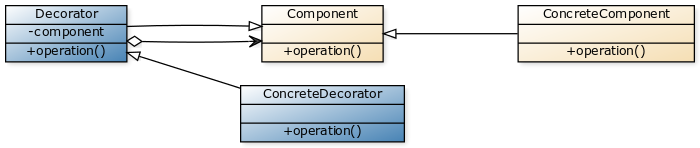
Pattern "décorateur"
Ce pattern permet de répondre à la problématique de l’interception en rajoutant dynamiquement des compétences à une classe:
Si on considère l’interface:
public interface ITenantStore
{
void Initialize();
Tenant GetTenant(string tenant);
IEnumerable GetTenantNames();
void SaveTenant(Tenant tenant);
void UploadLogo(string tenant, byte[] logo);
}
public class TenantStore : ITenantStore
{
public TenantStore(IBlobContainer tenantBlobContainer,
IBlobContainer logosBlobContainer)
{
...
}
}
On ajoute une compétence à la classe en injectant une classe du même type. Dans cet exemple, la compétence rajoutée est le logging:
class LoggingTenantStore : ITenantStore
{
private readonly ITenantStore tenantStore;
private readonly ILogger logger;
public LoggingTenantStore(ITenantStore tenantstore, ILogger logger)
{
this.tenantStore = tenantstore;
this.logger = logger;
}
public void Initialize()
{
tenantStore.Initialize();
}
public Tenant GetTenant(string tenant)
{
return tenantStore.GetTenant(tenant);
}
public IEnumerable GetTenantNames()
{
return tenantStore.GetTenantNames();
}
public void SaveTenant(Tenant tenant)
{
tenantStore.SaveTenant(tenant);
logger.WriteLogMessage("Saved tenant" + tenant.Name);
}
public void UploadLogo(string tenant, byte[] logo)
{
tenantStore.UploadLogo(tenant, logo);
logger.WriteLogMessage("Uploaded logo for " + tenant);
}
}
On peut ensuite rajouter plusieurs compétences en faisant des cascades "d’injection".
Pattern "interception"
"Interception" permet d’introduire dynamiquement entre la classe appelante et la classe cible, du code responsable de l’ajout de compétences. La différence entre "décorateur" et "interception" est que interception crée lui-même dynamiquement les classes dans lesquelles on veut rajouter les compétences.
Le nom "interception" provient du fait qu’on intercepte la classe pour lui rajouter des compétences.
Concrètement l’interception permet d’ajouter un comportement à une classe sans inplémenter directement ce comportement dans la classe. Par exemple, si on souhaite logguer des évènements, il suffit de configurer un comportement pour qu’il se déclenche lors de l’appel de fonctions et d’attacher ce comportement à la class. L’intérêt est aussi de pouvoir rajouter plusieurs comportements.
Interception d’instances
Dans ce cas, Unity instancie:
– Un objet proxy (du même type que la classe cible) qui est inséré entre la classe appelante et la classe cible. C’est sur cet objet qu’on rajoutera les différentes compétences.
– Un pipeline de comportements ("behavior pipeline") permettant de rajouter des compétences à l’objet proxy. On utilise le terme "pipeline" car les compétences sont appelées à la suite.
La classe cible doit dériver de "MarshalByRefObject" ou implémenter une interface qui définit les méthodes à intercepter. Il n’est pas possible de faire un "cast" de l’objet proxy vers le type de la classe cible.

Interception de type
Dans ce cas, Unity génère directement la classe cible avec les compétences voulues en fonction de son type. Les fonctions à intercepter doivent être virtuelles.
Implémentation de l’interception avec Unity
Prérequis
Pour utiliser l’interception avec Unity, il faut ajouter l’extension correspondante avec NuGet:
using Microsoft.Practices.Unity.InterceptionExtension;
...
IUnityContainer container = new UnityContainer();
container.AddNewExtension();
Définition d’un intercepteur
Il suffit de satisfaire l’interface "IInterceptionBehavior" et d’implémenter la méthode:
public IMethodReturn Invoke(IMethodInvocation input, GetNextInterceptionBehaviorDelegate getNext)
Cette méthode est exécutée lorsqu’on appelle la méthode dans la classe interceptée. "Input" permet de connaître les paramètres d’entrée de la fonction et "getNext" permet d’exécuter ou non le prochain intercepteur dans le pipeline.
L’appel au prochain intercepteur peut se faire en implémentant:
IMethodReturn result = getNext()(input, getNext);
Enregistrer un intercepteur
container.AddNewExtension();
container.RegisterType(
new Interceptor(),
new InterceptionBehavior(),
new InterceptionBehavior());
"TenantStore" est la classe interceptée; "ITenantStore" correspond à l’interface de "TenantStore".
"InterfaceInterceptor" est la méthode d’interception (par interface), on peut utiliser:
– TransparentProxyInterceptor pour l’interception d’instance
– VirtualMethodInterceptor pour l’interception par type.
"LoggingInterceptionBehavior" et "CachingInterceptionBehavior" sont des intercepteurs satisfaisant l’interface IInterceptionBehavior.
L’ordre de l’enregistement est important puisqu’il sera le même dans le pipeline de comportements.
Appel à un intercepteur
SaveTenant() est une méthode définie dans TenantStore et qui sera interceptée. La variable "tenantStore" n’est pas de type "TenantStore" mais il s’agit d’une classe proxy qui satisfait "ITenantStore" et qui sera interceptée.
Interception d’instance et interception de type
TransarentProxyInterceptor
Permet d’intercepter un objet qui satisfait plusieurs interfaces.
Par exemple:
container.RegisterType<ITenantStore, TenantStore>(
new Interceptor(),
new InterceptionBehavior(),
new InterceptionBehavior());
var tenantStore = container.Resolve();
// From the ITenantStore interface.
tenantStore.SaveTenant(tenant);
// From the ITenantLogoStore interface.
((ITenantLogoStore)tenantStore).SaveLogo("adatum", logo);
Dans l’exemple, "TenantStore" satisfait "ITenantStore" et "ITenantLogoStore". Avec TransparentProxyInterceptor, la classe proxy satisfera aussi les deux interfaces.
TransparentProxyInterceptor est plus lent à s’exécuter.
VirtualMethodInterceptor
Contrairement à InterfaceInterceptor et TransparentProxyInterceptor qui utilisent un objet proxy qui satisfait une interface, VirtualMethodInterceptor utilise un objet qui dérive de la classe modèle et dont les méthodes virtuelles sont réimplémentées.
Utiliser un comportement pour ajouter une interface à une classe existante
Il peut être nécessaire de rajouter une interface par implémentation, on peut le faire en considérant l’interface comme un comportement:
container.Register(
new Interceptor(),
new InterceptorBehavior(),
new InterceptorBehavior(),
new AdditionalInterface());
Dans l’exemple, on rajoute l’interface "ILogger".
Implémenter l’interception sans utiliser de container
On peut éviter d’appeler UnityContainer" en faisant appel directement à la classe "intercept".
Le code avec "container" est:
// Example 1. Using a container.
// Configure the container for interception.
container = new UnityContainer();
container.AddNewExtension();
// Register the TenantStore type for interception.
container.RegisterType(
new Interceptor(),
new InterceptionBehavior(),
new InterceptionBehavior());
// Obtain a proxy object with an interception pipeline.
var tenantStore = container.Resolve();
L’équivalent sans "container" est:
// Example 2. Using the Intercept class.
ITenantStore tenantStore = Intercept.ThroughProxy(
new TenantStore(tenantContainer, blobContainer), new InterfaceInterceptor(),
new IInterceptionBehavior [] { new LoggingInterceptionBehavior(),
new CachingInterceptionBehavior()
});
– Intercept.ThroughProxy permet de créer un objet proxy.
– Intercept.NewInstance permet de créer une nouvelle instance qui dérive de la classe à intercepter.
Politique d’injection
L’inconvénient de l’approche présentée précédemment est qu’elle nécessite d’enregistrer les interceptions auprès de la classe "container" pour toutes les classes pour lesquelles on souhaite un comportement d’interception. Une autre approche est de permettre l’interception lorsque certaines conditions sont réunies:
– La classe se trouve dans un namespace particulier.
– La classe possède des propriétés avec certaines valeurs.
– La classe possède un attribut particulier.
– etc…
La politique d’injection permet de définir les conditions que doivent satisfaire une classe pour qu’elle soit interceptée évitant ainsi d’avoir à configurer explicitement l’interception pour cette classe.
L’exemple suivant permet de montrer une implémentation de la politique d’injection pour les classes se
trouvant dans un namespace particulier ("Tailspin.Web.Survey.Shared") et dont l’interception se déclenche lors de l’appel à des fonctions avec des signatures commençant par "Get*" et "Save*":
container.RegisterType(
new InterceptionBehavior(),
new Interceptor());
container.RegisterType(
new InterceptionBehavior(),
new Interceptor());
var first = new InjectionProperty("Order", 1);
var second = new InjectionProperty("Order", 2);
container.Configure()
.AddPolicy("logging")
.AddMatchingRule(new InjectionConstructor(
new InjectionParameter("Tailspin.Web.Survey.Shared")))
.AddCallHandler(new ContainerControlledLifetimeManager(),
new InjectionConstructor(), first);
container.Configure()
.AddPolicy("caching")
.AddMatchingRule(new InjectionConstructor(new [] {"Get*", "Save*"}, true))
.AddMatchingRule(new InjectionConstructor(
"Tailspin.Web.Survey.Shared.Stores", true))
.AddCallHandler(new ContainerControlledLifetimeManager(),
new InjectionConstructor(), second);
Il existe aussi une implémentation qui permet de configurer des comportements par attribut. Ainsi on enregistre le comportement d’interception au niveau de "container" et l’application des comportements se fait en décorant la classe ou des fonctions avec un attribut particulier.