| PARTIE 1 | PARTIE 2 | PARTIE 3 | ||
|---|---|---|---|---|
| Sommaire général | Concevoir des microservices | Appels entre Microservices | Intégration continue et implémentation des tests | Références |
Quelques définitions
Architecture orientée service (SOA)
Qu’est-ce que l’approche en microservices ?
Les microservices ne sont pas la solution idéale
Concevoir des microservices
Principe général
Séparation de la logique fonctionnelle en contextes bornés
Bounded context
Découpage en contextes bornés
Casser un monolithe
Couche anticorruption
Extraire la logique fonctionnelle
Application de DRY
Utiliser une base de données à partir de microservices
Passer d’une base de données commune à une base séparée
Données statiques partagées
Utiliser un service “proxy”
Accéder à des ressources provenant d’un autre service
ACID vs BASE
Quelques définitions
Quelques définitions en préambule…
Architecture orientée service (SOA)
L’approche SOA a le même objectif que l’architecture en microservices:
- Casser l’architecture en monolithe: un monolithe est une application qui est implémentée dans un seul projet. Cette architecture est généralement la plus facile à mettre en œuvre puisque toutes les problématiques d’implémentation et d’exécution (choix de la technologie de programmation, problématiques d’accès concurrents à une ressource, communications entre composants, déploiement, usine de build, intégration continue etc…) se posent pour un seul projet.
A l’opposé ce type d’architecture rend plus difficile l’expérimentation de technologies exotiques. Elle peut devenir contraignante dans le cas où le code existant devient trop complexe à faire évoluer. - Permet de promouvoir la réutilisation de briques de services: isoler un service et le séparer d’un monolithe permet d’isoler des fonctionnalités et de faciliter leur réutilisation par plusieurs projets.
- Facilite l’intégration de services: un des objectifs des services est de permettre de les appeler à partir de projets différents. L’utilisation de technologies de communication ou de middleware permet d’appeler des services en étant dans un processus différent à travers le réseau. Faciliter les communications entre processus permet de partager plus facilement une fonctionnalité.
L’approche SOA est considérée par beaucoup comme un échec car:
- Trop théorique: beaucoup d’architectes ont écrit des articles pour décrire cette approche sans forcément donner des indications pratiques sur la façon de casser un monolithe et d’avoir une implémentation évolutive d’un service. Les services sont perçus comme des monolithes pour lesquels on a facilité les communications.
- Pas de prise en compte des difficultés opérationnelles: l’approche trop théorique n’a pas apporté de solutions à des problématiques opérationnelles comme le déploiement, la scalabilité, le monitoring etc… Les implémentations de services peuvent se heurter à des difficultés à assurer des problématiques qui se résolvent plus facilement avec une approche en monolithe.
- Protocoles de communication difficiles à utiliser: l’architecture en services a, parfois été vendue par des éditeurs de middlewares qui proposaient des solutions de communications souvent couteuses et propriétaires. Ces solutions avaient une empreinte forte sur l’implémentation des services ce qui couplaient les services au middleware.
- Choix d’architecture peu évolutive et contraignante: l’utilisation de ces middlewares peut aussi rendre l’architecture en services peu évolutive et contraignante car très dépendantes des middlewares.
Qu’est-ce que l’approche en microservices ?
Les microservices sont un cas particulier des services: ce sont des services autonomes de petites tailles travaillant ensemble.
La plupart des définitions que l’on peut trouver évoque l’importance de l’autonomie et de la taille:
| “En informatique, les microservices sont un style d’architecture logicielle à partir duquel un ensemble complexe d’applications est décomposé en plusieurs processus indépendants et faiblement couplés, souvent spécialisés dans une seule tâche.” | “In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.” | |||
| Wikipedia | ||||
| James Lewis and Martin Fowler | ||||
A la différence de l’approche SOA, l’approche Microservices a émergé dans le but de répondre plus facilement à des problématiques opérationnelles. L’architecture en microservices énonce des principes d’architectures en indiquant des solutions possibles et pratiques pour la plupart des problématiques.
Il n’est pas forcément pertinent d’appliquer rigoureusement toutes les solutions envisagées, tout dépend du contexte. L’important est d’avoir en tête des solutions possibles et d’adapter certaines d’entres elles à son contexte en fonction de ses problématiques propres.
Comme on l’a indiqué plus haut, l’objectif principal d’une architecture en microservices est de casser une application en monolithe pour la rendre moins complexe:
On peut énoncer quelques caractéristiques de l’architecture en microservices:
- “Doing one thing well”: on doit tenter de limiter un microservice à une seule fonction. La règle n’est pas absolue mais chaque microservice doit avoir une responsabilité limitée. Les délimitations du microservice peuvent correspondre à des frontières fonctionnelles.
- Autonomie: un microservice doit être autonome par rapport aux autres microservices. Le but est d’éviter de trop coupler les microservices entre eux.
- Utiliser des technologies plus adaptées aux besoins: un atout des microservices est de permettre une plus grande libertée sur les choix technologiques par rapport à une application monolitique. La taille limitée d’un microservice rends plus facile des choix technologiques risqués ou exotiques. Les développeurs sont, ainsi, plus libres de leurs choix techniques en utilisant une technologie plus adaptée.
- Tolérance aux pannes: les microservices peuvent être plus tolérants aux pannes par rapport à une application en monolithe. En cas d’échec d’un service, les autres services peuvent toujours fonctionner. L’absence d’un service dégrade l’application toutefois elle peut rester partiellement opérationnelle. A l’inverse, si une application en monolithe crashe, on peut difficilement la faire fonctionner de façon partielle, il faut généralement la redémarrer entièrement.
- S’adapter à la charge: les microservices permettent de s’adapter plus facilement à la charge.
Adapter la charge peut se faire de 2 façons:- Mise à l’échelle verticale (i.e. scale-up): pour augmenter les capacités de l’application, on augmente les capacités de la machine hôte. Ce type d’opération est couteux et plus difficile à mettre en œuvre car il faut remplacer la machine hôte et interrompre le fonctionnement de l’application pendant l’opération.
- Mise à l’échelle horizontale (i.e. scale-out): l’augmentation des capacités de l’application se fait en augmentant le nombre d’instances. Ce type d’opération pose d’autres problèmes comme le load-balancing toutefois elle est moins couteuse qu’une augmentation des capacités de la machine hôte. En outre, elle donne la possiblité d’adapter la charge “à chaud” c’est-à-dire sans interruption de service en ajoutant ou en diminuant le nombre d’instances.
L’approche en microservice rend plus facile la mise à l’échelle horizontale qui est la méthode la plus scalable et la moins couteuse.
De même, il est moins risqué de déployer un service qu’une application entière. Si on constate un bug, on peut plus facilement effectuer un rollback de la nouvelle version.
Les microservices ne sont pas forcèment la solution idéale
L’architecture en microservices apporte de nombreux avantages toutefois, elle est loin d’être une solution idéale car elle déplace la compléxité de l’implémentation vers d’autres problématiques par rapport à une application en monolithe:
- La compléxité des microservices n’est pas dans le code source comme pour un monolithe, mais dans les interactions entres les services.
- Les microservices peuvent être très hétérogènes ce qui peut rendre leur implémentation plus complexe qu’un monolithe.
En réalité, une application en microservices est un système distribué. En plus de la compléxité fonctionnelle de l’application, se posent d’autres problématiques plus difficiles à résoudre que pour un monolithe comme par exemple:
- Les communications entre services,
- Le partitionnement de la base de données,
- La modification d’un service par rapport au fonctionnement des autres services,
- Les tests,
- Le déploiement,
- Etc…
Concevoir des microservices
Le but de cette partie est d’énoncer quelques principes pour la conception d’une architecture en microservices idéale. Il n’y a pas de solutions parfaites ou universelles, ces principes ne servent qu’à apporter quelques pistes de résolution qu’il convient d’appliquer en fonction du contexte.
Principe général
D’une façon générale, la conception de microservices doit assurer:
- Un faible couplage: de façon à permettre de modifier les services indépendamment et d’assurer une autonomie dans leur fonctionnement. Des services faiblement couplés permettront de tirer partie au maximum de l’architecture en microservices: tolérance aux pannes, s’adapter à la charge, faciliter les déploiements, etc…
- Grande cohésion: assurer une cohésion entre les services vise à rendre les échanges entre ces services de façon la plus cohérente possible en:
- Utilisant des interfaces claires avec des types précis: par exemple, il faut éviter d’utiliser des types comme
objectpas assez précis qui laissent trop de libertés quant au type des objets. De même, il faut éviter de définir des fonctions qui ont plusieurs objectifs, il est préférable de limiter une fonction à un seul cas d’utilisation. - Eviter les choix technologiques trop exotiques dans les communications entre service: par exemple, il faut éviter d’utiliser des middlewares qui sont généralement couteux en licence et peuvent avoir une empreinte forte dans l’implémentation des services.
- Eviter les breaking changes: il faut penser les interfaces pour limiter les breaking changes lors des évolutions des services. Des breaking changes dans les interfaces d’un service nécessitent la modification des services qui y font appel. Ces breaking changes peuvent compliquer les déploiements.
- Ne pas exposer des détails d’implémentation internes d’un service: exposer des détails de l’implémentation interne d’un service peut donner des indices sur son fonctionnement. D’autres services peuvent involontairement tirer partie de ce fonctionnement et avoir une implémentation dépendant de ce fonctionnement. Des implémentations trop dépendantes rendent le couplage plus important entre les services.
- Utilisant des interfaces claires avec des types précis: par exemple, il faut éviter d’utiliser des types comme
Séparation de la logique fonctionnelle en contextes bornés
Les contextes bornés (i.e. bounded context) correspond un notion qui provient du “Domain-Driven Design” de Eric Evans. Le gros intérêt de cette approche est qu’elle propose une solution pour séparer une application en microservices. Un contexte borné peut correspondre à plusieurs microservices ayant en commun un contexte fonctionnel.
Dans l’approche DDD:
- La complexité fonctionnelle est séparée en contextes bornés: chaque contexte borné répond à un besoin fonctionnel qui possède un langage spécifique, c’est l’ubiquitous language”. Ce langage permet d’avoir une logique spécifique au contexte borné qui ne déborde pas de ce contexte.
- Les frontières du contexte borné sont franchises seulement avec des interfaces: seules les interfaces sont exposées en dehors du contexte borné de façon à volontairement limiter les échanges entre contexte borné à ces interfaces. Cette limitation permet de contrôler et de maitriser les interfaces et donc les échanges.
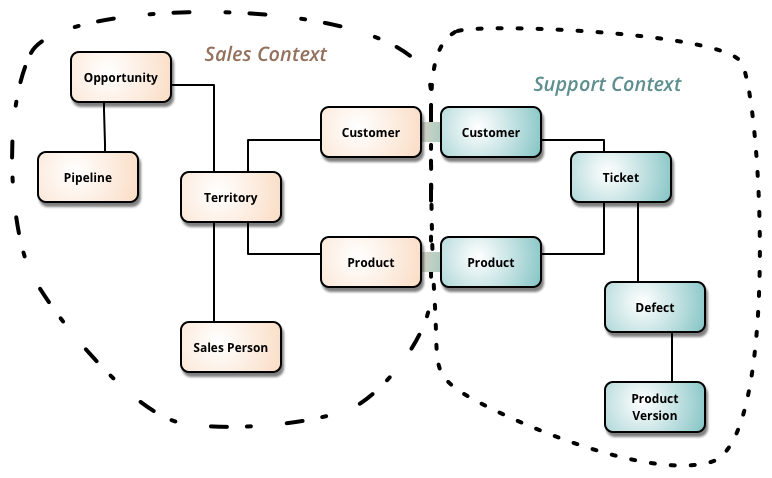
Bounded context
Les contextes bornés donnent une solution efficace pour définir les frontières des différents microservices.
L’approche “Bounded Context” est intéressante pour les microservices car:
- Les échanges sont plus nombreux entre services dans un même même domaine fonctionnel.
- Elle évite d’exposer trop d’interfaces au-delà du domaine.
Ainsi cette approche minimise le couplage entre les contextes bornés et maximise la cohésion à l’intérieur d’un contexte borné.
Découpage en contextes bornés
Le découpage des contextes bornés et plus spécifiquement en microservices n’est pas anodin car il apporte certaines contraintes qui peuvent être plus difficilement surmontables que dans une application en monolithe.
En effet, une fois que le découpage en contextes bornés et en microservices est effectué, il est difficilement réversible. La séparation entre les contextes devient franche, et il sera plus difficile de partager du code entre ces contextes si on s’aperçoit qu’un fonctionnement est proche. De même, si on se rend compte d’une erreur dans le découpage des microservices, le code pourrait être plus difficilement déplaçable d’un service à l’autre.
Casser un monolithe
La plupart du temps, on ne part pas d’un projet “from scratch” et on peut être contraint d’adapter un projet existant. On l’a évoqué plus haut, un intérêt de l’approche en microservices est de permettre à une application d’évoluer en limitant sa complexité. Plus une application en monolithe augmente en taille et plus elle devient complexe. Avec le temps, cette complexité tend à rendre de plus en plus difficile la réalisation de nouvelles fonctionnalités.
Couche anticorruption
La première étape pour aller vers une application en microservices est de tenter d’arrêter de faire grossir l’application en monolithe. On peut, ainsi, tenter de développer des nouvelles fonctionnalités dans un service séparé et protégé par une couche anticorruption (i.e. anticorruption layer).
Cette couche anticorruption a pour but d’éviter de corrompre la partie dans laquelle est implémentée la logique fonctionnelle. La couche métier est la plus importante car c’est elle qui possède la valeur ajoutée de l’application, c’est la partie la plus susceptible d’être conservée si la technologie change. La couche anticorruption vise à servir “d’adaptateurs technologiques” à la couche métier.
Dans l’exemple suivant, l’objectif a été de séparer la couche de présentation “Presentation Layer” de la couche métier. La couche métier accède à la base de données par l’intermédiaire d’une couche “Data Access Layer” qui appartient à la couche anticorruption.
La couche de présentation fait appel à la couche métier pour tous ces traitements, en passant par l’intermédiaire d’appels REST. L’API REST permettant ces appels fait partie aussi de la couche anticorruption.
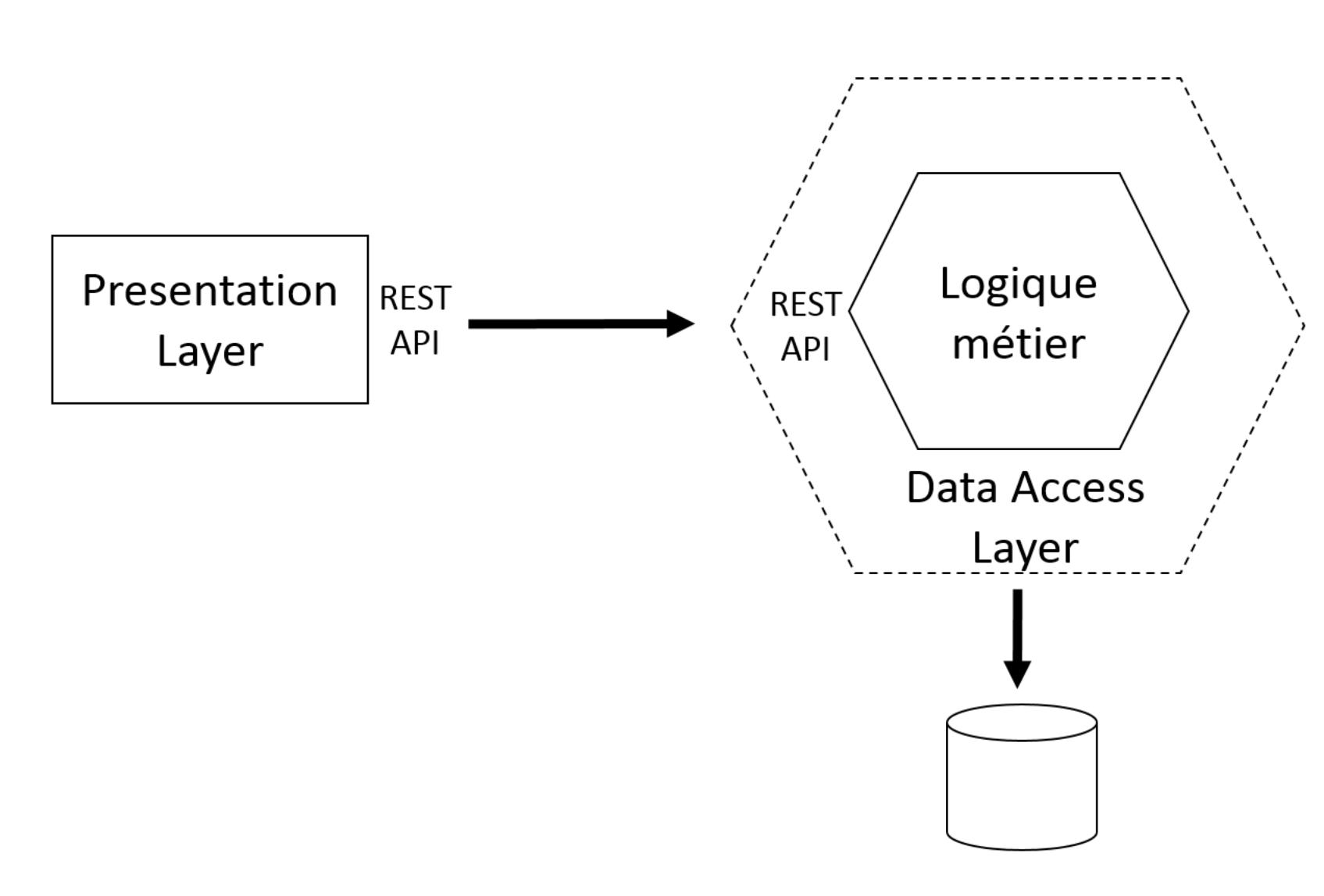
Extraire la logique fonctionnelle
Une fois qu’on a isolé la ou les couches de présentation de la couche métier. On peut tenter, dans un premier temps, de séparer la couche métier en modules. Cette séparation a pour but de préparer une séparation plus franche en contextes bornés. Le but est donc, de considérer ces modules comme s’ils étaient des contextes bornés.
Dans l’exemple suivant, on peut voir qu’un premier travail a consisté à séparer la couche métier en modules plus ou moins autonomes (par exemple, ils ne font pas tous appels à la base de données). Ces modules peuvent, ensuite, plus facilement être séparés de la couche métier pour former un contexte borné plus autonome. Les appels à la couche métier “historique” se fait par l’intermédiaire d’une API REST qui fait partie de la couche anticorruption.
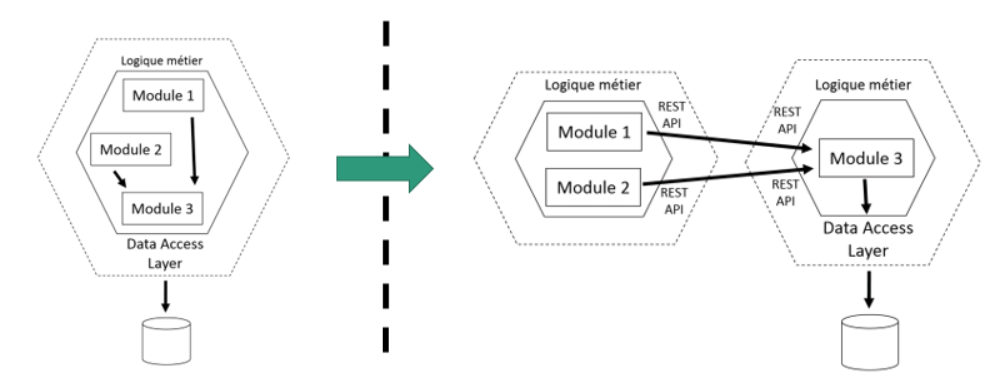
Application de DRY
Lorsqu’on conçoit des microservices, on duplique souvent des traitements d’un service à l’autre. On peut être tenté d’appliquer le principe de programmation DRY pour éviter ces duplications.
De façon à éviter trop de duplications d’un service à l’autre, on peut mutualiser du code dans des bibliothèques techniques et mettre ces bibliothèques à disposition des développeurs des différents services. Ce type de procédé peut avoir quelques conséquences:
- Elle amène les clients des services à s’adapter aux services puisqu’ils passent par l’intermédiaire d’une bibliothèque fournie par le service donné.
- La bibliothèque fournie peut aussi contenir du code fonctionnel.
- Une bibliothèque fournie peut involontairement augmenter le couplage entre des clients et un service car ils doivent utiliser cette bibliothèque pour s’interfacer avec le service.
Ainsi d’une façon générale, utiliser une bibliothèque fournie par les développeurs d’un service est une mauvaise pratique. Il est préférable d’utiliser des bibliothèques techniques générales, si possible, publiques:
- Elles ne doivent pas imposer une technologie spécifique,
- Elles doivent permettre aux clients d’être libre sur leur choix de technologie,
- Elles ne doivent pas contenir d’implémentation fonctionnelle.
Ainsi, l’application de DRY doit se limiter à l’intérieur d’un service et il faut généralement éviter de l’appliquer entre services.
Utiliser une base de données à partir de microservices
Lorsqu’on conçoit plusieurs microservices qui font appels à une base de données, on peut se demander si on doit utiliser une seule base de données qui sera partagée entre tous les microservices ou plutôt avoir une base de données par service.
Avoir une base de données commune est plus rapide à implémenter. D’autre part, les services partageant un même domaine fonctionnel peuvent partager les mêmes tables. Cependant, en cas de modifications de la base pour convenir aux besoins d’un service, on peut impacter tous les services faisant appel à cette base. Avoir une base commune entre services, peut aussi nécessiter des mécanismes de synchronisation des services quand un objet a été mis à jour et qu’il faut le rafraîchir dans les autres services.
D’une façon générale, avoir une base de données commune augmente le couplage entre les services et affecte la cohésion.
Passer d’une base de données commune à une base séparée
Il n’y a pas de recettes miracles car chaque cas de figure est plus ou moins spécifique toutefois on peut tenter de séparer la base de données suivant les services qui l’utilisent:
- Identifier le mapping entre les objets et les tables: de façon à pouvoir isoler chaque table et à les déplacer dans des bases séparées,
- Identifier à quel contexte borné pourrait appartenir une table,
- Casser les clés étrangères entre les tables: casser des clés étrangères rendra le contenu de la base de données moins cohérent. Ainsi, il faut que les futures services soient plus robustes aux incohérences qui pourraient survenir.
- Différencier les données en lecture seule et en lecture/écriture.
De façon générale, tous les services ne font pas appels à toutes les tables:
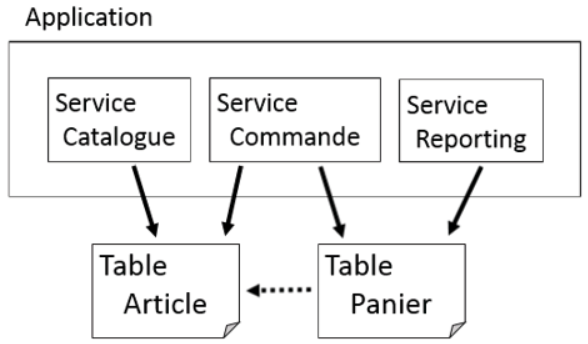
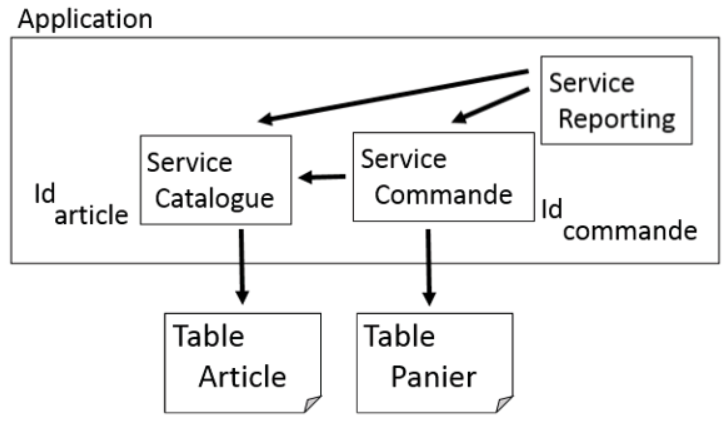
Pour passer à une base séparée, on peut aussi s’aider d’identifiants uniques. Ces identifiants ne sont pas forcément des clés primaires dans les tables. L’intérêt de ces identifiants est que chacun d’entre eux désignent une entité précise. Une entité peut être créée dans un service, toutefois elle peut être identifiée de façon unique grâce à son identifiant et surtout le service peut échanger l’identifiant avec les autres services. Même si la représentation complète d’une entité reste dans un service précis, les autres services peuvent désigner cette entité au moyen de son identifiant.
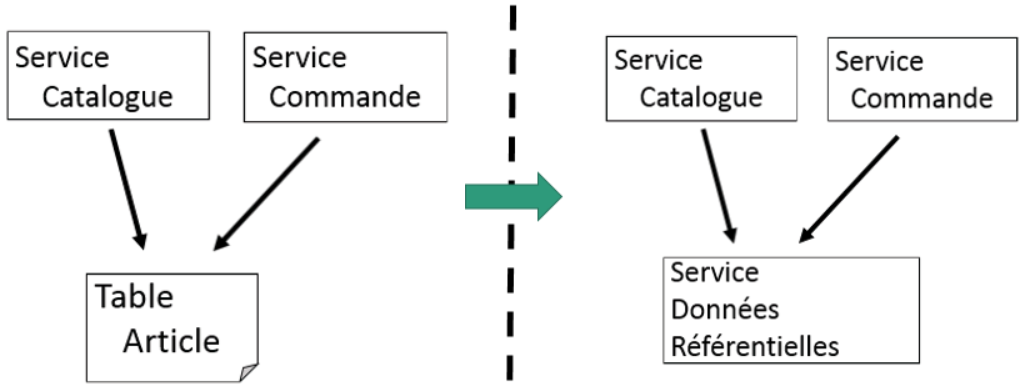
Données statiques partagées
On peut se poser la question de savoir comment traiter le problème des données statiques ou des données référentielles. Ce sont des données qui changent rarement et qui sont consultées, la très grande majorité du temps, en lecture seule. Plusieurs solutions sont possibles:
- Une table en lecture seule: tous les services accèdent à la même table et les accès à cette table sont en lecture seule. Cette solution est facile à implémenter toutefois, les services deviennent dépendants d’une même table. Une modification de la table impacte tous les services.
- Dupliquer les données statiques pour tous les services: sachant que les données statiques changent rarement, on peut les dupliquer sur plusieurs tables. Chaque table étant requêtée par un seul service. Le gros problème de cette solution est la synchronisation entre les tables qui est nécessaire à chaque mise à jour des données. Il faut prévoir un mécanisme de synchronisation si cette solution est adoptée.
- Stocker les données dans le code: cette solution convient dans le cas où les données statiques ne sont pas trop volumineuses et peuvent être stockées dans une assembly. L’intérêt de cette méthode est qu’on peut partager cette assembly et la consommer avec NuGet par exemple. En cas de mise à jour, il suffit de mettre à jour le package NuGet avec la nouvelle assembly.
Utiliser un service “proxy”
Que ce soit pour des données référentielles ou non, une solution peut consister à passer par un service spécialisé pour accéder à des données particulières. Ce service spécialisé accède seule à la table contenant les données. Cet espèce de service “proxy” est l’intermédiaire que doit obligatoirement utiliser les autres services pour accéder à ces données:
Le gros intérêt de cette méthode est que l’accès aux données n’est pas dupliqué sur les autres services. L’accès aux données en lecture et en écriture ne se fait que d’un seul service. Cette organisation n’est pas anodine et peut poser des problèmes en cas d’erreurs. Il faut prendre en compte ces erreurs possibles lors de la conception des services client.
Ainsi en cas d’erreurs dans le cas d’écriture de données en passant par un service “proxy”, il n’y a pas de notion de transactions comme dans le cas d’une base de données relationnelle. Il faut prévoir un comportement si le service “proxy” échoue à écrire le donnée:
- Tolérer les données incohérentes: l’échec dans l’écriture d’une donnée ou l’absence de cette donnée en lecture ne doivent pas déstabiliser le service client. Il faut prendre en compte ces incohérences.
- Essayer plus tard l’insertion d’une donnée: dans le cas d’un échec à l’insertion d’une donnée, on peut envisager un mécanisme de répétition de l’insertion un peu plus tard.
- Vérifier que l’insertion s’est bien passée: pour être sûr de l’insertion de la donnée et de sa persistance, on peut effectuer une requête en lecture auprès du service “proxy” pour vérifier que la donnée a bien été insérée.
- Prévoir les échecs répétés: dans le cas où le service “proxy” échoue à écrire une donnée et que les requêtes en lecture indique les échecs répétées des insertions, il faut prévoir un mécanisme d’abandon et permettre d’annuler complètement l’opération.
- Transaction distribuée: une autre solution peut consister à utiliser des mécanismes de transactions distribuées. Ces mécanismes sont complexes à implémenter notamment dans le cadre de microservices, il est préférable de les éviter.
Accéder à des ressources provenant d’un autre service
D’une façon générale, les accès à des ressources situées dans un autre service doivent respecter certaines précautions car ces appels se font à travers le réseau. Le fait de passer à travers le réseau n’est pas anodin car il peut dégrader les performances dans le cas où il n’est pas rapide, voir il peut mener à des erreurs s’il est en échec.
En outre, des appels à d’autres microservices pour récupérer des données n’est pas aussi simple que de créer un objet lors de l’appel à une fonction dans une même application. Ainsi, il faut:
- Interroger le service contenant la ressource quand on a besoin: ne pas trop anticiper la récupération d’une donnée car entre son accès et son utilisation, la donnée peut avoir changé.
- Eviter de garder un objet provenant d’un autre service trop longtemps en mémoire: pour la même raison que précédemment, si on garde une donnée trop longtemps, on peut en détenir une version obsolète.
- Eviter de récupérer l’intégralité d’une ressource: dans la majorité des cas, une version partielle de la ressource peut suffire. L’intérêt de la version partielle est qu’il est moins couteux de la récupérer par rapport à une ressource complète.
ACID vs BASE
ACID et BASE sont des acronymes utilisés pour indiquer des propriétés s’appliquant à des transactions effectuées sur des base de données. ACID est généralement appliqué aux bases de données relationnelles:
- Atomicité (atomicity): chaque opération sur la base de données doit être atomique même si elle est formée de plusieurs petites opérations. Du point de vue de l’application qui effectue la requête, l’opération doit être annulée complètement si une petite opération a échoué.
- Cohérence (consistency): cette propriété indique que toutes les transactions possibles provoquant un changement à la base de données doivent la laisser dans un état valide.
- Isolation: les requêtes vers la base doivent être isolées c’est-à-dire qu’une application qui effectue une requête ne doit pas se rendre compte que d’autres applications effectuent des requêtes au même moment.
- Durabilité (durability): les changements effectués sur la base de données dans le cas où ils sont confirmés doivent être permanent. Par exemple, une insertion d’une donnée doit être permanente si elle a été exécutée et confirmée.
Dans le cadre du théorème CAP énoncé par Eric Brewer, il n’est pas possible d’appliquer rigoureusement ACID dans le cas d’un système distribué:
“Un système distribué ne peut garantir que 2 des contraintes suivantes à la fois:
- Cohérence (consistency),
- Disponibilité (availability),
- Tolérance au partionnement (partition tolerance).”
La propriété de disponibilité indique que toutes les requêtes doivent recevoir une réponse sans garantie que cette réponse contient l’écriture la plus récente.
La tolérance au partitionnement doit permettre à un système distribué de continuer à fonctionner même si quelques messages entre les nœuds du système ont été perdus à travers le réseau.
A cause du théorème CAP, les transactions dans les systèmes distribués tentent de respecter les propriétés BASE:
- Basically Available: cette contrainte indique qu’un système doit garantir la disponibilité au sens du théorème CAP. Il doit toujours avoir une réponse à une requête, toutefois la réponse pourrait être un échec ou la réponse pourrait être incohérente.
- Soft State: l’état du système peut changer au cours du temps même dans le cas où des données ne sont pas insérées. L’état du système peut être amené à changer pour garantir “éventuellement la cohérence”.
- Eventually consistency: le système peut éventuellement être cohérent quand il n’y a pas de données insérées. Quand des données sont insérées, le temps de les propager, le système ne vérifie pas la cohérence de toutes les transactions.
Les propriétés BASE sont moins contraignantes que les propriétés ACID. Le fait de pouvoir relâcher quelques contraintes permet d’être plus adapté dans le cadre de système distribué et, par suite, dans le cas de l’architecture en microservices. Il faut donc concevoir des microservices en essayant de suivre une approche BASE plutôt qu’ACID.
Partie 1: Concevoir des microservices
Partie 2: Appels entre microservices