Parfois quand on veut effectuer un traitement particulier, utiliser un middleware propriétaire ou simplement utiliser une bibliothèque tiers, on ne dispose pas forcément d’assembly .NET permettant d’effectuer ce traitement et il peut être nécessaire d’effectuer des appels à une bibliothèque codée en C++. Cette bibliothèque native peut être livrée sous forme d’une bibliothèque statique (fichier .lib) ou d’une bibliothèque dynamique (fichier .dll). Effectuer ce type d’intéropérabilité n’est pas forcément trivial pour beaucoup de développeurs. Le but de cet article est ainsi d’expliquer 2 techniques pour appeler du code se trouvant dans des bibliothèques C++ à partir de code .NET. Les 2 techniques que l’on va expliciter ne sont pas strictement équivalentes:
- Platform/Invoke: cette technique permet d’appeler des bibliothèques dynamiques assez facilement à condition que la DLL expose les méthodes qu’on souhaite appeler. Dans le cas où on ne maitrise pas l’implémentation de la bibliothèque et qu’on n’est pas en mesure d’exposer les méthodes à appeler, cette méthode peut être impossible à mettre en œuvre.
- C++/CLI (CLI pour Common Language Infrastructure): il s’agit d’un langage capable de générer des assemblies contenant du code managé et du code natif. Le gros intérêt de ce langage est de pouvoir être appeler par du code managé et de pouvoir appeler du code natif. Il fait ainsi office de wrapper pour s’interfacer avec une bibliothèque statique ou une bibliothèque dynamique codée en C++.

D’abord, on va apporter quelques explications en préambule pour aider à comprendre le reste de l’article. Ensuite, on va expliciter ces 2 techniques avec un exemple simple de code .NET appelant du code C++.
Quelques explications en préambule
Encodage
char vs wchar_t
Installation Visual Studio
Platform/Invoke
Effectuer un appel P/Invoke
Exemple d’appel
Création de la bibliothèque dynamique NativeCallee
Création de l’exécutable NativeCodeCaller
Chaîne de caractères contenant des caractères Unicode
Retour de chaînes de caractères
C++/CLI
Conversion de NativeCallee en bibliothèque statique
Création de l’assembly mixte MixedAssembly
Quelques explications en préambule
Avant de rentrer dans le détail du code, quelques explications peuvent aider à la compréhension d’éléments d’implémentation dans le code de cet article. Si vous êtes familier avec ces notions, passer directement à la partie suivante.
Bibliothèque statique vs bibliothèque dynamique
On avait eu l’occasion d’expliciter les différences principales entre une bibliothèque dynamique et une bibliothèque statique dans un article précédent.
Encodage
Un problème récurrent qui peut subvenir lorsqu’on manipule des chaînes de caractères en C++ concerne l’encodage des caractères de la chaîne. Voici quelques indications générales sur l’encodage (le terme “code point” correspond au code utilisé pour encoder un caractère) :
- ASCII (American Standard Code for Information Interchange): chaque caractère ASCII nécessite 1 octet (i.e. byte) en mémoire. 1 octet permet d’encoder 256 code points car 1 octet correspond à 8 bits soit 28=256 possibilités. Toutefois les 256 code points ne sont pas tous utilisés en ASCII, seulement les 128 premiers code points. Ces 128 premiers code points correspondent aux caractères usuels de la langue anglaise (sans accents) et quelques caractères spéciaux (cf. ASCII Table).
- Codepage: l’ASCII ne tient pas compte des spécificités régionales. Par exemple, il n’y a aucun caractère spécial pour le français (comme é, à, ç, è, etc…). Pour prendre en compte les caractères correspondant aux spécificités régionales, la 2e moitié des 128 code points sont utilisés sur les 256 possibilités de l’ASCII. Cet encodage nécessite donc toujours 1 octet. Chaque encodage est très spécifique à la région, il faut donc autant d’encodages “codepage” que de langues ou de régions. D’autre part, pour pouvoir lire un fichier écrit avec un encodage particulier, il faut connaître cet encodage au préalable pour pouvoir le lire.
- ANSI (American National Standards Institute): cet encodage correspond à la codepage 1252 ou “Latin-1 Windows”. Il est composé des caractères de l’ASCII sur les 128 premiers code points puis des caractères usuels pour les langues d’Europe de l’Ouest pour les 128 code points suivants (cf. ANSI table).
- USC-2: cet encodage correspond à une extension de l’ASCII pour prendre en compte plus de code points. Il nécessite 2 octets par code points et permet d’encoder 65535 caractères.
- UTF-16 (“Unicode”): cet encodage correspond à une volonté de rendre les encodages universels c’est-à-dire pour qu’un encodage permette de prendre en compte la plupart des caractères. Dans un premier temps, il nécessitait 2 octets et était identique à l’USC-2. Il n’est pas compatible avec l’ASCII c’est-à-dire que des programmes ne lisant que l’ASCII ne pourront pas lire un fichier codé en UTF-16 toutefois les 128 premiers code points sont identiques à l’ASCII si on ne considère qu’un seul octet. Assez vite UTF-16 s’est révélé insuffisant pour encoder tous les caractères, on a donc décidé de rajouter une paire de 2 octets pour avoir 4 octets. Chaque code points est donc formé de 2 mots de 16 bits chacun. Le code point de chaque caractère peut alors être formé sur 2 ou 4 octets soit un ou 2 mots. Malheureusement cet encodage ne fixe pas d’ordre pour ces 2 mots, il faut donc convenir de l’ordre des mots pour savoir quel est le mot de poids fort et celui de poids faible.
- Big Endian (BE): cet encodage correspond à l’octet de poids fort en premier.
- Little Endian (LE): cet encodage correspond à l’octet de poids faible en premier.
- UTF-32: cet encodage nécessite 4 octets de façon fixe. UTF-32 est une implémentation de USC-4. Pas de nécessité de convenir de l’ordre des octets comme UTF-16 car l’encodage fixe un ordre précis. Cet encodage est rarement utilisé car très volumineux.
- UTF-8: cet encodage est aussi universel et chaque caractère possède un code point particulier. Contrairement à UTF-32, les code points ne nécessitent pas un nombre fixe d’octets. Les code points peuvent nécessiter 1, 2, 3 ou 4 octets. Il est compatible avec l’ASCII c’est-à-dire que si un texte est encodé en UTF-8 et ne comporte que des caractères ASCII, les code points seront les mêmes que si le texte était encodé en ASCII (cf. Unicode Character Code Charts).
UTF-8 est beaucoup utilisé pour le web à cause du nombre d’octets variable ce qui permet d’économiser de la mémoire pour les langues occidentales. Toutefois il est défavorable par rapport à l’UTF-16 pour les langues asiatiques.
UTF-8 est utilisé par les systèmes d’exploitation Linux et UTF-16 est utilisé pour Windows.
Pour plus de détails sur Unicode, voir Unicode en 5 min.
char vs wchar_t
En C/C++, on peut stocker des chaînes de caractères dans des tableaux d’objets de type char. La chaîne est alors accessible par un objet de type char* pointant vers ce tableau. L’encodage des caractères de cette liste peuvent varier en fonction du système d’exploitation, par exemple:
- Sur un système Linux qui gère les chaînes de caractères nativement en utilisant UTF-8,
char*permet de stocker des caractères codés en UTF-8. - Sur Windows,
char*permet de stocker des chaînes avec des caractères encodés en ASCII avec des spécificités régionales correspondant à celles indiquées dans les paramètres du système d’exploitation.
Dans le même sens, wchar_t permet de stocker des caractères nécessitant un espace de stockage “large” (i.e. wide). Il n’y a pas de définition universelle de ce qu’est un espace de stockage “large”. Cet espace dépend du compilateur et du système d’exploitation. Par exemple:
- Sur un système Linux,
wchar_tpermet de stocker des caractères encodés en UTF-32 sur 4 octets. - Sur Windows,
wchar_tpermet de stocker des caractères encodés en USC-2 ou UTF-16.
Dans le code, l’initialisation de ces chaînes peut varier en fonction de l’encodage utilisé. Ainsi sur Windows:
- Pour une chaîne contenant des caractères ASCII ou ANSI:
const char *s0 = "hello"; - Pour une chaîne contenant des caractères UTF-8:
const char *s1 = u8"hello"; - Pour une chaîne contenant des caractères UTF-16:
const wchat_t *s2 = u"hello"; - Pour une chaîne contenant des caractères UTF-32:
const wchat_t *s3 = U"hello"; - Pour une chaîne contenant des caractères “larges” c’est-à-dire USC-2 ou UTF-16:
const wchar_t *s4 = L"hello";
Pour plus d’informations, voir String and Character Literals (C++).
Installation Visual Studio
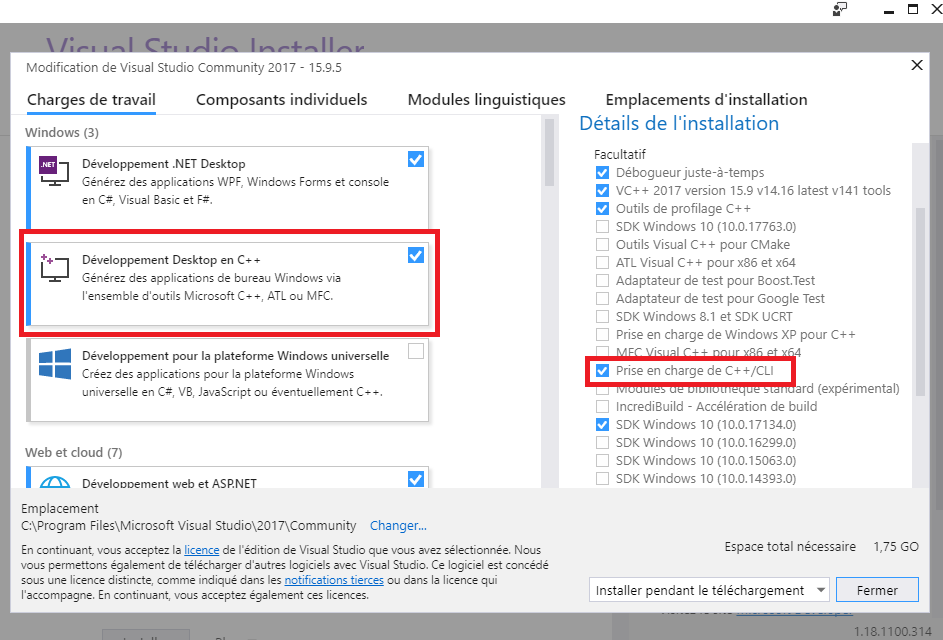
Pour réaliser les différentes parties de cet article, il faut s’assurer que le support C++ est bien
installé dans Visual Studio. En exécutant l’installateur de Visual Studio 2017, il faut que “Développement Desktop en C++” et que “Prise en charge C++/CLI” soient cochés:
Platform/Invoke
Comme indiqué en introduction, P/Invoke (i.e. Platform Invoke) est une technique qui permet d’appeler du code non managé à partir de code managé. L’utilisation de P/Invoke convient lorsque:
- du code non managé existe,
- qu’il est trop couteux de le migrer,si on doit utiliser une API non managé et qu’il n’existe pas de version .NET équivalent de cette API,
- si on doit faire appel à des fonctions de l’API Win32.
Le gros inconvénient de P/Invoke est qu’il faut parfois adapter le code à appeler pour utiliser cette technique. Ensuite, les interfaces entre le code managé et le code non managé doivent être définis et implémentées avec soin de façon à éviter les erreurs mais aussi de mauvaises performances
lors de la “conversion” des objets managés en objets non managés et inversement.
En effet, lorsqu’on utilise P/Invoke pour appeler du code non managé, il faut être rigoureux dans le choix du type des objets et dans la façon dont ils sont passés en paramètre. Pour effectuer ces choix, il faut avoir en tête:
- le fonctionnement du code de “conversion” managé vers non managé suivant le type d’objet,
- certains mécanismes comme celui du Garbage Collector ou
- les conventions d’appels de fonctions.
Effectuer un appel P/Invoke
Pour appeler le code se trouvant dans une bibliothèque dynamique il faut utiliser l’attribut DllImport. Toutefois pour que cette méthode soit utilisable, il faut que les fonctions appelées dans la bibliothèque native soit exposée. En effet comme on l’a indiqué en préambule, une bibliothèque dynamique contient du code machine qui peut être directement chargé et exécuté en mémoire. Toutefois les DLL sur Windows n’exposent pas par défaut le code qu’elles contiennent. Ça veut dire que si on souhaite utiliser une DLL et qu’on fait référence à une fonction dans cette DLL, par défaut on ne peut pas connaître l’adresse à laquelle se trouve le code machine correspondant à la fonction dans la DLL.
Pour indiquer l’adresse à laquelle se trouve le code correspondant à une fonction dans une DLL, il faut l’exposer explicitement. Dans un précédent article, on a indiqué une méthode pour permettre d’exposer du code se trouvant dans une bibliothèque dynamique (cf. Référencer une DLL C++ avec une bibliothèque statique d’import).
La technique Platform/Invoke consiste à:
- déclarer dans le code C# la signature d’une fonction à appeler dans une DLL et qui est exposée.
- ajouter dans la déclaration de cette fonction l’attribut
DllImportavec le nom de la DLL pour que le compilateur C# puisse implémenter l’appel P/Invoke. - indiquer des éléments qui peuvent aider le CLR à effectuer l’appel dans la DLL comme la convention d’appels, le nom de la méthode si celui-ci diffère de celui de la signature.
- indiquer dans la signature des indications pour aider à effectuer les “conversions” de type des paramètres en entrée ou en sortie de la fonction.
Pendant l’exécution et lorsque la fonction est appelée dans le code C#, le CLR va utiliser les indications de la déclaration avec l’attribut DllImport pour indiquer au runtime C++ comment effectuer l’appel au code dans la DLL. Le runtime va charger la DLL en mémoire et exécuter le code correspondant. Le passage des objets en paramètres de la fonction peut se faire de différentes façons suivant le type de l’objet:
- l’objet peut être “marshallé” c’est-a-dire qu’une conversion est faite entre le code managé exécuté par le CLR et le code non managé exécuté par le runtime C++. Cette conversion essaie de copier le contenu de l’objet de façon à ce qu’il soit le plus fidèle au contenu d’origine. D’autre part, la conversion implique que 2 versions de l’objet sont présents en mémoire: une version dans le code managé et une version dans le code non managé.
- quand le type le permet, les objets peuvent ne pas être “marshallé” et la même instance de l’objet en mémoire peut être utilisée à la fois dans le code managé et dans le code non managé. Sachant que l’appel se fait à partir du code managé, c’est le CLR qui instancie l’objet en mémoire. Pour éviter que l’objet ne soit déplacé par le Garbage Collector pendant l’appel au code non managé, il est épinglé en mémoire (i.e. le terme utilisé est pinned). Quand l’appel est effectué c’est le pointeur qui est transmis au code non managé. Quand l’appel est terminé, l’objet n’est plus épinglé pour que le Garbage Collector puisse éventuellement le collecter. Pendant l’appel, le code non managé est capable de modifier l’objet ce qui peut éventuellement mener à des erreurs s’il supprime l’objet par exemple.
Pour davantage d’information concernant P/Invoke voir l’article Platform invoke en 5 min.
Exemple d’appel
L’exemple présenté permet d’appeler du code se trouvant dans une bibliothèque dynamique appelée NativeCallee. Cet appel se fait à partir d’une assembly .NET appelée NativeCodeCaller.
Les appels se feront de cette façon: NativeCodeCaller ⇒ NativeCallee
Création de la bibliothèque dynamique NativeCallee
On va créer un projet C++ vide en cliquant sur les éléments suivants dans Visual Studio 2017:
- Créer un projet C++ vide en cliquant sur “Nouveau” ⇒ “Projet” ⇒ Dans “Visual C++”, cliquer sur “Projet vide” (“Empty project“).
Il faut nommer le projetNativeCallee. - Ajouter un classe en effectuant un clique droit sur le projet puis cliquer sur “Ajouter…” et enfin cliquer sur “Classe”.
Il faut nommer la classeNativeCallee. - Implémentation de
NativeCallee.h: insérer ce code dans le fichierNativeCallee.h:#ifndef NATIVECALLEE_H #define NATIVECALLEE_H #pragma once #ifdef NATIVECALLEE_EXPORTS #define NATIVECALLEE_API __declspec(dllexport) #else #define NATIVECALLEE_API __declspec(dllimport) #endif extern "C" NATIVECALLEE_API void DisplayTextWithCallee(const wchar_t *textToDisplay); class NativeCallee { private: wchar_t *textToDisplay; public: NativeCallee(wchar_t *textToDisplay); ~NativeCallee(); void DisplayText(); }; #endif /* NATIVECALLEE_H */ - Implémentation de
NativeCallee.cpp: insérer ce code dans le fichierNativeCallee.cpp:#include "NativeCallee.h" #include <wchar.h> void DisplayTextWithCallee(const wchar_t *textToDisplay) { NativeCallee *callee = new NativeCallee(const_cast<wchar_t*>(textToDisplay)); callee->DisplayText(); delete callee; } NativeCallee::NativeCallee(wchar_t *textToDisplay) { this->textToDisplay = textToDisplay; } NativeCallee::~NativeCallee() { } void NativeCallee::DisplayText() { wprintf(L"Displaying from unmanaged code: %s\n", this->textToDisplay); }Ce code permet:
- d’instancier une classe avec une chaîne de caractères,
- d’afficher cette chaîne de caractères avec la méthode
NativeCallee::DisplayText(), - d’exposer la méthode
DisplayTextWithCallee()dans la DLL avec la directive préprocesseurNATIVECALLEE_EXPORTS.
Pour plus de détails, voir l’article Référencer une DLL C++ avec une bibliothèque statique d’import.
- Configurer les propriétés du projet
NativeCallee:
Effectuer un clique droit sur le projetNativeCalleepuis cliquer sur “Propriétés”:- Dans la partie “Général”, sélectionner les éléments suivants:
- “Type de configuration” (“Configuration type“): “Bibliothèque dynamique (.dll)” (“Dynamic Library“).
- “Jeu de caractères” (“Character set“): “Utiliser le jeu de caractères Unicode” (“Use Unicode Character set“).
- “Prise en charge du Common Language Runtime” (“Common Language Runtime Support“): “Pas de prise en charge du Common Language” (“No Common Language Runtime Support“).
- Dans la partie “C/C++” ⇒ “Préprocesseur”, on indique la valeur suivante pour le paramètre “Définitions de préprocesseur” (“Preprocessor definitions
“):NATIVECALLEE_EXPORTS - Dans la partie “C/C++” ⇒ “Avancé”, on indique la convention d’appels (“call convention“) “__stdcall (/Gz)”
Ne pas oublier de valider en cliquant sur “Appliquer”.
- Dans la partie “Général”, sélectionner les éléments suivants:
On doit être capable de compiler le projet. Dans le répertoire Debug, le fichier NativeCallee.dll devrait être présent.
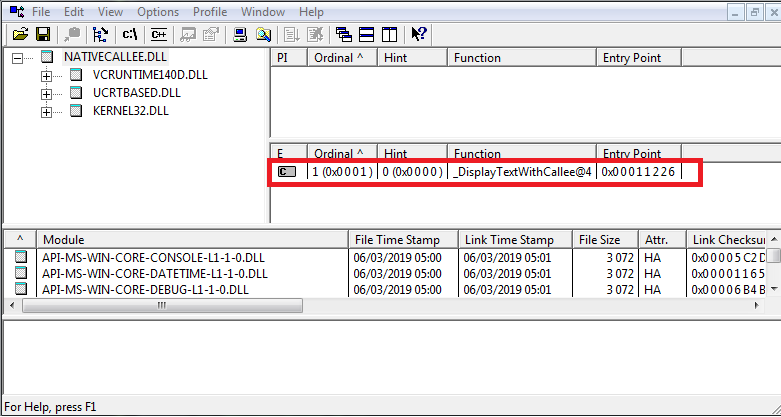
La fonction exportée doit être visible en inspectant la DLL NativeCallee.dll avec DependancyWalker.
“DependancyWalker” peut être téléchargé sur www.dependencywalker.com/.
Création de l’exécutable NativeCodeCaller
On va créer l’exécutable .NET qui va effectuer l’appel vers la DLL native.
- Créer une application Console .NET en effectuant un clique droit sur la solution ⇒ cliquer sur “Ajouter” ⇒ “Nouveau projet” ⇒ Dans la partie “Visual C#”, sélectionner “Application Console” (“.NET Framework”).
Il faut nommer le projet
NativeCodeCaller. - Dans le fichier
Program.cs, (contenant lemainde l’application), il faut indiquer l’implémentation suivante:using System; using System.Runtime.InteropServices; namespace NativeCodeCaller { class Program { static void Main(string[] args) { string textToDisplay = "text to display"; Console.WriteLine($"Displaying from managed code: {textToDisplay}"); DllImportExample.DisplayTextWithCallee(textToDisplay); Console.ReadLine(); } } public class DllImportExample { [DllImport("NativeCallee.dll", CallingConvention = CallingConvention.StdCall, CharSet = CharSet.Unicode)] public extern static void DisplayTextWithCallee(string textToDisplay); } }
Si on compile à ce stade, la compilation va réussir mais la DLL NativeCallee.dll ne se trouve pas dans le répertoire de sortie de l’exécutable donc l’exécution va échouer car NativeCallee.dll se sera pas trouvée.
On va donc copier NativeCallee.dll dans le répertoire de sortie de l’exécutable NativeCodeCaller:
- Il faut changer les dépendances des projets en effectuant un clique droit sur la solution puis en cliquant sur “Dépendances du projet…” (“Project dependencies“); sélectionner “NativeCodeCaller” et cocher
NativeCallee.
Cliquer sur OK pour valider. - On rajoute un évènement post-build à l’exécutable pour effectuer la copie:
- Accèder aux propriétés du projet
NativeCodeCalleren effectuant un clique droit sur le projet
Dans l’onglet “Evènements de build” (“Build events“) et dans la partie “Ligne de commande de l’évènement post-build” (“Post-build event command line“), ajouter la ligne suivante:xcopy $(SolutionDir)$(ConfigurationName)\NativeCallee.dll $(TargetDir) /Y - Puis sélectionner pour le paramètre “Exécuter l’évènement post-build” (“Run the post-build event“): “Toujours” (“Always“).
- Accèder aux propriétés du projet
- Recompiler la solution en cliquant sur “Régénérer la solution” (“Rebuild solution“). Après compilation, la DLL
NativeCallee.dlldoit se trouver dans le répertoire de sortie de l’exécutableNativeCodeCaller.
Pour exécuter, il faut indiquer que le projet de démarrage est NativeCodeCaller en effectuant un clique droit sur ce projet puis en cliquant sur “Définir comme projet de démarrage” (“Set as Startup project“).
Le résultat de l’exécutable est du type:
Displaying from managed code: text to display Displaying from unmanaged code: text to Display
Chaîne de caractères contenant des caractères Unicode
Si on modifie la chaîne de caractères à afficher en utilisant quelques caractères spéciaux, par exemple en modifiant la chaîne de caractères dans le fichier Program.cs du projet NativeCodeCaller:
string textToDisplay = "text to display éèà";
Si on regénère la solution et si on relance l’exécution, on constate que l’affichage n’est pas le même en C++:
Displaying from managed code: text to display éèà Displaying from unmanaged code: text to display ÚÞÓ
Malgré l’utilisation dans l’attribut DllImport du paramètre CharSet.Unicode, les caractères spéciaux ne sont pas visibles en C++:
[DllImport("NativeCallee.dll", CallingConvention = CallingConvention.StdCall,
CharSet = CharSet.Unicode)]
Dans le code C#, les chaînes de caractères sont encodées en Unicode. Lorsque la chaîne est passée au code C++, elle est convertie en chaîne dont les caractères sont de type wchar_t. En Windows, les caractères de ce type sont aussi encodés en Unicode alors pourquoi la chaîne n’est pas affichée correctement ? Le problème provient de la fonction wprintf car, par défaut, elle considère que le flux de sortie est en mode ANSI. Ainsi les caractères suivant le code point 128 dans l’encodage ANSI correspondent aux caractères au codepage “Latin-1 Windows” qui sont différents des caractères Unicode.
Une solution est de changer le mode du flux de sortie pour qu’il affiche les caractères en Unicode. On peut effectuer ce changement en modifiant le code de la fonction NativeCallee::DisplayText() dans le projet NativeCallee:
#include <wchar.h>
#include <iostream>
#include <Windows.h>
#include <io.h>
#include <fcntl.h>
// ...
void NativeCallee::DisplayText()
{
_setmode(_fileno(stdout), _O_U16TEXT);
wprintf(L"Displaying from unmanaged code: %s\n", this->textToDisplay);
}
En recompilant et en exécutant, l’affichage est de nouveau correct:
Displaying from managed code: text to display éèà Displaying from unmanaged code: text to display éèà
Retour de chaînes de caractères
Les retours d’appels P/Invoke sous forme de chaînes de caractères nécessitent quelques précautions car ils peuvent faire l’objet de fuites mémoires. Voici 2 possibilités pour récupérer un résultat sous forme de chaîne de caractères:
- 1ère possibilité: retourner directement une chaîne de caractères après l’appel.
Cette méthode n’est pas très sûre car elle nécessite de créer la chaîne de caractères dans le code non managée. L’objet sera donc créé en mémoire dans le tas. A la fin de l’appel, pour que l’objet puisse être converti dans une chaîne .NET il ne faut pas le détruire ce qui entraîne qu’il n’est jamais libéré du tas d’où la fuite mémoire. - 2e possibilité: créer la chaîne à retourner en C#.
On crée l’objet dans le tas managé en C# sous forme de chaîne de caractères de typechar*avec le paramètreunsafepour qu’elle soit accessible sous forme d’un tableau de caractères; on épingle cet objet le temps de l’appel pour qu’il ne soit pas déplacé par le Garbage Collector. On effectue l’appel P/Invoke en utilisant le pointeur de la chaîne. Cette chaîne ne sera pas “marshallée” et sera utilisée de la sorte par le code non managé. Le code C++ peut ainsi écrire dans la chaîne pour indiquer une valeur en retour.
Le code C# peut ainsi récupérer la valeur de la chaîne en utilisant le pointeur puis ensuite libérer lui-même la chaîne, évitant ainsi une fuite mémoire.
Les gros inconvénients de la 2e méthode sont:
- qu’il faut connaître la longueur de la chaîne pour pouvoir la créer en C# au préalable.
- qu’il faut exécuter du code “unsafe” en C# à cause de l’utilisation de pointeurs.
Pour illustrer, on va compléter l’exemple en retournant une copie de la chaîne fournie en paramètre.
On ajoute la méthode suivante dans le fichier NativeCallee.cpp dans le projet NativeCallee:
void DisplayTextWithCalleeAndReturnCopy(const wchar_t *textToDisplay,
wchar_t *const returnedString)
{
NativeCallee *callee = new NativeCallee(const_cast<wchar_t*>(textToDisplay));
callee->DisplayText();
delete callee;
size_t stringLength = wcslen(textToDisplay);
wcscpy_s(returnedString, stringLength + 1, textToDisplay);
}
Cette méthode effectue le même traitement que DisplayTextWithCallee() puis effectue une copie de la chaîne de caractère textToDisplay vers la chaîne returnedString qui a déjà été créée.
Il faut exposer cette méthode dans la DLL en ajoutant dans NativeCallee.h la déclaration:
extern "C" NATIVECALLEE_API void DisplayTextWithCalleeAndReturnCopy(const wchar_t *textToDisplay, wchar_t *const returnedString);
Dans le fichier Program.cs du projet NativeCodeCaller, on modifie la classe DllImportExample en ajoutant la déclaration suivante:
public class DllImportExample
{
// ...
[DllImport("NativeCallee.dll", CallingConvention = CallingConvention.StdCall,
CharSet = harSet.Unicode)]
public extern static void DisplayTextWithCalleeAndReturnCopy(string textToDisplay,
IntPtr returnedString);
}
On modifie le main pour effectuer l’appel de cette façon:
static void Main(string[] args)
{
string textToDisplay = "text to display éèà";
Console.WriteLine($"Displaying from managed code: {textToDisplay}");
string returnedString = string.Empty;
unsafe
{
fixed (char* unmanagedString = new char[textToDisplay.Length + 1])
{
IntPtr unmanagedStringPtr = (IntPtr)unmanagedString;
DllImportExample.DisplayTextWithCalleeAndReturnCopy(textToDisplay,
unmanagedStringPtr);
returnedString = Marshal.PtrToStringUni(unmanagedStringPtr);
}
}
Console.WriteLine($"Returned string: {returnedString}");
Console.ReadLine();
}
Dans le code d’appel:
- On utilise un bloc de code “unsafe” car on effectue des manipulations de pointeurs.
- On crée ensuite une chaîne de caractères avec une longueur correspondant à la taille de la chaîne d’origine avec le caractère de terminaison.
- On utilise le mot-clé
fixedpour fixer la chaîne allouée sur le tas managé pour éviter qu’elle ne soit déplacée par le Garbage Collector. - On récupère le pointeur de la chaîne de caractères.
- On effectue l’appel P/Invoke.
- A partir du pointeur, on effectue une conversion vers une nouvelle chaîne managée.
Pour que ce code compile, il faut autoriser l’utilisation de blocs “unsafe” dans les propriétés du projet NativeCodeCaller:
Effectuer un clique droit sur le projet NativeCodeCaller puis cliquer sur “Propriétés”; dans l’onglet “Build”, il faut cocher “Autoriser les blocs de code unsafe” (“Allow unsafe code“).
Après compilation, le résultat de l’exécution est de type:
Displaying from managed code: text to display éèà Displaying from unmanaged code: text to display éèà Returned string: text to display éèà
On peut utiliser un bloc de code légèrement différent: au lieu d’allouer la chaîne de caractères sur le tas, on peut l’affecter sur la pile puisque la pile n’est pas géré par le Garbage Collector. L’objet est supprimé de la pile à la sortie de la fonction. On évite, ainsi d’avoir à épingler la chaîne avec fixed.
Pour allouer la chaîne sur la pile, on utilise le mot-clé stackalloc:
unsafe
{
char* unmanagedString = stackalloc char[textToDisplay.Length + 1];
IntPtr unmanagedStringPtr = (IntPtr)unmanagedString;
DllImportExample.DisplayTextWithCalleeAndReturnCopy(textToDisplay,
unmanagedStringPtr);
returnedString = Marshal.PtrToStringUni(unmanagedStringPtr);
}
Comme on peut le voir, pour utiliser cette méthode, il faut connaître la taille de la chaîne de caractères pour la créer au préalable ce qui peut être très contraignant.
Le code de cette partie se trouve dans la branche platform_invoke du repository GitHub github.com/msoft/CallUnmanagedDll.
C++/CLI
Le C++/CLI (CLI pour Common Language Infrastructure) est une technologie Microsoft qui permet de manipuler et d’appeler du code natif en C ou en C++ à partir de code managé .NET. Il s’agit d’un langage qui mélange C++ et technologie .NET.
Les principaux avantages de ce langage sont:
- Permet d’encapsuler du code C++ natif de façon à éviter d’effectuer trop d’appels nécessitant du “marshalling”.
- Quand des opérations de “marshalling” sont effectuées, la plupart du temps le langage le fait de façon implicite sans qu’il soit nécessaire de préciser des paramètres supplémentaires.
- Le C++/CLI est plus flexible que la technologie P/Invoke car il est possible de consommer des bibliothèques statiques.
- On peut débugguer le code C++/CLI et le code C++ qui est appelé.
Pour avoir davantage d’information sur le C++/CLI, voir l’article C++/CLI en 10 min.
Pour illustrer, on se propose de compléter l’exemple précédent en ajoutant une assembly mixte contenant du code C++/CLI. Cette assembly fera l’intermédiaire entre l’assembly managée et la DLL native. On appellera cette assembly MixedAssembly. Les appels se feront, ainsi, de cette façon:
NativeCodeCaller ⇒ MixedAssembly ⇒ NativeCallee.
Conversion de NativeCallee en bibliothèque statique
Dans un premier temps, on va convertir la bibliothèque dynamique NativeCallee en bibliothèque statique:
- Il faut accéder aux propriétés du projet en effectuant un clique droit sur le projet
NativeCalleepuis en cliquant sur “Propriétés”.
Dans “Général”, il faut sélectionner le paramètre suivant:
“Type de configuration” (“Configuration Type“): “Bibliothèque statique (.lib)” (“Static Library“)
Valider en cliquant sur OK. - On va ensuite supprimer la copie de la DLL
NativeCallee.dlldans le répertoire de sortie du projetNativeCodeCaller.
Il faut accéder aux propriétés du projetNativeCodeCaller, dans l’onglet “Evènement de build”, il faut supprimer le contenu de “Ligne de commande de l’évènement post-build”.
Création de l’assembly mixte MixedAssembly
Pour créer une assembly mixte, il suffit de créer une bibliothèque de classes C++ classique:
- Créer un projet C++ vide en cliquant sur “Nouveau” ⇒ “Projet” ⇒ Dans “Visual C++”, cliquer sur “Projet vide” (“Empty project”).
Il faut nommer le projet
MixedAssembly. - On ajoute une classe en effectuant un clique droit sur le projet
MixedAssembly⇒ Ajouter ⇒ class…
On nomme la classeNativeCaller. - On modifie les propriétés du projet pour générer une assembly mixte:
En effectuant un clique droit sur le projetMixedAssemblypuis en cliquant sur “Propriétés”, il faut indiquer les paramètres suivants:- Dans Général:
“Type de configuration“: “Bibliothèque dynamique (.dll)” (“Dynamic Library“).
“Jeu de caractères” (“Character set“): “Utiliser le jeu de caractères Unicode” (“Use Unicode Character set“).
“Prise en charge du Common Language Runtime“: “Prise en charge du Common Language Runtime (/clr)” - Dans C/C++ ⇒ Général :
On indique le répertoire des fichiers.hdu projetNativeCallee:
“Autres répertoires Include” (“Include directories“):..\NativeCallee - Dans C/C++ ⇒ Avancé :
On indique le paramètre:
“Convention d’appel” (“Call convention“):__stdcall (/Gz) - On indique la bibliothèque statique dans les dépendances en allant dans:
“Editeur de liens” (“Linker“) ⇒ “entrée” (“Input“):..\Debug\NativeCallee.lib
On valide en cliquant sur OK.
- Dans Général:
- On précise l’implémentation de la classe
NativeCaller:
Dans le fichierNativeCaller.h:#pragma managed using namespace System; namespace MixedAssembly { public ref class NativeCaller { private: String ^textToDisplay; public: NativeCaller(String ^textToDisplay); void CallNativeCode(); }; }Dans le fichier
NativeCaller.cpp:#pragma managed #include "NativeCaller.h" #include "NativeCallee.h" #include <stdio.h> #include <stdlib.h> #include <vcclr.h> using namespace System::Runtime::InteropServices; MixedAssembly::NativeCaller::NativeCaller(String ^textToDisplay) { this->textToDisplay = textToDisplay; } void MixedAssembly::NativeCaller::NativeCaller::CallNativeCode() { pin_ptr<const wchar_t> convertedString = PtrToStringChars(this->textToDisplay); NativeCallee *callee = new NativeCallee(const_cast<wchar_t*>(convertedString)); callee->DisplayText(); delete callee; }Cette implémentation permet de créer une classe managée
NativeCaller. Dans la méthodeNativeCaller::CallNativeCode(), on convertit la chaîne managéetextToDisplayen chaîne de caractères native pour appeler la classe nativeNativeCallee. - On ajoute la référence de
MixedAssemblydans le projetNativeCodeCaller. Il s’agit d’une dépendance managée classique donc il suffit d’effectuer un clique droit sur “Références” du projetNativeCodeCallerpuis “Ajouter une référence…” puis sélectionner “MixedAssembly”. - On modifie l’implémentation du
maindansProgram.csdu projetNativeCodeCallerpour instancier et appeler la classeNativeCaller:using MixedAssembly; namespace NativeCodeCaller { class Program { static void Main(string[] args) { string textToDisplay = "text to display éèà"; Console.WriteLine($"Displaying from managed code: {textToDisplay}"); NativeCaller nativeCaller = new NativeCaller(textToDisplay); nativeCaller.CallNativeCode(); Console.ReadLine(); } } }L’appel est classique puisqu’il s’agit d’un appel d’une classe managée.
Il suffit de compiler. L’exécution est similaire aux résultats obtenus plus haut:
Displaying from managed code: text to display éèà Displaying from unmanaged code: text to display éèà
Avec l’assembly mixte, il devient, ainsi plus facile de consommer la dépendance native NativeCallee.lib et de même, il devient plus facile de référencer l’assembly mixte MixedAssembly à partir de l’assembly NativeCodeCaller.
D’autre part, comme la NativeCallee.lib est une bibliothèque statique, le code est inclus directement dans l’assembly MixedAssembly.dll.
Le code de cette partie se trouve dans la branche cpp_cli du repository GitHub github.com/msoft/CallUnmanagedDll.
Exception de type AccessViolationException
Les appels à du code natif en particulier en utilisant l’attribut DllImport peuvent occasionner des exceptions de type System.AccessViolationException dans le cas où une opération aurait pu mener à une corruption de la mémoire. Les exceptions de type System.AccessViolationException ne proviennent pas forcément du CLR, elles peuvent provenir du système d’exploitation qui constate qui l’exécution d’une instruction dans un processus peut corrompre la mémoire. Quand cette exception est lancée à l’extérieur du processus par le système d’exploitation, il peut être plus compliqué de l’intercepter.
Pour davantage de détails sur les exceptions de ce type, voir Gestion des “Corrupted State Exceptions” par le CLR).
Conclusion
Dans cet article, on a pu expliciter 2 méthodes pour effectuer de l’interopérabilité de .NET vers du code natif. Ces 2 méthodes peuvent être choisies suivant les cas d’utilisation auxquels on peut être confronté.
On a aussi eu l’occasion de parler de quelques problématiques qui peuvent subvenir comme l’encodage de chaînes de caractères, le passage de chaînes de caractères, le “marshalling”, le retour de chaînes de caractères et les exceptions qui peuvent subvenir. Il existe beaucoup d’autres problèmes pouvant résulter de ce type d’appel.
L’exécution des exemples présentés ne présente pas de difficultés sur un poste de développeur car si l’installation de l’environnement de développement est correctement faite, aucune dépendance liée au Runtime C++ ne sera manquante. Toutefois si on veut déployer ce type de solution sur des machines classiques, d’autres problématiques spécifiques au Runtime C++ peuvent subvenir. On aura l’occasion d’expliciter quelques unes de ces problématiques dans un prochain article.
- P/Invoke Tips: http://benbowen.blog/post/pinvoke_tips/
- P/Invoke Tutorial: Passing strings: https://manski.net/2012/06/pinvoke-tutorial-passing-strings-part-2/
- String and Character Literals (C++): https://docs.microsoft.com/en-us/cpp/cpp/string-and-character-literals-cpp?view=vs-2019
- Stackoverflow.com – std::wstring VS std::string: https://stackoverflow.com/questions/402283/stdwstring-vs-stdstring
- Stackoverflow.com – DllImport – ANSI vs. Unicode: https://stackoverflow.com/questions/17808003/dllimport-ansi-vs-unicode
- Windows Data Types: https://docs.microsoft.com/fr-fr/windows/desktop/WinProg/windows-data-types
- P/Invoke how to get a unicode string from C# to C++: https://social.msdn.microsoft.com/forums/en-US/08bdec64-5de9-4773-865f-1bfeb890a0e5/pinvoke-how-to-get-a-unicode-string-from-c-to-c
- Stackoverflow.com – Output unicode strings in Windows console app: https://stackoverflow.com/questions/2492077/output-unicode-strings-in-windows-console-app
- WideCharToMultiByte function: https://docs.microsoft.com/fr-fr/windows/desktop/api/stringapiset/nf-stringapiset-widechartomultibyte
- Stackoverflow.com – How do I use MultiByteToWideChar?: https://stackoverflow.com/questions/6693010/how-do-i-use-multibytetowidechar
- Stackoverflow.com – How do you properly use WideCharToMultiByte: https://stackoverflow.com/questions/215963/how-do-you-properly-use-widechartomultibyte
- Debugging System.AccessViolationException – DllImport hell: https://blog.elmah.io/debugging-system-accessviolationexception/