| PARTIE 1 | PARTIE 2 | PARTIE 3 | ||
|---|---|---|---|---|
| Sommaire général | Concevoir des microservices | Appels entre Microservices | Intégration continue et implémentation des tests | Références |
Intégration continue
Effectuer une “build” pour tous les services
Effectuer une “build” par service
Plusieurs “build pipelines”
Appliquer des tests
Pyramide des tests
Tests unitaires
Tester un service
Tests de performance
Tests “end-to-end” (e2e)
Consumer-Driven Contract tests
Tests après la mise en production
Stratégies de déploiement
Plusieurs services par hôte
Un service par hôte
Un service par “container”
Déploiement sans serveur
Intégration continue
Dans le cas d’une application en monolithe, le processus d’intégration continue passe par l’exécution des tests pour toute l’application. Dans le cas d’une application en microservices, on peut de la même façon choisir de considérer l’application comme un composant unique qui doit être testé intégralement. Cette approche est dans le prolongement de celle utilisée pour les applications en monolithe, elle a pour avantage de garantir que l’approche en microservices ne dégrade pas l’application.
Le gros inconvénient de maintenir une approche similaire à celle d’une application en monolithe est de ne pas tirer partie du découpage en microservices. Ce découpage apporte une grande flexibilité puisqu’il permet de découper l’application en domaines fonctionnels et d’affecter ces domaines à des équipes particulières.
Il n’y a pas de meilleures solutions entre choisir de considérer de tester l’application dans son intégralité ou choisir de la tester par service. Il faut juste arbitrer en fonction de ses contraintes opérationnelles.
De façon générale, l’intégration continue peut se résumer de cette façon:
- Compiler l’application sur un serveur de builds après chaque commit.
- Exécuter les tests à chaque commit de façon à avoir un retour rapide sur les éventuelles régressions qui auraient pu être introduites.
- Le résultat de la compilation et de l’exécution des tests doit être visible par tous les développeurs de façon à ce qu’ils puissent se rendre compte des éventuels échecs de compilation ou de tests dont l’exécution aurait échoué.
- Quand une build est en échec à cause d’une erreur de compilation ou d’un test en défaut, il faut corriger au plus vite.
- Une nouvelle version de l’application doit être déployée après chaque commit.
Effectuer une “build” pour tous les services
Cette approche consiste à compiler et à exécuter les tests pour toute l’application et pour tous les services à chaque commit d’un service.
Cette approche est la plus facile à mettre en œuvre car il suffit d’une seule usine de builds pour tous les services. Elle est dans le prolongement de l’approche utilisée pour une application en monolithe. Il n’y aura donc pas beaucoup d’adaptations nécessaires à l’usine de builds lors du découpage d’une application en monolithe en une application en microservices.
L’intégration continue consiste à effectuer une build après chaque commit. Dans le cas d’une application en microservices, il faudra donc builder tous les services après chaque commit.
Builder tous les services après chaque commit peut s’avérer de plus en plus compliqué à mesure que le nombre de développeurs augmente. De la même façon, plus le nombre de services augmente et plus les commits seront fréquents.
Effectuer une “build” par service
Effectuer une build par service consiste à considérer une usine de builds par service et non pour toute l’application. Chaque microservice devient indépendant en terme de livraison ce qui signifie qu’ils sont livrés indépendamment l’un de l’autre.
Cette approche est plus compliquée à mettre en œuvre car elle nécessite de mettre en place une usine de build par service et non pour toute l’application. Toutefois, effectuer une build par service permet:
- D’exécuter des tests de façon plus ciblée puisqu’ils seront exécutés suivant la livraison d’un service précis.
- Cette approche donne la possibilité de déployer un service à la fois.
- Sachant que souvent le découpage des équipes épouse celui des services, effectuer une build par service permet de responsabiliser davantage chaque équipe. Une équipe est responsable d’un service donc en cas d’échec de la build de ce service, cette seule équipe est concernée. Les responsabilités sont, ainsi, clairement définies. Cette approche est en accord avec le principe “You build it, you run it” énoncé par Werner Vogels d’Amazon.
Avoir une build par microservice n’est pas facile à mettre en œuvre pour un projet from scratch car les contextes bornés (i.e. bounded context) ne sont pas forcément très stables. Au début de la conception d’un projet, on peut être amener à modifier fréquemment l’architecture et le découpage fonctionnel des microservices. Ainsi une approche de construire une build par microservice nécessite d’adapter systématiquement l’usine de build de tous les services en fonction des nouvelles organisations. Cette approche entraîne donc davantage de travail de la part des équipes de développement.
Même si l’approche une build par microservice est plus contraignante, il faut tenter de l’atteindre le plus vite possible quand les contextes bornés sont stabilisés. De même, dans le cas de l’adaptation d’un monolithe, les contextes bornés sont généralement plus stables on peut donc appliquer cette approche dès le début.
Plusieurs “build pipelines”
Un des objectifs du continuous delivery est d’avoir un feedback rapide sur une build après le commit d’un développeur. Cette contrainte est importante car avoir des builds rapides à exécuter permet de déployer des services rapidement.
Pour que le feedback soit rapide, il faut que les tests s’exécutent rapidement. Or, certains tests peuvent être longs à s’exécuter, en particulier si plusieurs services sont impliqués ou si des tests entraînent l’exécution d’un workflow complexe. Pour éviter qu’une build soit trop pénalisée par l’exécution de tests longs et pour permettre d’avoir un feedback rapide, une solution consiste à considérer plusieurs pipelines:
- Une build exécutant des tests rapides: ces tests sont exécutés à chaque livraison. Etant donné que leur exécution est rapide, ils n’empêchent pas d’avoir un feedback rapide après chaque commit.
- Une build exécutant les tests longs: étant donné que ces tests sont longs à exécuter, ils ne peuvent pas être exécutés après chaque commit. Par exemple, on peut les exécuter de façon différée une fois par jour.
Appliquer des tests
Dans le cadre de tests appliqués à des microservices, on peut se demander quels sont les composants sur lesquels on va appliquer les tests:
- Doit-on tester tout le système ?
- Faut-il appliquer les tests à tous les services ?
- Doit-on tester les interactions entre les services ?
- Faut-il tester les services comme une boite noire ?
- Doit-on exécuter des tests internes aux services ?
Il n’est pas trivial de répondre à ces questions d’autant que le premier réflexe est de chercher à tester une application en microservices comme on pourrait tester un monolithe. On va voir par la suite que certaines approches courantes dans le cas des monolithes ne sont pas forcément très pertinentes pour les microservices.
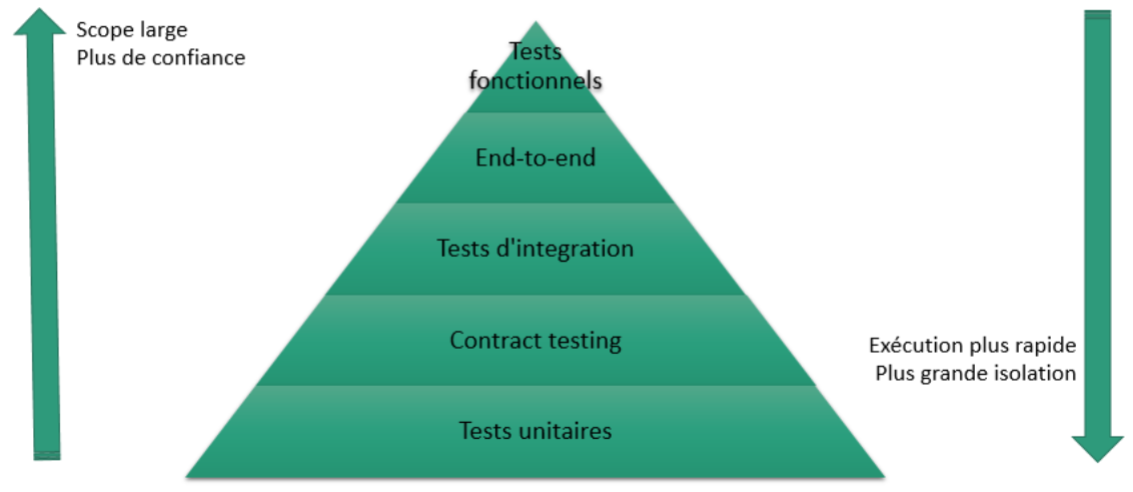
Pyramide des tests
La pyramide des tests (cf. TestPyramid) est un concept énoncé par Mike Cohn. Elle indique que:
- Tests unitaires: 80 à 90% des tests sont des tests unitaires visant à tester des éléments précis de l’application comme des classes ou des fonctions. Ces tests sont peu couteux à exécuter et s’exécutent généralement rapidement car ils n’impliquent pas beaucoup de code.
- Tests d’acceptance: ils concernent 5 à 15% des tests. Ils concernent une ou plusieurs fonctionnalités. Ils visent à tester la réponse de l’application à une fonctionnalité dans un cadre précis. Ces tests sont plus couteux et plus longs à exécuter que les tests unitaires car ils nécessitent l’exécution de plus de code et des interactions entres des éléments plus complexes.
- Tests IHM: ils représentent 1 à 5% des tests. Ces tests vérifient les comportements de l’application au niveau de l’IHM ou plus généralement des entrées/sorties. Ils correspondent au niveau le plus élevé où il est possible d’appliquer des tests à l’application. Ces tests sont couteux car ils sont complexes à mettre en œuvre et qu’ils nécessitent toute l’application pour s’exécuter.
Dans le cadre des microservices, la pyramide des tests peut s’exprimer de cette façon:
Tests unitaires
Comme pour une application classique, on peut appliquer des tests unitaires à des microservices. Il n’y a pas de spécificités dans le cadre des microservices:
- Ces tests sont nombreux car ils s’appliquent à des classes et des fonctions.
- Ils s’exécutent rapidement.
- Comme pour n’importe quel type d’application, on peut mettre en place une approche TDD (i.e. Test-Driven Design ou conception dirigée par les tests).
- Les tests unitaires s’appliquent seulement à des fonctions internes du service.
De nombreux outils existent pour faciliter l’application des tests unitaires: mockito, Moq, nUnit, JUnit etc…
Tester un service
En s’élevant d’un niveau dans la pyramide des tests, on peut chercher à tester un service entier. Cette approche est utile car elle permet de vérifier que le service réalise correctement sa fonction. On peut détecter facilement les régressions par rapport aux clients car ces tests peuvent impliquer les interfaces du service. Ce type de tests est intéressant puisqu’ils permettent de révéler rapidement les problèmes en cas d’échec.
Il existe de nombreux outils permettant d’appliquer des tests à des services:
- curl: cet outil n’est pas spécifique aux microservices. Il n’est pas non plus spécifique aux tests d’une façon générale. Il permet d’effectuer des requêtes HTTP en définissant des éléments précis d’une requête. L’intérêt de cet outil est sa simplicité.
- Jbehave et cucumber: ces outils ne sont pas non plus spécifiques aux microservices toutefois ils facilitent l’implémentation et l’exécution de tests d’acceptance. Ils permettent d’implémenter des applications suivant l’approche BDD (i.e. Behavior-Driven Developement ou dévoloppement dirigé par le comportement).
- Chai et Mocha: ces outils ne sont pas spécifiques aux microservices mais ils sont spécialisés dans le test d’application web.
Tester des microservices peut nécessiter d’effectuer des traitements sur du JSON. Certains outils permettent de faciliter l’implémentation de ces traitements: Newtonsoft ou JSON.Net, google-gson, JSON.simple ou FasterXML/jackson.
Enfin d’autres outils sont plus spécialisés pour le test de microservices:
Tests de performance
Une attention particulière doit être apportée aux tests de performance dans une application en microservices. Il ne faut pas négliger la latence provoquée par les appels aux microservices. Cette latence est généralement négligeable dans une application monolithe car les appels de fonctions se font plus rarement en utilisant le réseau. De même, un appel à une application en microservices peut se traduire par plusieurs appels internes à d’autres microservices ce qui augmente encore les différences de performances qu’il peut y avoir avec une application monolithe.
L’intérêt des tests de performance est de détecter une exécution anormalement lente d’un microservice avant sa livraison. L’exécution lente d’un microservice peut dégrader les performances de toute l’application.
Certains outils sont spécialisés pour les tests de performances et de charge: Gatling et Apache JMeter.
 |
On peut citer aussi mountebank qui est spécialement conçu pour effectuer des tests à travers le réseau et est particulièrement adapté pour les microservices:
|

|
Tests “end-to-end” (e2e)
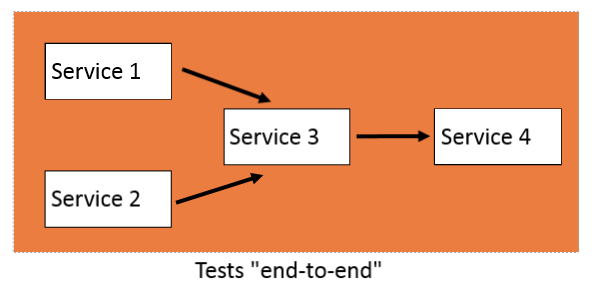
Pour appliquer des tests d’acceptance sur une application en microservices, on pourrait vouloir appliquer des tests de bout en bout c’est-à-dire appliquer les tests sur un workflow entier impliquant plusieurs services. Ce type de tests permet de tester de façon plus complète les interactions entre les services en considérant l’application comme une boite noire.
Par exemple, si on considère le schéma suivant, appliquer des tests end-to-end implique de tester plusieurs services en effectuant des appels en entrée et en testant les résultats en sortie:
Si on intègre les tests end-to-end dans le cadre des build chains (i.e. chaine de livraison), ils doivent être exécutés à la fin des chaines:
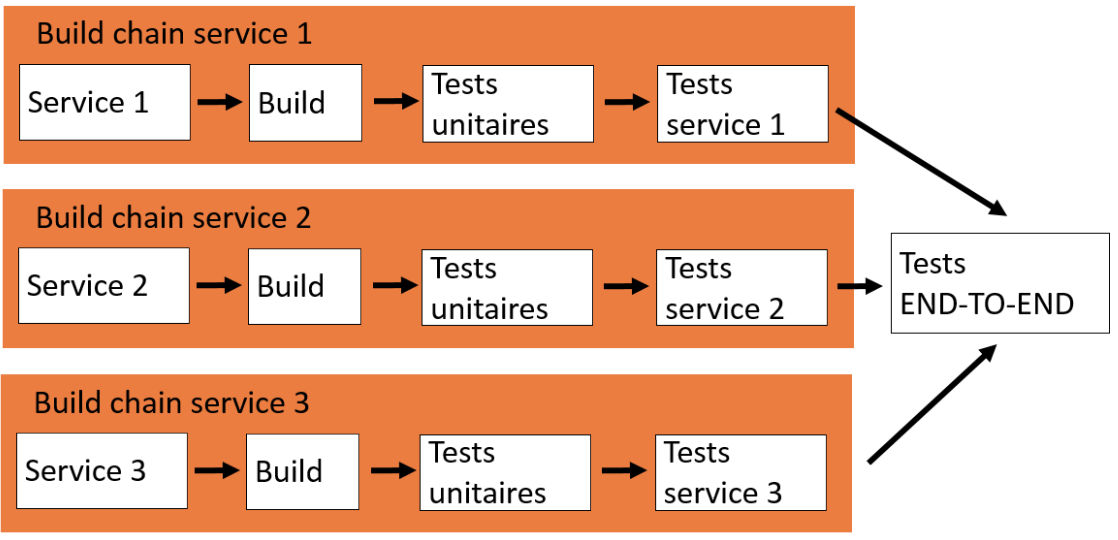
Par exemple, si on considère les build chains de plusieurs services Service 1, Service 2 et Service 3, les tests end-to-end doivent s’exécuter:
- Après les tests unitaires et après les tests concernant chaque service,
- A chaque fois qu’une build s’est terminée pour chacun des 3 services.
Aux premiers abords, les tests end-to-end peuvent présenter de nombreux intérêts:
- Ils permettent de couvrir un spectre large de l’application et de tester le fonctionnement de plusieurs services entre eux.
- Ils donnent la possibilité d’appliquer des tests fonctionnels puisqu’on peut tester des workflows entiers.
- Si une version de l’application en microservices réussit les tests, on peut livrer la version en production avec une grande confiance.
Toutefois, appliquer des tests end-to-end à une application en microservices est une fausse bonne idée car l’exécution de ces tests peut vite devenir longue à mesure que le nombre de microservices augmente:
- Les tests end-to-end sont plus longs à s’exécuter car ils concernent tous les services. Il faut que tous les services soient compilés et prêts à être exécuté pour qu’on puisse exécuter les tests end-to-end. Non seulement, il faut une plateforme de tests pouvant impliquer tous les services simultanément mais en plus les tests doivent s’exécuter après chaque livraison d’un service.
- Pas de feedback rapide: si on a beaucoup de tests end-to-end et beaucoup de services, l’exécution prendra du temps et retardera la génération d’un feedback rapide après une build. Ne pas avoir de feedback rapide compromet toute la chaine de livraison de l’application et empêche la livraison rapide de composants.
- En cas d’échec d’un test end-to-end: il faut corriger et ré-exécuter toute la chaine pour un service donné ce qui retarde la livraison du service et aussi éventuellement celle des autres services. Cette complexité peut rendre difficile la livraison de l’application.
- Quand déclencher les tests end-to-end: sachant que ce type de test prend du temps à s’exécuter et empêche la livraison de services, on peut se demander quand doit-on les exécuter. Par exemple, si on les exécute une fois par jour, ils ne rentrent pas dans le cadre de tests rapides et en cas d’urgence, on peut être amené à livrer des services sans attendre la fin de leur exécution. Ne pas attendre le feedback des tests end-to-end abaisse considérablement la pertinence de ces tests.
Il faut donc éviter au maximum les tests end-to-end car:
- Ils impliquent trop de microservices et qu’il est compliqué d’avoir une plateforme permettant l’exécution simultanée de tous les services.
- Ils impliquent trop d’équipes car toutes les équipes doivent participer à la maintenance des tests end-to-end.
- Ils impliquent le réseau ce qui entraîne une complexité qui ne permet pas d’avoir une feedback rapide sur un microservice précis.
Enfin en cas d’échec d’un test end-to-end, il peut être compliqué de savoir où se trouve le bug car son exécution implique plusieurs services. Comment savoir qui doit corriger le bug alors que tous les développeurs ne connaissent pas forcément tous les aspects fonctionnels de l’application. En effet pour un développeur, il sera compliqué de trouver un bug sur du code d’une autre équipe.
Il faut donc éviter au maximum les tests end-to-end dans le cadre de microservices…
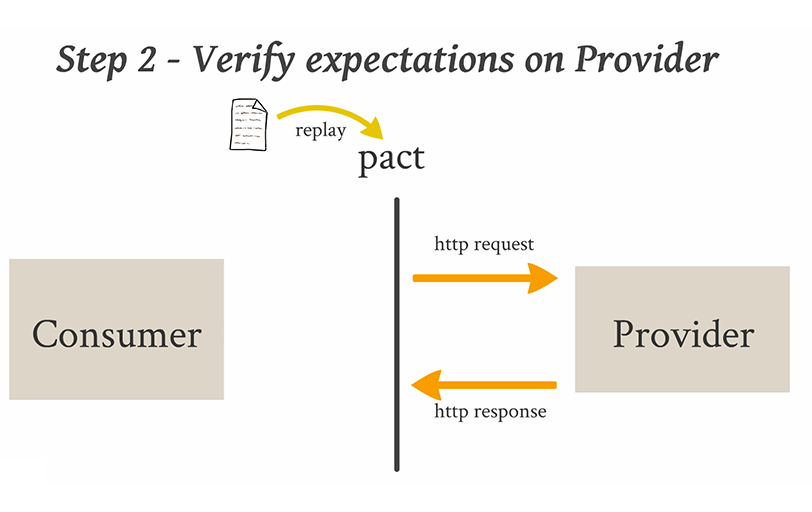
Consumer-Driven Contract tests
Pour tester un service, une solution peut consister à appliquer des tests par contrats dirigés par le client du service (i.e. Consumer-Driven Contract tests). L’idée de ces tests est de simplifier l’approche des tests end-to-end (i.e. tests de bout en bout) de façon à tester un seul service et de pouvoir identifier efficacement les éventuelles régressions.
On considère dans un premier temps que les communications entre un client et un service font partie d’un contrat:
- Le client s’engage à générer des requêtes compréhensibles du service: le client a des besoins précis auprès du service qui justifient l’envoi de requêtes vers ce service,
- Le service s’engage à répondre au client: le service doit répondre de façon précise aux demandes du client si ces requêtes sont compréhensibles.
Le client et le service sont donc liés par un contrat dont les termes sont définis par le client. Les tests Consumer-Driven Contract visent à tester les termes de ce contrat:
- Si la demande du client n’est pas compréhensible alors le service ne peut pas répondre.
- Si le service ne répond pas à une demande compréhensible d’un client alors il a rompu le contrat.
Les tests Consumer-Driven Contract s’implémentent de la façon suivante:
|

|
|
|
Ainsi, les tests Consumer-Driven Contract permettent de valider le contrat entre un client et un service puisqu’ils prennent en compte les attentes du client de façon précise. Ces tests s’exécutent sur un seul service, ils sont donc plus rapides que les tests end-to-end et surtout ils permettent d’avoir un feedback rapide pour un service donné. Enfin les tests Consumer-Driven Contract permettent de détecter et d’éviter les breaking changes d’un service.
L’implémentation de tests Consumer-Driven Contract est fastidieuse et nécessite l’utilisation d’outils comme:
Tests après la mise en production
L’application de tests à des microservices est complexe car:
- Il faut prendre en compte le lien d’un service avec les autres services,
- Il est difficile de mettre en œuvre une plateforme de tests complète impliquant tous les services simultanément.
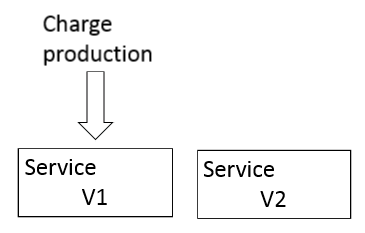
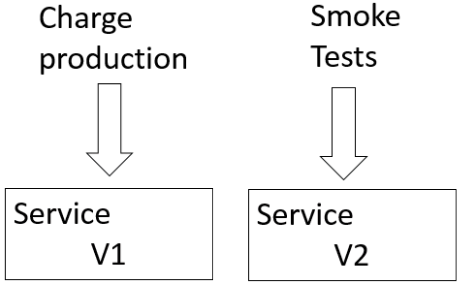
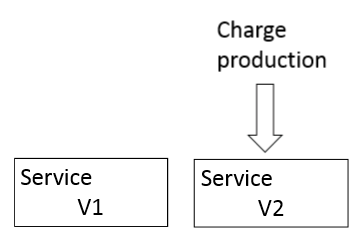
En plus des tests Consumer-Driven Contract (i.e. test par contrat dirigé par le client), il existe des tests qu’on peut appliquer après la mise en production. Ces tests ont l’avantage de ne pas nécessiter une plateforme spécifique en plus de la plateforme de production. Ils visent à tester le comportement d’un service directement en production sans utiliser ses réponses.
Les tests après la mise en production s’appliquent de la façon suivante:
|
 |
|
|
|
|
L’intérêt principal de ce type test est d’augmenter la confiance lors de la livraison d’un service et de limiter le risque de régression puisqu’on a le temps d’observer le comportement du service à déployer.
Dans la documentation, ce type de déploiement sont des “Zero Downtime Deployment” (i.e. déploiement avec zéro temps d’interruption de service), ils sont indiqués avec plusieurs variantes:
- Blue/Green deployment: il s’agit du même mécanisme que celui expliqué précédemment. Pour l’appliquer il faut être capable de mettre en production 2 chaines d’exécution, ce qui sous-entend d’avoir un load-balancer qui répartit la charge dans l’une ou l’autre des chaines d’exécution.
- Canary Release: ce pattern consiste à utiliser le service V2 sur un échantillon restreint de données de production. Cette configuration est maintenue pendant le temps du test. Si les résultats sont satisfaisants alors on affecte toutes les données de production sur le service V2.
- Dark Launch: cette pratique consiste à déployer la partie non visible d’une fonctionnalité en utilisant la charge de production. L’intérêt de cette pratique est de tester les performances du service sur lequel la fonctionnalité est implémentée.
Stratégies de déploiement
La stratégie de déploiement fait aussi l’objet de particularités dans le cadre d’une application en microservices car chaque service peut être un livrable séparé. Dans l’approche en monolithe, on déploie le plus souvent un seul composant sur une seule machine hôte. Pour les microservices, il est possible d’être plus fléxible en déployant:
- Plusieurs services sur une même machine hôte,
- Un service par machine hôte,
- Un service par container. Le container peut être déployer seul sur une machine hôte ou avec d’autres containers.
- Il est aussi possible de déployer des microservices sans serveurs avec des approches Cloud “serverless”.
Plusieurs services par hôte
Cette approche est plus facile et plus rapide car le déploiement est effectué sur une machine hôte. Dans le cas où les services sont sur le même serveur Apache Tomcat, IIS ou nginx, ils peuvent être démarrés simplement en démarrant le serveur. Cette approche est dans le prolongement des déploiements d’une application en monolithe et a l’avantage de ne pas trop complexifier l’environnement de déploiement.
L’inconvénient majeur d’avoir plusieurs services par hôte est de moins isoler les services entre eux:
- Si les services sont dans le même processus, on ne peut pas monitorer les services individuellement.
- Le redémarrage du serveur Web entraîne le redémarrage de tous les services.
- Dans le cas où un service consomme anormalement beaucoup de ressource, il peut impacter les autres services et donc toute l’application.
- Si les services utilisent des technologies différentes, il faudra déployer toutes les technologies sur la même machine hôte.
Avoir plusieurs services sur une même machine hôte est une approche intéressante dans un premier temps car elle est simple à mettre en œuvre toutefois pour utiliser pleinement la flexibilité des microservices, il faut préférer d’autres stratégies.
Un service par hôte
Avoir un service par hôte est une approche qui permet une plus grande flexibilité. Par hôte, on peut considérer une machine physique mais aussi une machine virtuelle. Avec cette approche:
- Chaque service s’exécute de façon isolée.
- On peut affecter à chaque service, une charge CPU et une quantité de mémoire précise.
- Il est plus facile d’appliquer des fonctionnalités de load balancing et d’autoscaling.
- La problématique de déploiement d’un service peut être réduite au déploiement d’une machine virtuelle.
De nombreuses solutions existent pour faciliter l’utilisation de machines virtuelles. Certaines permettent d’automatiser la création de machines virtuelles comme Packer ou boxfuse.
 |
Des solutions permettent de créer des machines virtuelles comme:
Pour personnaliser des images VM, on peut utiliser des scripts Puppet, Chef ou Ansible.
 |
Pour automatiser l’installation de composants Windows, on peut s’aider de chocolatey nuget.

L’utilisation d’images VM peut comporter quelques inconvénients:
- Les builds d’images VM sont plus longues que les builds des microservices car les fichiers sont plus lourds.
- L’initialisation d’une machine virtuelle peut être plus longue que le démarrage d’un service.
- Une machine virtuelle peut être sous utilisée par le microservice qu’elle héberge.
- La mise en place d’une build chain incluant des images VM peut être longue à effectuer et peut détourner une équipe de ses problématiques fonctionnelles en particulier si elle implique l’implémentation de scripts complexes.
Un service par “container”
Un container permet de virtualiser des composants au niveau du système d’exploitation. On peut configurer pour chaque container des ports de communications ou un système de fichiers spécifiques. De même qu’une machine virtuelle, il est possible de limiter les ressources CPU et la mémoire utilisée par container.
Les solutions les plus courantes pour l’utilisation de containers sont Docker et Solaris Zones.
 |
Il est possible d’exécuter plusieurs containers sur une même machine hôte. D’autre part, l’avantage des containers par rapport aux machines virtuelles est de ne disposer que du minimum pour exécuter un microservice, limitant ainsi la taille des images. Enfin des gestionnaires de clusters comme Kubernetes ou Marathon peuvent aider à gérer des containers en les plaçant sur des hôtes disponibles.
L’utilisation de containers comporte quelques inconvénients:
- Leur utilisation ne prive pas de devoir administrer la machine hôte qui les héberge. Cependant des solutions comme Google Container Engine ou Amazon EC2 Container Service dispensent d’administrer la machine hôte.
- Les containers peuvent sous-utiliser une machine hôte ce qui peut occasionner des coûts supplémentaires.
Déploiement sans serveur
Dans le cadre de microservices, certains services Cloud permettent un déploiement sans serveur. Le déploiement doit se faire en uploadant un package et en indiquant la fonction qui sera exécutée dans le package à chaque requête au service. La fonction exécutée doit être sans états.
Ce service est proposé sous le nom de Lambda chez Amazon Web Services (AWS) et Azure Functions chez Microsoft Azure. La facturation de ces services se fait au temps d’exécution et à la mémoire consommée.
Le gros avantage du déploiement sans serveur est de réduire au minimum les problématiques liées au déploiement: il n’y plus de notions de machines virtuelles ni de containers. Au dela du déploiement, il n’y a pas non plus de nécessité de s’intéresser aux problématiques de load balancing ou d’autoscaling. Enfin, le temps de mise en œuvre de la build chain est réduit.
Monitoring
Il est important de pouvoir monitorer l’état des microservices dans une application en microservices car on peut anticiper un éventuelle défaut d’un service avant que le service soit complètement en échec. D’autre part, le monitoring peut faciliter la détection d’un bug ou d’un échec quand:
- Plusieurs services sont concernés,
- Les services sont répartis sur plusieurs serveurs.
Le monitoring peut passer par l’utilisation de logs comme pour une application en monolithe toutefois sachant que les services peuvent être dispersés sur plusieurs machines hôte, l’analyse de logs peut être très fastidieuse. De plus, les logs classiques ne permettent pas facilement d’anticiper le défaut éventuel d’un service.
La meilleure pratique pour monitorer des services est d’utiliser un service centralisé pour analyser les logs générés avec 3 outils:
|
 |
|
 |
Pour anticiper les échecs, on peut utiliser des métriques:
- Collecter la charge CPU et la mémoire utilisée permet de détecter un défaut ou de prévoir des besoins d’autoscaling.
- Exposer des métriques sur les services: par exemple remonter des taux d’erreurs ou un temps de réponse peut révéler l’état des performances d’un service.
Pour permettre d’utiliser efficacement ces métriques, il faut standardiser leur collecte. Certains outils peuvent faciliter l’utilisation de métriques comme:
- Des bibliothèques logicielles Metrics: elles permettent d’envoyer les métriques d’un service. Elles sont disponibles dans plusieurs langages de programmation.
- Graphite: il permet d’envoyer des métriques d’un serveur ou d’un service en temps réel. Il permet aussi de monitorer les métriques avec des graphiques.
- Zipkin: cet outil permet de tracer des requêtes à travers un système distribué.
En conclusion…
Le but de cet article était de comparer l’architecture en microservices avec une architecture plus traditionnelle. Choisir une architecture en microservices n’est pas anodin puisqu’elle nécessite de prendre en compte certaines problématiques liées aux systèmes distribués. D’autre part la plupart des processus d’intégration et de déploiement peuvent être assez différents d’une architecture en monolithe plus classique et nécessiter des efforts d’implémentation qui peuvent être conséquents au début de la réalisation d’un projet. Toutefois, les microservices donnent la possibilité de réduire les interruptions de service lors de déploiement ou de s’adapter à la charge de façon moins couteuse, apportant ainsi une plus grande flexibilité. De nombreuses problématiques liées aux microservices peuvent être résolues en utilisant des solutions techniques déjà implémentées. Quelques unes de ces solutions ont été présentées dans cet article.
Partie 1: Concevoir des microservices
Partie 2: Appels entre microservices
Partie 3: Intégration continue et implémentation des tests
Personne ne devrait dire “test fonctionnel”. La pyramide des tests est transversale à cette idée.
Si votre définition de test fonctionnel est “test sur cas réel” alors ca peut déjà etre le cas à chaque niveau.
Si votre définition de test fonctionnel est “comme le ferait un utilisateur” alors c’est bien le haut de la pyramide, mais ca ne devrait pas s’appeler comme ca.
En general, on convient d’appeler ca : test manuel, ou test exploratoire.
Il faut bannir l’expression “test fonctionnel”, sinon les équipes qui vont l’utiliser sans connaitre la pyramide vont finir par tout mettre dedans.