| PARTIE 1 | PARTIE 2 | PARTIE 3 | ||
|---|---|---|---|---|
| Sommaire général | Concevoir des microservices | Appels entre Microservices | Intégration continue et implémentation des tests | Références |
Choix des interfaces
Utiliser le “semantic versioning”
Créer un nouveau point d’accès en cas de “breaking changes”
Appels synchrones ou asynchrones
Tolérer les échecs partiels
Pattern “circuit breaker”
Chef d’orchestre ou chorégraphie
Service discovery
Connaître la configuration des services en avance
Pattern “client-side discovery”
Pattern “server-side discovery”
Quelques technologies utilisées pour les appels
Communications asynchrones par messagerie
Communications synchrones
REpresentational State Transfer (REST)
REST over HTTP
API RESTful
Niveau 0
Niveau 1
Niveau 2
Niveau 3
Niveau de maturité
Eviter les “anemic domain models”
Les liens entre les services sont complexes à gérer car ils nécessitent d’aborder certaines problématiques qui sont, souvent, inexistantes dans le cas d’une application monolithe. Les choix effectués pour définir et implémenter ces liens doivent respecter une règle d’or:
“Peut-on modifier et déployer un service sans en impacter un autre ?”
Les problématiques les plus importantes concernant les appels entre services sont:
- Le choix des interfaces
- Le versionnement des interfaces
- Le tolérance aux erreurs
- Effectuer des appels synchrones/asynchrones
- Le topologie des appels
Choix des interfaces
Le choix des interfaces entre microservices est délicat car une mauvaise définition de ces interfaces peut contraindre à de nombreux refactorings qui impacteront plusieurs services. Il faut donc définir des interfaces pour qu’elles soient le plus stable possible de façon à minimiser les changements:
- Eviter d’utiliser des interfaces avec des types trop abstraits (comme
objectpar exemple): il est préférable d’utiliser des types précis quitte à multiplier les fonctions. Dans le cas où on utilise plusieurs fonctions, une modification peut amener à modifier quelques signatures sans devoir modifier toutes les signatures. Les quelques fonctions modifiées peuvent ne pas impacter tous les clients du service. D’autre part, utiliser des interfaces trop indéfinies nécessitent une connaissance “à priori” de la part des clients sur les types réels utilisés. Il ne pourra pas “découvrir” les interfaces. - Utiliser une approche API first: il faut définir les interfaces entre 2 microservices avant de les implémenter. La définition des interfaces permet de se mettre d’accord avec tous les clients et éviter des incompréhensions.
- Etre flexible à la lecture pour être plus robuste aux changements d’interfaces.
Martin Fowler a appelé cette astuce Tolerant Reader, elle permet d’être plus tolérant aux changements dans les réponses des microservices. Pour chercher un objet dans un fichier XML, on peut utiliser le XPath relatif ou le XPath absolu.
Si on prends l’exemple XML suivant:
<catalog>
<book>
<title>XML</title>
</book>
</catalog>
Pour lire le titre dans le nœud title, on peut exécuter le code suivant:
using System.Xml;
...
string xml = ...
XmlDocument doc = new XmlDocument();
doc.LoadXml();
XmlNode titleNodeUsingAbsPath = doc.SelectSingleNode("/catalog/book/title");
XmlNode titleNodeUsingRelPath = doc.SelectSingleNode("//book/title");
La requête peut être effectuée en utilisant le XPath absolu avec la syntaxe /catalog/book/title.
Si on utilise le XPath relatif, la syntaxe utilisée est //book/title.
Dans le cas où le fichier XML change de structure:
<catalog>
<content>
<book>
<title>XML</title>
</book>
</content>
</catalog>
Le XPath relatif avec la même syntaxe permet toujours de récupérer le contenu du nœud title. En revanche la version avec le XPath absolu ne permet plus de récupérer le nœud title.
Utiliser le “semantic versioning”
Le “semantic versioning” permet d’indiquer qu’une version contient des breaking changes:
- Les versions sont numérotées en utilisant 3 nombres: MAJOR.MINOR.PATCH (par exemple 4.7.1)
- Un incrément du nombre MAJOR indique un breaking change avec la version précédente.
- Un incrément du nombre MINOR indique l’ajout d’une fonctionnalité rétrocompatible.
- Un incrément du nombre PATCH indique des corrections de bugs rétrocompatibles.
En cas de changement de version, les clients du service peuvent savoir l’importance des changements effectués et envisager la mise à jour de leurs interfaces.
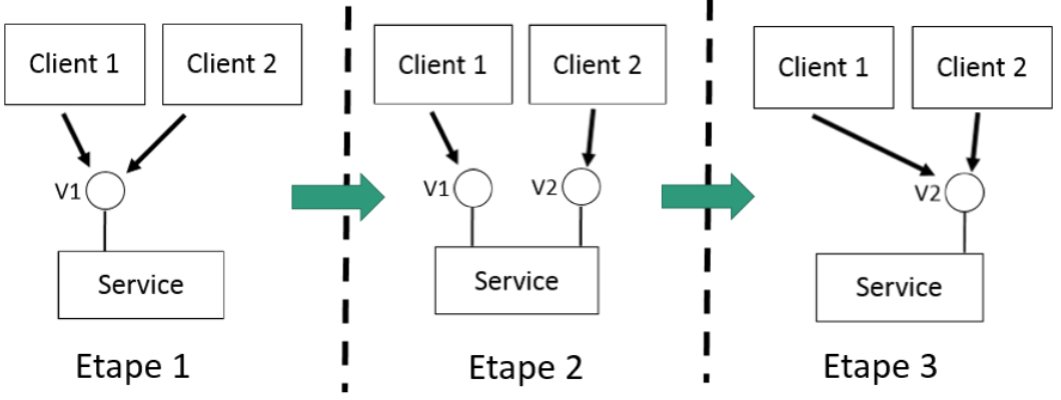
Créer un nouveau point d’accès en cas de “breaking changes”
Pour éviter un impact trop fort sur les clients d’un service en cas de breaking changes des interfaces, une méthode consiste à procéder par étape:
- Etape 1: utilisation des interfaces V1 par tous les clients.
- Etape 2: on introduit la nouvelle interface V2 et on indique aux clients de migrer vers l’interface V2. Les clients migrent au fur et à mesure. On maintient les 2 interfaces V1 et V2 pour ne pas trop impacter les clients qui utilisent toujours les interfaces V1. On indique aux clients une date à partir de laquelle V1 ne sera plus disponible.
- Etape 3: quand tous les clients ont migré, on supprime les interfaces V1 et tous les clients utilisent V2.
Appels synchrones ou asynchrones
On peut se poser la question de savoir comment effectuer des appels entre les clients et leurs microservices:
- Effectuer des appels synchrones: le client envoie une requête au microservice, il attend pendant le traitement de la requête et il récupère la réponse du service en fin de traitement.
- Effectuer des appels asynchrones: le client envoie une requête au microservice mais n’attend pas pendant le traitement. Le client peut être notifié à la fin du traitement directement par le service ou le client s’abonne à des évènements déclenchés par le service de façon à recevoir des notifications.
Les appels synchrones correspondent au modèle request/response. Le client doit s’adapter au temps de traitement du service et doit prendre en compte ce temps de traitement dans son implémentation. Prendre en compte le temps de traitement permet, par exemple, d’éviter des timeouts dans le cas où le temps est trop long. Si le temps de traitement se rallonge suivant le type de requête, le client devra s’adapter en conséquence. L’avantage des appels synchrones est que le client peut avoir une réponse immédiate sur le statut de la requête. Du fait de l’adaptation du client en fonction du temps de traitement, ce type d’appels augmente le couplage entre service.
A l’opposé les appels asynchrones permettent d’éviter une adaptation du client suivant le temps de traitement de la requête. Ce type d’appels correspond au modèle orienté évènement. Le client s’abonne à des évènements du service en fonction de ce pourquoi il veut être notifié. L’émetteur de l’évènement n’a pas de connaissances des clients qui s’abonnent. Ce type d’appels permet de moins coupler les clients à leur service.
Suivant la topologie des échanges entre un microservice et ses clients, on peut être amener à faire un choix dans le type d’appels à implémenter:
| Un à un | Un à plusieurs | |
| Synchrone | Request/Response | N/A |
| Asynchrone | Notification | Publication/Souscription |
| Request/Response asynchrone | Publication/Réponses asynchrones |
Effectuer des appels asynchrones est plus complexe qu’effectuer des appels synchrones. On peut distinguer 2 façons de faire des appels asynchrones:
- Mécanisme de souscription: le client souscrit auprès du microservice et il est notifié au déclenchement d’un évènement.
- Mécanisme d’observation: le client fait du polling auprès du microservice sur lequel il a effectué un appel. Le client déclenche lui-même ses actions en fonction de ce qu’il a découvert pendant le polling.
Tolérer les échecs partiels
Les microservices sont de petites applications conçues pour être autonomes. Pourtant pour effectuer un traitement, microservice peut devoir faire appel à d’autres services et ainsi de suite. Si les services appelés ne sont pas en mesure de répondre ou si une partie du réseau est en défaut, le microservice ne sera pas en mesure d’effectuer son traitement et ne répondra pas à son tour à une requête qui lui a été adressée. Un défaut dans un service de bas niveau peut, ainsi être propagé à d’autres services de plus haut niveau mettant en péril toute l’application.
L’implémentation d’un microservice doit donc tolérer les échecs lors des appels à d’autres microservices. Il faut prendre en compte les scénarios d’échecs lors des appels pour ne pas propager l’échec et donner une réponse même si le traitement n’a pas abouti. Une première approche est d’être en mesure de détecter un échec lors d’un appel à travers le réseau en mettant en place des timeouts.
Quand l’échec est détecté, il faut implémenter une logique en rapport avec les impératifs du contexte fonctionnel. Par exemple, dans certains cas il peut être inutile de répéter une requête car les paramètres de la requête peuvent être obsolètes en cas d’appels répétés. Dans d’autres cas, on peut se permettre d’effectuer de nouvelles tentatives. Quel que soit la solution implémentée, il faut avoir une logique pour le cas le plus défavorable. Ainsi dans le cas de requêtes répétées et non traitées, il faut prévoir un nombre maximum de requêtes en défaut et avoir un traitement particulier si ce nombre est atteint comme, par exemple, considérer le service appelé comme inaccessible et ne plus envoyer de requêtes vers ce service.
Pattern “circuit breaker”
Le pattern circuit breaker vise à apporter une solution homogène lors d’échecs dans les appels entre microservices. La solution consiste à placer entre les microservices un composant appelé circuit breaker. Ce composant analyse les appels d’un microservice à l’autre et détecte les cas où un appel n’a pas abouti.
Dans le schéma suivant, on peut voir que le circuit breaker se place entre le client et le service (appelé supplier sur le schéma) et sert d’intermédiaire entre les appels du client au service. Dans le cas où les appels aboutissent, le circuit breaker n’effectue aucun traitement particulier. En revanche, s’il détecte un appel non abouti vers un service après un timeout, il “ouvre” le circuit pour que les futurs appels vers ce service ne soit plus effectués. Le circuit breaker répondra systématiquement par un échec pour les appels suivants au service (mécanisme de heartbeat).
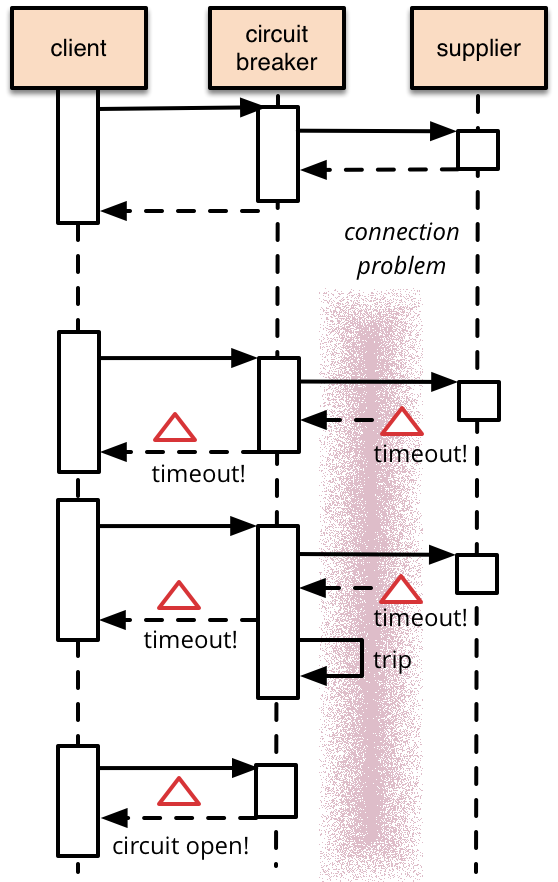
Dans des implémentations plus sophistiquées, le circuit breaker peut effectuer des appels vers le service en défaut pour détecter s’il redevient opérationnel de façon à refermer le circuit et à rediriger, à nouveau, les appels.
L’interruption des appels par le circuit breaker peut se faire lorsque les requêtes en échec dépasse un certain seuil et pas forcément à partir du premier appel non abouti. Le circuit breaker peut aussi indiquer à des outils de monitoring qu’un service est en défaut.
| Netflix Hystrix est un exemple d’implémentation du pattern circuit breaker en java. Hystrix est disponible sur Github. |  |
Chef d’orchestre ou chorégraphie
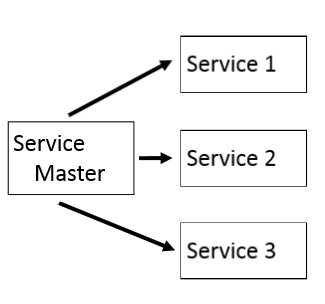
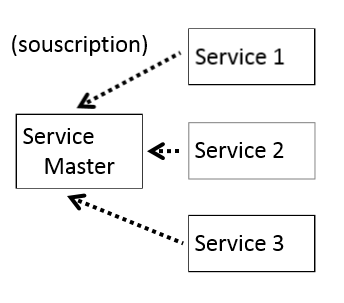
Dans le cas de workflows, un traitement peut nécessiter d’appeler successivement plusieurs microservices. La logique de ces workflows peut être implémentée de 2 façons dans le service appelant:
|
 |
|
 |
Dans le cas du chef d’orchestre, l’ordonnancement entre microservices est plus facile à implémenter et se fait directement dans le service master. Cette implémentation donne la possibilité d’effectuer des appels synchrones aux services, ainsi on peut facilement stopper le workflow si un appel à un service n’aboutit pas.
L’inconvénient majeur de cette approche est que le service master connaît tous les services qu’il doit appeler et la logique d’ordonnancement est implémentée directement dans le service ordonnanceur.
Cette connaissance des autres services augmente le couplage entre service puisque il peut être nécessaire de modifier l’ordonnanceur si une interface change dans les services appelés.
La chorégraphie est plus complexe à implémenter que le mécanisme de chef d’orchestre. Dans le cas de la chorégraphie, il peut être plus difficile d’interrompre le workflow en cas d’erreurs, en particulier si le déclenchement des évènements se fait de façon asynchrone. De même avec ce type de mécanisme, il est plus complexe d’effectuer un ordonnancement entre les services en fonction des évènements déclenchés.
L’intérêt du mécanisme en chorégraphie est que le service master n’a pas de connaissances des services appelés. Il ignore aussi l’ordre dans lequel les services doivent effectuer leur traitement. Le service master se contente de déclencher des évènements et ce sont les services eux-mêmes qui ont la connaissance de savoir s’ils doivent s’exécuter ou non. Ainsi la chorégraphie permet de diminuer le couplage entre microservices.
Service discovery
Lorsque des microservices sont exécutés sur des machines différentes, il faut avoir certaines informations pour savoir comment appeler ces services comme l’adresse IP des services ou les ports de connexions. Dans le cas d’autoscaling où des instances de service sont rajoutées à “chaud”, comment savoir qu’une nouvelle instance est active ?
Toutes ces problématiques peuvent se résoudre de 2 façons:
- En connaissant la configuration des services en avance pour savoir comment les appeler ou
- Découvrir cette configuration “à chaud” c’est-à-dire pendant l’exécution sans la connaître au préalable.
Connaître la configuration des services en avance
Cette solution est la plus rapide à implémenter et convient bien dans le cas où il n’y a pas beaucoup d’instances de services et que la topologie des services ne change pas. Dans le cas où la configuration change fréquemment, avoir les paramètres de connexion des services avant exécution peut être assez contraignant car le moindre changement peut nécessiter le redémarrage des services et l’interruption de l’application.
Ce type de configuration peut rendre plus difficile l’assignation dynamique d’une adresse IP aux différents services, par exemple, pour assurer des fonctions comme l’autoscaling ou le load-balancing. D’une façon générale, configurer les paramètres des connexions en avance nécessite d’indiquer ces paramètres dans la configuration des services. Cette connaissance des paramètres amène un couplage des clients à leurs services.
Pattern “client-side discovery”
Découvrir la configuration des services à l’exécution permet une affectation dynamique des paramètres de connexion. Un exemple de mécanisme permettant la configuration “à chaud” est le pattern client-side discovery. Ce mécanisme nécessite un service qui référence les paramètres de connexion des autres services.
- Dans un premier temps, chaque service indique sa configuration auprès du service registry qui va la conserver.
- Chaque client souhaitant effectuer une requête auprès d’un service, doit au préalable récupérer la configuration auprès du service registry.
- Le client fait ensuite appel directement au service avec les paramètres qu’il a obtenu après avoir interrogé le service registry.
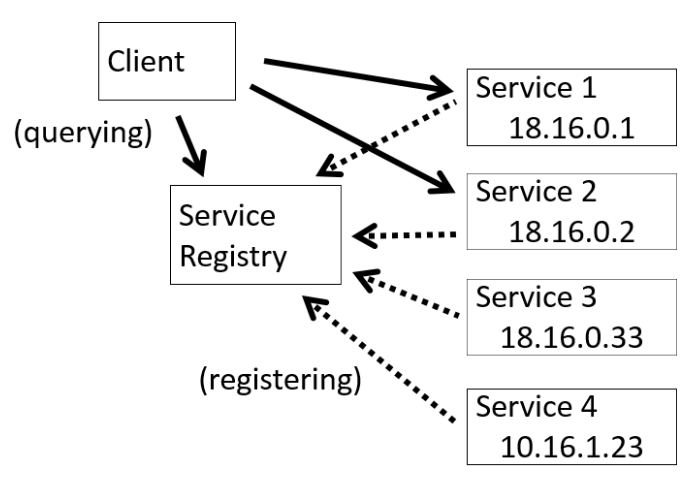
Ce mécanisme permet l’implémentation d’algorithmes de load-balancing directement dans le client. Le client peut effectuer une requête à une instance particulière d’un service en fonction de la charge. L’inconvénient du pattern client-side discovery est que les logiques de connexion au service et le load-balancing sont implémentées dans chaque client. Il n’y a pas un composant qui effectue ce traitement de façon homogène pour tous les clients.
Il existe des exemples d’implémentation du pattern client-side discovery dans Netflix OSS (Netflix Open Source Software) disponible sur GitHub:
|
 |
Pattern “server-side discovery”
Le pattern server-side discovery ajoute un composant par rapport au pattern client-side discovery. Un router est ajouté pour servir d’intermédiaire entre le client et les services. Le client ne fait plus appel directement aux services:
- Dans un premier temps, le client appelle le router dans le but d’effectuer une requête auprès d’un service.
- Le router effectue une requête auprès du service registry pour récupérer les paramètres de connexion du service.
- Le router appelle, ensuite, directement les services avec la requête du client.
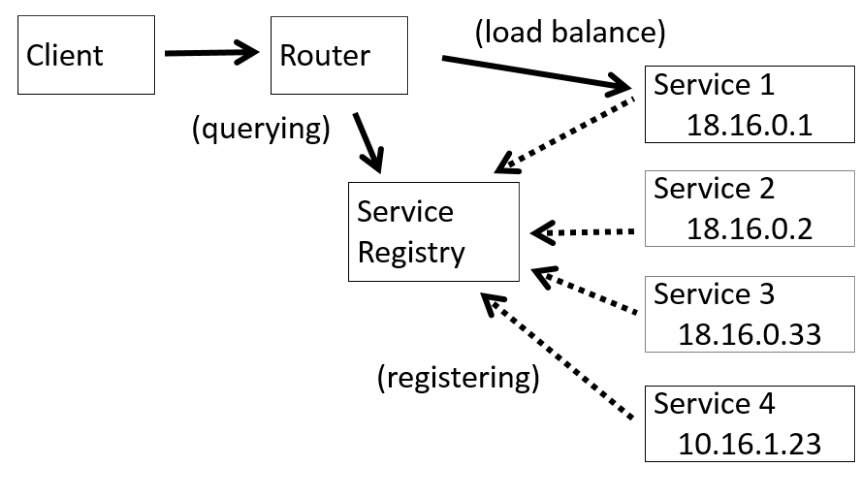
Les autres mécanismes sont les mêmes que pour le client-side discovery c’est-à-dire:
- Les services enregistrent leur configuration auprès du service registry,
- Seulement le service registry possède la configuration des services.
L’intérêt du server-side discovery est de permettre l’implémentation de l’algorithme de load balancing à un seul endroit c’est-à-dire dans le router. Il n’est pas nécessaire d’implémenter le load-balancing dans chaque client.
Il existe quelques exemples de router:
|
|
|
|
 |
 |
Exemples de service registry:
|
 |
|
 |
|
 |
Quelques technologies utilisées pour les appels
Il est possible d’utiliser une multitude de technologies pour effectuer des appels entre microservices. Le choix de la technologie doit correspondre aux besoins toutefois d’une façon générale:
- Il faut éviter d’utiliser des middlewares propriétaires qui dirigent trop l’implémentation des microservices.
- Il faut prendre en compte les risques liés au réseau
- Il faut distinguer les technologies synchrones et asynchrones.
Les techonologies les plus couramment utilisées dans le cas de communications synchrones sont:
- REST over HTTP
- Apache Thrift (RPC)
Dans le cas de communications asynchrones par message:
Outre le protocol utilisé, il faut aussi faire un choix sur le format des messages:
- Format texte: les formats XML et JSON sont couramment utilisés.
- Format binaire: on peut considérer Apache Avro ou Protocol Buffers.
Communications asynchrones par messagerie
Il existe beaucoup d’implémentations permettant des communications par messagerie:
 |
 |
|
 |
Toutes ces implémentations permettent une plus grande flexibilité que les communications synchrones classiques:
- Découplage entre les clients et les services: le client envoie sa requête sur un canal sans connaître le service qui va la traiter. Il n’y a pas de mécanismes pour chercher le service.
- Message tampon: les messages sont placés dans des files d’attente et seront traités de façon asynchrone par le service même s’il n’est pas disponible au moment de l’envoi du message.
- Interactions flexibles entre les clients et les services: la plupart des mécanismes sont supportés.
- Communications interprocessus explicites: il n’y a pas de différences entre un appel à un service local ou à distance.
Ces technologies offrent plus de flexibilité toutefois elles sont plus complexes à mettre en œuvre car il faut installer un agent de messagerie et il faut configurer les communications.
D’autres part, les communications request/response deviennent complexes à mettre en œuvre car les communications se font par des canaux qui sont identifiés avec des ID. Le client doit corréler sa requête avec la réponse en utilisant l’ID du canal.
Communications synchrones
Le mécanisme le plus courant utilisé est celui permettant d’effectuer des appels request/response entre le client et le service. Le protocole utilisé est souvent REST over HTTP.
Certaines solutions permettent d’effectuer des appels request/response de façon asynchrone sans passer par des solutions de messagerie, par exemple:
- Par programmation par évènements avec les Futures en Scala ou Rx Observables de Reactive Extensions
- Par implémentation de mécanismes de files d’attente avec RestMS ou IronMQ.
REpresentational State Transfer (REST)
On parle souvent de REST pour effectuer des appels entre microservices en le qualifiant de protocole. Il s’agit d’un abus de langage car REST n’est ni un protocole, ni une norme. REST a été introduit dans la thèse de Roy Fielding qui le définit comme un style d’architecture imposant des contraintes. Ces contraintes concernent différents points:
- Communication Client-Serveur: le client est séparé du serveur.
- Communication sans état: une requête doit contenir toutes les informations nécessaires à son exécution. Le serveur ne doit pas stocker de données de contexte.
- Mise en cache: une réponse du serveur contient des informations pour que le client puisse mettre en cache la réponse. Ces informations peuvent être considérées comme la durée de validité de la réponse.
- Des interfaces uniformes: les interfaces permettent d’identifier les ressources disponibles. La manipulation de ces ressources doit se faire au travers d’une représentation. Les messages doivent être autodescriptifs c’est-à-dire qu’ils doivent suffire à comprendre les informations qu’ils contiennent.
- Système hiérarchisé en couches: un client peut se connecter à un serveur final ou à un intermédiaire sans qu’il s’en aperçoive. Le fait de passer par un intermédiaire doit être transparent pour le client. Cette contrainte permet d’effectuer du load-balancing.
- Code-on-demand: cette contrainte permet d’exécuter des scripts récupérés à partir du serveur. Tous les traitements ne s’effectuent pas du coté du serveur.
On applique REST le plus souvent partiellement dans les appels entre microservices toutefois son intérêt est d’énoncer des contraintes s’appliquant à ces appels notamment:
- Le client est désolidarisé du serveur,
- Il n’y pas de gestion d’états,
- Une requête peut être répartie sur plusieurs serveurs,
- On peut utiliser HTTP
- Une API REST implémentée totalement n’a pas besoin de documentation,
- Le client peut “découvrir” les fonctionnalités proposées par l’API sans connaissances préalables.
REST over HTTP
REST over HTTP est un protocole utilisant HTTP. L’intérêt de HTTP est de mettre à disposition des éléments qui facilitent la mise en œuvre d’appels entre client et serveur:
- URL: une adresse qui permet d’indiquer l’adresse du microservice.
- Type MIME: les messages peuvent être de type différent, on peut indiquer le type dans l’entête des messages. Le plus couramment on utilise JSON ou XML.
- Verbes HTTP: ce sont des méthodes qui permettent des traitements particuliers:
GETpour effectuer des opérations de lecture d’une ressource,POSTpour créer une ressource,PUTpour mettre à jour une ressource etDELETEpour supprimer une ressource.
Les codes d’erreurs HTTP sont aussi très utiles puisqu’ils indiquent des codes de retours possibles pour les appels:
| Code | Message | Signification |
|---|---|---|
| 200 | OK | Succès pour toutes les méthodes sauf POST |
| 201 | Created | Réponse à un POST |
| 400 | Bad Request | Le contenu de la requête n’a pas été compris |
| 401 | Unauthorized | L’authentification a échouée |
| 403 | Forbidden | Authentification correcte mais l’utilisateur ne peut pas accéder à la ressource |
| 404 | Not Found | Le ressource n’a pas été trouvée |
| 429 | Too Many Requests | La limite de requêtes autorisées est dépassée |
| 500 | Internal Error | Problème interne au service |
| 503 | Service unavailable | Service non disponible |
API RESTful
Une API RESTful définit une API qui respecte toutes les contraintes définies par REST. La très grande majorité du temps, les API ne respectent pas l’intégralité de REST, elles prennent en compte quelques contraintes. De façon à mesurer le niveau de maturité d’une API avec REST, Leonard Richardson a défini 4 niveaux:
- Plus le niveau est élevé et plus l’API respecte les contraintes REST
- Plus le niveau est élevé et moins le client a besoin d’informations préalables pour envoyer sa quête au service.
- Plus le niveau est élevé et plus le couplage est faible.
Niveau 0
Les clients envoient des requêtes HTTP POST vers un seul point d’accès du service. Chaque requête contient:
- L’action à effectuer,
- L’objet cible sur lequel va porter l’action,
- Les paramètres nécessaires à l’exécution de l’action.
Ce niveau nécessite une connaissance du client pour pouvoir envoyer sa requête. Le client ne peut pas exécuter la requête sans savoir où indiquer les différents éléments.
Par exemple, si on souhaite récupérer une liste de livres en faisant appel à une API REST, une requête pourrait être:
POST /books HTTP/1.1
Content-Type: application/json
La réponse de l’API pourrait être:
{
"books": [
{
"title": "The Little Prince",
"id": "1",
"author": {
"firstname": "Antoine",
"lastname": "Saint-Exupery"
}
},
{
"title": "Madame Bovary",
"id": "2",
"author": {
"firstname": "Gustave",
"lastname": "Flaubert"
}
}
]
}
Pour supprimer un livre, la requête pourrait être:
POST /books HTTP/1.1
Content-Type: application/json
{
"delete": {
"book": [
{ "id": "1" }, { "id": "2" }
]
}
}
Quelque soit l’action a effectué, la méthode HTTP utilisée est POST. Le corps de la requête contient:
- l’action à effectuer c’est-à-dire:
delete; - l’objet cible à savoir:
booket - les paramètres nécessaires à l’exécution:
1et2.
Le client doit connaître la syntaxe de la requête pour pouvoir l’exécuter. Cette connaissance couple le client avec le service.
Niveau 1
L’API supporte la notion de ressource. Une ressource correspond à un élément sur lequel on souhaite effectuer une action. L’action peut être une création, une mise à jour, une suppression etc… Chaque requête à l’API REST concerne une ressource particulière.
Une requête contient:
- L’action à effectuer auprès de la ressource,
- Les paramètres nécessaires à l’exécution de l’action.
Chaque ressource comporte une identifiant rangé dans un champ dont le nom est Id. L’utilisation d’un nom de champ identique pour tous les identifiants permet d’éviter d’avoir une connaissance trop précise de la structure des ressources. On sait que quelque soit la ressource, l’identifiant sera rangé dans un champ dont le nom est Id.
Par exemple, pour avoir la liste des livres, une requête pourrait être:
POST /books HTTP/1.1
Content-Type: application/json
La réponse de l’API pourrait être:
{
"books": [
{
"title": "The Little Prince",
"id": "1",
"authorId": "antoine_saint_ex"
},
{
"title": "Madame Bovary",
"id": "2",
"authorId": "gustave_flaubert"
}
]
}
Les auteurs sont une ressource différente de celle des livres. La liste des livres ne comprends pas de données sur les auteurs, seuls les identifiants des auteurs sont utilisés. Les données sur les auteurs peuvent être obtenues en effectuant une requête spécifique pour les auteurs.
Pour obtenir des informations sur un auteur, on pourrait effectuer une requête:
POST /author?id=antoine_saint_ex HTTP/1.1
Content-Type: application/json
La réponse contient les données de l’auteur avec un champ Id pour indiquer l’identifiant de l’auteur:
{
"author": {
"id": "antoine_saint_ex",
"firstname": "Antoine",
"lastname": "Saint-Exupéry"
}
}
Pour ce niveau, le client doit aussi connaître des éléments de syntaxe de la requête pour pouvoir l’exécuter. Toutefois certaines données comme, par exemple, les identifiants sont indiquées en utilisant un nom moins spécifique.
Niveau 2
Les requêtes effectuées utilisent des verbes HTTP pour indiquer l’action à effectuer:
GETpour une lecture,POSTpour une insertion,PUTpour une mise à jour etDELETEpour une suppression.
Comme pour les autres niveaux, les paramètres se trouvent dans le corps de la requête. A ce niveau, on utilise les codes de retours HTTP dans les réponses aux requêtes.
Par exemple, pour obtenir la liste de livres:
GET /books HTTP/1.1
Pour obtenir un auteur particulier:
GET /author?id=1 HTTP/1.1
Pour supprimer un livre:
DELETE /books?id=2 HTTP/1.1
A ce niveau, l’API paraît plus uniformisée. Il n’y a pas de connaissances à avoir sur la syntaxe des requêtes:
- L’utilisation des verbes HTTP indiquent l’action à effectuer,
- L’organisation en ressource permet d’avoir une logique qui est la même quel que soit le type d’objet.
Niveau 3
Une API satisfaisant ce niveau est basée sur le principe HATEOAS (Hypertext As The Engine Of Application State). HATEOAS est une contrainte qui permet d’indiquer dans la réponse à une requête GET, toutes les autres opérations possibles sur l’API. Ces opérations sont indiquées sous forme de lien hypertext dans le corps de la réponse.
Par exemple, si on envoie une requête pour obtenir la liste de livres:
POST /books?id=1 HTTP/1.1
Un exemple de réponse de niveau 3 pourrait être:
{
"book":
{
"title": "The Little Prince",
"id": "1",
"authorId": "antoine_saint_ex",
"links": [
{
"rel": "self",
"href": "http://localhost:8080/books/1"
},
{
"rel": "list",
"href": "http://localhost:8080/books"
},
]
}
}
La réponse contient des liens qui permettent de parcourir les ressources de l’API. En s’aidant de ces liens, la connaissance nécessaire pour utiliser l’API est encore abaissée et on peut “découvrir” toutes les fonctionnalités de l’API sans connaissances préalables.
Niveau de maturité
L’intérêt des niveaux de maturité n’est pas forcément d’implémenter le niveau le plus élevé pour une API. Généralement le niveau 2 suffit, dans la majorité des cas, à avoir une API standardisée facilement utilisable.
Utiliser des niveaux de maturité pendant le développement d’une API permet de:
- Standardiser la syntaxe pour éviter aux clients d’avoir une connaissance préalable de cette syntaxe.
- Utiliser un même niveau de maturité pour toutes les API de l’application en microservices: l’intérêt est d’éviter d’implémenter des niveaux inutiles s’il y a une trop grosse différence de maturité entre les services.
Par exemple si un service implémente le niveau 3, et que tous les autres services implémentent le niveau 1, les clients de ce service peuvent ne pas utiliser les fonctionnalités des niveaux 2 et 3. Ce qui rend inutile l’effort d’implémentation jusqu’au niveau 3.
Il est donc préférable d’avoir un niveau de maturité homogène dans une application en microservices.
Eviter les “anemic domain models”
La notion de ressource peut donner l’impression que les services REST ne font pas de traitements fonctionnels sur des objets et qu’ils ne permettent que de publier le contenu de ces objets.
Dans l’exemple plus haut, les ressources sont les livres ou les auteurs. Le service REST ne sert qu’à consulter ces objets comme on pourrait l’effectuer dans une base de données. Ce type de service peut mener à des anemic domain models.
Un anemic domain model est une notion introduite par Martin Fowler pour qualifier un modèle qui ne possède pas de logique mais seulement des propriétés. Le modèle n’a donc aucune logique fonctionnelle et se contente d’exposer ses propriétés. Dans le cas de microservices, il faut éviter d’implémenter ce type de REST API car ils font perdre l’intérêt des microservices. Même s’il peut être utile d’avoir un niveau de maturité permettant d’exposer des ressources, ça ne veut pas dire que le service REST sera dépourvu de logique fonctionnelle. Les ressources ne traduisent pas forcément un objet en base mais juste une notion issue d’un traitement fonctionnel.
Par exemple, si on prends le cas d’un service permettant d’autoriser des “deals” de marché financier en fonction de certains critères. Les données relatives au “deal” sont fournies lors de la requête. Le service effectue des contrôles sur ce “deal” en fonction des données fournies et donne une réponse contenant éventuellement une autorisation. Dans ce cas, la ressource est l’autorisation du “deal”. Cette ressource correspond à une notion obtenue après un traitement fonctionnel.
Partie 1: Concevoir des microservices
Partie 2: Appels entre microservices