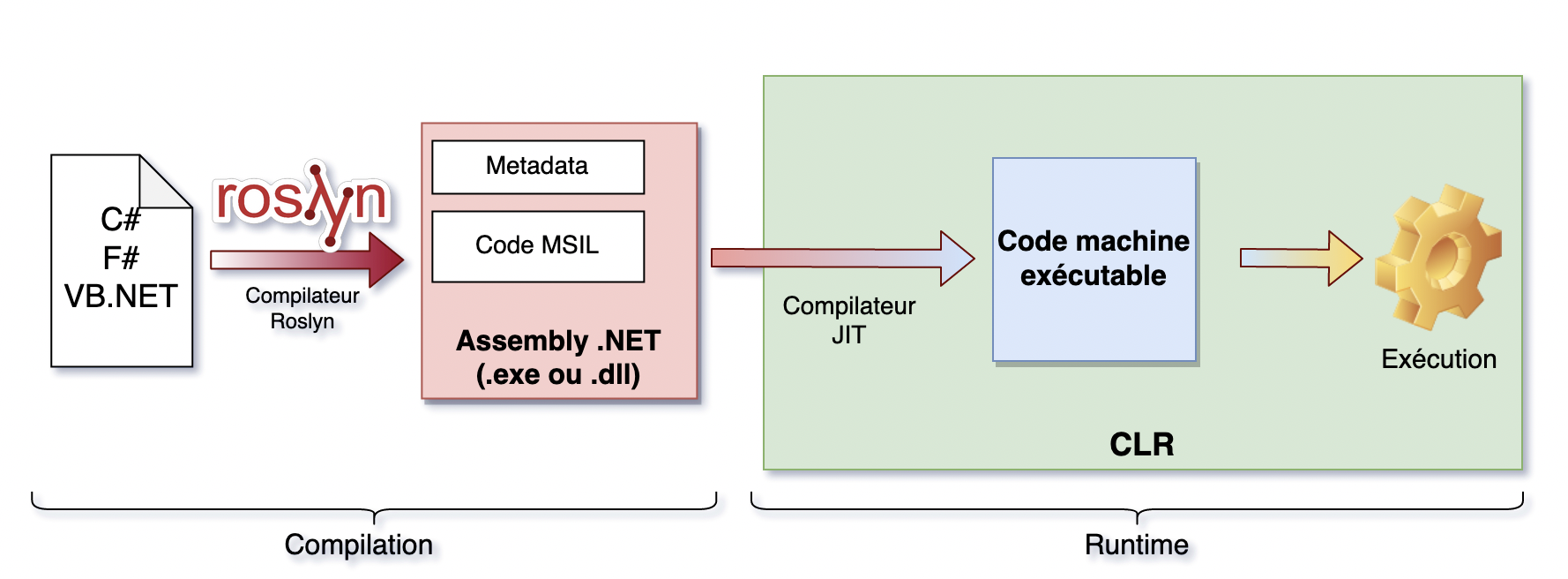
Le but de cet article est de résumer et d’expliquer les fonctionnalités de C# 10.0. Dans un premier temps, on explicitera le contexte de C# 10.0 par rapport aux autres composants (frameworks, IDE, compilateur etc…) qui permettent de l’utiliser. Ensuite, on rentrera dans le détail des fonctionnalités.
Les fonctionnalités les plus rapides à expliquer se trouvent dans cet article. Les autres fonctionnalités nécessitant davantage d’explications se trouvent dans des articles séparés.
Depuis C# 8.0, les évolutions fonctionnelles de C# se font pour .NET seulement (anciennement appelé .NET Core). Le framework .NET est toujours supporté toutefois les nouvelles fonctionnalités ne sont pas implémentées pour cet environnement.
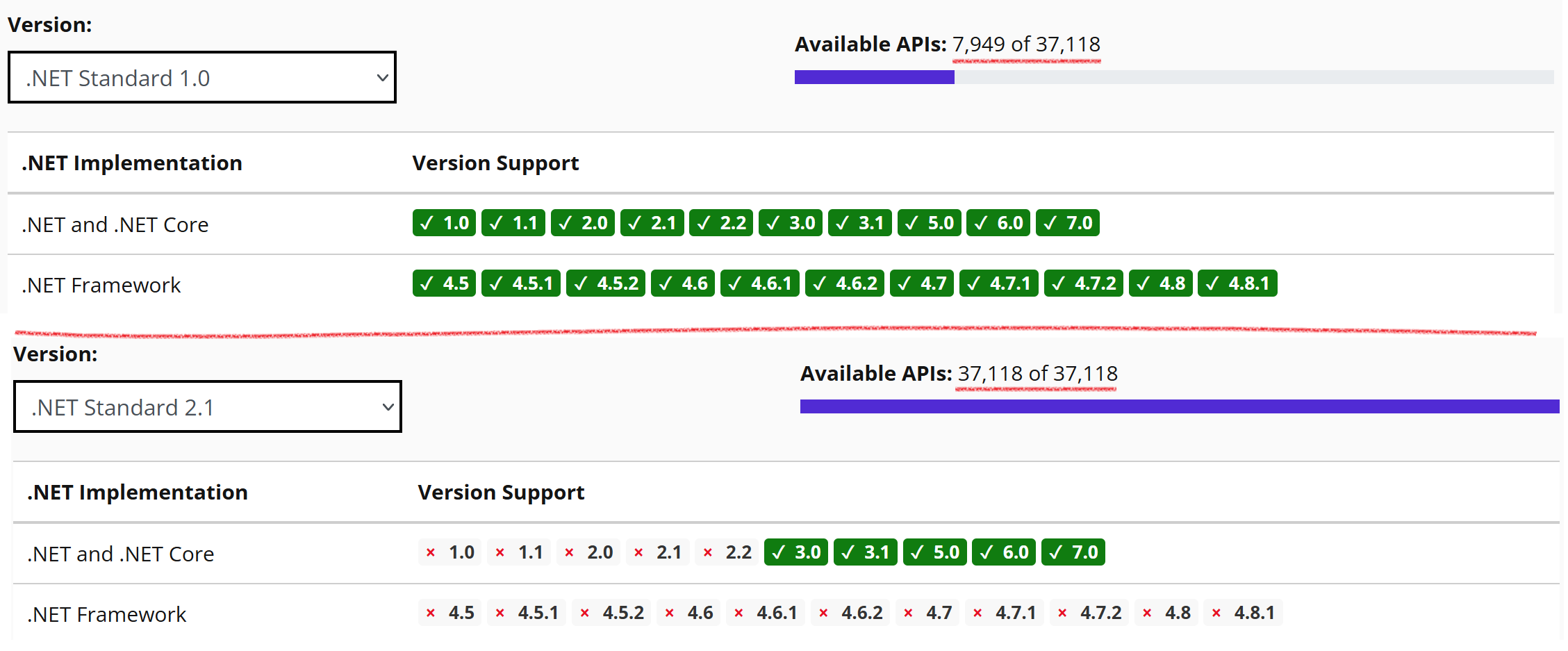
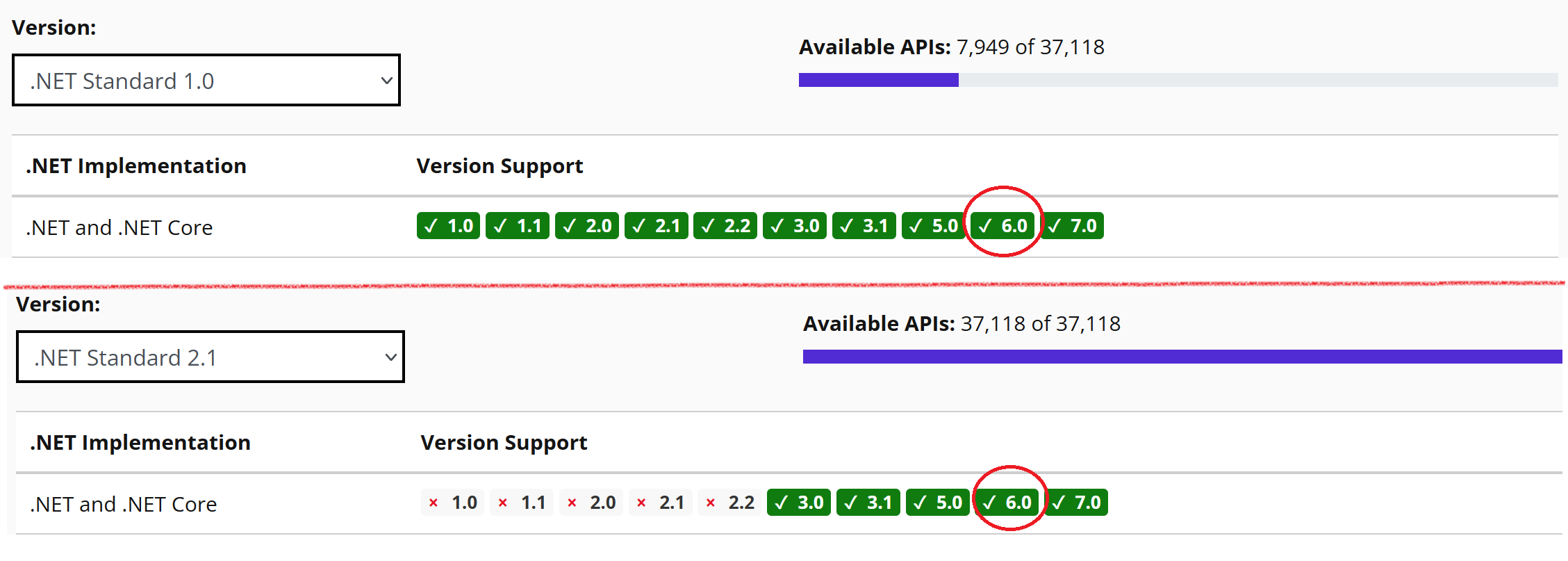
Comme les environnements du framework .NET et de .NET ne subsistent plus en parallèle, l’approche .NET Standard n’a plus d’intérêt. .NET Standard s’arrête donc à la version 2.1. Les versions 5.0, 6.0, 7.0 et 8.0 de .NET implémentent .NET Standard de la version 1.0 à 2.1 toutefois il est conseillé de cibler une version de .NET plutôt que .NET Standard.
Chronologie des releases
Ce tableau permet de résumer les dates de sorties de C# 10.0, de Visual Studio, du compilateur Roslyn et des versions .NET.
(2): Le framework .NET 4.8 est sorti en avril 2019
(3): .NET 4.8 est la dernière version du framework .NET. Les nouvelles fonctionnalités ne seront plus développées dans cet environnement.
(4): La dénomination .NET Core est remplacée par .NET. L’environnement correspondant au framework .NET s’arrête à la version 4.8. Les versions .NET 5.0 et supérieurs correspondent à l’environnement .NET Core.
(5): .NET Standard n’est plus nécessaire puisque les 2 environnements framework .NET et .NET Core n’évoluent plus fonctionnellement. Ils ont laissé place à l’environnement uniformisé .NET (voir .NET 5+ and .NET Standard pour plus de détails).
Lien entre la version C# et le compilateur
Le tableau précédent permet d’indiquer la version de C# dans le contexte des frameworks de façon à avoir une idée des sorties des autres éléments de l’environnement .NET. Toutefois, la version de C# est liée à la version du compilateur C#. Le compilateur est ensuite livré avec Visual Studio (depuis Visual Studio 2017 15.3) ou avec le SDK .NET.
Le chemin du compilateur est lié au composant avec lequel il est livré:
Avec Visual Studio: par exemple pour Visual Studio 2022 Professional: C:\Program Files (x86)\Microsoft Visual Studio\2022\Professional\MSBuild\Current\Bin\Roslyn\csc.exe
Avec les Build tools: par exemple pour les Build Tools for Visual Studio 2022: C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\MSBuild\Current\Bin\Roslyn\csc.exe
Avec le SDK .NET:
Sur Linux: /usr/share/dotnet/sdk/<version>/Roslyn/bincore/csc.dll
Sur Windows: C:\Program Files\dotnet\sdk\<version>\Roslyn\bincore\csc.dll
On peut connaître la version du compilateur en tapant:
csc -help
On peut savoir quelles sont les versions de C# que le compilateur peut gérer en exécutant:
csc -langversion:?
Limiter la version C# à compiler
Par défaut, le compilateur compile dans les versions suivantes de C#:
.NET 6.0: C# 10.0
.NET 5.0: C# 9.0
Framework .NET: C# 7.3
.NET Core 3.x: C# 8.0
.NET Core 2.x: C# 7.3
.NET Standard 2.1: C# 8.0
.NET Standard 2.0: C# 7.3
.NET Standard 1.x: C# 7.3
On peut volontairement limiter la version C# que le compilateur va traiter:
Dans Visual Studio: dans les propriétés du projet ⇒ Onglet Build ⇒ Advanced ⇒ Paramètre Language version.
En éditant directement le fichier .csproj du projet et en indiquant la version avec le paramètre LangVersion:
Les fonctionnalités les plus basiques de C# 10.0 sont présentées dans cet article. Les autres fonctionnalités nécessitant davantage d’explications sont présentées dans d’autres articles:
Pour simplifier la syntaxe des déclarations d’objets dans un fichier .cs, à partir de C# 10, il est possible d’indiquer le namespace auquel appartient l’objet en utilisant la déclaration:
namespace <nom du namespace>;
Cette déclaration est valable pour tous les objets déclarés dans le fichier, elle remplace la syntaxe avec les accolades. Ainsi la syntaxe suivante:
namespace CS10Syntax;
internal class FileScopedNamespaceDemo
{
}
Est équivalente à:
namespace CS10Syntax
{
internal class FileScopedNamespaceDemo
{
}
}
Lorsqu’on utilise une déclaration de namespace avec la portée du fichier, on ne peut pas effectuer plusieurs déclarations, une seule déclaration par fichier .cs est possible.
namespace CS10Syntax1;
internal class FirstClass
{
}
// ⚠ Cette 2e déclaration génère une erreur ⚠
namespace CS10Syntax2;
internal class SecondClass
{
}
De même l’emplacement de la déclaration du namespace a une importance, il faut qu’elle soit après les using... et avant la déclaration des objets:
// ⚠ Cette déclaration génère une erreur ⚠
namespace CS10Syntax1;
using System;
De même:
using System;
internal class SecondClass
{
}
// ⚠ Cette déclaration génère une erreur ⚠
namespace CS10Syntax1;
L’emplacement correct est:
using System;
namespace CS10Syntax1;
internal class SecondClass
{
}
Enfin il est possible d’utiliser la déclaration du namespace sans déclarer d’objets après:
using System;
namespace CS10Syntax1;
Motif property étendu (pattern matching)
Cette fonctionnalité vise à améliorer la syntaxe du property pattern dans le cadre du pattern matching.
Le motif property (i.e. property pattern) permet de tester des conditions sur les propriétés d’un objet dans le cadre du pattern matching.
Par exemple, si on considère les objets suivants:
public class Vehicle
{
public string Name;
public int PassengerCount;
public Engine Engine;
}
public class Engine
{
public string EngineType;
public int Horsepower;
}
Ensuite, on instancie 2 objets Vehicle de cette façon:
var fordMustang = new Vehicle { Name = "Ford Mustang", PassengerCount = 4, Engine = new Engine { EngineType = "V8", Horsepower = 480 } };
var renault4l = new Vehicle { Name = "Renault 4L", PassengerCount = 4, Engine = new Engine { EngineType = "Straight-four", Horsepower = 27 } };
Pour appliquer des conditions sur la propriété Name, on peut utiliser le code suivant:
var vehicle = fordMustang;
string engineSize = string.Empty;
if (vehicle.Name == "Ford Mustang")
engineSize = "Big engine";
else if (vehicle.Name == "Renault 4L")
engineSize = "Little engine";
else
engineSize = "No matches";
Si on utilise la syntaxe correspond au motif property:
Le motif property peut aussi être utilisé avec l’opérateur is, par exemple:
if (vehicle is Vehicle { Engine.EngineType:"V8" })
Console.WriteLine("Big engine");
else
Console.WriteLine("Little engine");
Amélioration des expressions lambda
Une série d’améliorations a été apportée aux expressions lambda pour faciliter leur utilisation. L’amélioration la plus utile est de permettre au compilateur d’essayer de déduire un type concret pour une expression lambda. La documentation évoque la notion de type naturel (i.e. natural type) toutefois il faut avoir en tête que dans l’absolu le terme “type”, dans ce cas, est utilisé de façon abusive puisqu’une expression lambda n’a pas, en soit, de type, il s’agit d’une déclaration sous la forme d’un delegate. Plus concrétement, quand on parle de Func<> ou Action<>, il ne s’agit pas de type mais de déclarations de delegate. Par abus de langage, on parle de “type” pour faciliter la compréhension ou pour évoquer le type delegate.
Avant de rentrer plus dans le détail de cette amélioration, on peut rappeler la définition de quelques termes.
Déduction du type de delegate
Delegate
Il s’agit du type d’une référence vers une méthode comportant une signature particulière. Le delegate définit donc le type de la référence et non pas la référence elle-même. Par exemple, en C# un delegate peut se déclarer de cette façon:
public delegate int AddDelegate(int a, int b);
La méthode suivante possède une signature compatible avec le delegate:
public static int Add(int a, int b)
{
return a + b;
}
On peut donc instancier le delegate et l’exécuter de cette façon:
AddDelegate delegateInstance = Add;
int result = delegateInstance(3, 5);
A partir du C# 2.0, il est possible d’avoir une notation plus directe pour déclarer les delegates:
AddDelegate delegateInstance = delegate(int a, int b)
{
return a + b;
};
Expression lambda
Une expression lambda est une notation permettant de créer des types de delegates ou d’arbres d’expression. Les expressions lambda sont déclarées en utilisant l’opérateur =>.
Si on prend l’exemple précédent, on peut utiliser une expression lambda pour déclarer le delegate:
AddDelegate delWithLambda = (a, b) => a + b;
Cette notation est un raccourci pour:
AddDelegate delWithLambda = (a, b) => { return a + b; };
Le delegate s’exécute de la même façon que précédemment:
int result = delWithLambda(3, 5);
Les expressions lambda sont apparues avec C# 3.0.
Action<T> et Func<T, TResult>
Action<T> et Func<T, TResult> sont des delegates prédéfinis pour faciliter l’utilisation de delegates et d’expression lambda. L’inconvénient de l’exemple précédent est qu’il nécessite la déclaration du delegateAddDelegate:
public delegate int AddDelegate(int a, int b);
Pour éviter de déclarer des delegates avant d’utiliser des expressions lambda, on peut utiliser Action et Func:
Action<T> correspond à des delegates de méthodes (pas de type de retour) de 0 ou plusieurs arguments.
Func<T, TResult> correspond à des delegates de fonctions de 0 ou plusieurs arguments avec un résultat.
Dans l’exemple précédent, si on utilise Func<T, TResult>:
Func<int, int, int> addWithFunc = (a, b) => a + b;
Une autre notation est équivalente (peu utilisée car plus lourde):
Func<int, int, int> addWithFunc = delegate(a, b) { return a + b; };
Les types de delegateAction<T> et Func<T, TResult> sont apparus avec le framework .NET 3.5.
Expression
En C#, le type Expression désigne un objet permettant de représenter une expression lambda sous la forme d’un arbre d’expressions (i.e. expression tree). Ce type se trouve dans le namespaceSystem.Linq.Expressions, il s’utilise sous la forme:Expression<Func<TResult>> ou Expression<TDelegate> où TDelegate est un delegate déclaré au préalable.
Ainsi Expression<Func<TResult>> correspond à la représentation fortement typée d’une expression lambda, elle ne contient pas seulement sa déclaration mais aussi toute sa description. Expression<TDelegate> dérive de la classe abstraite System.Linq.Expressions.LambdaExpression qui correspond à la classe de base pour représenter une expression lambda sous forme d’un arbre d’expressions:
public sealed class Expression<TDelegate> : LambdaExpression
C# 10.0
Déduction du “type” de l’expression lambda
Précédemment lorsqu’une expression lambda était déclarée, il fallait explicitement indiquer quel était le nom du delegate utilisé. Par exemple si on considère l’expression lambda suivante:
Func<int, int, int> addWithFunc = (a, b) => a + b;
Le delegateFunc<int, int, int> est précisé explicitement. Avant C# 10, cette précision était obligatoire. A partir de C# 10, on peut utiliser var et laisser le compilateur déduire une déclaration de delegate. On peut désormais écrire:
var addWithFunc = (int a, int b) => a + b;
Implicitement le compilateur va considérer addWithFunc comme étant un delegateFunc<int, int, int>.
Func<> n’est pas un type mais une déclaration de delegate
Malgré le fait qu’on utilise le mot-clé var, il faut avoir en tête que le compilateur ne déduit pas un type possible pour l’expression lambda mais une déclaration de delegate. Par abus de langage, la documentation parle de Func<> comme étant un type de delegate toutefois il s’agit de la déclaration d’un delegate parmi d’autres. Par opposition à un type qui est précis, il peut exister une infinité de ces déclarations de delegate.
Par exemple, si on déclare le delegate suivant:
public delegate int AddDelegate(int a, int b);
Alors on peut aussi écrire:
AddDelegate addWithFunc = (a, b) => a + b;
Dans l’absolu, Func<int, int, int> et AddDelegate ne sont donc pas des types mais 2 déclarations différentes d’un même delegate toutefois dans la documentation, on parlera de type de delegate.
Dans le cadre de cette amélioration, le compilateur déduit une déclaration sous la forme Func<> ou Action<> quand cela est possible. Dans certains cas, il n’est pas possible de déduire un delegate précis, par exemple:
var addWithFunc = (a, b) => a + b;
Dans ce cas, il n’est pas possible de déduire le type des arguments a et b.
Pour que la déclaration précédente soit possible, il faut préciser les types de a et b:
var addWithFunc = (int a, int b) => a + b;
De la même façon, il peut être impossible de déduire le type de retour, par exemple:
var compareInt = (int a, int b) => a > b ? 1 : "not";
Le type de retour peut être un entier ou une chaîne de caractères, il faut préciser explicitement le type de retour pour que le compilateur puisse déduire le type de delegate:
var compareInt = object (int a, int b) => a > b ? 1 : "not";
Le type de delegate sera alors Func<int, int, object>.
object et System.Delegate
Si on précise explicitement les types object ou System.Delegate à la place de var, le compilateur peut aussi considérer ces types plus généraux plutôt que les types de delegate:
Delegate addWithFunc = (int a, int b) => a + b;
ou
object addWithFunc = (int a, int b) => a + b;
Appliquer des attributs aux expressions lambda
C# 10.0
A partir de C# 10, on peut désormais appliquer des attributs sur les arguments et la valeur de retour d’une expression lambda.
Par exemple si on considère l’expression lambda suivante:
var addWithFunc = (int a, int b) => a + b;
Le type de cette expression lambda est Func<int, int, int>.
On déclare l’attribut suivant applicable sur les arguments d’une méthode et sur une valeur de retour d’une fonction (grâce à l’attribut System.AttributeUsage):
[AttributeUsage(AttributeTargets.ReturnValue | AttributeTargets.Parameter)]
public class CustomAttribute: Attribute
{
public CustomAttribute(string innerProperty)
{
this.InnerProperty = innerProperty;
}
public string InnerProperty { get; set; }
}
Si on redéclare l’expression lambda en l’aggrémentant d’attributs:
var addWithFunc = [return: CustomAttribute("Lambda return attribute")]
([CustomAttribute("1st param")] int a, [CustomAttribute("2nd param")] int b) => a + b;
Dans la classe CustomAttribute, on ajoute les fonctions statiques suivantes pour récupérer les attributs s’ils sont présents:
[AttributeUsage(AttributeTargets.ReturnValue | AttributeTargets.Parameter)]
public class CustomAttribute: Attribute
{
// ...
public static IDictionary<string, CustomAttribute?> FindArgumentCustomAttributes(Delegate func)
{
return func.Method.GetParameters()
.Where(p => p.Name != null)
.ToDictionary(p => $"{p.Name}", p => p.GetCustomAttribute<CustomAttribute>());
}
public static CustomAttribute? FindReturnValueCustomAttributes(Delegate func)
{
return func.Method.ReturnParameter.GetCustomAttribute<CustomAttribute>();
}
}
On peut récupérer la valeur de ces attributs en exécutant:
var addWithFunc = [return: CustomAttribute("Lambda return attribute")]
([CustomAttribute("1st param")] int a, [CustomAttribute("2nd param")] int b) => a + b;
var argumentCustomAttributes = CustomAttribute.FindArgumentCustomAttributes(addWithFunc);
foreach (var argumentAttribute in argumentCustomAttributes)
{
if (argumentAttribute.Value != null)
Console.WriteLine($"{argumentAttribute.Key}: {argumentAttribute.Value.InnerProperty}");
}
var returnValueCustomAttribute = CustomAttribute.FindReturnValueCustomAttributes(addWithFunc);
if (returnValueCustomAttribute != null)
Console.WriteLine(returnValueCustomAttribute.InnerProperty);
On obtient le résultat:
a: 1st param
b: 2nd param
Lambda return attribute
Permettre l’affectation et la déclaration de variables lors d’une déconstruction de tuple
Les tuples sont apparus avec le framework .NET 4.0 (voir Tuple et ValueTuple (C# 7) pour plus de détails), ce sont des structures de données permettant de stocker un nombre variable d’objets de type différent. L’intérêt est d’éviter à avoir à déclarer la structure explicitement. Les objets sont stockés dans les membres du tuple. Les tuples sont des objets de type System.Tuple qui sont des objets de type référence.
Le type et le nombre de membres contenus dans le tuple sont indiqués à l’initialisation:
Tuple tuple = new Tuple(5, "5", 5.0f);
On peut aussi instancier un tuple de type System.Tuple en utilisant la syntaxe:
Tuple tuple = Tuple.Create(5, "5", 5.0f);
Historiquement, les membres contenant les objets sont .Item1, .Item2, …, .Item<N>:
var tuple = (ValueAsInt: 5, ValueAsString: "5", ValueAsFloat: 5.0f);
System.ValueTuple
A partir du framework .NET 4.7 est apparu le type System.ValueTuple permettant de créer des objets équivalent à System.Tuple. La principale différence entre ces 2 types est:
System.ValueTuple est une structure et permet donc, de créer des objets de type valeur.
System.ValueTuple est fonctionnellement très proche de System.Tuple. Par exemple, on peut initialiser des objets System.ValueTuple avec une syntaxe semblable en utilisant la méthode statique ValueTuple.Create():
var tuple = ValueTuple.Create(5, "5", 5.0f);
A partir de C# 7.0, on peut initialiser les objets de type System.ValueTuple de cette façon:
(int, string, float) tuple = (5, "5", 5.0f);
On peut nommer les membres comme pour les objets de type System.Tuple:
var tuple = (ValueAsInt: 5, ValueAsString: "5", ValueAsFloat: 5.0f);
A partir de C# 7.1, lors de l’initialisation d’un tuple, il n’est pas obligatoire de préciser le nom et le type des éléments du tuple si on l’initialise à partir de variables déjà existantes. Le nom et le type sont déterminés à partir des variables existantes:
int valueAsInt = 5;
string valueAsString = "5";
float valueAsFloat = 5.0f;
var tuple = (valueAsInt, valueAsString, valueAsFloat); // Le nom et le type des éléments du tuple
// sont déterminés en fonction des noms et types des variables.
Console.WriteLine(tuple.valueAsInt);
Console.WriteLine(tuple.valueAsString);
Console.WriteLine(tuple.valueAsFloat);
Déconstruction
La déconstruction permet d’affecter les membres d’un tuple dans des variables distinctes (ces syntaxes sont possibles pour les types System.Tuple et System.ValueTuple):
Dans le but d’apporter une réponse technique au besoin de pouvoir créer des applications web, Microsoft a développé la technologie ASP.NET quasi depuis les débuts de .NET. Quelques années plus tard, est arrivé ASP.NET MVC permettant de construire des pages web en utilisant le modèle Modèle-Vue-Controleur (MVC) de façon à permettre d’organiser le code lié à la GUI dans la vue et le code plus fonctionnel dans le controller. Lorsque .NET Core est apparu en 2016, ASP.NET MVC a été remplacé par ASP.NET Core. Avec l’arrêt du développement du framework .NET et le renommage de .NET Core en .NET en 2022, l’appelation ASP.NET Core a été abandonnée pour revenir à ASP.NET. Fonctionnellement ASP.NET regroupe des cas d’utilisations assez différents liés aux applications web: ASP.NET Web Forms, ASP.NET Web Pages, ASP.NET Web API etc… Même si la technologie sous-jacente est la même, chaque cas d’utilisation est adressé avec ces différents modèles de programmation.
Parmi ces modèles, ASP.NET Web API comme son nom l’indique, a pour but de créer des API Web. Il utilise la base ASP.NET MVC pour ne garder que les controllers qui répondent aux requêtes.
Les applications ASP.NET peuvent être construites en utilisant le design pattern Builder qui va permettre de rajouter et de configurer des fonctionnalités suivant son cas d’utilisation de l’application web.
Dans le cas d’ASP.NET, la classe IApplicationBuilder permet de rajouter des fonctionnalités à l’application et de les configurer.
Avec ASP.NET 6, quelques améliorations et changements ont été faits pour simplifier le code nécessaire pour créer une API. C’est dans ce cadre que sont apparues les API minimales.
Le but de cet article est de passer en revue les fonctionnalités les plus importantes des API minimales. L’objectif n’est pas de paraphraser la documentation officielle mais d’avoir rapidement une idée des caractéristiques et fonctionnalités des API minimales.
On peut créer une API minimale en exécutant avec le CLI .NET:
dotnet new web -o <nom du projet>
On obtient une application dont la quantité de code est très réduite:
var builder = WebApplication.CreateBuilder(args); # Instanciation de WebApplicationBuilder
var app = builder.Build(); # Instanciation de l'application web
app.MapGet("/", () => "Hello World!"); # Définition d'une réponse à la route GET à l'adresse "/"
app.Run(); # Exécution de l'API
Ce code permet d’implémenter en peu de code une API capable de répondre à une requête GET à l’adresse "/". Peu de lignes sont nécessaires pour implémenter l’API, il n’y a pas de lignes using pour indiquer les namespaces utilisés à cause de la fonctionnalité des namespaces implicites (C# 10).
Minimal API vs MVC
A partir de .NET 6 et ASP.NET 6, un effort de simplification a été fait pour ne pas être obligé d’utiliser MVC pour construire des applications web et des API. Que ce soit une application web ou une API, l’approche modulaire en utilisant le design pattern Builder (avec WebApplicationBuilder) permet de rendre une application ASP.NET facilement modifiable et rend aisé l’ajout de nouvelles fonctionnalités. L’intérêt étant d’avoir une application simple si on le désire, qui pourra facilement être perfectionnée par la suite suivant les besoins.
Par exemple, avec le CLI .NET, plusieurs possibilités pour créer une application ASP.NET:
dotnet new web pour créer une application web simple sous la forme d’une API minimale comme l’exemple précédent
dotnet new webapi pour créer une API avec des controllers.
dotnet new webapp ou dotnet new razor pour créer une application web avec des pages Razor.
dotnet new mvc pour créer une application web MVC (i.e. Model-View-Controller)
dotnet new angular ou dotnet new react pour créer une application Single Page (i.e. SPA), respectivement en Angular ou React.
L’ajout de fonctionnalités plus spécifiques au type d’application se fait avec l’objet WebApplicationBuilder ou WebApplication avec l’exécution de fonctions comme:
builder.services.AddControllers() pour gérer les controllers dans le cadre d’une API web
builder.Services.AddRazorPages() pour rajouter la gestion des pages Razor.
Comme on l’a vu précédemment, l’implémentation des API minimales est réduite de façon à minimiser la quantité de code nécessaire. Suivant son besoin, il faudra se poser la question de savoir si on souhaite implémenter une API minimale ou une application web.
Différences entre une API minimale et une application Web
Dans la documentation, une opposition est faite entre les API minimales et les API utilisant des controllers. De la même façon, on peut croire qu’il y a des grosses différences entre les API minimales, les applications Web utilisant Razor ou le modèle MVC. En réalité, toutes ces types d’application utilisent la même base de composants:
Microsoft.NETCore.App correspondant aux assemblies de .NET.
Microsoft.AspNetCore.App correspondant aux assemblies ASP.NET.
Le choix du type d’application se fait suivant les middlewares ou la configuration qui est faite par la suite. Il est très bien possible de combiner dans la même application tous les différents types d’applications. On peut très bien partir d’une API minimale qui ne répond qu’à un seul end-point et rajouter la gestion des controllers, puis la gestion des pages Razor etc…
Ainsi la version actuelle d’ASP.NET (version 7) a permis de concilier tous les différents types d’applications en implémentant des comportements différents au moment du routage d’une requête. La configuration de ce routage se fait avec des méthodes d’extensions qui ajoutent des fonctionnalités à l’application, par exemple:
MapRazorPages(this IEndpointRouteBuilder endpoints) dans Microsoft.AspNetCore.Mvc.RazorPages rajoute la gestion des pages Razor,
AddRazorPages(this IServiceCollection services) dans Microsoft.AspNetCore.Mvc ajoute les services utilisés par les pages Razor.
MapControllerRoute(this IEndpointRouteBuilder endpoints, ...) dans Microsoft.AspNetCore.Mvc.Core rajoute la gestion des controllers,
AddControllersWithViews(this IServiceCollection services) dans Microsoft.AspNetCore.Mvc pour ajouter les services utilisés par les vues dans le cadre du modèle MVC (Model-View-Controller).
Routing
Un des points clés des API minimales mais aussi des autres types d’applications est le routing. C’est un des composants le plus important qui permet de diriger les requêtes vers l’élément technique qui sera chargé de son exécution: cet élément technique peut être une expression lambda, une fonction, un controller, un middleware technique ou une page statique.
Paramètres dans la route
On peut paramétriser la route en indiquant des arguments, par exemple si on ajoute un paramètre:
app.MapGet("/order/{id}", (string id) => $"Returning order with id: {id}");
Par exemple, pour requêter cette route, on peut utiliser l’URL:
On peut indiquer des contraintes sur les paramètres d’une route pour limiter les types possibles des paramètres ou définir des réponses différentes suivant l’application de ces contraintes.
D’une façon générale, la contrainte peut être définie avec la syntaxe:
{<nom paramètre>:<contrainte>}
La contrainte peut être sur:
Le type du paramètre, par exemple pour indiquer qu’un paramètre doit être un entier, par exemple {orderId:int}.
D’autres types sont possibles:
bool: booléen,
datetime: date
float: nombre flottant
alpha: chaîne de caractères ne contenant que les caractères alphabétiques (de A à Z non sensible à la casse).
Taille d’une chaîne de caractères:
minlength(<taille minimum de la chaîne>): par exemple {firstName:minlength(2)}
maxlength(<taille maximum de la chaîne>): par exemple {firstName:maxlength(128)}
Dans le cadre des API minimales, les fonctions les plus immédiates pour implémenter des end-points sont:
EndpointRouteBuilderExtensions.MapGet() pour répondre à une requête GET,
EndpointRouteBuilderExtensions.MapPost() pour répondre à une requête POST,
EndpointRouteBuilderExtensions.MapPut() pour répondre à une requête PUT,
EndpointRouteBuilderExtensions.MapDelete() pour répondre à une requête DELETE,
EndpointRouteBuilderExtensions.MapPatch() pour répondre à une requête PATCH,
EndpointRouteBuilderExtensions.MapMethods() pour répondre à plusieurs types de requêtes
etc…
Ces méthodes permettent d’implémenter facilement une réponse à une requête, par exemple EndpointRouteBuilderExtensions.MapGet() permet de répondre à une requête GET. On indique le chemin de la route et le code à exécuter lorsque la route est sollicitée. Ce code peut être indiqué avec un delegate:
app.MapGet("/", delegate () { return "This is a GET response"; });
Par suite, une expression lambda:
app.MapGet("/", () => "This is a GET response");
Avec une expression lambda asynchrone:
app.MapGet("/", async () => { await Task.Run<string>(() => "This is a GET response"); });
Avec la méthode MapMethods() , on peut indiquer les méthodes auxquelles le end-point doit répondre sous forme d’une liste de chaines de caractères, par exemple:
app.MapMethods("/", new List<string> { "GET", "PATCH" }, () => "This is a GET response");
Une redirection d’URL: Results.Redirect("/newURL")
Un fichier (dans le cas d’un téléchargement): Results.File(<chemin du fichier>)
Injection de dépendances
L’injection de dépendances est aussi supportée pour les API minimales. Comme pour les applications ASP.NET, un moteur d’injection de dépendances est nativement fourni. Pour configurer des objets à injecter, il faut utiliser le membre WebApplicationBuilder.Services de type IServiceCollection qui dispose de quelques méthodes pour effectuer cette configuration suivant la durée de vie voulue des objets:
Transient (i.e. éphémère): les objets enregistrés de cette façon sont instanciés à chaque fois qu’ils sont injectés.
Scoped: la même instance de l’objet sera utilisée dans le cadre d’une même requête HTTP. Ainsi une nouvelle instance est créée pour chaque requête à l’API.
Singleton: les objets de ce type sont créés une seule fois et la même instance est utilisée pendant toute la durée de vie.
Il existe plusieurs façons de configurer un objet à injecter. Ces différentes méthodes correspondent à des surcharges différentes des méthodes utilisées pour configurer ces objets:
On indique seulement le type de l’objet lors de la configuration. L’objet sera identifié par ce type lorsqu’il doit être injecté.
On indique un type par lequel l’objet sera identifié et le type réel de l’objet à injecter. Le type réel de l’objet doit dériver du type utilisé pour l’identifier. Lors de l’injection, l’objet sera identifié par le type utilisé pour l’identification de l’objet.
On indique une interface par laquelle l’objet sera identifié et le type réel de l’object à injecter. Le type réel de l’objet doit satisfaire l’interface utilisée pour l’identifier. Lors de l’injection, l’objet sera identifié par l’interface.
Enfin il est possible d’utiliser des factories pour instancier l’objet. On indique l’interface avec laquelle l’objet sera identifié. Lors de l’injection, l’objet sera identifiée par l’interface et la factory sera appelée pour instancier l’objet.
Pour chaque durée de vie, la méthode pour configurer l’objet dans le moteur d’injection de dépendances est:
Transient: IServiceCollection.AddTransient()
Scoped: IServiceCollection.AddScoped()
Singleton: IServiceCollection.AddSingleton()
Par exemple, si on considère la classe et interface suivantes:
public interface IServiceToInject
{
string InnerMember { get; }
}
public class ServiceToInject: IServiceToInject
{
public string InnerMember => "Inner value";
}
Lors de la configuration d’une route, on peut utiliser le service par injection, par exemple:
app.MapGet("/order/{id}", (string id, IServiceToInject instance) => $"This ID is: {id} and Inner member value: {instance.InnerMember}");
Si on requête l’API à l’adresse https://localhost:7120/order/ALDSE3XD
Le retour sera:
This ID is: ALDSE3XD and Inner member value: Inner value
Middlewares
Dans une application ASP.NET, les middlewares correspondent à des portions de code qui peuvent être exécutées lorsqu’une requête HTTP est reçue par une application ASP.NET Core. Ces portions de code sont exécutées successivement. Lorsqu’un middleware écrit une réponse correspondant à la requête, les middlewares suivants ne sont plus exécutés. Ainsi lorsqu’une requête HTTP parvient à l’API web, les portions de code correspondant aux middlewares vont être exécutées successivement jusqu’à ce qu’un des middlewares écrive la réponse. L’appel successif des différents middlewares s’appelle un pipeline de middlewares. Les middlewares sont ordonnés dans le pipeline et ils sont exécutés dans le même ordre.
Comme les API minimales sont des applications ASP.NET, de nombreux middlewares sont directement disponibles. Pour les ajouter au pipeline de middlewares, il faut généralement utiliser une méthode d’extension avec IApplicationBuilder.
Pour résumer, par sécurité les browsers empêchent un même script d’effectuer des requêtes HTTP vers des origines différentes. Si une requête est effectuée vers une origine différente, par défaut, la requête sera bloquée par le browser. Dans le cas où des ressources nécessitent des requêtes dans une origine différente, il faut activer des requêtes multi-origines (CORS) de façon à relâcher un élément de sécurité du browser. Cette activation se fait par le serveur répondant à la requête en indiquant les origines vers lesquelles le browser doit autoriser des requêtes multi-origines. Ces indications se font en ajoutant dans le header de la réponse le champ: Access-Control-Allow-Origin avec la valeur correspondant à l’origine vers laquelle autoriser les requêtes.
Pour une explication plus complète, voir Cross-Origin Resource Sharing (CORS).
Dans le cadre d’une API, c’est donc cette API qui doit effectuer l’ajout du champ Access-Control-Allow-Origin. Le middleware CORS permet d’effectuer ce traitement. Ainsi si la requête reçue par l’API contient dans le header le champ: Origin avec une adresse à autoriser ou la wildcard"*" alors la réponse contiendra un champ Access-Control-Allow-Origin avec l’adresse autorisée si la configuration le permet.
Ainsi, sans activation du CORS, avec l’implémentation suivante:
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/order/{id}", (string id) => $"Order ID is: {id}");
app.Run();
Si on effectue une requête GET https://localhost:7120/order/45345 sans champ particulier dans le header, on obtient la réponse suivante:
Order ID is: 45345
Si on rajoute le champ Origin dans le header de la requête:
Origin
http://otherorigin.com
Pas de changement dans la réponse de l’API. A ce stade il n’y a pas d’activation du CORS.
Si on modifie l’implémentation de l’API:
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddCors(options =>
{
options.AddDefaultPolicy(
policy =>
{
policy.WithOrigins("http://otherorigin.com");
});
});
var app = builder.Build();
app.UseCors();
app.MapGet("/order/{id}", (string id) => $"Order ID is: {id}");
app.Run();
Si on effectue une requête sans champ Origin, la réponse de l’API ne comporte pas de champ particulier.
Si on rajoute le champ Origin dans la requête:
Origin
http://otherorigin.com
La réponse de l’API comporte 2 champs supplémentaires:
Access-Control-Allow-Origin
http://otherorigin.com
Vary
Origin
A ce stade le CORS est activé pour http://otherorigin.com.
Dans le cas où on veut activer le CORS pour toutes les URL, on peut configurer l’API en utilisant une wildcard"*":
Cet article fait partie d’une série d’articles sur les apports fonctionnels de C# 10.0.
A partir de C# 10 et .NET 6, 2 fonctionnalités permettent de limiter la répétition des using <namespace> en tête des fichiers C#:
l’opérateur global et
la propriété ImplicitUsings.
Ces 2 fonctionnalités visent à déclarer les namespaces une fois par projet de façon à ne pas avoir à répéter les déclarations dans tous les fichiers .cs.
Mot-clé global
A partir de C# 10, le mot-clé global a désormais 2 significations:
Utilisé en tant que mot-clé de cette façon global:: il est un alias pour désigner le namespace global par opposition à un namespace déclaré par le développeur dans son code. Le namespace global contient des types qui ne sont pas déclarés dans un namespace nommé. global:: permet de différencier 2 namespaces qui auraient le même nom et dont un des 2 ferait partie de code déclaré en dehors du code du développeur.
Par exemple, si on considère le code suivant:
namespace CS10_Example.System
{
public class Object
{ }
}
On peut utiliser cette classe de cette façon:
namespace CS10_Example
{
internal class GlobalKeywordExample
{
public void ExecuteMe()
{
var exampleInstance = new System.Object();
}
}
}
System.Object désigne la classe CS10_Example.System.Object. Si on veut instancier l’objet Object provenant du framework, on ne peut pas le faire sans passer par le mot-clé global:
var exampleInstance = new System.Object();
var objectInstance = new global::System.Object();
Dans cet exemple global::System.Object désigne bien l’objet object du framework.
A partir de C# 10, global est aussi utilisé en tant que modificateur de portée lorsqu’on déclare des namespaces. Lorsque global précède une déclaration using <namespace>, il permet d’étendre la portée de la déclaration à la portée du projet.
Ainsi si on déclare l’utilisation d’un namespace dans un fichier, en faisant précéder la déclaration avec global, la déclaration aura pour portée le projet:
global using CS10_Example.System;
On peut aussi déclarer de façon globale des alias avec une syntaxe du type:
global using Env = System.Environment;
L’intérêt est d’éviter de multiplier les déclarations des mêmes namespaces dans plusieurs fichiers .cs du projet. Une seule déclaration suffit.
Propriété ImplicitUsings
ImplicitUsings est une propriété du .csproj qui est apparu à partir de .NET 6 qui permet d’ajouter des déclarations globales de namespace dans un .csproj en fonction du type de projet créé. Si la propriété est activée, alors à la compilation, des déclarations du type suivant seront rajoutées:
global using global::<namespace du framework>;
Ces déclarations ont pour but d’éviter la multiplication des using <namespace> dans chaque fichier d’un projet.
Dans la pratique suivant le type du projet, les déclarations sont rajoutées dans un fichier se trouvant dans:
<répertoire du projet>\obj\<configuration>\<target framework>\<nom du projet>.GlobalUsings.g.cs
Par exemple si le projet s’appelle Cs10Example, que la configuration de compilation soit Debug et que le framework cible net6.0 alors le fichier sera:
global using global::System
global using global::System.Collections.Generic
global using global::System.IO
global using global::System.Linq
global using global::System.Net.Http
global using global::System.Threading
global using global::System.Threading.Tasks
En plus des déclarations précédentes, les namespaces implicites seront:
global using global::System.Net.Http.Json
global using global::Microsoft.AspNetCore.Builder
global using global::Microsoft.AspNetCore.Hosting
global using global::Microsoft.AspNetCore.Http
global using global::Microsoft.AspNetCore.Routing
global using global::Microsoft.Extensions.Configuration
global using global::Microsoft.Extensions.DependencyInjection
global using global::Microsoft.Extensions.Hosting
global using global::Microsoft.Extensions.Logging
Si la propriété ImplicitUsings n’est pas présente dans le fichier .csproj, la fonctionnalité est désactivée par défaut.
Désactiver ImplicitUsings
Pour désactiver ImplicitUsings, on peut soit supprimer la propriété du fichier .csproj (la valeur par défaut est désactivée), soit explicitement la désactiver avec la valeur disable:
Ajouter ou supprimer une déclaration using globale dans le .csproj
Il est possible d’ajouter ou de supprimer une déclaration using globale directement dans le fichier .csproj.
Pour effectuer une déclaration using globale dans le .csproj pour supprimer un namespace particulier, on peut utiliser la syntaxe:
Cette fonctionnalité permet d’apporter une solution pour faciliter et personnaliser l’interpolation de chaînes de caractères.
Avant C# 10.0, le traitement appliqué lors de l’interpolation de chaînes de caractères ne pouvait pas être modifié ni personnalisé. C# 10.0 introduit l’attribut InterpolatedStringHandler dans le but d’implémenter un traitement personnalisé lorsqu’une interpolation de chaînes de caractères est effectuée.
Interpolation de chaîne de caractères
Pour rappel l’interpolation de chaîne de caractères consiste à faciliter la construction d’une chaîne de caractères en permettant d’interpoler des expressions qui seront évaluées au moment de la construction de la chaîne.
Par exemple:
int wordCount = 5;
string interpolationExample = $"Ceci est un exemple contenant {2 * wordCount} mots provenant de la variable '{nameof(wordCount)}'";
interpolationExample contient la chaîne "Ceci est un exemple contenant 10 mots provenant de la variable 'wordCount'" qui provient de l’interpolation de 2 expressions:
2 * wordCount renvoyant 10 et
nameof(wordCount) renvoyant "wordCount".
Options d’alignement et de formatage
L’interpolation peut être affinée en utilisant d’autres options de construction des expressions interpolées. La forme générale des expressions est:
{<expression interpolée>[,<option d'alignement>][:<option de formatage>]}
Ainsi:
L’option d’alignement permet d’indiquer une constante correspondant au nombre minimum de caractères de l’expression.
Si la chaîne est trop courte et que la constante est positive: la chaîne sera alignée à droite et la longueur sera complétée par des espaces.
Si la chaîne est trop courte et que la constante est négative: la chaîne sera alignée à gauche et la longueur sera complétée par des espaces.
L’option de formatage suivant le type du résultat de l’expression permet d’apporter une indication sur le formatage à appliquer (voir Format string component pour des exemples d’options de formatage).
Par exemple, si on exécute:
string example1 = $"'{1,6}'"; // chaine de caractères trop courte, alignement à droite
Console.WriteLine(example1);
On obtient:
' 1'
Avec:
string example2 = $"'{1,-6}'"; // chaine de caractères trop courte, alignement à gauche
Console.WriteLine(example2);
On obtient:
'1 '
Avec:
string example3 = $"'{1234567,6}'"; // Chaîne assez longue, pas d'ajout de caractères
Console.WriteLine(example3);
Le résultat es:
'1234567'
Concernant l’option de formatage, l’option dépend du type de la valeur résultant de l’évaluation de l’expression. Si on considère un nombre décimal pour lequel on ne garde que 3 chiffres significatifs, on appliquera l’option de formatage '0.000' (voir les options de formatage des nombres):
Pour échapper les caractères { et }, il faut utiliser respectivement {{ et }}, par exemple:
int number = 5742;
string example5 = $"Le nombre {number} est affiché avec {{number}}.";
Console.WriteLine(example5);
Le nombre 5742 est affiché avec {number}.
Pour éviter que le caractère : ne soit évalué dans une expression comme une option de formatage, il faut entourer l’expression ternaire utilisant : avec ( et ). Par exemple:
int limit = 7;
string exemple6 = $"La limite est: {limit > 5 ? "haute" : "basse"}"; // ERREUR
string exemple6 = $"La limite est: {(limit > 5 ? "haute" : "basse")}"; // OK
Verbatim string
Dans une chaîne de caractères simple, on peut échapper les caractères spéciaux en utilisant @, par exemple pour le chemin d’un fichier:
Antérieurement à C# 10, l’interpolation de chaînes de caractères n’était pas possible pour les chaînes constantes toutefois il était possible d’effectuer des concaténations de chaînes constantes:
public const string constIntegerAsString = "5";
public const string stringInterpolationExample = $"Number {constIntegerAsString} is five !!"; // ERREUR avant C# 10
public const string constantStringExample = "Number " + constIntegerAsString + " is five !!"; // OK
La concaténation est possible car le compilateur construit une chaine de caractères unique à la compilation ce que n’était pas le cas de l’interpolation avant C# 10. Si on regarde le code MSIL correspondant à cette méthode:
public void ExecuteMe()
{
Console.WriteLine(constantStringExample);
}
On peut voir que la concaténation correspond à une chaîne constante:
.method public hidebysig instance void ExecuteMe() cil managed
{
// Code size 11 (0xb)
.maxstack 8
IL_0000: ldstr "Number 5 is five !!"
IL_0005: call void [System.Console]System.Console::WriteLine(string)
IL_000a: ret
}
Avec C# 10, le compilateur a été amélioré pour permettre les interpolations de chaînes constantes:
public const string constIntegerAsString = "5";
public const string stringInterpolationExample = $"Number {constIntegerAsString} is five !!"; // OK à partir de C# 10
Si on regarde le code MSIL de la méthode suivante, on peut se rendre compte que le code est identique à celui plus haut:
public void ExecuteMe()
{
Console.WriteLine(stringInterpolationExample);
}
De même que pour la concaténation, dans le cas de l’interpolation, le compilateur effectue la construction de la chaîne directement lors de la compilation.
L’interpolation pour une chaîne de caractères constante n’est possible que si l’interpolation est effectuée avec d’autres chaînes constantes. Il n’est pas possible d’effectuer une interpolation avec des variables dont le type nécessite une conversion.
Les exemples suivants génèrent une erreur de compilation:
public const int constInteger = 5;
public const string stringInterpolationExample = $"Number {constInteger} is five !!"; // ERREUR
L’interpolation "{constInteger}" nécessite une conversion d’un entier vers une chaîne de caractères qui doit être effectuée à l’exécution en prenant en compte les paramètres régionaux. Cette conversion ne peut être effectuée à la compilation.
Gestionnaire d’interpolation de chaînes de caractères
C# 10.0
C# 10.0 permet d’implémenter des classes qui peuvent effectuer des traitements personnalisés à la suite d’interpolation de chaînes de caractères. L’intérêt est d’être flexible sur le traitement effectué en utilisant les avantages de la syntaxe de l’interpolation de chaînes. Le traitement peut consister à construire une chaîne de caractères en utilisant les expressions à évaluer comme c’est le cas pour une interpolation de chaîne normale mais il n’est pas obligatoire de construire une chaîne de caractères.
L’implémentation de la classe correspondant à un gestionnaire de chaînes de caractères doit répondre à certaines conditions:
Le constructeur doit accepter au moins 2 arguments entier:
literalLength permettant d’indiquer la longueur de la chaine de caractères.
formattedCount indiquant le nombre d’éléments pour lesquels il faudra effectuer un traitement de formatage.
Une méthode publique void AppendLiteral(string s) pour ajouter une chaîne où aucun traitement n’est nécessaire.
Une méthode publique void AppendFormatted<T>(T t) acceptant un objet pour lequel un formatage est nécessaire.
Attribut InterpolatedStringHandler
A titre d’exemple, on considère les 2 objets suivants:
public class TwoDimensionPoint
{
public TwoDimensionPoint(int x, int y)
{
X = x;
Y = y;
}
public int X { get; set; }
public int Y { get; set; }
}
public class ThreeDimensionPoint
{
public ThreeDimensionPoint(int x, int y, int z)
{
X = x;
Y = y;
Z = z;
}
public int X { get; set; }
public int Y { get; set; }
public int Z { get; set; }
}
Si on souhaite générer une chaîne de caractères contenant les valeurs des membres de ces 2 classes, une première approche est de surcharger les fonctions ToString():
public class TwoDimensionPoint
{
// ...
public override string ToString()
{
return $"{X}; {Y}";
}
}
public class ThreeDimensionPoint
{
// ...
public override string ToString()
{
return $"{X}; {Y}; {Z}";
}
}
Avec cette implémentation, on doit surcharger ToString() pour les 2 objets. Si on a de nombreux objets pour lesquels on doit surcharger ToString(), cela peut rendre l’implémentation assez fastidieuse. Une autre approche pourrait être de rassembler le traitement de conversion en chaîne de caractères dans un seul objet.
Avec C# 10, avec un gestionnaire de chaînes de caractères il est possible d’implémenter une classe qui va gérer les interpolations de chaînes de caractères pour des types particuliers et ainsi permettre de rassembler les conversions en chaînes de caractères dans une seule classe. Ainsi si on considère la classe suivante dont les caractéristiques correspondantes aux conditions indiquées précédemment:
[InterpolatedStringHandler]
public class PointStringFormatter
{
StringBuilder builder;
public PointStringFormatter(int literalLength, int formattedCount)
{
builder = new StringBuilder(literalLength);
Console.WriteLine($"\tliteral length: {literalLength}, formattedCount: {formattedCount}");
}
public void AppendLiteral(string s)
{
builder.Append(s);
}
public void AppendFormatted<T>(T t)
where T: class
{
if (t is null)
AppendLiteral("null");
if (t is ThreeDimensionPoint threeDimensionPoint)
AppendLiteral($"{threeDimensionPoint.X}; {threeDimensionPoint.Y}; {threeDimensionPoint.Z}");
else if (t is TwoDimensionPoint twoDimensionPoint)
AppendLiteral($"{twoDimensionPoint.X}; {twoDimensionPoint.Y}");
else if (t is string)
AppendLiteral(t as string);
else
throw new InvalidOperationException($"{nameof(T)} is unknown");
}
public override string ToString()
{
return this.GetFormattedText();
}
internal string GetFormattedText() => builder.ToString();
}
Dans la méthode AppendFormatted(), on peut voir que la conversion des 2 types ThreeDimensionPoint et TwoDimensionPoint est gérée. Ainsi, dans le cas où il est nécessaire d’avoir une implémentation particulière pour un grand nombre de classes, il peut être plus aisé de rassembler les logiques de conversion dans une même méthode.
On peut améliorer l’implémentation de la méthode AppendFormatted() en utilisant le pattern matching plutôt que des if...then...else:
public void AppendFormatted<T>(T t)
where T: class
{
string pointAsString = t switch
{
ThreeDimensionPoint threeDimensionPoint => $"{threeDimensionPoint.X}; {threeDimensionPoint.Y}; {threeDimensionPoint.Z}",
TwoDimensionPoint twoDimensionPoint => $"{twoDimensionPoint.X}; {twoDimensionPoint.Y}",
null => "null",
string formattedString => formattedString,
_ => throw new InvalidOperationException($"{nameof(T)} is unknown")
};
AppendLiteral(pointAsString);
}
Si on définit la méthode suivante:
public void ShowPoint(PointStringFormatter point)
{
Console.WriteLine(point.GetFormattedText());
}
On peut utiliser directement la classe PointStringFormatter en exécutant:
var point1 = new ThreeDimensionPoint(4, 7, 9);
var point2 = new TwoDimensionPoint(4, 7);
ShowPoint($"{nameof(point1)}: {point1}");
ShowPoint($"{nameof(point2)}: {point2}");
Ainsi comme on peut le constater, l’instanciation de l’objet PointStringFormatter est effectuée à partir d’une chaîne de caractères à interpoler. De façon plus explicite, on pourrait écrire:
var point1 = new ThreeDimensionPoint(4, 7, 9);
PointStringFormatter pointFormatter = $"{nameof(point1)}: {point1}";
Console.WriteLine(pointFormatter); // Execution de PointStringFormatter.ToString()
Le résultat est le même que précédemment.
La même instance de PointStringFormatter peut servir pour les 2 types d’objets:
var point1 = new ThreeDimensionPoint(4, 7, 9);
var point2 = new TwoDimensionPoint(4, 7);
PointStringFormatter pointFormatter = $"{nameof(point1)}: {point1} / {nameof(point2)}: {point2}";
Console.WriteLine(pointFormatter);
On peut observer que l’instanciation d’un gestionnaire d’interpolation de chaînes de caractères peut se faire implicitement à partir d’une chaîne de caractères à interpoler. Ainsi, on peut facilement implémenter des comportements spécifiques pour:
Effectuer des conversions de classes en chaînes de caractères,
Faciliter des logs particuliers suivant des types d’objets,
Centraliser dans une même classe les conversions en chaînes de types d’objets différents.
Gestionnaire par défaut: DefaultInterpolatedStringHandler
Si on regarde le code MSIL correspondant au code suivant:
int number = 5742;
string example5 = $"Le nombre {number} est affiché avec {{number}}.";
Console.WriteLine(example5);
On peut y voir que le gestionnaire DefaultInterpolatedStringHandler est utilisé pour l’interpolation des chaînes de caractères. C’est le gestionnaire par défaut pour traiter les chaînes de caractères interpolées.
ref struct
Un intérêt d’utiliser un gestionnaire de chaînes de caractères interpolées est de prévoir une implémentation optimisée pour minimiser l’utilisation des ressources en particulier quand le gestionnaire est instancié fréquemment. Ainsi dans le cas où on implémente le gestionnaire sous la forme d’une classe, chaque instanciation va créer un objet dans le tas managé. En cas d’utilisation fréquente, le garbage collector pourrait être sollicité de façon répétée pour traiter les instances du gestionnaire à disposer.
Une optimisation permettant d’éviter des sollicitations du garbage collector serait d’utiliser une structure. En effet les structures étant, la plupart du temps, instanciées sur la pile, elles évitent une utilisation du garage collector en cas d’instanciation répétée.
Pour aller plus loin, on peut utiliser une ref struct qui va garantir que le structure ne peut être utilisée que sur la pile. En effet, apparu en C# 7.2, ref peut être utilisé quand on déclare un objet struct pour indiquer qu’une instance de la structure ne peut se trouver que dans la pile et ne pourra pas correspondre à une allocation dans le tas managé.
Dans le cadre de notre exemple, on peut modifier l’implémentation en utilisant une ref struct plutôt qu’une classe:
public ref struct PointStringFormatter
{
...
}
Attribut InterpolatedStringHandlerArgument
Dans le cas précédent, l’instanciation du gestionnaire de chaîne de caractères à interpoler a été effectuée juste avec un argument qui est la chaîne à interpoler. On peut ajouter des arguments lors de l’instanciation du gestionnaire en utilisant l’attribut InterpolatedStringHandlerArgumentAttribute.
Pour rappel, on peut instancier un gestionnaire:
Directement à partir d’une chaîne de caractères interpolées:
C’est en utilisant cette 2e méthode, qu’il est possible d’utiliser l’attribut InterpolatedStringHandlerArgument pour instancier le gestionnaire avec des arguments supplémentaires. Ainsi on considère une méthode avec plusieurs arguments en plus du gestionnaire, on utilise le attribut InterpolatedStringHandlerArgument pour indiquer quels sont les arguments à utiliser pour instancier le gestionnaire.
Par exemple, si on considère le gestionnaire PointStringFormatterV2 avec un constructeur avec 2 arguments supplémentaires par rapport à PointStringFormatter:
public ref struct PointStringFormatterV2
{
public PointStringFormatterV2(int literalLength, int formattedCount, string formattingPrefix, string formattingSuffix)
{
// ...
}
// ...
}
On définit la méthode suivante en ajoutant les arguments formattingPrefix et formattingSuffix. Puis on indique dans l’attribut InterpolatedStringHandlerArgument les arguments à utiliser pour instancier le gestionnaire:
Le constructeur du gestionnaire PointStringFormatterV2 sera instancié en utilisant les arguments formattingPrefix et formattingSuffix ayant respectivement les valeurs "(" et ")".
Dans le cadre de cet exemple, l’implémentation de PointStringFormatterV2 est:
[InterpolatedStringHandler]
public class PointStringFormatterV2
{
private StringBuilder builder;
private string formattingPrefix;
private string formattingSuffix;
public PointStringFormatterV2(int literalLength, int formattedCount, string formattingPrefix, string formattingSuffix)
{
builder = new StringBuilder(literalLength);
this.formattingPrefix = formattingPrefix;
this.formattingSuffix = formattingSuffix;
Console.WriteLine($"\tliteral length: {literalLength}, formattedCount: {formattedCount}");
}
public void AppendLiteral(string s)
{
builder.Append(s);
}
public void AppendFormatted<T>(T t)
{
string pointAsString = t switch
{
ThreeDimensionPoint threeDimensionPoint => $"{threeDimensionPoint.X}; {threeDimensionPoint.Y}; {threeDimensionPoint.Z}",
TwoDimensionPoint twoDimensionPoint => $"{twoDimensionPoint.X}; {twoDimensionPoint.Y}",
null => "null",
string formattedString => formattedString,
_ => throw new InvalidOperationException($"{nameof(T)} is unknown")
};
AppendLiteral(this.formattingPrefix);
AppendLiteral(pointAsString);
AppendLiteral(this.formattingSuffix);
}
internal string GetFormattedText() => builder.ToString();
}
C# 10 permet de rajouter l’attribut CallerArgumentExpressionAttribute pour indiquer sous forme d’une chaine de caractères l’expression à l’origine de la valeur d’un paramètre de la fonction courante.
Attributs de diagnostic avant C# 10
Tous ces attributs peuvent être utilisés pour apporter des informations de diagnostic sur la façon dont une méthode est appelée. Ces informations peuvent, par exemple, être logguées.
Par exemple si on considère le code suivant:
public class Example
{
public void CallingMethod()
{
string calleeSecondArgument = "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. Suspendisse lectus tortor...";
int firstInteger = 9;
int secondInteger = 610;
this.Callee(firstInteger + secondInteger, calleeSecondArgument, true);
}
private void Callee(int firstArgument, string secondArgument, bool thirdArgument)
{
Console.WriteLine(firstArgument);
Console.WriteLine(secondArgument);
Console.WriteLine(thirdArgument);
}
}
Sans surprise la valeur des 3 arguments est affichée dans la console:
619
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. Suspendisse lectus tortor...
True
Dans Callee(), on peut facilement afficher la valeur de chaque argument. Dans le but d’avoir des informations supplémentaires au moment de l’exécution, on peut utiliser les attributs indiqués précédemment sous la forme d’arguments supplémentaires de la méthode:
619
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. Suspendisse lectus tortor...
True
CallingMethod
C:\MyStuff\Dev\Example\ExampleCS10\CallerExpresssionArgumentFeature.cs
19
Comme on peut le voir, les arguments avec les attributs de diagnostic ne comportent plus les valeurs par défaut mais sont interprétés par le compilateur.
Précisions sur la valeur de CallerMemberName
La valeur renvoyée par l’argument CallerMemberName change suivant la nature de la méthode appelante:
Dans le cas d’une méthode ou propriété: la valeur sera le nom de la méthode ou de la propriété comme on a pu le voir précédemment.
Dans le cas d’un constructeur: la valeur sera ".ctor", par exemple:
internal class Example
{
public Example()
{
this.Callee();
}
private void Callee([CallerMemberName] string memberName = "")
{
Console.WriteLine(memberName);
}
}
Le résultat est:
.ctor
Dans le cas d’un constructeur statique: ".cctor", par exemple:
internal class Example
{
static Example()
{
var example = new Example();
example.Callee();
}
private void Callee([CallerMemberName] string memberName = "")
{
Console.WriteLine(memberName);
}
}
Le résultat est:
.cctor
Pour une surcharge d’opérateur: la valeur sera du type "op_<nom de l'opérateur>", par exemple:
internal class Example
{
public static Example operator +(Example a) => a.Callee();
private Example Callee([CallerMemberName] string memberName = "")
{
Console.WriteLine(memberName);
return this;
}
}
On peut appeler la surcharge de l’opérateur en exécutant:
var example = new Example();
Console.WriteLine(+classToExecute);
On obtient:
op_UnaryPlus
Dans le corps du finalizer: la valeur sera "Finalize".
Le plus compliqué est d’avoir un exemple permettant d’exécuter le finalizer:
static void Main(string[] args)
{
var example = new CallerMemberNameFeature();
MyMethod(1);
example.Dispose();
GC.Collect();
GC.WaitForPendingFinalizers();
}
private static void MyMethod(int i)
{
new CallerMemberNameFeature();
}
A l’exécution, on obtient:
Finalize
CallerArgumentExpression
C# 10
L’attribut CallerArgumentExpressionAttribute apparu en C# 10 permet de renvoyer l’expression à l’origine de la valeur du paramètre de fonction pour lequel l’attribut est utilisé.
Si on considère l’exemple suivant:
internal class CallerExpressionArgumentFeature
{
public void CallingMethod()
{
string calleeSecondArgument = "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. Suspendisse lectus tortor...";
int firstInteger = 9;
int secondInteger = 610;
this.Callee(firstInteger + secondInteger,
string.Format($"{0} {1} {2}", calleeSecondArgument, firstInteger, secondInteger));
}
private void Callee(int argument1, string argument2,
[CallerArgumentExpression("argument1")] string argumentExpression = "")
{
Console.WriteLine(argumentExpression);
}
}
Dans cet exemple, le paramètre argumentExpression de la méthode Callee() comporte un attribut CallerArgumentExpression("argument1") indiquant que le paramètre doit contenir l’expression à l’origine de la valeur de l’argument argument1.
L’argument comportant l’attribut CallerArgumentExpression doit obligatoirement comporter une valeur par défaut.
En appelant la méthode CallingMethod():
var example = new CallerExpressionArgumentFeature();
example.CallingMethod();
On obtient:
firstInteger + secondInteger
Cette expression se trouve dans l’appel de la méthode Callee() dans CallingMethod():
Obtenir l’expression à l’origine des valeurs des arguments peut être intéressant à logguer, par exemple, dans le cas où la valeur n’est pas celle attendue.
Dans un 1er temps, on rappelle les caractéristiques des structs. Ensuite, on indique quelles ont été les améliorations apportées aux structs par C# 10 et C# 11.
Rappels concernant les objets de type valeur
D’une façon générale, les types d’objet en C# peuvent être séparés en 2 familles:
Les objets de type référence: les variables d’objets de type référence contiennent des références vers les objets en mémoire. Ces variables contenant les références sont objets de type valeur. Ainsi lorsqu’on effectue une affectation d’une variable d’un objet de type référence vers une autre variable, la référence est dupliquée et copiée dans la nouvelle variable toutefois l’objet référencé n’est pas dupliqué.
Parmi les objets de type référence, on peut trouver les classes, les interfaces, les tableaux, le type delegate et le type dynamic. Les objets de type référence dérivent de System.Object.
Les objets de type valeur: les variables d’objets de type valeur correspondent à la représentation de la valeur réelle de l’objet. L’affectation d’une variable d’un objet de type valeur vers une autre variable effectue une copie de la représentation de la valeur de l’objet.
Les objets de type valeur sont les structs et les enums. Parmi les structs, on peut citer les tuples, booléens, les types intégrals (sbyte, byte, short, ushort, int, uint, long, ulong et char), les types à virgule flottante (float ou double) et decimal. Les objets de type valeur dérivent de System.ValueType qui dérive de System.Object.
Caractéristiques des objets de type valeur
Les caractéristiques essentielles des objets de type valeur sont qu’en tant que représentation de la valeur d’un objet, ils ne sont jamais nuls et les affectations de variables effectuent des copies des objets par valeur. Ainsi tous ces objets possèdent un constructeur par défaut qui va effectuer une initialisation à zéro des différentes données membres que constituent l’objet de type valeur. Si ce constructeur n’est pas explicitement implémenté, il est rajouté par le compilateur.
L’initialisation à zéro consiste à affecter:
0 aux membres de type intégral, 0.0f aux float, 0.0d aux double, 0m aux decimal,
false aux objets bool,
null aux objets de type référence,
Initialiser à zéro les membres de type valeur.
Caractéristiques des objets struct
En plus des caractéristiques des objets de type valeur, une struct ne peut pas être statique, ne peut pas hériter d’une autre struct et ne peut pas être abstraite. Une struct peut satisfaire une interface et peut avoir des membres statiques.
Ainsi, si on considère:
internal struct StructExample
{
public int IntegerMember;
public string StringMember;
public ClassExample ClassMember;
}
internal class ClassExample { }
Alors:
var structExample = new StructExample();
Console.WriteLine(structExample.IntegerMember); // 0
Console.WriteLine(structExample.StringMember); // null
Console.WriteLine(structExample.ClassMember); // null
Cette implémentation ne génère pas d’erreurs toutefois des warnings indiquent que les membres ne sont jamais initialisés:
warning CS0649: Field 'StructExample.StringMember' is never assigned to, and will always have its default value null
warning CS0649: Field 'StructExample.ClassMember' is never assigned to, and will always have its default value null
warning CS0649: Field 'StructExample.IntegerMember' is never assigned to, and will always have its default value 0
Les warnings disparaissent si on initialise les membres:
var structExample = new StructExample { IntegerMember = 0, StringMember = string.Empty, ClassMember = new ClassExample() };
Concernant les autres caractéristiques des structs:
Du coté du code MSIL, les différences ne sont pas très grandes entre les classes et les structs. Si on considère les 2 objets suivants dont les implémentations sont volontairement très proches:
internal struct StructExample
{
public int IntegerMember;
public StructExample(int integerMember)
{
this.IntegerMember = integerMember;
}
}
Et:
internal class ClassExample
{
public int IntegerMember;
public ClassExample(int integerMember)
{
this.IntegerMember = integerMember;
}
}
Si on regarde le code MSIL correspondant à ces 2 objets:
.class private auto ansi beforefieldinit CS10_Tests.ClassExample
extends [System.Runtime]System.Object
Ensuite:
sealed dans le cas de la struct qui interdit l’héritage.
auto dans le cas de la classe qui permet au compilateur de réordonner les membres de l’objet pour réduire les “espaces morts” entre membres occupant un espace différent en mémoire.
sequential dans le cas de la struct pour indiquer que les membres de l’objet sont disposés séquentiellement dans l’ordre de définition.
Dans le constructeur, un appel est effectué dans le cas de la classe au constructeur de System.Object:
var structExample = new StructExample(10);
Console.WriteLine(structExample.IntegerMember);
var classExample = new ClassExample(10);
Console.WriteLine(classExample.IntegerMember);
On peut remarquer que pour l’instanciation de la struct ou de la classe, le même opérateur newobj est utilisé. Newobj est, en effet, utilisé dans le cas d’un objet de type référence ou d’un objet de type valeur.
On peut donc constater que le code MSIL généré est très semblable entre une classe et une struct.
Si on modifie l’implémentation de cette façon:
StructExample structExample; // Une struct n'est pas null donc cette construction est possible
structExample.IntegerMember = 10;
Console.WriteLine(structExample.IntegerMember);
ClassExample classExample = new ClassExample(10);
Console.WriteLine(classExample.IntegerMember);
Le code MSIL est sensiblement différent et reflète la construction de la struct spécifique aux objets de type valeur. Cette construction n’est pas possible dans le cas de la classe:
Comme l’objet est de type valeur, il n’est pas nul. La variable locale correspondant à l’objet est sur la pile avec:
IL_0000: ldloca.s V_0
Dans le cas de la classe, le constructeur est appelé et l’opérateur newobj renvoie la référence vers la pile.
Avant C# 10.0
De façon à ce que les membres d’une structure soient initialisés à zéro à l’initialisation, certaines restrictions étaient appliquées aux structures. En cas d’absence de constructeur, le compilateur ne faisait que rajouter un constructeur permettant d’initialiser à zéro les membres de la structure. Toutes les autres formes d’implémentation du constructeur où tous les membres ne sont pas initialisés, menaient à une erreur de compilation:
Il n’était pas possible d’implémenter un constructeur sans paramètre:
internal struct StructExample
{
public int IntegerMember;
public string StringMember;
public ClassExample ClassMember;
public StructExample() {} // ⚠ Erreur avant C# 10.0 ⚠
}
Les initialisations de membres au même niveau que leur déclaration n’étaient pas possible:
internal struct StructExample
{
public int IntegerMember = 0; // ⚠ Erreur avant C# 10.0 ⚠
public string StringMember = string.Empty;
public ClassExample ClassMember = null;
}
Le constructeur doit initialiser toutes les données membres:
internal struct StructExample
{
public int IntegerMember;
public string StringMember;
public ClassExample ClassMember;
// Il n'est pas nécessaire que le constructeur
// contienne des paramètres pour tous les membres
public StructExample(int integerMember)
{
IntegerMember = integerMember;
// StringMember = string.Empty; // ⚠ Erreur, membre non initialisé ⚠
// ClassMember = new ClassExample(); // ⚠ Erreur, membre non initialisé ⚠
}
}
readonly struct
C# 7.2
Historiquement le mot-clé readonly pouvait être utilisé pour indiquer qu’un membre d’une classe ou d’une structure ne peut être initialisé que par un initializer (avant l’exécution du constructeur) ou par le constructeur.
A partir de C# 7.2, le mot-clé readonly peut être placé devant struct de façon à indiquer au compilateur que la structure doit être immutable. Par suite le compilateur vérifiera que les membres de la structure ne peuvent pas être modifiés:
Une propriété ne pourra pas avoir d’accesseurs en écriture:
public readonly struct MyStruct
{
public int WritableProp { get; set; } // ERREUR
public int ReadOnlyProp { get; } // OK
}
Les variables membres publiques doivent utiliser le mot-clé readonly:
public readonly struct MyStruct
{
public int WritableMember; // ERREUR
public readonly int ReadOnlyMember; // OK
}
La déclaration d’évènements dans la structure n’est pas autorisée:
public readonly struct MyStruct
{
public event EventHandler Event; // ERREUR
}
Ainsi la syntaxe permet de garantir que la structure est immutable.
ref peut être utilisé quand on déclare un objet struct pour indiquer qu’une instance de la structure ne peut se trouver que dans la pile et ne pourra pas correspondre à une allocation dans le tas managé, par exemple:
A partir de C# 8.0, les structures de type ref struct ou readonly ref struct peuvent être disposable. Sachant que les ref struct et les readonly ref struct sont stockées seulement sur la pile, il n’est pas possible de les faire satisfaire une interface, on ne peut donc pas implémenter IDisposable. A partir de C# 8.0, si une ref struct ou une readonly ref struct implémente une méthode publique void Dispose() alors la structure sera disposable sans avoir à rajouter explicitement : IDisposable.
Par exemple, si on considère la structure suivante:
ref struct DisposableStruct
{
public Dispose()
{
Console.WriteLine("Disposed");
}
}
En exécutant le code suivant, la méthode Dispose() est bien exécutée:
De façon à rendre les structs moins contraignantes à utiliser et de les rapprocher des fonctionnalités de classes, quelques améliorations ont été apportées:
A partir de C# 10:
Il est désormais possible de déclarer un constructeur sans paramètre.
L'initialisation d'un membre ou d'une propriété est possible directement au niveau de se déclaration.
On peut utiliser l'opérateur with avec des structs.
A partir de C# 11, il n'est plus nécessaire que le constructeur initialise tous les membres.
Constructeur sans paramètre
C# 10
A partir de C# 10, il n'est plus obligatoire d'utiliser un constructeur avec au moins un paramètre. On peut désormais implémenter un constructeur sans paramètre toutefois il est obligatoire d'initialiser tous les membres en C# 10 (cette obligation n'est plus valable avec C# 11). Si les membres ne sont pas initialisés explicitement, des erreurs de compilation sont générées:
internal struct StructExample
{
public int IntegerMember;
public string StringMember;
public ClassExample ClassMember;
public StructExample()
{
// ⚠ ERREUR en C# 10 ⚠
}
}
Erreurs de compilation si les membres ne sont pas explicitement initialisés:
error CS0171: Field 'StructExample.IntegerMember' must be fully assigned before control is returned to the caller.
error CS0171: Field 'StructExample.StringMember' must be fully assigned before control is returned to the caller.
error CS0171: Field 'StructExample.ClassMember' must be fully assigned before control is returned to the caller.
Si on initialise tous les membres:
internal struct StructExample
{
public int IntegerMember;
public string StringMember;
public ClassExample ClassMember;
public StructExample()
{
IntegerMember = 0;
StringMember = string.Empty;
ClassMember = new ClassExample();
}
}
L'obligation d'initialiser explicitement les membres disparait avec C# 11.
Initialisation des membres ou propriétés directement lors de leur déclaration
C# 10
Désormais il est possible d'initialiser des membres et des propriétés d'une struct lors de leur déclaration. Lorsqu'au moins un membre est initialisé lors de sa déclaration, un constructeur explicite est requis sinon une erreur de compilation est générée (cette obligation ne s'applique pas pour une propriété):
internal struct StructExample
{
public int IntegerMember = 0; // ⚠ ERREUR ⚠: au moins un constructeur est requis
}
Cette implémentation entraîne une erreur à la compilation:
error CS8983: A 'struct' with field initializers must include an explicitly declared constructor.
L'implémentation d'un constructeur sans paramètre suffit:
internal struct StructExample
{
// Membres
private ClassExample classExample = new ClassExample();
public int IntegerMember = 0;
public string StringMember = string.Empty;
// Constructeur sans paramètre
public StructExample() {}
// Propriété
public ClassExample ClassMember => this.classExample;
}
Utilisation de with avec des structs
C# 10
Si on considère la struct:
internal struct StructExample
{
public int IntegerMember;
public string StringMember;
}
On peut utiliser l'opérateur with (introduit en C# 9) pour construire une autre instance d'une struct en se basant sur la 1ère instance:
var firstExample = new StructExample { IntegerMember = 10, StringMember = "First" };
var secondExample = firstExample with { StringMember = "Second" };
Console.WriteLine(secondExample.IntegerMember); // 10
Console.WriteLine(secondExample.StringMember); // Second
L'objet généré par l'opérateur with (cf. secondExample) possède des membres avec les mêmes valeurs que l'objet à gauche de l'opérateur (cf. firstExample) à l'exception des membres dont on modifie explicitement la valeur (comme StringMember):
10
Second
L'initialisation explicite des membres n'est plus obligatoire
C# 11
A partir de C# 11, il n'est plus nécessaire d'initialiser tous les membres dans le constructeur. Dans le cas où les membres ne sont pas initialisés explicitement, ils sont initialisés à zéro (comme dans le cas où il n'y a pas de constructeur):
internal struct StructExample
{
public int IntegerMember;
public string StringMember;
public ClassExample ClassMember;
public StructExample() { }
}
Cette implémentation ne générera pas d'erreurs à la compilation toutefois des warnings seront générés car les membres ne sont pas initialisés:
warning CS0649: Field 'StructExample.StringMember' is never assigned to, and will always have its default value null
warning CS0649: Field 'StructExample.ClassMember' is never assigned to, and will always have its default value null
warning CS0649: Field 'StructExample.IntegerMember' is never assigned to, and will always have its default value 0
Les membres sont initialisés à zéro (comme dans le cas d'une absence de constructeur):
var structExample = new StructExample();
Console.WriteLine(structExample.IntegerMember); // 0
Console.WriteLine(structExample.StringMember); // null
Console.WriteLine(structExample.ClassMember); // null
En initialisant les membres, les warnings disparaissent:
internal struct StructExample
{
public int IntegerMember;
public string StringMember;
public ClassExample ClassMember;
public StructExample()
{
this.ClassMember = new ClassExample();
this.StringMember = string.Empty;
this.IntegerMember = 0;
}
}
Le framework .NET existant depuis les années 2000, beaucoup d’applications existent toujours en ayant comme cible le framework historique. Même si la grande majorité des fonctionnalités existent entre le framework .NET et .NET, le passage d’un framework à l’autre est loin d’être trivial. Des solutions existent pour limiter la quantité de code ciblant le framework .NET comme par exemple utiliser .NET Standard. En effet, .NET Standard permet ainsi d’avoir du code utilisable à la fois par des applications ciblant le framework .NET et .NET. Toutefois, de la même façon le passage du code du framework .NET à .NET Standard est loin d’être trivial.
Ainsi dans le but de ne pas avoir à trop migrer du code “legacy”, on peut se poser la question de savoir quelles sont les compatibilités entre le framework .NET historique et l’implémentation plus actuelle de .NET.
Le but de cet article est d’étudier en détails les différences entre le framework .NET et .NET et vérifier quels sont les éléments de compatibilité entre les 2:
Quelles sont les différences entre une assembly ciblant le framework .NET et une assembly ciblant .NET sous Windows ?
Une assembly ciblant framework .NET peut-elle être utilisée directement dans une application .NET ? Et inversement ?
Est-on obligé d’utiliser .NET Standard pour avoir des assemblies communes entre le framework .NET et .NET ?
Dans cet article pour éviter les confusions, on emploiera les termes:
“Framework .NET historique” pour désigner le framework .NET dont la version s’arrête à 4.8.x.
“.NET” pour désigner l’implémentation actuelle de .NET (anciennement appelée .NET Core).
Dans un premier temps, on va indiquer quelles sont les différences les plus importantes entre une application ciblant le framework .NET historique et la même application ciblant .NET. Ensuite, on va montrer quelles sont les possibilités pour utiliser des assemblies communes sans forcément utiliser .NET Standard.
Fonctionnement générale de .NET
Avant tout, le but de cette partie est de décrire le fonctionnement générale de .NET suivant les 2 implémentations.
Historique de .NET
Framework .NET historique
Historiquement le framework .NET historique a été construit au dessus de Windows ce qui le rend très spécifique à cette plateforme. On peut, toutefois, distinguer 2 types de dépendances sur lesquelles repose une application ciblant le framework .NET historique:
Les dépendances systèmes: ensemble de DLL Windows permettant à l’application de s’interfacer avec le système d’exploitation et plus généralement la machine, par exemple: advapi32.dll, kernel32.dll, gdi32.dll etc… (on peut trouver une liste plus exhautive sur Microsoft Windows library files).
Le framework .NET historique: avant Windows 10, le framework était distribué de façon séparé du système d’exploitation (cf. dotnet.microsoft.com/en-us/download/dotnet-framework). Il fallait donc l’installer séparément. Depuis Windows 10, le framework fait partie du système d’exploitation et est distribué en même temps sans installation séparée. On peut toutefois considérer les DLL et assemblies du framework .NET historique séparément des DLL système. L’assembly la plus connue faisant partie de cette catégorie est mscorlib.dll.
Historiquement et en particulier avant Nuget (apparu avec le framework 4.0), une application ciblant le framework .NET historique était distribuée sans aucune assembly du framework, seul le code et les assemblies fonctionnelles étaient fournis. De façon à rendre une application moins dépendante de la version du framework installée sur une machine, lors de l’implémentation d’une application, certaines dépendances du framework pouvaient être téléchargées via Nuget à partir du framework 4.0. Ainsi, on peut trouver des packages Nuget comme System.Runtime, System.IO, System.IO.FileSystem etc… Les assemblies dans ces packages sont déployées au même moment que l’application ce qui permet de rendre l’application moins dépendante des assemblies .NET du système d’exploitation.
Le framework .NET historique est toujours supporté toutefois il ne bénéficie plus plus d’évolutions fonctionnelles notables. La dernière version est 4.8.1. Il existe des compatibilités de code avec .NET Core.
.NET Core
L’implémentation .NET Core a commencé en 2016 de la version .NET Core 1.0 jusqu’à la version 3.1. Cette implémentation continue actuellement sous l’appellation .NET. Le plus gros avantage de cette implémentation est qu’elle n’est pas dépendante de la plateforme Windows à l’inverse du framework .NET historique. A la compilation, il est possible de cibler d’autres systèmes d’exploitation comme Linux ou Mac OS. De plus, il est possible de déployer une application .NET Core de façon autonome avec toutes les dépendances dans le même répertoire ce qui limite d’éventuel problème de dépendances non satisfaites à l’exécution.
Au fur et à mesure des versions de .NET Core, les fonctionnalités du framework .NET historique ont été portées sur .NET Core:
.NET Core 1.0: portage des fonctionnalités principales du framework .NET historique avec la CoreCLR et la machine virtuelle permettant l’exécution des application .NET.
.NET Core 2.0: supporte .NET Standard 2.0. Beaucoup de fonctionnalités sont rajoutés au .NET Standard 2.0 et donc de fait sont rajoutées dans .NET Core 2.0 comme ASP.NET Core 2.0, Entity Framework Core 2.0, Razor Pages, SignalR.
.NET Core 3.0: le support de technologie desktop comme WPF ou Windows Forms est rajoutée mais réservé à une plateforme Windows. .NET Core 3.0 introduit des fonctionnalités inédites comme les Web assemblies.
La dénomination .NET Core s’est arrêtée avec la version 3.1 toutefois cette implémentation a continué sous l’appélation .NET.
.NET
Il s’agit actuellement de l’implémentation principale de la technologie .NET. L’appellation a commencé avec la version 5.0 qui est la continuation de .NET Core. Une très grande partie des fonctionnalités du framework .NET historique ont été portées dans .NET. Désormais, les évolutions fonctionnelles ne sont implémentées que dans cette implémentation.
Dans Visual Studio 2022, l’interface ne permet plus de créer une application du framework .NET historique sans éditer directement le fichier .csproj.
Fonctionnement général du CLR
Le but de cette partie est d’évoquer quelques caractéristiques du CLR.
Chargement des assemblies à la demande
Par défaut, le CLR fonctionne en ne chargeant que les types dont il a besoin en mode “lazy loading” c’est-à-dire seulement s’il doit appeler une méthode dans ce type.
Par exemple si on considère le code suivant:
Une classe QuickSort se trouvant dans une assembly nommée QuickSort.dll:
namespace Example
{
public class QuickSort
{
public QuickSort(int numberCount)
{
// ...
}
public IReadOnlyList<int> OriginalNumbers => this.originalNumbers;
public IReadOnlyList<int> Sort()
{
// ...
}
}
}
Le détail du code n’a pas d’importance, il faut juste prêter attention aux appels qui sont effectués.
Une classe QuickSortCaller se trouvant dans une assembly nommée Launcher.dll:
namespace Launcher
{
internal class QuickSortCaller
{
public QuickSortCaller()
{
}
public void CallQuickSort()
{
var quickSort = new QuickSort(10);
Console.WriteLine($"Original numbers: {string.Join("; ", quickSort.OriginalNumbers)}");
var sortedNumbers = quickSort.Sort();
Console.WriteLine($"Sorted numbers: {string.Join("; ", sortedNumbers)}");
}
}
}
Enfin le "Main" dans l’assemblyLauncher.dll:
namespace Example.Launcher
{
class TestClass
{
static void Main(string[] args)
{
PrintAssemblies();
Console.ReadLine();
var quickSortCaller = new QuickSortCaller();
quickSortCaller.CallQuickSort();
PrintAssemblies();
Console.ReadLine();
}
public static void PrintAssemblies()
{
var assemblies = AppDomain.CurrentDomain.GetAssemblies();
foreach (var assembly in assemblies)
{
Console.WriteLine(assembly.GetName());
}
}
}
}
Le but de cette application est de lancer le tri en ordre croissant de 10 nombres par la classe QuickSort à partir de Launcher.exe. L’exécution est interrompue par des Console.ReadLine() de façon à pouvoir vérifier quelles sont les assemblies qui sont chargées en mémoire.
Ainsi on peut voir que le chargement de l’assemblyQuickSort.dll ne s’est fait que lorsqu’il y a eu un appel à une fonction se trouvant dans cette assembly.
Démarrage d’une application .NET
Le démarrage d’une application .NET ne suit pas tout à fait le même ordre dans le cas du framework .NET historique et de .NET:
Dans le cas du framework .NET historique, l’application est un exécutable (i.e. fichier .exe) qui ne peut être lancé que sur Windows. Le format de ce fichier correspond à un Portable Executable qui sera reconnu par le système d’exploitation. Ce fichier contient une petite partie de code natif qui sert d’amorce pour démarrer le CLR par l’intermédiaire de mscoree.dll. Toutes les dépendances principales du framework dans mscorlib.dll sont ensuite chargées. Le code .NET se trouve sous la forme de code IL que le CLR va compiler en code machine par l’intermédiaire du compilateur JIT. Le premier module compilé et exécuté est celui correspondant à la fonction main. Suivant l’exécution, les autres parties du code seront compilées et les dépendances chargées au besoin.
Pour .NET, le fichier exécutable dépend du système d’exploitation qui a été ciblé lors de la compilation (i.e. runtime packs). Cet exécutable est une application hôte (i.e. “app host”) native qui va servir d’amorce pour charger et exécuter des DLL ayant des responsabilités différentes:
hostfxr.dll: cette DLL va sélectionner le bon runtime permettant d’exécuter l’application .NET. Ce runtime dépend du runtime ciblé au moment de la compilation, du système d’exploitation et du runtime réellement installé.
hostpolicy.dll: regroupe toutes les stratégies pour charger le runtime, appliquer la configuration, résoudre les dépendances de l’application et appeler le runtime pour exécuter l’application.
coreclr.dll: c’est le CLR qui va exécuter le code .NET. Le comportement est ensuite similaire au framework .NET historique: le code .NET sous la forme de code IL est compilé au besoin par l’intermédiaire du compilateur JIT. Ce code est ensuite exécuté.
Chargement des dépendances
Le principe général de chargement des dépendances est le même entre le framework .NET historique et .NET. On distingue les assemblies du framework et les dépendances plus spécifiques au code exécuté ne faisant pas partie du framework. Dans le cas du framework .NET historique, beaucoup de classes de base se trouvent dans mscorlib.dll qui est chargée au démarrage de l’application. Pour .NET, les classes de base se trouvent dans System.Private.CoreLib.dll et dans d’autres assemblies (comme System.Runtime, System.Threading, etc…).
En dehors des classes et des assemblies de base du framework, les dépendances sont chargées par le CLR au besoin si le code exécuté le nécessite. Ainsi si l’exécution d’une portion de code fait appel à un type se trouvant dans une dépendance, cette dépendance doit être chargée en mémoire si ce n’est pas déjà le cas. Le code IL obtenu suite à la compilation indique l’assembly à partir de laquelle ce type peut être trouvé; c’est de cette façon que le CLR, à l’exécution, peut savoir où le récupérer. Par exemple dans le cadre de l’exemple précédent, si on regarde le code IL correspondant à l’appel au code se trouvant dans l’assemblyQuickSort.dll:
On peut voir que le classe Example.QuickSort se trouve dans l’assemblyQuickSort. A partir des metadatas dans le manifest, on peut trouver les caractéristiques de QuickSort:
.assembly extern QuickSort
{
.ver 1:0:0:0
}
Si l’assembly est signée par nom fort, les metadatas comportent la clé publique correspondant à la signature:
Ainsi une dépendance externe est identifiée avec le nom de l’assembly, la version et éventuellement la clé publique. Ce fonctionnement est le même entre le framework .NET historique et .NET. En revanche, ce qui diffère est la façon dont les dépendances sont cherchées par le CLR. En effet, lorsque le CLR doit chercher une dépendance qui n’a jamais été chargée, une séquence est lancée pour chercher l’emplacement de cette dépendance.
Processus de recherche des assemblies avec le framework .NET historique
En plus de la version indiquée dans les metadatas du manifest du code IL, le CLR va chercher à déterminer la version de l’assembly à charger suivant des binding redirects pouvant se trouver dans:
Le fichier de configuration de l’application <nom exécutable>.exe.config.
Quand le CLR a déterminé la version à charger, il vérifie que l’assembly n’est pas déjà chargée. Si une version différente de l’assembly est déjà chargée, une exception de type FileLoadException est lancée. Si l’assembly possède un nom fort, il est possible d’en charger plusieurs versions (i.e. Side-by-side execution). Pour plus de détails sur la signature par nom fort, voir Signature des assemblies par nom fort en 5 min.
Si l’assembly n’a pas déjà été chargée, une recherche est faite dans le GAC (i.e. Global Assembly Cache). Si le GAC ne permet pas d’obtenir l’assembly à charger, une recherche à d’autres emplacements appelée probing est effectuée (i.e. Default probing). Par défaut cette recherche est effectuée:
Dans le répertoire de l’application ou dans un répertoire avec le même nom que l’assembly:
<répertoire de l'application>\<nom assembly>.dll
<répertoire de l'application>\<nom assembly>\<nom assembly>.dll
<répertoire de l'application>\<culture>\<nom assembly>.dll
<répertoire de l'application>\<culture>\<nom assembly>\<nom assembly>.dll
Dans les répertoires se trouvant dans l’élément de configuration privatePath modifiable avec le paramètre <probing> dans le fichier de configuration ou dans le code avec AppDomainSetup.PrivateBinPath.
Débugguer la recherche de dépendances avec “fuslog”
Il est possible de débugguer cette séquence de recherche de dépendance en utilisant fuslogvw.exe.
Processus de recherche des assemblies avec .NET
Avec .NET, le chargement des dépendances est différent du mécanisme utilisé pour le framework .NET historique. Avec le framework .NET historique, il existait un AppDomain par défaut dans lequel les assemblies étaient chargées. Quand une assembly était chargée dans un AppDomain, il n’était pas possible de la décharger toutefois il était possible de décharger l’AppDomain entier. Ainsi l’AppDomain constitue une frontière qui permet, par exemple, de charger la même assembly dans des versions différentes. Les appels d’un AppDomain à l’autre se faisait par sérialisation/désérialisation d’objets.
AssemblyLoadContext
Avec .NET (à partir de la version 5), l’objet AppDomain existe toujours toutefois il n’existe qu’un seul AppDomain et il n’est pas possible d’en créer un autre: AppDomain.CreateDomain(...) mène à une erreur. Les contextes de chargement (i.e. loader context) permettent de remplacer les AppDomains en apportant des fonctionnalités supplémentaires:
Les contextes de chargement sont nommés, et il n’y a pas de contexte courant comme pour les AppDomains. On peut utiliser la fonction AssemblyLoadContext.GetLoadContext(<assembly>) pour renvoyer le contexte utilisé pour une assembly donnée.
Les appels d’un contexte à l’autre ne sont pas très couteux.
On peut toujours déchargé un contexte de chargement de façon à décharger une assembly:
var newLoadContext = new AssemblyLoadContext(name: <nom du contexte>, isCollectible: true);
// isCollectible à true autorise à décharger le contexte par la suite.
newLoadContext.LoadFromAssemblyPath(<chemin de l'assembly>);
// ...
newLoadContext.Unload();
On peut implémenter un comportement particulier pour charger les dépendances d’une assembly (y compris les dépendances natives). On peut s’aider de la classe AssemblyDependencyResolver dans la résolution des dépendances.
Voir albahari.com/nutshell/E8-CH18.aspx pour davantage de détails sur l’implémentation.
Les fonctions Assembly.Load(byte[]), Assembly.LoadFrom(filename) créent toujours un contexte de chargement séparé.
L’intérêt principal de AssemblyLoadContext est de proposer une isolation pour permettre de facilement choisir dans quel contexte les dépendances seront chargées et quel contexte sera utilisé pour accéder à la dépendance d’une assembly. On peut indiquer une portée avec using dans laquelle un autre contexte de chargement sera utilisé:
var addonLoadContext = new AssemblyLoadContext(...);
using (addonLoadContext.EnterContextualReflection())
{
var addonAssembly = Assembly.Load(<nom de l'assembly>);
}
Recherche par défaut des assemblies
Lors de l’exécution de l’application par l’app host”, après avoir chargé l’assemblycoreclr.dll et avant de donner le main au CoreCLR, “l’app host” affecte certaines propriétés pour indiquer des éléments de contexte à l’exécution:
TRUSTED_PLATFORM_ASSEMBLIES: liste des chemins des assemblies du framework (managées et natives).
APP_PATHS et APP_NI_PATHS: chemin de l’application
NATIVE_DLL_SEARCH_DIRECTORIES: liste des chemins des répertoires qui seront parcourus pour chercher les DLL natives.
PLATFORM_RESOURCE_ROOTS: liste des chemins des répertoires qui seront parcourus pour chercher les assemblies satellites (assemblies de ressources).
APP_CONTEXT_BASE_DIRECTORY: répertoire de base de l’application
APP_CONTEXT_DEPS_FILES: liste des fichiers contenant les dépendances, les données du contexte de compilation et les dépendances de compilation pour l’application.
FX_DEPS_FILE: liste des fichiers contenant les dépendances du framework.
La valeur de ces propriétés peut être obtenue avec:
AppContext.GetData(<nom de la propriété>);
Ces propriétés sont utilisées par le CLR pour trouver les dépendances managées ou natives lors de l’exécution de l’application. Par défaut, le contexte de chargement AssemblyLoadContext.Default parcourt les chemins indiqués dans les propriétés TRUSTED_PLATFORM_ASSEMBLIES et APP_PATHS.
Les assemblies satellites (assemblies de ressources) sont cherchées dans les répertoires indiquées par les propriétés PLATFORM_RESOURCE_ROOTS et APP_PATHS en ajoutant l’extension liée au nom de la culture:
On peut voir des logs concernant la recherche des dépendances en affectant les variables d’environnement suivantes avant d’exécuter l’application:
COREHOST_TRACE=1: permet d’indiquer qu’on souhaite activer les logs.
COREHOST_TRACEFILE=out.txt: permet d’indiquer le fichier de sortie dans lequel on souhaite envoyer les logs.
COREHOST_TRACE_VERBOSITY=4: pour indiquer le niveau de logs (4 étant le maximum).
Pour ajouter ces variables lors du débug de l’application dans Visual Studio:
Debug ⇒ <nom du projet> Debug Properties
Rajouter les variables dans la partie Environment Variables
Dans le cas d’une exécution à la ligne de commandes, on peut créer un .bat contenant:
set COREHOST_TRACE=1
set COREHOST_TRACEFILE=out.txt
set COREHOST_TRACE_VERBOSITY=4
Launcher.exe
Redirection de type
La fonctionnalité de “type forwarding” (i.e. redirection de type) permet de déplacer un type d’une assembly à une autre sans avoir à changer les références des assemblies utilisant ce type. Cette fonctionnalité est régulièrement utilisée par Microsoft lors des changements de framework pour assurer la retrocompatibilité: par exemple lorsque des types ont été déplacés de System.Core.dll vers mscorlib.dll entre les frameworks 3.5 et 4 ou plus récemment lorsque des types de mscorlib.dll sont déplacés dans System.Private.CoreLib entre les frameworks .NET 4.8 et .NET Core.
Pour illustrer, on prend l’exemple d’une application permettant d’appliquer l’algorithme “Quick sort” à une liste d’entiers. Le but n’est pas de rentrer dans les détails de l’algorithme mais d’avoir un exemple d’appel de fonctions. Ainsi:
L’algorithme se trouve dans une assembly nommée QuickSort:
namespace Example;
public class QuickSort
{
private readonly int[] originalNumbers;
public QuickSort(int numberCount)
{
this.originalNumbers = new int[numberCount];
Random rnd = new Random();
for (int i = 0; i < numberCount; i++)
{
originalNumbers[i] = rnd.Next();
}
}
public IReadOnlyList<int> OriginalNumbers => this.originalNumbers;
public IReadOnlyList<int> Sort()
{
// ...
}
}
L’algorithme est appelé à partir d’une autre assembly nommée Launcher.exe:
using System;
using Launcher;
namespace Example.Launcher
{
class TestClass
{
static void Main(string[] args)
{
var quickSort = new QuickSort(10);
Console.WriteLine($"Original numbers: {string.Join("; ", quickSort.OriginalNumbers)}");
var sortedNumbers = quickSort.Sort();
Console.WriteLine($"Sorted numbers: {string.Join("; ", sortedNumbers)}");
}
}
}
Pour résumer Launcher.exe appelle une classe et une fonction dans QuickSort.dll. Ainsi Launcher.exe référence QuickSort.dll. On décide de déplacer le code dans QuickSort.dll dans une autre assembly appelée NewQuickSort.dll sans changer la référence dans Launcher.exe donc:
On supprime le code se trouvant dans QuickSort.dll.
On référence l’assemblyNewQuickSort.dll dans QuickSort.dll et
On ajoute l’attribut TypeForwardedTo() dans QuickSort.dll pour transférer le type Example.QuickSort vers NewQuickSort.dll:
using System.Runtime.CompilerServices;
[assembly: TypeForwardedTo(typeof(Example.QuickSort))]
namespace Example;
Le type Example.QuickSort se trouve désormais dans l’assemblyNewQuickSort.dll. La référence typeof(Example.QuickSort) dans QuickSort.dll est possible car QuickSort.dll référence NewQuickSort.dll. Enfin l’assemblyLauncher.exe n’est pas modifiée, elle référence uniquement QuickSort.dll et le code Example.QuickSort qui est censé s’y trouver.
A l’exécution, Launcher.exe instancie la classe Example.QuickSort à partir de la référence vers l’assemblyQuickSort.dll. Le CLR charge le type directement dans l’assemblyNewQuickSort.dll à cause du transfert de type de QuickSort.dll vers NewQuickSort.dll.
TypeForwardedFrom
On peut utiliser l’attribut System.Runtime.CompilerServices.TypeForwardedFromAttribute pour indiquer l’assembly à partir de laquelle un transfert de type est effectué. L’indication se fait en utilisant le nom complet de l’assembly comportant l’indication TypeForwardedTo. L’utilisation de l’attribut TypeForwardedFromAttribute est dans le but de documenter le transfert de type, il n’y a pas de traitement effectué par le CLR lorsque cet attribut est utilisé.
Dans notre exemple, on pourrait rajouter l’attribut TypeForwardedFromAttribute dans l’assemblyNewQuickSort.dll pour indiquer que le transfert du type Example.QuickSort provient de l’assemblyQuickSort.dll:
namespace Example;
[System.Runtime.CompilerServices.TypeForwardedFrom("QuickSort, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null")]
public class QuickSort
{
// ...
}
Différences de structure et de dépendances entre le framework .NET historique et .NET
Dans un 1er temps, on va indiquer quels sont les éléments constituant la structure d’une assembly .NET. Dans une 2e temps, on va chercher à trouver les différences de structure entre des assemblies ciblant des frameworks différents.
Structure d’une assembly
On peut se poser la question de savoir quelles sont les différences de structure des assemblies entre le framework .NET historique et .NET d’une part et les assemblies .NET ciblant Windows et ciblant Linux ou Mac OS d’autre part.
Le code .NET pouvant être exécuté est stocké dans des fichiers appelés assemblies. Ces assemblies sont composés des éléments suivants:
Les assemblies sont composées des éléments suivants:
PE Header: l’assembly est structurée dans un objet PE de plus bas niveau. A ce titre, il possède ce type d’en-tête.
Un manifest contenant une liste des références externes de l’assembly.
Sections contenant du code natif compilé.
Dans le cas d’assembly managée:
CLR Header: présent dans le cas d’une assembly managée. Ce sont des informations sur la version cible du framework .NET historique; éventuellement le hash pour la signature par nom fort (cf. Signature par nom fort); l’adresse dans le fichier des ressources et le point d’entrée indiquant la table des métadonnées permettant à l’assembly de s’autodécrire.
Liste des objets binaires utilisés dans les métadonnées.
Liste des chaines de caractères utilisées dans les métadonnées.
Liste des chaines de caractères utilisées dans le code IL (i.e. Intermediate Language).
Liste des GUID utilisés dans l’assembly.
Tables des métadonnées permettant d’indiquer des informations sur tous les types utilisés dans l’assembly.
Le code IL (i.e. Intermediate Language).
PE Header
Cet en-tête se trouve dans des fichiers dont le format est PE pour Portable Executable. Les fichiers contenant un en-tête PE Header sont des PE objects (i.e. objet PE). Ce format est commun pour structurer des fichiers différents comme des exécutables, des bibliothèques ou des drivers système. Il définit une structure connue du système d’exploitation pour qu’il puisse savoir où trouver des informations qui lui permettront de mapper le contenu du fichier organisé en sections à des zones en mémoire. Cette structure est indiquée dans l’en-tête du fichier (i.e. PE Header).
Le PE Header n’est pas spécifique à des assemblies .NET, il est aussi utilisé dans le cas de DLL natives.
Module
Un module est aussi un terme utilisé en managée et en non managée. Il désigne une unité de compilation contenant des métadonnées des types qu’il contient et du code compilé. Le code compilé n’est pas forcément du code machine. Il correspond à un niveau d’échelle plus élevé que les objets PE.
Un module ne peut pas être déployé seul et il ne contient pas de manifest c’est-à-dire qu’il n’indique pas quelles sont ses dépendances. Chaque module contient un seul type de code.
L’intérêt des modules est de pouvoir être utilisés indépendamment dans une unité déployable comme les assemblies.
Assembly
Une assembly est une unité déployable en opposition aux modules qui sont des unités de compilation. L’assembly peut ainsi être déployée seule. D’une façon générale, il s’agit de fichiers avec une extension .exe pour un exécutable ou .dll pour une bibliothèque de classes.
En .NET, les assemblies sont assez souples pour contenir un ou plusieurs modules, éventuellement des fichiers de ressources et des métadonnées. Les modules peuvent être compilés dans des langages différents. Il est aussi possible de merger le contenu de plusieurs assemblies dans une seule assembly.
On considère plusieurs types d’assemblies:
assembly managée: objet PE contenant du code managé. En .NET c’est la plus petite unité de déploiement. Dans la pratique, ces fichiers peuvent être des exécutables ou des bibliothèques de classes. Le plus souvent quand on utilise le terme assembly c’est pour désigner les assemblies managées.
assembly mixte: assembly .NET contenant à la fois du code managé et du code natif (cf. C++/CLI).
assembly native: on retrouve le terme assembly native dans la documentation Microsoft concernant WinSxS. Ce terme est ambigu car il laisse penser qu’il désigne d’assemblies .NET contenant seulement du code natif or, dans le cas de WinSxS, on parle bien de DLL natives classiques.En effet, en .NET, on distingue les assemblies (sous-entendu les assemblies managées) qui contiennent exclusivement du code managé et les assemblies mixtes contenant, à la fois du code managé et du code natif. Ainsi dans le cas où il n’y a que du code natif, le terme assembly native désigne un groupe d’une ou plusieurs DLL natives, de composant COM ou des collections de ressources, de types ou d’interfaces.
Side-by-side assembly: assembly native contenant une liste de ressources ou un groupe de DLL avec un manifest. Le loader du système d’exploitation utilise les informations du manifest pour identifier l’assembly et être capable de la charger quand un exécutable a une dépendance vers cette dernière. Elles ont une identité unique et sont utilisées pour éviter de casser des dépendances.
Private assembly: assembly native utilisée seulement par une seule application. Elle peut être inclue en tant que ressource d’une autre DLL ou installer dans le même répertoire que l’exécutable qui l’utilise.
Shared assembly: side-by-side assembly déployée dans le répertoire du cache des assemblies du système WinSxS. Ces assemblies peuvent être utilisées par un exécutable si la dépendance est indiquée dans son manifest.
Dans le cadre de cet article, par simplification, on ne s’intéressera qu’aux assemblies managées.
Code MSIL
En .NET, le code n’est pas directement compilé en code machine comme cela est le cas pour du code C++ natif. Le code .NET est compilé dans des assemblies contenant des instructions MSIL (pour MicroSoft Intermediate Language). Ces instructions sont exécutables par le CLR (i.e. Common Language Runtime).
Compilation avec Roslyn vs Compilation avec le JIT
A l’exécution et suivant les besoins du CLR, les instructions MSIL sont de nouveau compilées en code machine par le compilateur JIT (i.e. Just In Time). Le code machine généré est ensuite exécuté par la machine. Les instructions MSIL sont compilées à la demande, en fonction des appels qui sont effectués. Si des instructions correspondant à une fonction ne sont pas appelées alors ces instructions ne seront pas compilées par le compilateur JIT. D’autre part, le compilateur JIT effectue des optimisations dans le code généré suivant la façon dont les fonctions sont appelées. Ainsi les performances d’exécution d’un programmation peuvent s’améliorer au fur et à mesure de son exécution.
On peut trouver le terme CIL (pour Common Intermediate Language) pour désigner du code IL. Il correspond aux mêmes jeux d’instructions que le MSIL toutefois ce terme est utilisé dans le cadre du standard CLI (i.e. Common Language Infrastructure).
Comparaison entre des assemblies ciblant différents frameworks
On va considérer du code .NET simple que l’on va stocker dans une bibliothèque de classes (i.e. class library) nommée QuickSort.dll et on va cibler le framework .NET historique 4.8, .NET 6.0 sous Windows et sous Linux.
Le code correspondant à une classe dont la structure est (le code précis n’a pas d’importance mais on peut le consulter sur GitHub src/QuickSort/QuickSort/QuickSort.cs):
namespace Example
{
public class QuickSort
{
private readonly int[] originalNumbers;
public QuickSort(int numberCount)
{
[...]
}
public IReadOnlyList<int> OriginalNumbers => this.originalNumbers;
public IReadOnlyList<int> Sort()
{
[...]
}
private static void Quicksort(int[] numbers, int first, int last)
{
[...]
}
}
}
Comment générer dans Visual une assembly en ciblant le framework .NET historique 4.8 ?
Il faut éditer le fichier projet en faisant un clique droit sur le projet puis “Edit Project File” et modifier le contenu de cette façon:
Refaire la même opération avec Target runtime: win-x64 et Target location: bin\Release\net6.0\publish\win-x64\.
Les assemblies générées devraient se trouver dans les répertoires:
Runtime ciblant framework 4.8 pour Windows: bin\Release\net4.8\publish\win-x64\
Runtime ciblant .NET 6.0 pour Windows: bin\Release\net6.0\publish\win-x64\
Runtime ciblant .NET 6.0 pour Linux: bin\Release\net6.0\publish\linux-x64\
Si on compare les assemblies entre elles, on peut voir qu’elles ne sont pas tout à fait identiques:
Entre les assemblies .NET 6.0 ciblant Windows ou Linux:
fc /b bin\Release\net6.0\publish\linux-x64\QuickSort.dll bin\Release\net6.0\publish\win-x64\QuickSort.dll
Comparing files BIN\RELEASE\NET6.0\PUBLISH\LINUX-X64\QuickSort.dll and BIN\RELEASE\NET6.0\PUBLISH\WIN-X64\QUICKSORT.DLL
00000088: 4F AF
00000089: 7B 74
0000008A: 7D 07
0000008B: B7 8F
...
Entre les assemblies .NET 6.0 ciblant Windows et l’assembly ciblant le framework .NET historique 4.8, les différences sont plus importantes:
fc /b bin\Release\net4.8\publish\win-x64\QuickSort.dll bin\Release\net6.0\publish\win-x64\QuickSort.dll
Comparing files BIN\RELEASE\NET4.8\PUBLISH\WIN-X64\QuickSort.dll and BIN\RELEASE\NET6.0\PUBLISH\WIN-X64\QUICKSORT.DLL
00000084: 4C 64
00000085: 01 86
00000086: 03 02
00000088: 08 AF
00000089: 67 74
0000008A: FE 07
0000008B: BC 8F
[...]
FC: BIN\RELEASE\NET4.8\PUBLISH\WIN-X64\QuickSort.dll longer than BIN\RELEASE\NET6.0\PUBLISH\WIN-X64\QUICKSORT.DLL
Dans un 1er temps, on peut comparer les headers de ces fichiers avec dumpbin. Cet utilitaire permet d’afficher le PE Header de DLL. On peut obtenir cet outil en installant les “C++ profiling tools” dans la rubrique “Desktop development with C++” de l’installateur de Visual Studio. Après installation, cet outil se trouve dans un répertoire du type: C:\Program Files\Microsoft Visual Studio\<Version VS>\Community\VC\Tools\MSVC\<Version compilateur>\bin\Hostx64\x64\dumpbin.exe.
Ainsi, si on extrait le header pour chaque DLL en exécutant à partir de l’invite de commande “Native tools Command prompt”:
dumpbin /headers <chemin de l'assembly>
En comparant les headers des différentes versions de l’assemblyQuickSort.dll, on peut voir que:
Il n’y a pas de différences de headers entre les assemblies ciblant .NET 6.0 pour Windows ou pour Linux et
La seule différence notable dans le header entre une assembly ciblant .NET 6.0 et une autre assembly ciblant le framework .NET historique est dans la donnée "subsystem version":
Extrait du header de l’assembly ciblant le framework .NET historique:
Extrait du header de l’assembly ciblant .NET 6.0:
OPTIONAL HEADER VALUES
20B magic # (PE32+)
48.00 linker version
A00 size of code
400 size of initialized data
0 size of uninitialized data
0 entry point
2000 base of code
180000000 image base (0000000180000000 to 0000000180005FFF)
2000 section alignment
200 file alignment
4.00 operating system version
0.00 image version
6.00 subsystem version
[...]
OPTIONAL HEADER VALUES
20B magic # (PE32+)
48.00 linker version
A00 size of code
400 size of initialized data
0 size of uninitialized data
0 entry point
2000 base of code
180000000 image base (0000000180000000 to 0000000180005FFF)
2000 section alignment
200 file alignment
4.00 operating system version
0.00 image version
4.00 subsystem version
[...]
Les différences se trouvent donc ailleurs.
On se propose, ensuite, de comparer les metainfos des assemblies en utilisant ildasm (cet outil se trouve dans un chemin de type: C:\Program Files (x86)\Microsoft SDKs\Windows\v10.0A\bin\NETFX 4.8.1 Tools). Pour effectuer cette comparaison, on ouvre ildasm pour chaque assembly et on affiche les metainfos en allant dans View ⇒ Metainfo ⇒ Show (il faut que dans le menu metainfo aucune entrée ne soit cochée).
En comparant les metainfos des différentes versions de QuickSort.dll, on peut indiquer:
Il n’y a pas de différences entre les assemblies ciblant .NET 6.0 pour Windows ou pour Linux et
Entre des assemblies ciblant le framework .NET historique et NET 6.0, on peut citer quelques différences:
La référence vers l’assembly principale spécifique à chaque framework:
System.Runtime pour .NET 6.0
mscorlib pour le framework .NET historique
La présence d’attributs générés par le compilateur dans l’assembly ciblant .NET:
System.Runtime.CompilerServices.RefSafetyRulesAttribute: permettant d’indiquer que le module a été compilé en respectant les règles de sécurité sur les ref C# 11.
Equivalences entre le framework .NET historique et .NET
Comme on a pu le voir précédemment, le fonctionnement général de .NET est similaire entre .NET et le framework .NET historique. Les différences les plus importantes sont dans l’amorce de l’exécutable, les répertoires parcourus pour charger les dépendances et les dépendances elles-mêmes. De ces 3 éléments, les dépendances vont fortement contribuer à rendre plus difficile la compatibilité entre .NET et le framework .NET historique. Il existe des solutions pour limiter les incompatibilités entre les 2 implémentations de façon à porter des implémentations d’un framework à l’autre en gardant en tête que le portage le plus utile est du framework .NET historique vers .NET. L’autre sens n’a pas forcément un intérêt mais on étudiera quand même cette possibilité.
La solution la plus triviale pour rendre du code prévu pour le framework .NET historique compatible avec .NET est d’utiliser .NET Standard. Toutefois dans les cas où on ne peut pas refactorer ou recompiler des assemblies, il existe d’autres solutions.
.NET Standard
.NET Standard est l’approche historique de Microsoft pour trouver une compatibilité entre le framework .NET historique et les nouveaux frameworks .NET Core/.NET. L’approche a été d’inclure des types et objets dans le standard, chaque framework implémente le standard. Ainsi lorsqu’on construit une application ou une assembly, on ne dépend plus d’un framework mais du standard. La construction de .NET Standard permet ensuite de garantir que si une assembly dépend du standard alors elle est compatible avec les frameworks implémentant ce standard (pour davantage de détails sur la construction de .NET Standard, voir Comprendre .NET Standard en 5 min). La 1ère version de .NET Standard est la version 1.0, elle comprend peu d’objets mais beaucoup de frameworks l’implémentent.
Comparaison entre .NET Standard 1.0 et .NET Standard 2.1
Ainsi:
Plus on incrémente les versions de .NET Standard et moins de framework implémente le standard: cela s’explique par le fait que les frameworks les plus obsolètes n’évoluent plus.
La dernière version du standard c’est-à-dire la 2.1 n’est pas prise en charge par le framework .NET historique. Le framework .NET 4.8.x implémente au maximum .NET Standard 2.0.
Lorsqu’on développe une application ou des assemblies, il est tentant de les faire dépendre de .NET Standard plutôt qu’un framework particulier. Il faut, toutefois, avoir en tête que l’approche .NET Standard est abandonnée et ce standard ne sera plus incrémenté(*). Ainsi la version 8.0 de .NET qui est la dernière version de ce framework ne prend en charge aucune version de .NET Standard. La dernière version de .NET implémentant .NET Standard est la version 7.0. .NET Standard convient bien pour les anciennes applications, en particulier celles utilisant le framework .NET historique car cela permet de procéder par étape si on souhaite porter ces applications sur .NET. Toutefois dans le cadre de nouvelles applications, il vaut mieux utiliser directement .NET.
En effet, actuellement la très grande majorité des fonctionnalités du framework .NET historique existe en .NET y compris les fonctionnalités spécifiques aux plateformes Windows (WPF, WinForms, C++/CLI etc…). D’autre part, lorsqu’une fonctionnalité dans le framework .NET historique n’existe pas en .NET, il existe des équivalents. Il n’y a donc plus de raisons de chercher à garder une compatibilité avec la framework .NET historique.
Exemple d’utilisation de .NET Standard
A titre d’exemple, on se propose d’utiliser .NET Standard comme framework cible pour des assemblies de type bibliothèque de classes (i.e. class library). Dans notre exemple, on considère 2 assemblies:
QuickSort.dll: bibliothèque de classes comportant la classe QuickSort (l’implémentation de cette classe n’a pas d’importance):
namespace Example
{
public class QuickSort
{
// ...
}
}
On souhaite modifier le framework cible de QuickSort.dll pour cibler .NET Standard plutôt qu’un framework précis. Si on regarde le tableau de compatibilité sur learn.microsoft.com/en-us/dotnet/standard/net-standard, on peut voir que .NET 6.0 implémente toutes les versions de .NET Standard:
.NET 6.0 implémente toutes les versions de .NET Standard
De façon à être compatible avec le framework .NET historique, on va cibler .NET Standard 2.0 (le framework .NET historique n’implémente pas .NET Standard 2.1).
Pour changer le framework cible dans Visual Studio:
Clique droit sur le projet puis Properties
Dans la partie Application ⇒ General ⇒ Target Framework
Comme on peut le voir, on ne voit pas .NET Standard. Cela s’explique par le fait que .NET Standard est abandonné et Visual Studio n’expose pas directement la possibilité de sélectionner .NET Standard. On peut toutefois le faire en faisant:
Un clique droit sur le projet puis Edit project file.
Il faut modifier le fichier .csproj en remplaçant net6.0 par netstandard2.0 pour le paramètre TargetFramework:
Si on compile le projet QuickSort en l’état, on peut obtenir des erreurs dues à certaines fonctionnalités n’étant pas compatibles avec certaines versions de C#, par exemple:
Feature 'global using directive' is not available in C# 7.3. Please use language version 10.0 or greater.
On peut résoudre ce problème en désactivant les fonctionnalités incompatibles en rajoutant dans le .csproj:
<ImplicitUsings>disable</ImplicitUsings>
La compilation réussit puisque Launcher.exe cible .NET 6.0 qui est compatible avec .NET Standard 2.0.
Si on change le framework cible de Launcher.exe en choisissant le framework .NET historique (monikernet48):
Comme on peut le voir, compiler du code historique pour cibler .NET Standard nécessite de modifier les fichiers .csproj et de chercher un compromis dans le choix de la bonne version de .NET Standard. Ces étapes peuvent être couteuses en refactoring dans des projets de grande taille.
Compatibility shim
Utiliser .NET Standard n’est pas la seule façon d’utiliser des assemblies ne ciblant pas le même framework. Les compatibility shims ont régulièrement été utilisés par Microsoft pour assurer une compatibilité ascendante de ses frameworks:
Entre la version 2.0 et 4.0 du framework .NET historique,
On va s’intéresser spécifiquement à ce dernier cas. Le but étant de pouvoir utiliser une assembly ciblant le framework .NET historique dans une application .NET sans recompilation et sans modifier le framework cible. Dans ce cas, la compatibility shim utilisée consiste à effectuer des redirections de types (i.e. Type forwarding). On va détailler cette approche par la suite.
De façon à expliciter l’approche des compatibility shims, on se propose de croiser l’utilisation d’assemblies ne ciblant pas les mêmes frameworks:
En consommant une assembly ciblant le framework .NET historique dans une application .NET et
En consommant une assembly ciblant .NET dans une application ciblant le framework .NET historique.
Utiliser des assemblies framework .NET dans une application ciblant .NET
Cette approche consiste à vérifier s’il est possible de charger une dépendance ciblant le framework .NET historique à partir d’une application .NET. Comme on a pu le voir précédemment, le fonctionnement du CLR entre le framework .NET historique et .NET est très similaire, les grandes différences résident dans les chemins utilisés pour la recherche des dépendances. D’autre part, on a pu observer qu’il n’y a pas de différences dans la structure des assemblies lorsqu’elles ciblent des frameworks différents. La différence réside essentiellement dans les dépendances requises.
C’est essentiellement ce dernier point que Microsoft a tenté de résoudre pour permettre de charger des assemblies ciblant le framework .NET historique dans une application .NET. La compatibility shim utilisée consiste à effectuer une redirection des types (i.e. Type forwarding) du framework historique vers les mêmes types sous .NET.
Si on regarde le manifest de l’assembly avec ildasm.exe (accessible sur C:\Program Files (x86)\Microsoft SDKs\Windows\v10.0A\bin\NETFX 4.8.1 Tools), on peut voir:
L’assembly possède une dépendance vers mscorlib.dll qui est l’assembly de base de framework .NET historique.
Ensuite on compile l’assemblyLauncher.exe en mode “self-containded”:
Faire un clique droit sur le projet Launcher puis cliquer sur Publish
Cliquer sur Show all settings puis indiquer les paramètres:
Configuration: Release | Any CPU
Target Framework: net6.0
Deployment mode: Self-contained
Target runtime: win-x64
Cliquer sur Save puis Publish
Dans le répertoire de sortie, on peut constater qu’il contient toutes les dépendances. Si on ouvre l’assemblymscorlib.dll avec ildasm, on constate dans le manifest:
L’assemblymscorlib.dll n’est pas une vraie assembly. Il n’y a pas d’implémentation concernant les objets. Ainsi, l’objet System.Object ne possède pas d’implémentation dans cette assembly. En revanche, elle contient des redirections de types. L’objet System.Object est redirigé vers l’assemblySystem.Private.CoreLib. Cette assembly fait partie de .NET et contient des types de base du framework.
Si on exécute l’application, on constate qu’elle s’exécute normalement. La dépendance QuickSort.dll est bien chargée malgré le fait qu’elle cible le framework .NET historique. Les redirections de type permettent de substituer les types du framework .NET historique vers les types correspondant dans le .NET.
Ainsi le gros avantage de cette approche est qu’elle ne nécessite pas de recompilation ni de changement de framework cible (comme pour l’approche .NET Standard). Il faut, toutefois, avoir en tête que cette compatibility shim n’est pas infaillible: il peut subsister des différences entre une fonction appelée dans le framework .NET historique et la fonction se trouvant dans l’assembly vers laquelle les redirections sont effectuées. La moindre différence de signature entraînera une exception à l’exécution. D’autre part, plus .NET évolue et plus il s’écarte du framework .NET historique rendant les probabilités d’incompatibilités de plus en plus importantes.
Cette approche est donc plus risquée que .NET Standard puisque les problèmes d’incompatibilités ne peuvent être constatés qu’à l’exécution et non durant la compilation. Il faut donc bien tester l’exécution du code en essayant de balayer tous les scénarios d’appels de fonction utilisant une redirection de type.
Utiliser des assemblies .NET dans une application framework .NET
Cette approche consiste à effectuer l’inverse de ce que nous avons expérimenté précédemment. Nous cherchons à exécuter une application ciblant le framework .NET historique et à charger une assembly ciblant .NET.
Ainsi de façon à ne pas avoir d’erreurs de compilation, on compile Launcher.exe et QuickSort.dll en ciblant le framework .NET historique:
On modifie le fichier .csproj de Launcher.exe de cette façon:
L’application devrait compiler normalement et le répertoire de sortie devrait contenir les fichiers:
Launcher.exe
Launcher.exe.config
Launcher.pdb
QuickSort.dll
QuichSort.pdb
On publie QuickSort.dll pour cibler .NET en mode “self-contained” de façon à ce que le répertoire de sortie contienne toutes les dépendances .NET. On effectue un clique droit sur le projet QuickSort puis on clique sur Publish
Cliquer sur Show all settings puis indiquer les paramètres:
Configuration: Release | Any CPU
Target Framework: net6.0
Deployment mode: Self-contained
Target runtime: win-x64
Cliquer sur Save puis Publish
Dans le répertoire de sortie, on peut constater qu’il contient toutes les dépendances.
Copier toutes les dépendances du répertoire de sortie dans le répertoire de sortie de Launcher.exe.
Si on exécute l’application, on obtient l’erreur suivante:
Unhandled Exception: System.TypeLoadException: Could not load type 'System.Object' from assembly 'System.Private.CoreLib, Version=7.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e' because the parent does not exist.
Ceci s’explique par le chargement du type System.Object à partir de 2 emplacements différents.
Si on regarde le code IL du constructeur .ctor : void () de la classe Example.Launcher.TestClass de l’assemblyLauncher.exe avec ildasm.exe:
.method public hidebysig specialname rtspecialname
instance void .ctor() cil managed
{
// Code size 7 (0x7)
.maxstack 8
IL_0000: ldarg.0
IL_0001: call instance void [mscorlib]System.Object::.ctor()
IL_0006: ret
} // end of method TestClass::.ctor
On peut voir que le type System.Object est chargé à partir de l’assemblymscorlib.dll (appartenant au framework .NET historique).
Si on regarde le code IL du constructeur .ctor : void() de la classe Example.QuickSort de l’assemblyQuickSort.dll avec ildasm.exe:
On constate que le type System.Object est chargé à partir de l’assemblySystem.Runtime (appartenant au framework .NET).
Ainsi au démarrage de l’application, le CLR charge le type System.Object à partir de mscorlib.dll. Plus tard dans l’exécution de l’application pour le constructeur de la classe Example.QuickSort, il tente d’utiliser le type System.Object à partir de System.Runtime, or si ce type est déjà chargé toutefois il provient de 2 assemblies différentes d’où l’erreur à l’exécution.
Dans le message d’erreur "Could not load type 'System.Object' from assembly 'System.Private.CoreLib [...]' because the parent dœs not exist.", on peut se demander ce que signifie le terme “parent” ? Le code du CLR permet de comprendre ce terme: dans la fonction QuickSort.dllClassLoader::LoadApproxParentThrowing (le message de l’erreur est IDS_CLASSLOAD_PARENTNULL), on comprend que “parent” désigne le parent de tous les objets en .NET c’est-à-dire System.Object. Lors de l’exécution de ce code, le CLR part du principe que tous les objets en .NET ont pour parent System.Object dans mscorlib.dll or l’objet System.Object dans System.Private.CoreLib ne possède pas pour parent System.Object dans mscorlib.dll. La recherche du parent échoue pour System.Object dans System.Private.CoreLib d’où l’erreur.
Par suite l’objet System.Object dans System.Private.CoreLib ne peut être chargé. Ce problème ne permet pas une exécution de cette façon, ce qui rend incompatible les assemblies .NET avec les applications du framework .NET historique. Cela peut se comprendre puisque ce use-case n’a pas un réel intérêt fonctionnel (compatibilité descendante). Microsoft n’a donc pas cherché à le résoudre.
Conclusion
Pour une application, lorsque le volume de code existant est important, il est compliqué de savoir quelle est la meilleure approche pour faire évoluer les différentes dépendances et éviter une trop grande dette technique. Bien-que source d’instabilité, dans le milieu des années 2010, il aurait été inconcevable pour Microsoft de continuer à faire évoluer .NET sans proposer une réelle rupture en ouvrant cette technologie à d’autres plateformes que Windows. Problématique pour beaucoup d’équipes de développeurs, cette rupture tend à se stabiliser. En effet, actuellement Microsoft, a terminé sa migration du framework .NET historique vers .NET:
Le framework .NET historique n’évolue, désormais, plus fonctionnellement,
.NET Standard qui était l’approche de transition entre le framework .NET historique et .NET, est abandonné,
Le renommage de .NET Core en .NET qui était l’appellation initiale du framework .NET historique achève de tourner la page du framework historique.
Même si la période de transition entre l’arrêt du framework .NET historique et la poursuite des nouvelles fonctionnalités exclusivement sur .NET est maintenant terminée, elle aura duré 4 ans entre la 1ère version de .NET Core en juin 2016 et l’annonce de l’abandon de .NET Standard en septembre 2020. Durant 4 ans, pour tous les développeurs .NET s’est posé la douloureuse question de savoir comment faire évoluer son application:
Continuer à développer en ciblant le framework .NET historique en 4.8,
Migrer en ciblant .NET Standard,
Migrer en ciblant .NET Core puis .NET.
Pour encore beaucoup d’applications, la masse de code peut rendre cette évolution compliquée et couteuse. Dans ce optique, cet article avait pour but de montrer que l’approche .NET n’est pas complètement différente de l’approche du framework .NET historique:
Les assemblies ont la même structure entre les différents frameworks,
Suivant le framework ciblé, la plus grande différence dans les assemblies réside dans les dépendances,
Le CLR se comporte de la même façon pour charger des dépendances même si les répertoires de recherche des dépendances ne sont pas les mêmes.
Certaines fonctionnalités comme les AppDomains sont différentes entre le framework .NET historique et .NET.
Des compatibility shims permettent de continuer à utiliser des assemblies ciblant le framework .NET historique dans des applications .NET au prix d’effectuer des tests à l’exécution pour minimiser le risque d’exception en cas d’incompatibilité.
Ces compatibility shims permettent d’éviter de devoir recompiler ou changer la cible d’assemblies historiques.
J’espère que cet article vous aura aider à appréhender plus facilement le passage du framework .NET historique vers .NET.
Le but de cet article est d’expliquer les imports de modules Python (les modules d’extension ne seront pas abordés).
Dans un premier temps, on va décrire brièvement le fonctionnement du système d’import de modules. Ensuite, on va compléter cette description avec un exemple. Enfin, on va rappeler la syntaxe pour importer un module et obtenir des informations sur un module importé.
Les seuls objets Python sont les modules quelque soit leur implémentation:
les modules purs implémentés en Python sous la forme de fichier .py,
les modules d’extensions en C,
etc…
Les packages sont des objets Python pouvant s’apparenter à des répertoires. Ces packages contiennent des sub-packages ou des modules. Un package est un module avec un attribut __path__.
Il existe une différence entre l’identification des modules et packages Python et le chemin des fichiers ou répertoires correspondant dans le système de fichiers. Ainsi il faut considérer les modules et les packages comme étant un type d’objet plutôt que comme des fichiers ou des répertoires.
Par suite, les règles suivantes s’appliquent pour identifier des modules et packages par rapport aux fichiers correspondants:
Un module est identifié par le nom du fichier sans l’extension .py: si le fichier s’appelle hello_world.py alors le module s’appellera hello_world.
Un package est identifié de la même façon qu’un répertoire avec son nom.
Un sub-package est identifié à partir de ses packages parents suivant son chemin: ainsi si le sub-package est dans le répertoire numpy/polynomial alors le nom du sub-package sera numpy.polynomial.
Un module dans un package: par exemple si on considère un module sous la forme d’un fichier .py dans le répertoire numpy/polynomial/chebyshev.py alors l’identifiant du module sera numpy.polynomial.chebyshev.
Fonctionnement du système d’import
Un import consiste à effectuer 2 opérations:
La recherche d’un module nommé et
L’attribution d’un nom à ce module, la portée de ce nom étant local.
Mécanisme d’import des modules
L’utilisation de l’instruction import correspond à un appel à la fonction __import__() puis à l’attribution d’un nom local aux modules importés. Cette attribution se fait en rajoutant une entrée dans le dictionnaire sys.module. Ce dictionnaire permet de retrouver un module en fonction de son nom.
L’exécution de la fonction __import__() déclenche une série d’étapes qui ont pour but de trouver le module à charger:
Suivant le nom du module, une recherche est effectuée pour déterminer l’emplacement du module en fonction de son nom.
Avant d’effectuer une recherche à proprement parlé, une recherche est faite en utilisant le dictionnaire sys.modules contenant les modules en fonction du nom. Si le module n’est pas trouvé dans ce dictionnaire, la recherche se poursuit.
La recherche est effectuée par des objets appelés finders ou des importers. D’autres objets appelés loaders permettent de charger les modules. Les importers sont à la fois des finders et des loaders.
Par défaut, Python contient un certain nombre de finders et importers en parcourant sys.meta_path. Tous les objets de sys.meta_path sont appelés successivement pour trouver le module.
Pour voir le contenu du tableau sys.meta_path, il suffit d’exécuter:
>>> import sys
>>> sys.meta_path
[_frozen_importlib.BuiltinImporter,
_frozen_importlib.FrozenImporter,
_frozen_importlib_external.PathFinder,
<six._SixMetaPathImporter at 0xffff90cc1fa0>,
<pkg_resources.extern.VendorImporter at 0xffff90a7ceb0>]
On peut voir que la recherche est effectuée sur les modules “built-in” c’est-à-dire des modules écrit en C faisant partie du shell Python. Dans un 2e temps, la recherche s’effectue pour des modules “frozen”. Les modules “frozen” sont des modules compilés en byte-code exécutables sans l’utilisation de Python. Dans 3e temps, une correspondance est cherchée entre le nom du module et son emplacement suivant le chemin d’import (i.e. import path). La liste des emplacements du chemin d’import peut être listée en affichant le contenu de sys.path (les chemins dépendent de la distribution Python, de l’environnement et du contexte d’exécution). 2 autres variables peuvent être utilisées pour trouver le chemin d’un module sys.path_hooks et sys.path_importer_cache.
L’emplacement d’un module n’est pas forcément sur le disque, il pourrait être dans une archive .zip ou accessible avec une URL.
Lorsqu’un finder trouve la correspondance entre un module et son nom, il retourne le loader correspondant. Si le finder est un importer, il retourne sa propre instance.
Le module est rajouté dans sys.modules avant son exécution. Si l’exécution du module échoue, il est retiré du dictionnaire sys.modules. L’ajout dans sys.modules est faite au préalable car l’exécution du module peut l’amener à se charger lui-même ce qui pourrait provoquer une boucle récursive infinie en le rajoutant indéfiniment dans sys.modules.
Le loader correspondant exécute le module (en appelant la méthode exec_module()). Les modules peuvent se trouver dans des packages. Un package est lui-même un module avec un attribut __path__ indiquant le chemin du package.
Il existe 2 types de packages:
Regular packages: ils sont implémentés dans un répertoire contenant un fichier __init__.py. Ce fichier est exécuté implicitement à chaque import de ce type de packages. Les sub-packages c’est-à-dire les répertoires enfant doivent aussi contenir des fichiers __init__.py qui, en cas d’import, seront exécutés après le __init__.py du répertoire parent.
Namespace packages: ces packages sont constitués de portions pouvant se trouver à des emplacements différents dans le système de fichier. Par exemple, une portion peut être un fichier sur le disque et un autre peut être à un emplacement sur le réseau.
Attributs des modules
Lors de l’import de modules, des objets correspondant sont créés pour accéder aux fonctions dans les modules. Le mécanisme d’import ajoute quelques attributs indiquant d’où provient le module:
__name__: le nom du module
__loader__: nom du loader utilisé pour importer le module. Les finders et loaders disponibles peuvent être listés avec sys.meta_path.
__package__: dans le cas d’un package cet attribut possède la même valeur que __name__.
__spec__: ensemble des spécifications utilisées pour le système d’import.
__path__: chemin du package sur le disque. Ce chemin dépend de l’environnement virtuel utilisé.
__file__: fichier __init__.py utilisé itinialement. Ce chemin dépend de l’environnement virtuel utilisé.
__cached__: fichier compilé (voir CPython) utilisé à l’exécution. Ce chemin dépend de l’environnement virtuel utilisé.
En utilisant la fonction dir(), on peut voir la liste des attributs d’un module.
Chemin des modules dans les packages
Dans les packages, les imports de modules se font avec un chemin relatif au module courant ou en indiquant le chemin à partir du répertoire parent. Comme indiqué précédemment, les modules sont identifiés par nom. Dans le cas de modules présents sur le disque, le nom permet d’indiquer l’emplacement physique du fichier .py correspondant. Le nom des modules à importer doit respecter les règles suivantes:
Le nom ne doit pas comporter de / ou \ (à la différence d’un chemin de fichier), ils doivent être remplacés par ..
. permet d’indiquer le répertoire courant.
.. permet d’indiquer le répertoire parent.
Le nom du module correspond au nom du fichier correspondant sans l’extension .py.
Ainsi si on veut indiquer le chemin de:
./Module1.py alors l’import peut se faire avec from .Module1 import *
./InnerModule/Module3.py alors l’import peut se faire avec from .InnerModule.Module3 import *
../Module2.py l’import peut se faire avec from ..Module2 import *
Par exemple si on considère les fichiers suivants:
from Hello.Module2 import HelloFromModule2
def HelloFromModule1():
print("Hello from module 1")
HelloFromModule2()
Hello/Module2.py:
from Hello.InnerModule.Module3 import HelloFromModule3
def HelloFromModule2():
print("Hello from module 2")
HelloFromModule3()
Hello/InnerModule/Module3.py:
def HelloFromModule3():
print("Hello from module 3")
Dans ces exemples, les imports ont été faits suivant le répertoire parent du package. Si on avait indiqué les chemins de façon relative, il aurait fallu effectuer les imports de cette façon:
Les fichiers du package se trouvent dans un répertoire du type: python_example_module_import/venv/lib/python3.9/site-packages/Hello.
Enfin pour utiliser le package installé, on peut exécuter le fichier python_example_module_import/package_usage/test.py:
(venv) ~/python_example_module_import/package_usage% python test.py
Hello from module 1
Hello from module 2
Hello from module 3
Comment créer un package.whl ?
Pour créer un package, on peut utiliser un fichier setup.py et le packagesetuptools, voir Construire un package wheel.
Encapsulation
L’encapsulation au niveau de la syntaxe du langage à proprement parlé n’existe pas en Python. Toutefois il est possible de ne pas exposer des modules lorsqu’ils sont dans des packages. En effet dans les fichiers __init__.py des répertoires du packages, on peut indiquer les modules à importer lorsque le package est importé. Ainsi suivant les imports qui y sont effectués, on peut choisir d’exposer des modules particuliers ou de ne pas en exposer d’autres à l’extérieur.
Par exemple, si on considère l’exemple précédent, dans le fichier Hello/__init__.py, si on ne souhaite exposer que le Module1 alors on peut effectuer l’import de cette façon:
from .Module1 import HelloFromModule1
Dans ce cas à l’extérieur du package, on pourra effectuer l’import de cette façon:
import Hello as h
h.HelloFromModule1()
Le module Module2 n’étant pas exposé dans le fichier Hello/__init__.py, il n’est pas accessible de l’extérieur:
h.HelloFromModule2() # ERREUR
Pour que HelloFromModule2() soit accessible, il faut l’importer en modifiant Hello/__init__.py de cette façon:
from .Module1 import HelloFromModule1
from .Module2 import HelloFromModule2
Import d’un package
Comme indiqué précédemment:
Les seuls objets Python sont les modules.
Les packages sont des modules avec un attribut __path__.
Le système d’import a donc le même comportement qu’ils s’agissent de modules ou de packages. Il faut toutefois faire attention à la syntaxe utilisée lors de l’import. Ainsi les imports peuvent se faire:
Relativement au fichier courant ou
Par rapport au répertoire initial du package.
La recherche d’un module se fait en utilisant son nom (cf. Mécanisme d’import des modules). Le système d’import parcourt les répertoires du Python path pour trouver le module suivant son nom. Dans un premier temps, on va montrer comment récupérer les répertoires du Python path. Dans un 2e temps, on va indiquer la syntaxe d’import des modules et packages.
Python path
Le Python path est un tableau indiquant les chemins parcourus par le système d’import pour trouver un module suivant son nom. Pour obtenir cette liste de répertoire, il faut exécuter:
>>> import sys
>>> sys.path
Le résultat dépend du système d’exploitation et de la distribution Python utilisé toutefois le tableau devrait contenir en particulier:
Le répertoire courant,
Le répertoire de l’exécutable python: par exemple <répertoire d'Anaconda/lib/python3.9.
Le répertoire des packages: par exemple <répertoire d'Anaconda/lib/python3.9/site-packages.
Le répertoire des packages dans le cas d’un environnement virtuel: par exemple <répertoire env. virtuel/lib/python3.9/site-packages.
On peut voir les modules déjà importés en exécutant:
>>> sys.modules
Import de modules
Un module possède un namespace privé et ce namespace n’est pas directement accessible à l’extérieur du module. Un module peut importer un autre module.
Plusieurs syntaxes sont possibles pour importer un module:
import <nom du module>: le module est importé dans le namespace local toutefois tous les noms des objets ne sont pas accessibles à partir du namespace local. Pour accéder aux objets du module, il faut taper <nom du module>.<nom de l'objet>.
Par exemple:
import pandas
data = pandas.DataFrame()
import <nom de l'objet> as <nom alias>: permet d’éviter d’utiliser le nom entier du module pour accéder à ses objets. Avec cette syntaxe, le module est importé dans le namespace local toutefois les objets ne sont accessibles qu’en utilisant l’alias du module: <nom alias>.<nom de l'objet>.
Par exemple:
import pandas as pd
data = pd.DataFrame()
from <nom du module> import <nom de l'objet>: on ne charge qu’un seul objet du module dans le namespace local. Cet objet est accessible en utilisant directement son nom.
Par exemple:
from pandas import DataFrame
data = DataFrame()
from <nom du module> import *: tous les noms des objets du module sont importés dans le namespace local. Il n’est pas recommandé d’utiliser cette syntaxe car il peut y avoir des collisions entre des modules qui utiliseraient les mêmes noms d’objet. Avec cette syntaxe, les objets sont accessibles directement par leur nom.
Par exemple:
from pandas import *
data = DataFrame()
from <nom du module> import <nom de l'objet> alias <alias de l'objet>: cette syntaxe permet d’importer le nom d’un objet du module et de permettre d’utiliser cet objet en utilisant un alias.
Par exemple:
from pandas import DataFrame as PandasDataframe
data = PandasDataframe()
Avoir des informations sur un module importé
La fonction dir() permet de lister les noms d’objets définis dans le namespace local. Cette fonction permet de lister les variables, les fonctions et les modules.
Ainsi:
dir(): sans argument affiche les noms de variables, fonctions et modules qui sont accessibles dans le namespace local.
dir(<nom du module>): liste les objets accessibles dans le module.